
基于Flatten-CNN的语音带宽扩展研究
2022-01-28 15:16杨俊美雷杨陈习坤
华南理工大学学报(自然科学版) 2021年11期
杨俊美 雷杨 陈习坤
(华南理工大学 电子与信息学院,广东 广州 510640)
语音带宽扩展旨在利用高带宽语音信号低频分量和高频分量之间的数学关系来还原低带宽语音中丢失的高频分量。语音带宽扩展对于在低带宽信道上进行语音通信的设备非常有用,将语音带宽扩展模块集成到接收端设备中可以提高实时传输的低带宽语音的带宽,例如应用在公共交换电话网(PSTN)、人工耳蜗[1]等。除了应用于实时语音通信,其还可以应用于其他语音信号处理领域,例如文本合成语音(TTS)[2]、语音识别[3- 4]和语音增强[5]。
传统算法通常采用源滤波器模型[6],其主要理论依据是线性预测分析。源滤波器算法由两部分构成:第1部分是频谱包络的扩展,常见方法有码书映射[7]、线性映射[8]和统计模型映射等,其中码书映射基于矢量量化,统计模型映射有高斯混合模型[9- 10]和隐马尔可夫模型[11- 12];第2部分是激励信号的产生,目前有直接信号合成、非线性失真和窄带频谱移动与合成。
近年来流行的基于深度学习的算法已被证明优于传统算法。Kuleshov等[13]提出时域算法Audio-Unet,结构类似于自编码器,本质是卷积神经网络,不需要对数据进行预处理,输入低带宽语音波形预测出高带宽语音波形,效果较好;Ling等[14]提出时域算法SampleRNN,他们首次在语音带宽扩展任务中使用循环神经网络及其各种变型版,网络新颖;Wang等[15]提出T-CNN,其结构类似于文献[13]提出的AudioUnet,在损失函数中引入了频域损失,实质上也是时域算法,依然存在时域算法不能充分利用语音信号特征、训练数据量大的问题。Li等[16]提出频域算法DNN-BWE,其网络被预先训练为受限玻尔兹曼机,并根据低带宽对数功率谱预测高带宽对数功率谱。对于高频范围相位谱的缺失问题,他们提出了对低带宽相位谱重复、翻转、取相反数的方法。Eskimez等[17]提出基于生成对抗网络的频域算法F-GAN,用低带宽对数功率谱预测高频范围对数功率谱,再将预测的高频范围对数功率谱和原始的低带宽对数功率谱连接起来组成高带宽对数功率谱。其高频范围相位谱缺失的处理方法和文献[16]是一样的。F-GAN已经取得了不错的效果,但在对数功率谱特征提取时未能重视帧与帧之间的数学关系,频率轴数为奇数,网络深度浅,且忽略了语音时域信息。Lim等[18]提出时频两域算法TFNet,它定义了一个完全可微、端到端的时频网络,包含频谱融合层、频谱复制器、损失函数,分别在时域和频域训练神经网络,最后结合两个网络的信息生成高带宽语音。相对时域或者频域算法,其本质上是训练两个网络,所以模型相对复杂。
