
基于ReInspect算法的多目标追踪
2022-05-26 02:29王文远金晅宏宋文净王轶炜
计量学报 2022年4期
王文远, 金晅宏, 宋文净, 王轶炜
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
随着人口数量以及其流动性的增加,人群密集现象越来越常见,这就对治理公共空间和社会安全提出了巨大的挑战。智能视频监控系统在该领域包含丰富的内容及算法,人群场景分析在现实生活中存在巨大的应用价值,近年来吸引了大量研究者的关注[1~6]。人群密度高、模式变化快、场景中存在着巨大的遮挡等使得传统视频监控技术不能直接应用于人群场景[1,2]。传统的目标检测方法如背景模型的建立[7]、Kalman滤波[8]、混合相关滤波[9]、ViBe算法[10]等检测效率较低,准确率也低。目前应用广泛的机器学习算法[10]和深度学习算法如OverFeat算法[11]、Faster R-CNN(Regions with CNN featrutes)算法[12],能够达到较高的检测精度。OverFeat算法使用深度卷积网络一次完成分类、定位和检测这3个机器视觉任务,对单个网格产生的卷积特征使用分类器判断目标类别以及预测位置信息。Faster R-CNN算法利用深度卷积神经网络进行图像检测的算法,该方法使用CNN生成卷积网络特征图,并从卷积特征图中使用全连接层提取特征用于类别分类和位置预测,使用多尺度的锚点窗口融合网格卷积特征检测不同尺度与长宽比的图像目标。但OverFeat和Faster R-CNN算法都要通过置信度结果进行比对、移除。当检测目标存在遮挡时,极可能会移除掉被遮挡目标。若调整重叠面积判断参数,则又可能出现大量的重复检测结果[13~15]。
