
多粒度融合嵌入的中文实体识别模型
2022-05-09 10:59章海波
小型微型计算机系统 2022年4期
袁 健,章海波
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
命名实体识别(Named-entity Recognition,NER)是自然语言处理中最核心的任务之一,是机器翻译、实体链接、信息提取等任务的基础和前提,其主要的任务是对文本中的人名、组织机构名、地名等专有名词进行识别提取并进行分类.命名实体识别的结果会对后续任务产生直接的影响,因此对其进行更进一步的研究是十分具有价值的.
早期对于命名实体识别任务的处理一般是基于规则和词典的方法,例如K.Humphreys等提出的LaSIE-II[1]系统和Collins等提出的DL-CoTrain方法[2].基于规则和词典的方法可解释性比较强,速度较快.但是其中的词典与规则的构建和维护任务繁重,规则在不同领域的移植性表现很差,因此,研究人员开始使用机器学习的方法来研究NER.
在机器学习中,常用的方法有隐马尔科夫模型(HMM)[3,4]、条件随机场(CRF)[5,6]、最大熵(ME)[7,8]、支持向量机(SVM)[9,10]等.但是这些传统的机器学习方法依赖于人工对特征的选取,将各种特征信息加入到特征向量中,特征选择的好坏会直接影响到最终模型的性能.
近年来,随着深度学习的兴起,各种基于深度学习的方法开始应用于命名实体识别中[11,12].Collobert等[13]于2011年提出了基于滑动窗口方法和基于句子方法的两种神经网络结构来进行实体识别,但是其不能考虑到长距离单词之间的信息.Zhiheng Huang等[14]最先使用BiLSTM+CRF结构来处理序列标注任务,用双向RNN代替了之前的NN/CNN结构,可以有效的结合过去的特征和未来的特征,考虑到长远的上下文特征信息,实验表明RNN+CRF结构在命名实体识别数据集中取得了更好的效果.RNN+CRF结构的深度学习方法也成为了目前最主流的模型之一.
中文语言博大精深,是世界上最主流的语言之一,因此中文命名实体识别也是命名实体识别任务中一个重要的组成部分.但是由于中文本身的特点,与英文命名实体识别有很大不同,中文的字的边界是确定的,词的边界是模糊的.而英文中每个词是由空格分隔开来.所以中文分词、语义信息等要素直接影响了最终中文命名实体识别的结果.在主流的RNN+CRF模型中,主要有基于词和基于字符的两种模式来进行中文实体识别.例如冯蕴天[15]提出了基于词特征的深度信念网络实体识别模型,首先对神经网络语言模型进行无监督训练来得到词语特征的分布式表示,然后将分布式的特征输入到深度信念网络中以发现词语的深层特征.冯艳红[16]利用基于上下文的词向量和基于字的词向量,并考虑词语的标签之间的约束关系,提出了一种基于BLSTM的命名实体识别方法.Chuanhai Dong等[17]提出了基于字符的中文命名实体识别模型,该模型将字符向量和部首向量结合起来对中文进行实体识别.但是,基于词或基于字符的中文实体识别方法有其局限性:1)基于字符方法中由于窗口大小的限制,使得语义信息获取不足;2)基于词方法中由于词边界模糊,更依赖中文分词的准确性.于是也有一些研究人员提出了混合嵌入向量模型,如殷章志等[18]提出了简单融合字词的命名实体识别模型,将字向量与词向量简单地连接在一起.
针对以上问题,本文结合汉字字形特征,对字词特征进行融合,提出了多粒度融合嵌入的中文命名实体识别模型(Grapheme-Char Word Embedding Chinese Named Entity Recognition Model,简称GCWE-NER模型).本文主要工作如下:
1)本文利用BERT[19]模型强大的语义表达能力获取中文字符向量,从而更好地表征字符的多义性;2)本文提出合并字形特征的增强字符信息算法,针对汉字属于象形文字的特点,利用改进的卷积神经网络提取汉字的字形特征,将得到的字形特征向量与通过BERT获得的字符特征向量拼接得到增强字符向量;3)本文提出多粒度融合嵌入算法,利用注意力机制将增强字符向量与词向量结合,以便更好地利用增强字符向量信息和词向量的语义信息,而且不会因为直接连接导致向量维度过高,可以有效减小模型计算的复杂性;4)本文针对中文实体识别提出了GCWE-NER模型,实验表明,GCWE-NER模型在实验中取得了较好的结果.
