
融合学习过程特征的深度知识追踪方法
2022-06-01 09:49
浙江工业大学学报 2022年3期
(浙江工业大学 教育科学与技术学院,浙江 杭州 310023)
随着人工智能技术的飞速发展,在线学习进入领域垂直细分、方式丰富多样、资源开放共享以及内容供给智能的全新时代。个性化的在线学习关注学生的认知水平、学习表现等特征,旨在搭建智能化、个性化的教育平台,科学有效地对学生的知识掌握状态进行追踪,挖掘学生知识薄弱点,为学生制定个性化学习的路径。在知识掌握状态不断更新的过程中,知识追踪(Knowledge tracing,KT)根据学习者学习表现、认知风格等进行建模[1]。随着在线教育的发展,运用智能技术处理大规模数据成为必然趋势,优化算法预测学习偏好,借助深度学习跟踪动态人脸,获取用户表现等成为近年来热点研究问题[2-4]。基于神经网络的深度学习是可以有效提升知识追踪预测精度的重要工具。基于深度学习的知识追踪能够处理学习过程中动态和静态的学习者多维度特征,借助记录当前学习者状态和知识点关系形成记忆网络。基于深度学习的知识追踪模型与记忆矩阵模拟学习者的整个学习过程,学习者可以沉浸于实时监督的学习训练中,因此深度学习成为个性化在线学习中知识追踪的重要工具。笔者利用在线学习过程中的多维特征,基于学习过程答题交互进行建模,结合人工智能技术以优化深度知识追踪方法,探索和解决在线学习领域知识追踪技术难题,以期提升在线学习者学习效率。
1 知识追踪方法概述
知识追踪技术是根据学习者历史的答题情况对学习者的知识掌握情况进行建模,从而得到学习者当前的知识状态。Ai等[5]首先提出此概念,并将知识追踪描述成一个时序建模问题,以预测学习者未来的学习表现[6]。知识追踪形式化描述:根据学习者在学习活动中的答题历史记录Xt={x1,x2,…,xt},预测该学习者在下一次答题xt+1的表现,其中xt={qt,at},表示学习者在t时刻回答问题qt的结果为at。为了实现对学习者知识状态的精确分析,许多技术正被广泛应用于知识追踪研究领域,主要分为基于概率图的知识追踪方法和基于深度学习的知识追踪方法。
1.1 基于概率图的知识追踪方法
基于概率图的知识追踪方法需要手工标注学习过程中的各项参数再进行模型训练,典型的应用方法有:贝叶斯知识追踪(Bayesian knowledge tracing,BKT)、基于Rasch模型扩展的性能因素分析(Performance factors analysis,PFA)以及学习因素分析(Learning factors analysis,LFA)等。BKT模型将学习者知识状态建模为一组二元变量,变量一为学习状态是潜变量,变量二为答题结果是观察变量[7]。
BKT模型没有考虑学习者遗忘因素、知识之间的关系等问题,因此预测精度不高。为提升BKT模型的预测性能,有学者将知识层级关系、学习者先验知识估计以及题目难度估计等多维特征因素融入到BKT模型中[8],如李晓光等[9]融合学习过程中的众多特征优化了BKT模型;叶艳伟等[10]探究了学生遗忘因素和数据量对BKT模型预测的影响;Kaser等[11]利用动态贝叶斯网络将知识点进行关联提高了预测精度。而PFA和LFA方法利用动态概率模型并根据学习者的题目作答情况进行知识追踪,不断更新学习者对每个知识概念的掌握程度[12]。PFA和LFA都是评估多知识点的模型,能较好地解决多知识点追踪问题,但未考虑学习者知识状态是动态变化的,因此预测精度也较低。整体上,基于概率图的知识追踪方法都需要手动标注知识点,预测精度依赖教学者的先验教学经验,精准获取学习者知识状态的自动化程度较低。为了提高知识追踪性能,研究者通过结合概率图和认知诊断技术的方法提升预测精度[13]。其中项目反应理论(Item response theory,IRT)是最常见的练习测验认知诊断技术,该理论基于学生的能力水平θ和项目的难度水平βj,输出学生正确回答问题j的概率P(a),概率由一个项目反应函数来定义,通过习题难度来评估学习者对知识点的掌握能力。
1.2 基于深度学习的知识追踪方法
基于深度学习的知识追踪(Deep knowledge tracing,DKT)不需要丰富的先验教学经验和大量手工标记,便可以对学习者知识状态进行建模,其对学习者的知识追踪效果已被证明优于传统知识追踪方法,因此已成为主流的知识追踪方法[14]。
DKT使用独热编码方式将学习者的答题交互历史(qt,at)转换成固定长度的输入向量xt,转换后将xt传递到隐藏层,并使用长短期记忆(Long short-term memory,LSTM)单元计算隐藏状态ht,隐藏层包含了学习者学习过程中所有答题信息,因此隐藏层可以理解为学习者的知识状态层。进而,这个知识状态被传递到输出层以计算输出向量yt,yt表示正确回答下一道题目的概率,由于DKT得到的所有知识状态信息都储存在隐藏层中,所以教学者难以获得学习者的知识状态具体信息。Zhang等[15]提出了利用动态键值存储网络(Dynamic key-value memory networks,DKVMN)来解决上述两个问题,并取得了较好的效果,DKVMN利用记忆增强神经网络中的注意机制,将知识点(静态键记忆)与知识状态(动态键记忆)相关联,进而通过计算题目的知识点构成和知识状态向量来计算知识状态,其中动态键记忆矩阵随着学习者答题交互不断更新;Ai等[5]指出DKVMN模型不仅可以避免过度拟合,而且能精确地发现输入题目的知识构成。也有学者通过将DKT技术与其他技术相结合来提高知识追踪的性能,如马骁睿等[16]通过结合协同过滤算法重复利用学习者之间的特征信息,提出DKT-CF方法提高知识追踪预测精度;Wang等[17]利用题目之间的特征关系和知识点的联通关系设计了DKTS方法,有效地提升了知识追踪方法的服务性能。