为解决上述问题,本文提出了基于ReInspect算法多目标追踪方法,通过利用LSTM网络的记忆特性,有效解决了遮挡问题;不仅检测精度比传统方法高,且能有效解决重叠、遮挡等问题。通过对不同场景下针对多个运动目标进行捕获处理,证明算法具有较高的可靠性;同时对比传统的多目标追踪算法,证明了该算法具有更好的处理效果。
2 基于ReInspect的多目标检测
在OverFeat算法的基础上使用LSTM网络[13]能够极大地提高对遮挡目标的检测效果。这使得一个网格卷积特征能够被复用,并产生多个序列特征来表征在图像中被遮挡的目标。ReInspect算法就是一种基于CNN与LSTM相结合的遮挡目标检测算法[16~19]。具体算法框图如图1所示。

图1 ReInspect算法框图
ReInspect算法与OverFeat算法在整体流程上基本是一致的,二者的区别在于是否使用了LSTM神经网络结构和对应损失函数的预处理操作[16~19]。ReInspect算法采用LSTM网络结构对同一网络生成特征序列表示遮挡目标。假设LSTM网络产生的m个特征序列,对应的原始图像标记有n个目标真值。则在训练过程中,m个样本序列对应的目标类型将根据m个样本的预测结果与n个目标真值进行相似匹配产生。匹配目标类型的最大数量为min(m,n),而没有匹配的特征序列将标记为负样本类型,对应的坐标位置填0。另外,ReInspect算法还采用了一种特殊的损失函数预处理方式。这种处理每次进行操作后只会移除一个重叠检测结果。这种操作能够确保同一网格卷积特征产生的重叠目标不会被认为是重复检测而被错误移除。
2.1 LSTM高层网络结构
ReInspect算法在GoogLeNet网络[20]的基础上加入LSTM循环网络结构抽取特征值[16~19]。而LSTMs能够学习长期依赖关系[21]。
若网络存在被遮挡的目标,ReInspect算法期望能够利用LSTM网络的记忆特性对被遮挡的目标做进一步的判断检测。理论上叠加的次数越多,越能概括更复杂的图像遮挡情况,但需要的样本也越多[21]。