2 GCWE-NER模型
本文构建的GCWE-NER模型的结构如图1所示,该模型分为3层:输入层,语义编码层和标签解码层.
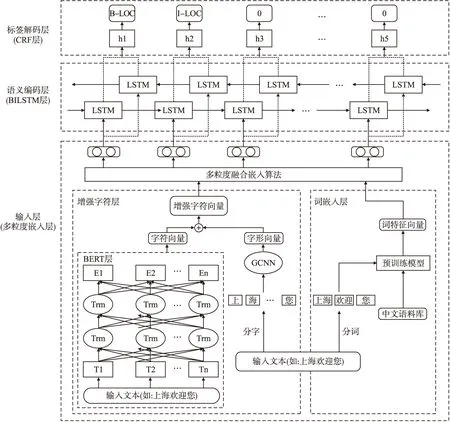
图1 GCWE-NER模型结构Fig.1 Structure of GCWE-NER model
首先在输入层,本文利用BERT模型获得输入语句中每个字的字符向量,然后通过改进的卷积神经网络GCNN对汉字图像提取生成字形向量,将字符向量与字形向量进行拼接得到增强字符向量.接着利用word2vec模型在百度百科语料库中进行预训练得到预训练模型,获取词特征向量,然后利用多粒度融合嵌入算法将增强字符向量与词特征向量有效地结合在一起.在语义编码层再将混合向量输入到双向LSTM神经网络中,经过前向训练和后向训练后,把两个训练获取的隐藏层向量拼接在一起,得到完整的隐状态序列.最后输入到标签解码层CRF模型中,通过动态规划算法得到最优预测结果.
2.1 输入层
2.1.1 合并字形特征的增强字符信息算法
1)字符向量获取
BERT[19]模型是一种强大的预训练模型,其核心部分是采用双向Transformer结构来抽取特征.Transformer是一种基于自注意力机制的深度神经网络,不仅可以获得更长的上下文信息,而且具备不错的并行计算能力,表义能力更强.本文选用BERT模型来获取中文字符向量,与其他语言模型相比,其优点是可以充分利用到单词上下文的信息,生成的字符向量更能表达多义性,包含更多的语义信息.
2)字形向量获取
汉字,起源于甲骨文,是世界上最为古老的象形文字之一,更偏向于图像信息而不是编码信息.在汉字的图形中通常蕴含着丰富的语义信息,一些学者通过提取汉字的特征来提升中文实体识别的效果.Dong[17]将汉字拆成了各个部首,如“朝”字拆成了“十”、“日”、“十”和“月”,对部首提取特征,与字符特征向量连接后进行中文实体识别,取得了不错的效果.不过这种方法也有一定的缺陷,例如“叶”和“古”可以拆成一样的部首,但是汉字意义却相差很大.这种方法忽视了汉字的整体结构性,汉字属于表意象形文字,字形相近的字含义也很接近,如“江”“河”,“草”“苗”等.因此可以利用卷积神经网络对汉字整体的字形特征进行提取,捕捉汉字中潜在的语义信息,字形相近的汉字得到的字形特征向量余弦相似度会更大.通过将字形向量作为特征之一,可以提升模型效果.