上述算法极大地促进了语音带宽扩展技术的发展,但仍然存在以下问题:时域算法语音特征提取不够精确,训练数据量大;频域算法对数功率谱特征提取忽略帧与帧之间的数学关系,频率轴数为奇数,不利于网络深度加深,且未利用语音时域信息;两域算法模型训练两个网络相对复杂。鉴于此,文中提出了一种基于频域运行的语音带宽扩展算法,以便于充分利用语音信号特征和减小数据量;此外,提出了一种改进的编码器,通过引入平铺层,使一维卷积核能够提取对数功率谱时频两轴信息,以有效提升网络结构特征提取能力;接着,在数据处理时去掉频率轴最后一个点,还原时再补零,使频率轴数为偶数而利于加深网络深度;最后在损失函数中引入时域损失,以便于充分利用语音两域信息。
1 算法描述
1.1 算法框架
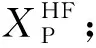
1.2 基于Flatten-CNN的语音带宽扩展网络
当前流行的频域算法结构[17]中,利用一维卷积核提取对数功率谱频率轴特征,取得了不错的效果。但它们的卷积核只作用于对数功率谱频率轴,而忽略了对数功率谱时间轴。对此,文中提出了基于Flatten-CNN的语音带宽扩展网络,其结构见图1。

(a)网络结构中的图层
首先,文中网络是一个序列到序列的模型,输入是128×64(128和64分别对应频率轴和时间轴)低带宽对数功率谱,输出是预测的高频范围对数功率谱。编码器中,引入了平铺层,它由拉伸和变形组合而成,通过将对数功率谱时频两轴数据(128×64)转化为一轴(8 192×1),使卷积核能够同时对对数功率谱时间轴和频率轴进行特征提取,充分利用对数功率谱帧与帧之间、低频和高频之间的数学关系。此外,平铺层能够使网络搭得很深,它使输出数据维度为1,卷积核数量能够从8、16、16、32、32、64、64、128、128、256、256、512逐渐增大。如果没有平铺层,直接进行一维卷积,数据维度是64,卷积核数量一般比这个数大,导致网络不能建得太深,否则网络参数过于庞大。在解码器中,文中引入了Shi等[19]提出的亚像素层。据研究[20],在图像超分辨率应用中,亚像素层是一种比插值或反卷积更优的上采样方法,它将低带宽图像特征图通过卷积和多通道间的重组得到高带宽图像特征图,减轻了图像重建时的伪影。亚像素层引入到文中语音带宽扩展网络后,编码器通过卷积核降采样得到低带宽对数功率谱特征图,解码器将低带宽对数功率谱特征图器通过卷积和多通道间的重组得到高频范围对数功率谱特征图。为防止网络层数过深而导致信息丢失,在编码器和解码器之间使用了跳跃连接,在实验中,发现这样做还可以加速网络的收敛。一维卷积层中,均使用参数化修正线性单元激活函数,详细参数设置见表1。