在ReInspect算法中一个网络特征最多能够产生rnn_len个目标检测结果,这就使ReInspect在训练时向前传播,单个网络将会返回多个特征和多个类型标签。在计算损失函数前,ReInspect算法需要将序列特征值的预测结果与真值进行匹配,再对序列样本赋予类别标签计算损失函数[22]。所以在损失函数的计算前,有必要对样本序列的排列次序进行调整。这项操作称为损失函数预处理。
2.2 损失函数预处理
通过调整循环LSTM网络结构产出特征的标签信息,能够确保特征序列正确反映遮挡检测目标。当循环LSTM网络的循环次数为m时,每一个网络将产生m对特征样本和标签信息组成的序列。若网络对应存在n个遮挡目标时,前n个网络特征序列对应的具体真值信息是没有逻辑关联的。ReInspect算法使用匈牙利算法[23]完成前n个特征序列与真值间的匹配,即希望训练时,前n个特征序列的预测结果与真值的总体加权匹配损失是最小的。
匹配距离计算方法如式(1)所示。
(1)
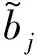
如图2所示的匹配问题,其中2个虚线框表示目标真值,标有序号的实线方框代表网络产生的4个预测结果。预测3与2个真值都没有重叠区域,所以有oij=1,直接剔除;预测1、2和4与真值的重叠区域都大于阈值,而预测1和预测2相比序列号为1优先匹配,因此预测1和预测4与真值匹配成功。
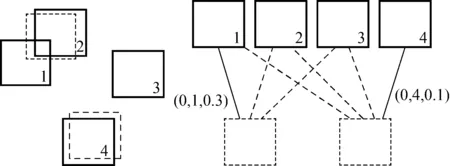
图2 检测结果匹配预处理示意图
2.3 损失函数
图像检测算法需要大量的训练图像,通过损失函数计算的反向传播梯度实现模型参数优化,并最终训练得到检测模型。损失函数如式(2)所示。
(2)
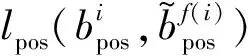
(3)
(4)
2.4 追踪后处理结果