卷积神经网络(convolutional neural network,CNN)[20]是一种前馈神经网络,包含了卷积层,池化层与全连接层,可以通过多个卷积核对图像特征进行自动提取,具备稀疏连接与参数共享的特点,被广泛应用于计算机视觉领域.本文在VGGNet的基础上进行改进,提出了GCNN网络.GCNN网络如图2所示,其中f表示过滤器数目,k表示过滤器大小,s表示步长,g_s表示每层输出的维度大小.GCNN网络使用的汉字图收集于新华字典,数量为8630.GCNN网络先将汉字图渲染为32×32的灰度图像输入,利用多组卷积核大小为3×3,步长为1的二维卷积和最大池化提取到中文汉字的128维字形向量gemb.同时,为了减少过拟合化,在训练中还加入了图像分类损失函数.利用GCNN网络对汉字图像x提取特征得到字形特征向量gemb后,直接送去预测它属于哪个中文.如果x相对应的中文标签是z,W为权重矩阵,那么图像分类损失函数为:
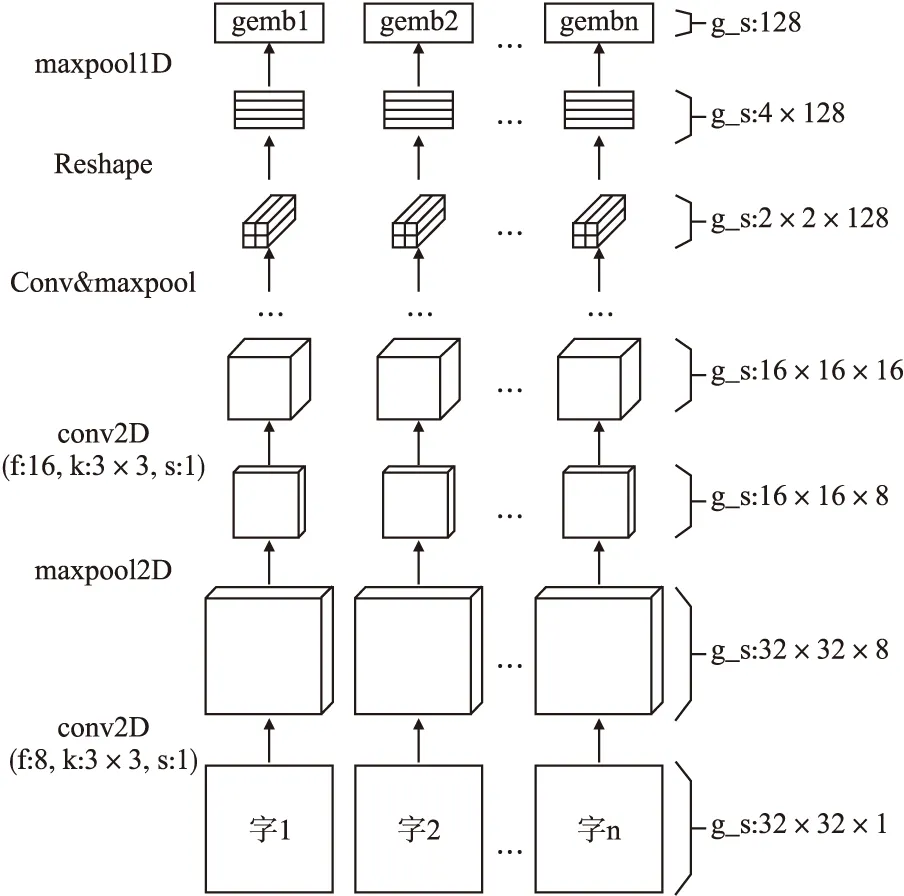
图2 GCNN网络Fig.2 GCNN net
L(cls)=-logp(z|x)=-logsoftmax(W×gemb)
(1)
3)合并字形特征的增强字符信息算法
本文结合GCNN网络和BERT模型提出了合并字形特征的增强字符信息算法,算法结构如图3所示.