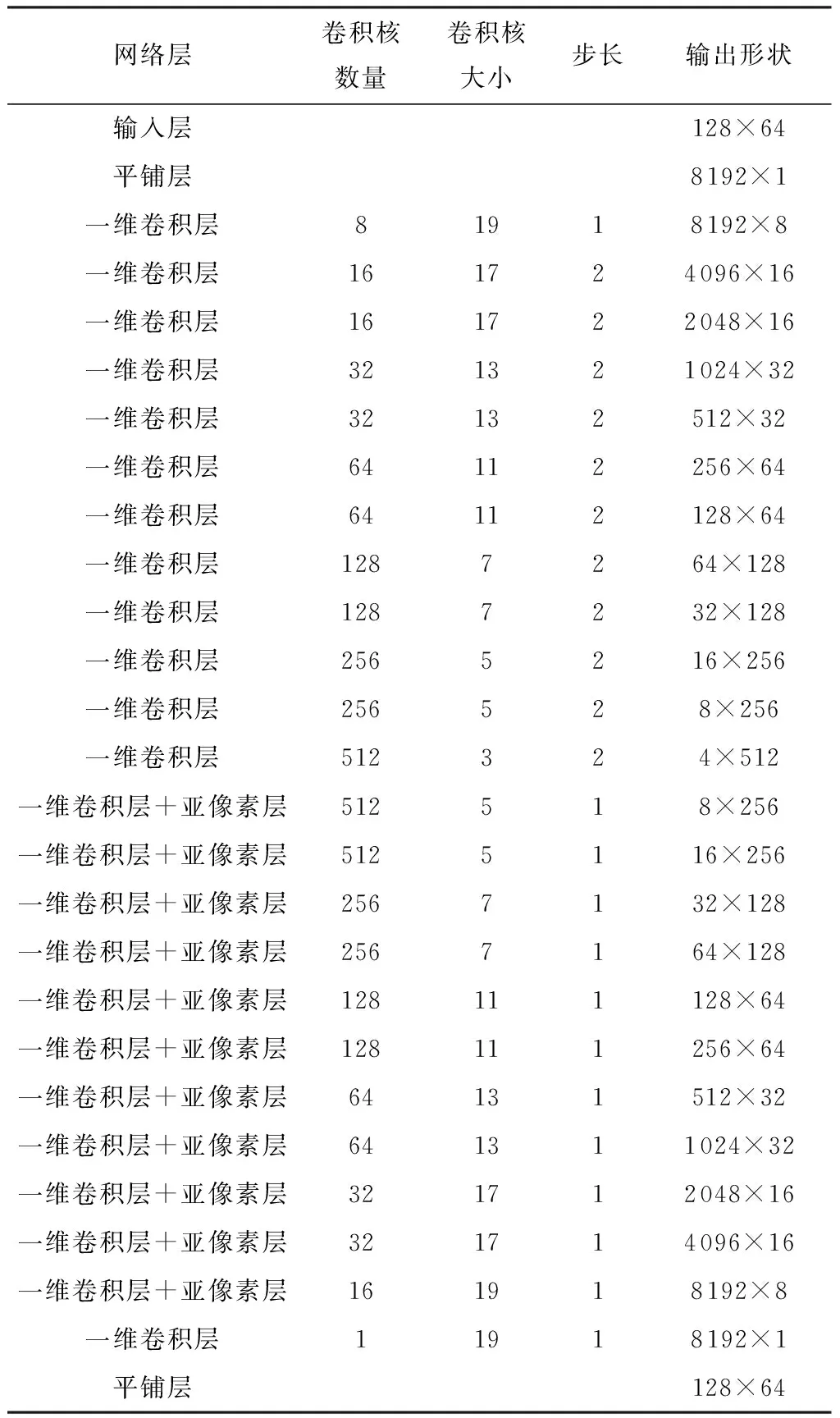
表1 文中所提的网络结构的详细参数1)Table 1 Detailed parameters of the network structure mentioned in the article
1.3 基于时域-频域联合优化的损失函数
目前流行的频域算法[17]中,损失函数只和频域有关,这会使训练出来的模型只具有在频域中的优良表现。文中受文献[15]的时频损失启发,在损失函数中引入了时域损失,使训练出来的模型同时具有在频域和时域中的优良表现。
频域损失函数LF是对预测的高频范围对数功率谱和真实的高频范围对数功率谱求均方误差(MSE):
(1)
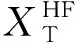
时域损失函数的计算过程如下:首先把低带宽对数功率谱输入到文中提出的Flatten-CNN,预测出高频范围对数功率谱;再将预测出的高频范围对数功率谱和原始的低带宽对数功率谱连接起来得到合成的高带宽对数功率谱;接着利用短时傅里叶逆变换(ISTFT)将合成的高带宽对数功率谱和真实相位谱从频域反变换到时域,得到预测的高带宽语音波形。同理,将真实的高频范围对数功率谱和原始的低带宽对数功率谱连接起来得到真实的高带宽对数功率谱;然后利用短时傅里叶逆变换将真实的高带宽对数功率谱和真实相位谱从频域反变换到时域,得到真实的高带宽语音波形;最后对预测的高带宽语音波形和真实的高带宽语音波形求均方误差(MSE),得到时域损失函数LT。
(2)
(3)
(4)
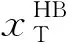
将时域损失函数和频域损失函数按一定比例相加得到最终的时频损失函数LTF。其中,α取值为0.75。
LTF=αLT+(1-α)LF
(5)
2 实验结果与分析
为验证文中算法的有效性,用TIMIT数据集[21]和VCTK数据集[22]进行模型的训练和测试。文中复现了文献[23]提出的Spline、文献[15]提出的T-CNN、文献[16]提出的DNN-BWE、文献[17]提出的F-GAN,利用笔者的开源代码实现了文献[13]提出的AudioUnet。对于文献[14]提出的SampleRNN,文中在TIMIT数据集实验中直接用他们原文中的结果作对比。
2.1 实验设置及评价指标
文中算法网络训练所使用显卡为NVIDIA TITAN Xp GPUs,深度学习框架为TensorFlow框架。使用Adam优化器进行优化,学习率设置为0.000 3,网络训练100个epoch,batch size设置为256。