ReInspect算法使用循环LSTM网络结构令单个网络单元产生多个序列特征值,并以此特征序列对遮挡目标进行检测。然后,相邻的网格特征因感知区域范围存在重叠部分,若两重叠检测结果来自相同网络,则同时保留。若两重叠检测结果来自不同网络,则移除可信度较小的检测结果。
另外,考虑到一个检测结果可能会与多个不同网格的检测结果重复,检测后处理方法再一次使用了匈牙利算法,实现了不同网格重复检测结果的移除。由于同一目标可能出现多次重复检测,后处理算法采用了置信度分段的方式对检测结果进行了多次匹配移除。
3 实验与分析
基于ReInspect算法的目标追踪框架如图3所示。
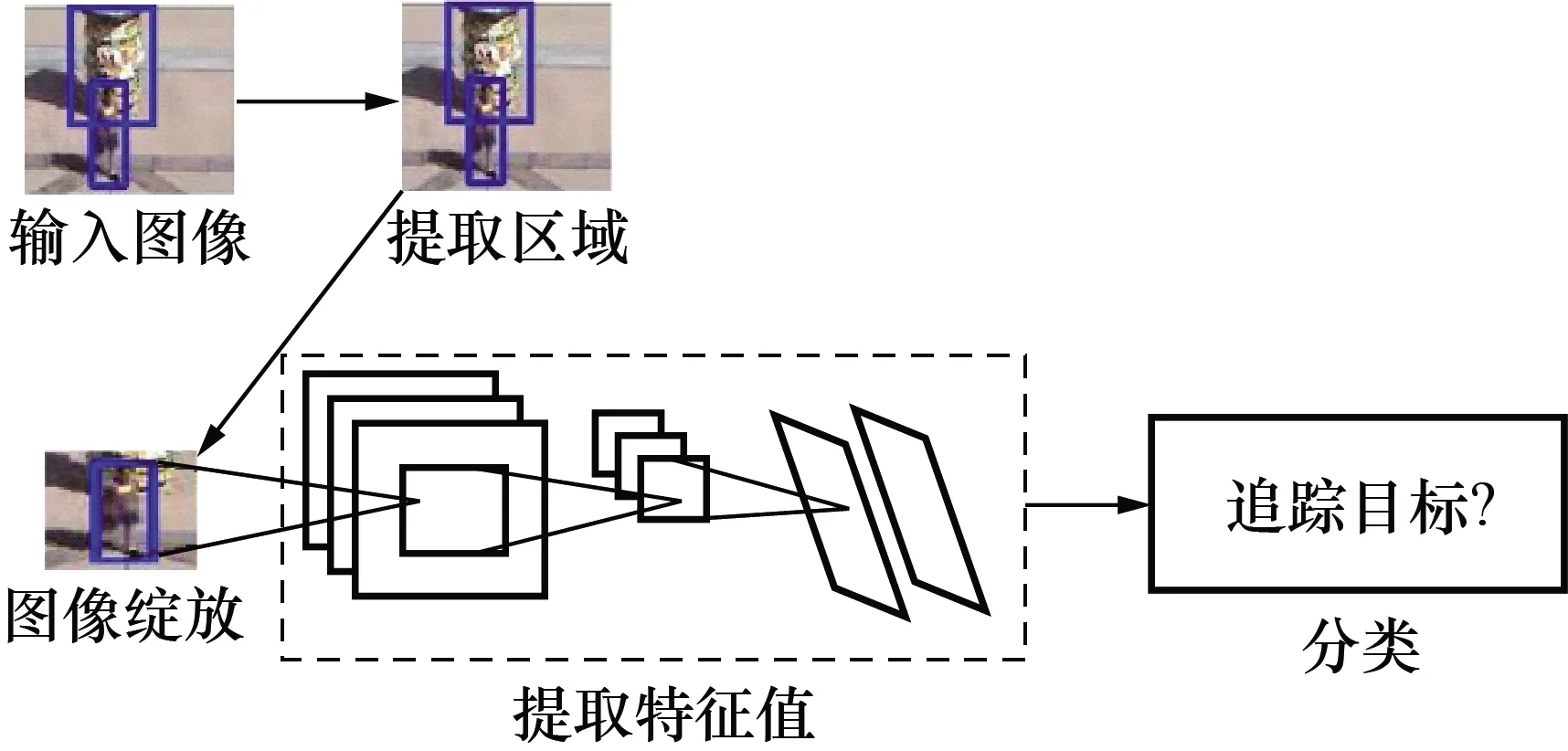
图3 基于ReInspect算法的多目标追踪框架
本文实验使用平台为Ubuntu 18.04操作系统,内存为16 GB,并使用显存为6 GB的NVIDIA GeForce RTX 2060显卡进行加速。本实验所使用的训练数据集为NICTA行人数据库,该数据库是目前规模较大的静态图像行人数据库, 25 551张含单人的图片, 5 207张高分辨率非行人图片。
实验测试数据集使用UCSD Ped数据集,该数据集由加州大学圣地亚哥分校提供。分别使用背景减除算法、ViBe算法、机器学习算法(HOG特征值+SVM训练)和本文算法对测试数据中的人型目标进行追踪。
实验从测试数据集中随机抽取场景1中的第300帧,各算法处理后结果如图4所示,追踪效果如表1所示。
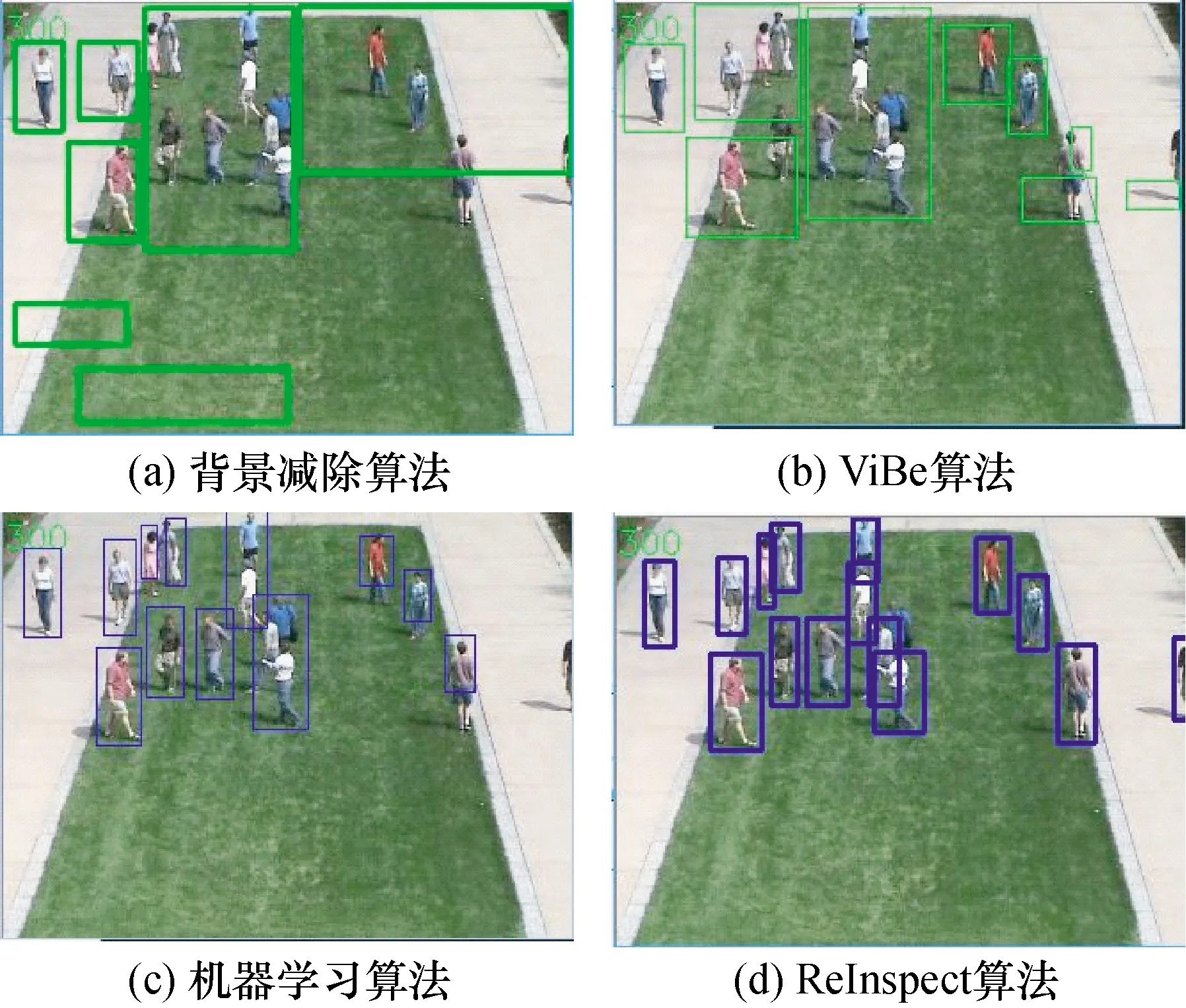
图4 场景1第300帧各算法处理效果图

表1 场景1第300帧追踪结果对比
由图4及表1可以看出,在人群密集、人与人之间出现重叠的情况下,传统的背景减除法和Vibe算法已经不能正确检测出单个的人,甚至会将地面上的阴影误检成一个人,准确率只有18.75%和31.25%,而机器学习算法虽然识别准确率显著提高,但是对于重叠和边缘的人群依然无法检测出。本文提出的算法不仅能够将重叠的行人明确检测出,还能区别地面上的阴影,效果远好于传统算法。