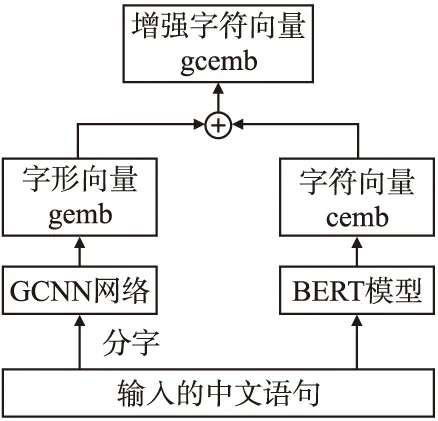
图3 合并字形特征的增强字符信息算法Fig.3 Enhanced character information of merging glyph features algorithm
算法描述如下:
算法1.合并字形特征的增强字符信息算法
输入:中文语句文本
输出:合并字形特征的增强字符向量
算法步骤:
Step 1.将输入的中文语句分为一个个汉字,输入到GCNN网络中,经过卷积和最大池化后得到128维字形特征向量gemb.
Step 2.将中文语句输入到BERT模型中,经过双向Transformer结构,得到字符特征向量cemb,向量维度为768维.
Step 3.将字形特征向量gemb与字符特征向量cemb拼接得到合并字形特征的增强字符向量gcemb,向量维度为896维,
gcemb=gembconcatcemb
(2)
2.1.2 多粒度融合嵌入算法
注意力机制(attention mechanism,简称attention),最先源于研究人员对图像领域的研究,后来研究人员把注意力机制引入到了机器翻译任务中,计算高效并且效果显著,于是开始有许多自然语言处理的工作开始把attention作为提升模型性能的一个重要组成模块.注意力机制主要分为两步:1)计算所有输入信息的注意力权值分布;2)通过注意力权值分布对输入信息进行加权平均.
在注意力机制的启发下,本文结合Raffel提出的Feed-Forward Attention[21],提出了多粒度融合嵌入算法,算法结构如图4所示.
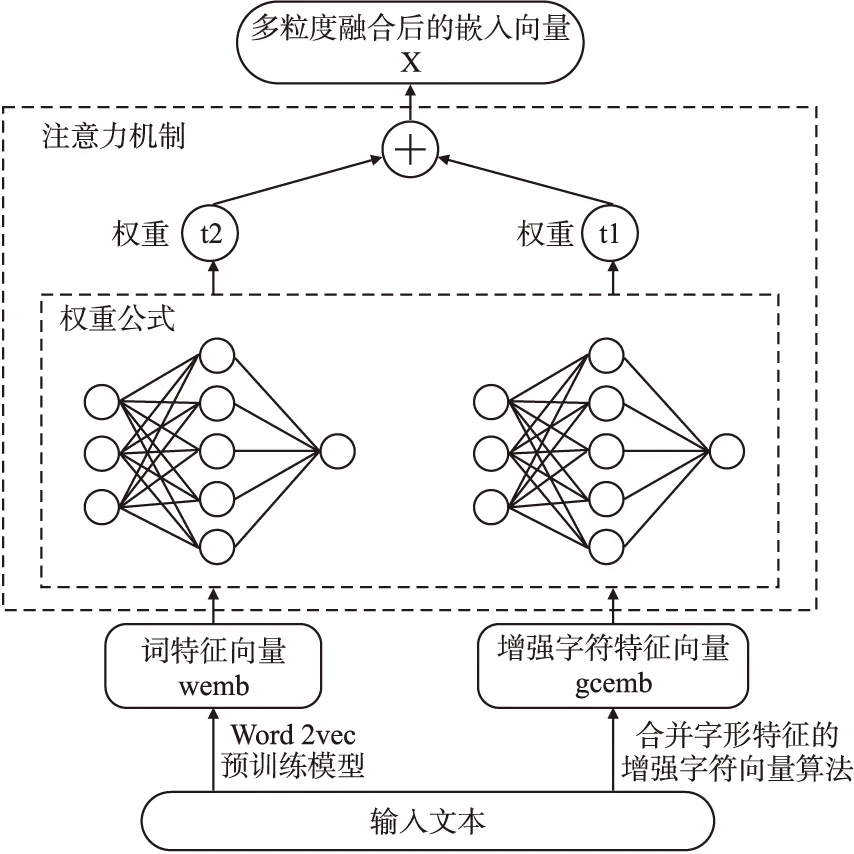
图4 多粒度融合嵌入算法Fig.4 Attention weight model
算法描述如下:
算法2.多粒度融合嵌入算法
输入:中文文本
输出:多粒度融合后的嵌入特征向量
算法步骤:
Step 1.输入中文文本,通过Word2vec预训练模型获取到词特征向量wemb,同时通过合并字形特征的增强字符向量算法获取到增强字符特征向量gcemb.