文中选取两个客观指标来评估语音带宽扩展性能,即分段信噪比SegSNR(segment signal-to-noise ratio)和对数功率谱距离LSD(log-spectral distance)[24],它们分别从时域和频域来评估性能。SegSNR反映了正常声音信号与噪声信号比值,定义如下:
(6)
式中,n、N分别是语音分段数、语音分段总数。
LSD反映了频域里两个信号之间的距离,定义如下:
(7)

2.2 TIMIT数据集实验结果
TIMIT数据集[21]是由德州仪器、麻省理工学院和SRI International合作构建的数据集。其采样频率为16 kHz,一共包含6 300个句子,由来自美国8个主要方言地区的630个人每人朗诵给定的10个句子得到。
数据处理:①TIMIT数据集下采样至8 kHz视为原始低带宽语音,原本的16 kHz视为真实高带宽语音。利用短时傅里叶变换(STFT)将语音变换到频域时,16 kHz语音的窗口大小(frame length)为512,8 kHz语音窗口大小为256。求出对数功率谱后,对于16 kHz语音的对数功率谱的频率轴,文中截取129-256作为真实的高频范围对数功率谱。对于8 kHz语音的对数功率谱的频率轴,文中截取1-128作为原始的低带宽对数功率谱。对于对数功率谱的时间轴,文中以64为长度进行分割,剩余部分不足64的用零填补,最终得到128×64的原始低带宽对数功率谱和高频范围对数功率谱。为了保证低带宽对数功率谱和高频范围对数功率谱的拼接连续性,数据还需要作归一化处理。②求出相位谱后,对于16 kHz语音相位谱的时间轴,以64为长度进行分割,剩余部分不足64的用零填补,得到257×64的真实相位谱。对于 8 kHz 语音相位谱也以64为长度进行分割,剩余部分不足64的用零填补。接着在频率轴截取1-128的部分,并将其翻转、取相反数,再将其和原始的1-129进行拼接,得到257×64人工相位谱。128×64原始低带宽对数功率谱和128×64预测的高频范围对数功率进行拼接,并用零填补缺失的中间点257,最终得到257×64的合成高带宽对数功率谱;同理可以得到257×64的真实高带宽对数功率谱。③模型训练时,利用短时傅里叶逆变换将合成的高带宽对数功率谱还原成时域语音信号时,所用相位谱是真实相位谱。模型训练好后,利用短时傅里叶逆变换将合成的高带宽对数功率谱还原成时域语音信号时,所用相位谱是人工相位谱。