然后随机抽取场景3中的第6 500帧,各算法处理后结果如图5所示,追踪效果如表2所示。
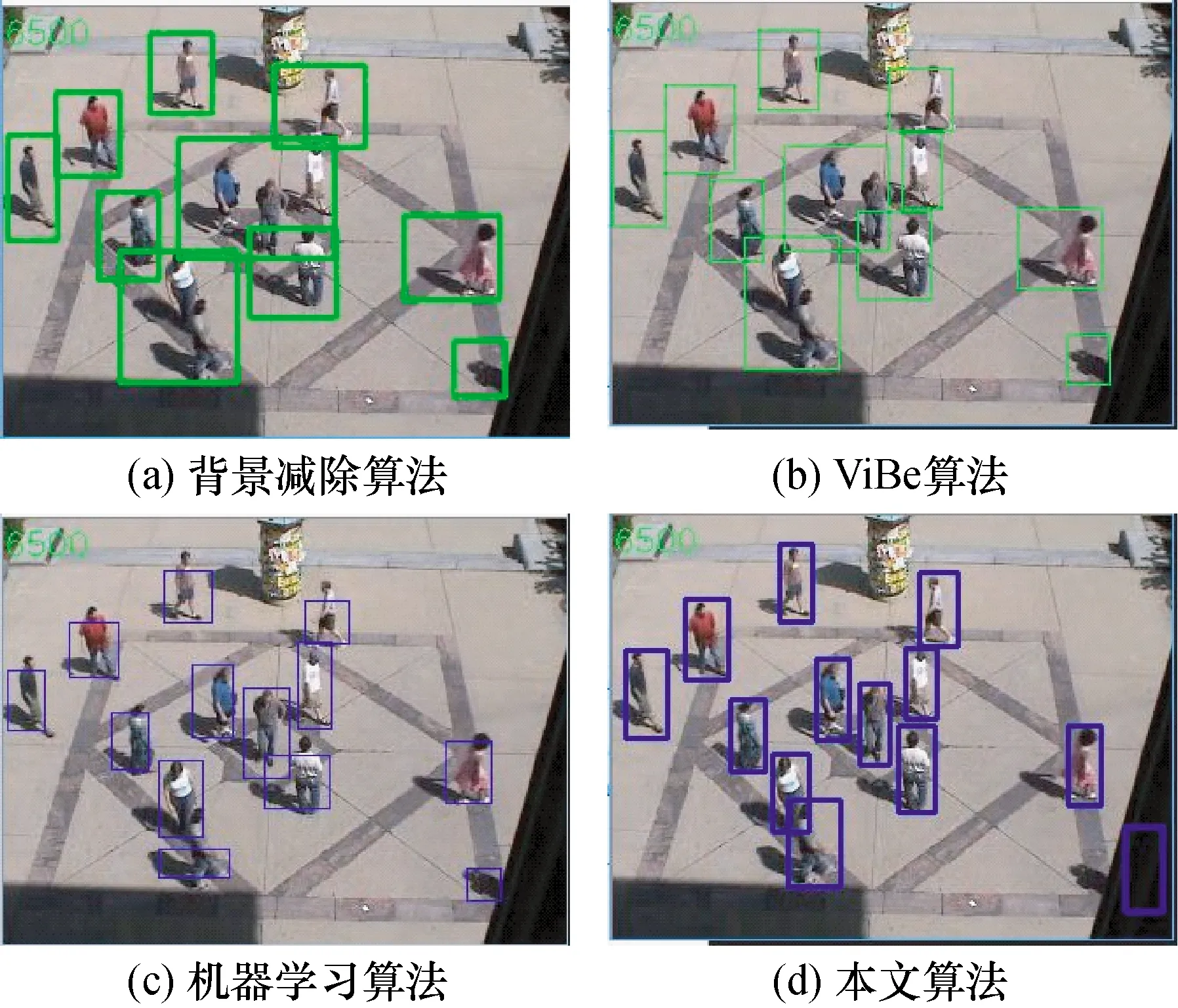
图5 场景3第6 500帧各算法处理效果图
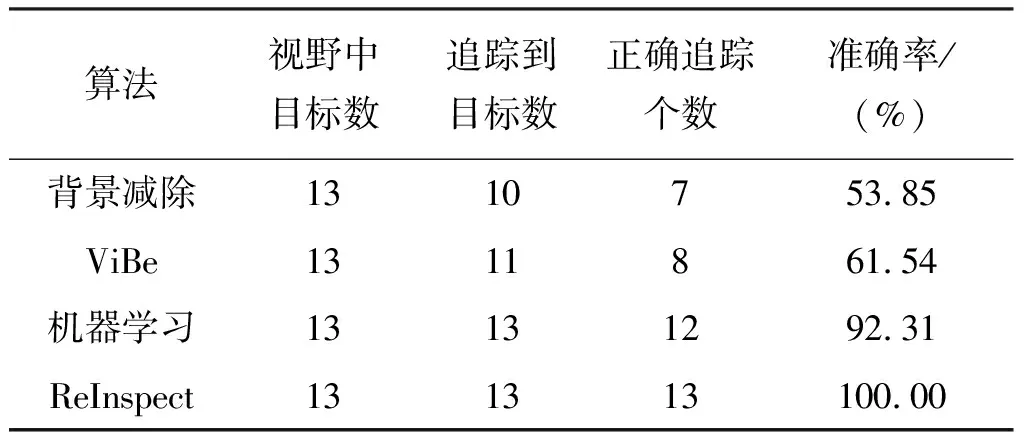
表2 场景3第6 500帧追踪结果对比
从实验结果看,当出现阴影遮挡情况的时候,背景减除算法、ViBe算法准确率都不高,机器学习算法虽然准确率为92.03%,但对于被遮挡的人也检测不出。而本文算法最显著的效果就是能将完全被阴影遮住的人检测出。
4 结 语
本文提出了一种基于深度学习的对多目标进行有效追踪的方法。从目标识别入手,首先将视频转化为图片形式,通过ReInspect算法将行人从图像中标出,判断图片中追踪物体是不是人并进行追踪。理论上,如果训练使用的样本库足够大,神经卷积网络的迭代次数足够多,实验可以达到准确率100%目标检测与追踪结果,尤其是能检测出被阴影覆盖或被人群遮挡的目标。虽然本方法具有较高的追踪准确性,但是处理时间上的消耗巨大,无法在一般环境下(无GPU加速的情况)处理正常视频流。因此,如何在保证高可靠性前提下尽量提高运算的处理速度,将是本课题进一步研究的重点。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
锦绣·下旬刊(2019年3期)2019-09-10
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
现代交际(2018年14期)2018-11-01
北京航空航天大学学报(2018年1期)2018-04-20
电子制作(2017年1期)2017-05-17