Step 2.将增强字符特征向量gcemb和词特征向量wemb输入到权重公式中,计算gcemb的权重t1和wemb的权重t2,
(3)
(4)
其中σ是logistic函数,W1,W2表示权值矩阵,b1和b2是可学习向量.
Step 3.将增强字符特征向量gcemb与词特征向量wemb按各自权重融合,计算得到混合嵌入向量x:
x=t1×gcemb+t2×wemb
(5)
利用注意力机制的多粒度融合嵌入算法可以动态调整增强字符向量gcemb与词向量wemb的使用比例,能够更好地结合字符信息,字形信息与词信息.而且对于以往向量与向量拼接而造成的维度增大问题,本文提出的基于注意力机制的多粒度融合嵌入算法不会造成维度过高,减轻了模型计算的复杂性,提高了运算效率.
2.2 语义编码层
循环神经网络(RNN)[22]是一种包含循环的神经网络,在理论上可以解决长期依赖问题,但是在实际操作中由于梯度在反向传播中不停连乘,会造成梯度爆炸和梯度消失,学习不到历史信息.
为了解决长期依赖问题,本文选用一种特殊的RNN网络——长短期记忆网络(Long Short Term Memory networks,LSTM)[14].通过前向与后向LSTM来计算上文与下文所含的隐藏信息,最终共同构成最后的输出.
2.3 标签解码层
在传统机器学习中,在标签解码阶段一般会选用Softmax多分类器来处理多分类的问题,但是Softmax在处理具有较强依存关系的序列标签时,输出相互独立,未考虑到相邻标签之间存在的关系,效果是有限的.例如,在BIO序列标注方式下,预测句子的第一个词一般是标签“O”或者“B”,而不是标签“I”,“B-Person”标签后可能会是“I-Persion”,而不会是“I-Organization”等错误标签.
为了避免上述的问题,论文采用条件随机场(CRF)[14]让它自己来学习这些约束条件,进而对BiLSTM的输出进行更好的解码,模型在解码时使用Viterbi算法来求解最优路径.
3 实 验
3.1 实验数据
本文使用的实验数据集来自于1998年《人民日报》的标注语料,这是由北京大学和富士通公司一起标注的语料,是中文自然语言处理中经典的标注语料.本文选用实验数据的80%作为训练集,剩余20%作为测试集,对数据中的人名,地名和组织机构名进行识别.
标注方式采用BIO标注模式,其中B表示实体最开始的部分,I表示实体开始部分以外的剩余部分,O表示不是实体的部分,例如B-LOC表示地名最开始的部分,I-LOC表示地名的剩余部分.PER,LOC,ORG分别代表人名,地名和组织机构名,故3种实体类型总共有6种标签,加上不是实体的O标签总共有7种标签.
3.2 实验设置
本文的模型实验基于Tensorflow深度学习框架,字符向量获取基于BERT-base模型,共12层,隐层为768维,采用12头注意力机制模式,词向量获取基于word2vec模型CBOW模式,上下文窗口设定为5,初始学习率设定为0.015,BiLSTM的初始学习率设定为0.001,batch_size设置为128,epoch设为40,模型采用随机梯度下降法来进行参数的优化,为了防止模型出现过拟合现象,使用dropout正则化方法,参数值设为0.5,为了在实验中防止出现梯度爆炸的现象,本文使用梯度截断法,并让参数值设定为5.对于模型实体识别的结果,本文采用精确率P(Precision)、召回率R(Recall)和F1值(F1-Score)3个指标来衡量,公式如下:
(6)
(7)
(8)
3.3 实验结果与分析
3.3.1 GCWE-NER有效性实验
为了验证GCWE-NER模型的有效性,本文在输入层分别采用字符向量char输入,词向量word输入,字词向量结合char+word输入和多粒度融合嵌入方式GCWE-NER输入,在编码层与解码层分别使用双向LSTM神经网络和条件随机场模型,结果如表1所示.