TIMIT数据集实验结果见表2,相较于F-GAN,文中算法在时域性能指标SegSNR上有较大提升,其从14.22 dB提升到19.67 dB;LSD从0.64 dB降低到0.55 dB,LSDH是高频范围对数功率谱距离,其从0.85 dB降低到0.77 dB。这个结果是符合预期的,因为F-GAN受限于频率轴数为奇数,网络不便于加深,且未有效利用对数功率谱时间轴信息。文中对频率轴数进行处理,使其为2的倍数,再使用平铺层加深网络深度、提取时间轴特征,从而更深的网络能够提取到更准确的信息。图2是文中算法用TIMIT数据集训练后输出的对数功率谱(LPS)。
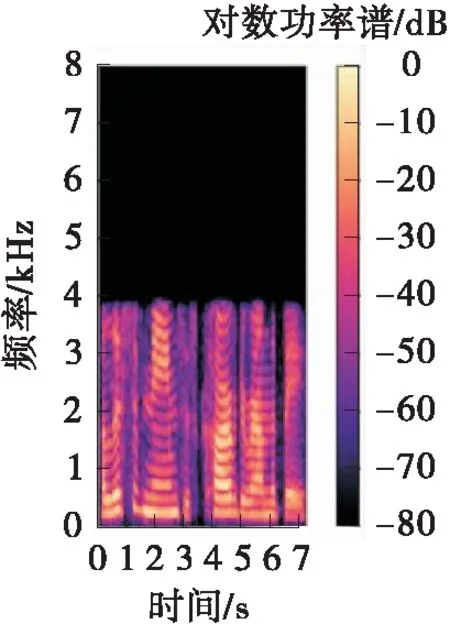
(a)原始LPS
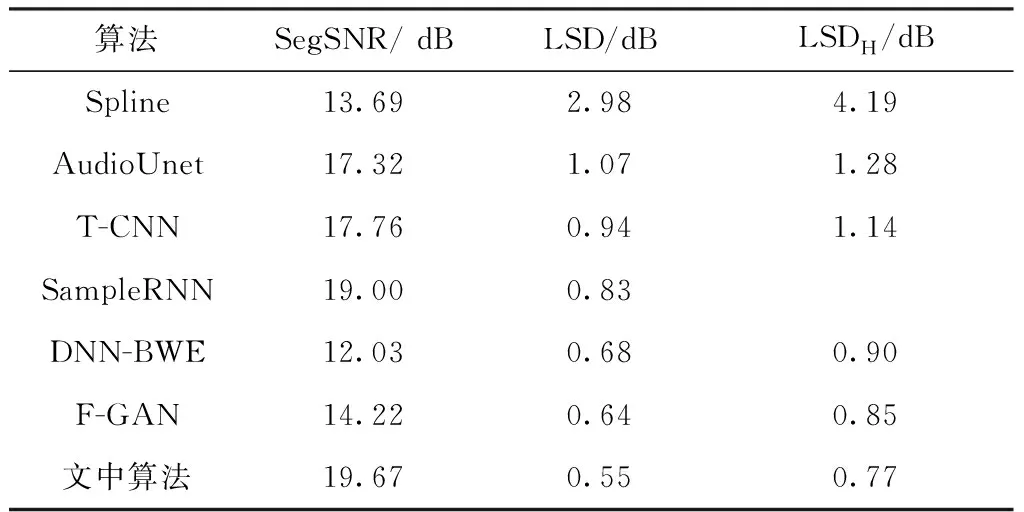
表2 TIMIT数据集实验结果
从指标上看,文中算法在频域指标LSD、LSDH上表现突出,这是毋庸置疑的,说明直接基于频域的算法能更好地提取频谱特征,提升频谱上的表现。从对数功率谱图上看,AudioUnet和T-CNN时域算法容易将对数功率谱图高频部分阴影区域过度填补,而文中频域算法能够更好地展示频谱图的高频阴影部分。从合成语音实际听觉来看:一方面,时域算法合成语音可能有呲呲声,这就是因为时域算法频谱图高频部分被过度填补导致频谱图不准确;另一方面,文中频域算法的音质通透感更强,这是频域指标LSD提升带来的效果,而非时域指标SNR。Spline三次样条插值算法是时域算法中最简单的,也较大提升了时域指标,但频域指标表现很差,Spline算法合成的语音几乎无高频语音特有的通透感。不过频域算法合成语音可能有金属声,这是因为在语音的诸多特征中,虽然频谱是影响最大的,但还有人工相位谱这个影响小的因素不准确所致。文中借鉴文献[15]引入了时域损失以尽量消除人工相位谱对合成语音的这种影响,当训练较好时,这种影响可以降到最低,以致几乎听不到金属声。
2.3 VCTK数据集实验结果
VCTK数据集[22]是爱丁堡大学语音技术研究中心的Yamagishi等构建的数据集。其采样频率是48 kHz,由110个不同口音的人每人朗诵400句在报纸上选取的句子,在爱丁堡大学的半消声室中使用全向麦克风(DPA 4035)录制。VCTKS表示单说话人数据集,VCTKM表示多说话人数据集。
VCTK数据集实验结果见表3,相较于F-GAN,VCTKS数据集实验中,SegSNR从18.77 dB提升到23.74 dB,LSD从0.49 dB降低到0.43 dB,LSDH从0.64 dB降低到0.59 dB;VCTKM数据集实验中,SegSNR从16.37 dB提升到22.67 dB,LSD从0.59 dB降低到0.53 dB,LSDH从0.78 dB降低到0.74 dB。图3是文中算法用VCTKM数据集训练后输出的对数功率谱。由图可见,VCTK数据集和TIMIT数据集的实验结果类似。
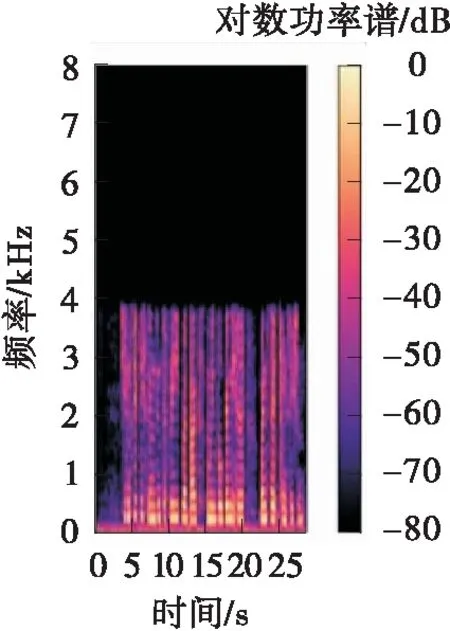