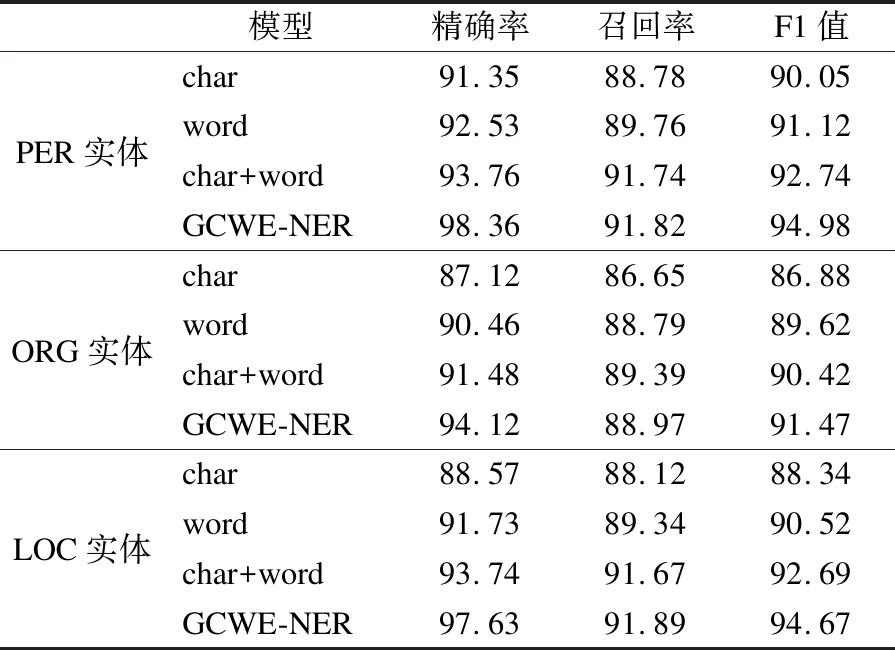
表1 有效性实验结果Table 1 Result of effectiveness experimental
从实验结果中可以看出,对于中文命名实体识别单一向量嵌入方式来说,基于词向量word的输入方式比基于字符向量char的输入方式识别效果更好,这是因为词向量与字符向量相比,词向量包含了更丰富的上下文语义信息.与单一向量嵌入方式相比,混合向量嵌入效果更好,例如字词融合的混合向量嵌入方式char+word取得了比单一向量嵌入更好的结果.在混合向量嵌入基础上,本文提出的GCWE-NER模型在实验中取得了更好的成绩,验证了模型的有效性.另外,在对于3种实体的识别中,实验发现对于人名和地名的识别效果较好,机构名的识别效果相对较差,这是由于机构名有些由多个词嵌套构成,识别相对来说比较困难.
3.3.2 GCWE-NER优越性实验
与他人的中文命名实体识别模型进行对比,GCWE-NER模型也表现了较好的优越性,实验对比结果如表2所示.