(a)原始LPS
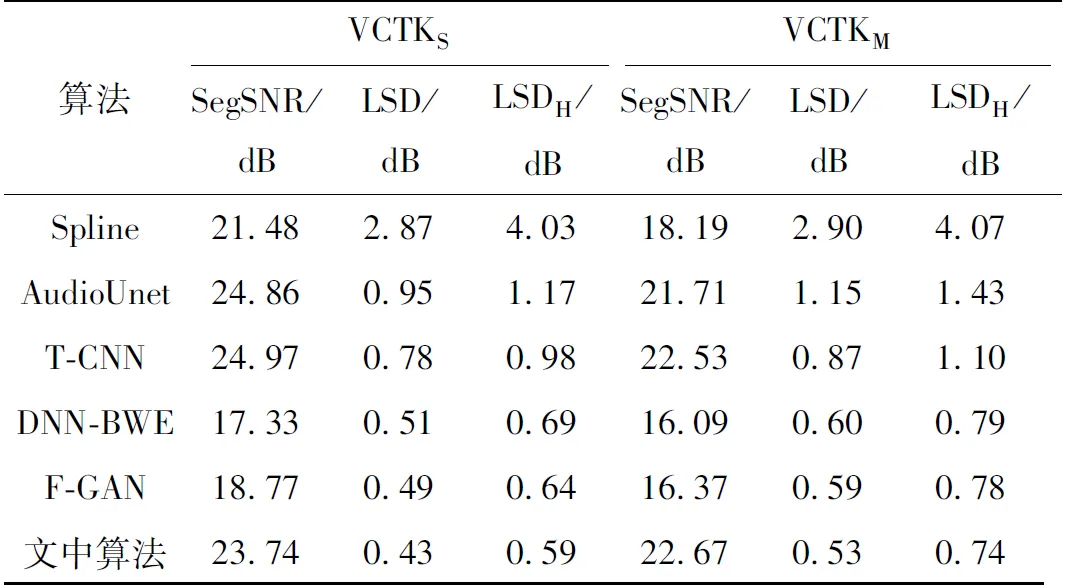
表3 VCTK数据集实验结果
2.4 损失函数消融实验结果
为了验证时频损失函数的优越性,文中进行了不同损失函数的消融分析,表4给出了损失函数消融实验结果,所用数据集是VCTKM。可以看出,仅使用频域损失函数时,指标LSDH、LSD表现较好,但指标SegSNR表现稍差。只使用时域损失函数时有类似结果,指标SegSNR表现较好,指标LSDH、LSD表现稍差。时频损失函数结合了时域和频域损失,在两个指标上有平衡的表现。
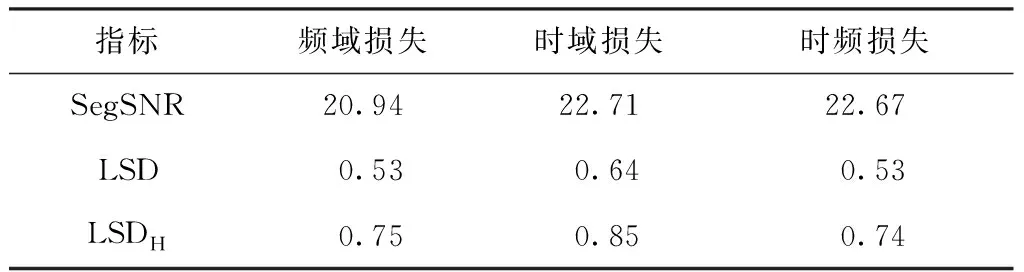
表4 损失函数消融实验结果
2.5 训练时间对比
文中频域算法的另一个优势是处理数据集时频域能够利用对称性减少数据量,训练速度更快,而时域算法不能减少数据集。为了保证测试的公平性,对AudioUnet和T-CNN进行了调整,以保证网络深度与文中算法一致。调整后均为55层,batch size均为256。时域算法AudioUnet和T-CNN产生了约21万条训练数据集,文中频域算法产生约10万条训练数据集。结果得到AudioUnet、T-CNN和文中算法的训练时间分别为379、420和221 s,可见文中算法训练速度更快。由此可知,理论上同样复杂度、深度的神经网络用在频域时,频域算法利用频域对称性减少数据集,训练速度更快。
3 结论
文中算法改进了目前频域流行算法F-GAN[17],借鉴了文献[15]的时频损失思路,使频域算法的输入和时域算法一致,频域算法能够应用时域算法里的网络模型,增强了频域算法的网络拓展性。它的编码器通过引入平铺层,实现时频两轴特征提取;频率轴数据处理时凑偶补零,以加深网络深度;它的损失函数引入了时域损失,充分利用了语音两域信息。实验结果表明,与当前的主流算法相比,文中算法生成的高带宽语音质量得到提高。文中算法依然存在频域方法人工相位谱不够精准的问题,接下来可以考虑用深度学习的方法对相位谱建模,以及引用更多的时域方法网络。
猜你喜欢
电声技术(2022年7期)2022-09-23
北京汽车(2021年2期)2021-05-07
语数外学习·高中版中旬(2021年12期)2021-03-09
花火彩版B(2020年5期)2020-09-10
语数外学习·高中版上旬(2020年8期)2020-09-10
科技视界(2020年24期)2020-08-26
科技视界(2020年22期)2020-08-14
振动工程学报(2019年2期)2019-05-13
速读·中旬(2017年8期)2017-09-04
新高考·高一数学(2016年10期)2017-07-06