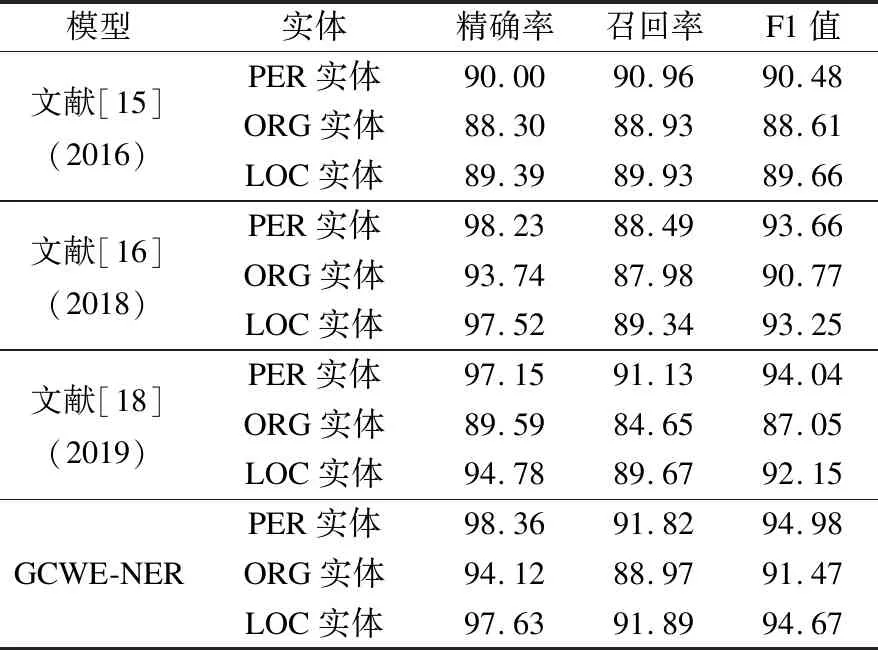
表2 优越性实验结果Table 2 Result of superiority experimental
文献[15]使用了深度信念网络,在大量无标注语料中无监督地训练语言模型,得到词性特征与词特征各自的分布式表示,再输入到构建的深度信念网络中,最后构建的6层网络架构,对于人名,机构组织名和地名识别的F1分值分别为90.48%,88.61%和89.66%.文献[16]利用基于上下文的词向量和基于字的词向量,前者表达命名实体的上下文信息,后者表达构成命名实体的前缀、后缀和领域信息,同时考虑词语的标签之间的约束关系,最终对于人名,机构组织名和地名识别的F1分值分别达到了93.66%,90.77%和93.25%.文献[18]在基于BiLSTM-CRF模型上,使用SVM对字词特征进行融合,最后在人名,机构组织名和地名识别的F1分值分别达到了94.04%,87.05%和92.15%.实验结果显示,与他人方法相比,GCWE-NER模型的识别效果均有一定程度的提升,与文献[18]将字向量与词向量直接拼接在一起相比较,GCWE-NER模型也取得了更好的成绩.与各模型对于人名,组织名和地名最好的实体识别结果F1值相比,GCWE-NER分别提升了0.94%,0.7%和1.42%.实验结果表明,GCWE-NER模型与他人中文实体识别模型相比更具有优越性.
4 结束语
在自然语言处理领域中,中文命名实体识别是最重要的基础任务之一.本文提出的GCWE-NER模型,首先利用GCNN网络提取汉字的字形特征,与字符向量拼接得到增强字符向量;再利用注意力机制,将词向量与增强字符向量以各自的权重动态地结合在一起,以此作为混合向量输入到BiLSTM网络中,有效地利用了中文的字形信息,字符信息和词向量的语义信息,并且不会造成向量维度过高,降低模型计算的复杂性.而且GCWE-NER模型也结合了双向长短时记忆网络捕捉上下文语义信息的能力,同时也保留了通过条件随机场模型来推理标签的能力,在1998年《人民日报》的标注语料实验上验证了其有效性和优越性.
中文嵌套实体识别的研究现在仍具有挑战性,在接下来的工作中将继续研究对于嵌套实体识别效果的提升.
猜你喜欢
中学生理科应试(2021年11期)2021-12-09
电脑报(2021年41期)2021-11-04
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
小猕猴学习画刊·下半月(2019年3期)2019-06-11
数学学习与研究(2018年15期)2018-11-12
电脑知识与技术(2016年22期)2016-10-31
小学阅读指南·低年级版(2016年5期)2016-05-14
初中生之友·中旬刊(2015年5期)2015-06-15
农机使用与维修(2014年10期)2014-10-23