由于在线学习过程通常是学习者经过系列学习操作再进行答题,而当前知识追踪研究忽略学习过程,仅对答题交互进行建模,缺乏对知识追踪模型训练要素的深入研究,预测精度和可解释性仍有进一步提升的空间。笔者尝试使用特征选择算法确定知识追踪模型最佳特征集,在深度知识追踪模型中融合学习过程动态和静态的多维特征,来兼顾知识追踪模型优化的预测精度和可解释性,提出融合学习过程多维特征的知识追踪优化方法。
2 问题描述与方法框架
2.1 问题描述
知识追踪是根据学习者的历史学习轨迹自动追踪知识状态的变化,预测学习者在未来学习过程中知识点掌握情况。笔者的知识追踪模型将学习者一次答题交互描述为Ri={si,qi,ri,bi},其中bi为学习行为序列,且提出的模型考虑学习者静态特征和题目特征对学习者答题的影响。由于考虑的特征维度较多,需要知识追踪方法能够挖掘学习平台收集的历史学习数据,并进行有效地分析和处理,具体如图1所示。图1中,输入层作为知识追踪的基础,包括学习者的学习行为序列、题目特征以及学习者静态特征信息,在该层中对学习过程描述是否准确直接影响预测精度;隐藏层则是知识追踪模型训练的过程,即学习者知识状态更新过程,其通常难以被读取,因此该层构造的合理与否决定了知识状态能否被实时输出并应用到实际教学活动中;输出层是计算出学习者答题正确的概率即知识状态,输出的结果与学习者实际答题结果一致性越高,则说明知识追踪服务性能越好。

图1 知识追踪问题描述Fig.1 Knowledge tracking problem description
2.2 融合学习过程多维特征的深度知识追踪方法框架
融合学习过程多维特征的知识追踪方法包括数据组成、知识追踪优化方法论和知识追踪模型3部分,如图2所示。数据可简单理解为由答题历史和其他数据两部分组成;知识追踪优化方法论包含了数据挖掘方法和对深度知识追踪模型的改进方法,从挖掘多维特征和特征融合两方面进行模型优化,提高模型的可解释性和预测精度;知识追踪模型,主要是在动态键值对网络模型的基础上进行优化,来保证所提方法的服务性能、可读性以及可解释性。
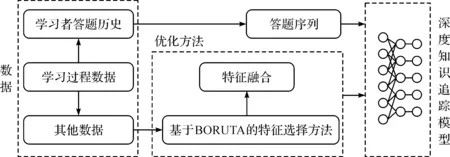
图2 融合学习过程特征的知识追踪框架Fig.2 Knowledge tracking framework incorporating learning process features
3 深度知识追踪模型优化设计
3.1 Post-hoc视角下学习过程特征选择方法
深度知识追踪与其他机器学习模型均存在可解性弱的问题,Lu等[18]指出可解释性可以分为Ante-hoc和Post-hoc两种视角。由于学习过程的复杂性,大多采用Post-hoc的角度进行可解释性分析。该方法基于已有研究和在线学习平台多元化数据属性的特征,以Post-hoc全局解释为视角,从学习过程众多特征中探寻影响学习结果的多维特征[19],并利用特征选择模型去除冗余特征以完成模型的输入组成,为知识状态解释提供数据分析支撑,简称BORUTA特征选择方法。
为了从数据集中挖掘出相关性强的特征和数据,通过BORUTA特征选择方法来实现此目标,BORUTA特征选择方法过程如图3所示[20]。在BORUTA特征选择方法中,为保证特征筛选的可靠性,首先将原始特征顺序打乱以增加随机性,打乱后的特征集(阴影特征)作为新特征添加到数据集中;然后使用随机森林评估每一个特征的重要性,在算法每次迭代时都会计算真实特征是否比阴影特征具有更高的重要性,以剔除无关特征;最后当所有特征得到标记重要或不重要,或算法达到随机森林运行的规定阈值,算法终止。设计Post-hoc视角下BORUTA特征选择方法挖掘出与学习结果相关度大的候选特征不仅可以减少深度学习训练的工作量,而且为模型的可解释性提供了有效保障。在线学习数据中既包含了学习者静态特征数据,也涵盖了资源数据和其它学习过程历史数据,因此数据集中会存在许多无关特征。所以在实际数据处理的过程中还需要对数据进行清洗,使模型的预测效果更加准确和高效。

图3 BORUTA特征选择方法Fig.3 BORUTA feature selection method
3.2 融合学习过程多维特征的深度知识追踪模型设计
由于DKVMN有良好的拓展性,核心研究工作是在DKVMN模型基础上进行优化设计。将处理过的数据作为模型的输入和输出,在模型的输出位置构建学习行为序列特征网络、学习者静态特征网络以及题目特征网络,将优化方法融入DKVMN框架中,提出了深度知识追踪优化方法DKVMN-BORUTA,具体如图4所示。
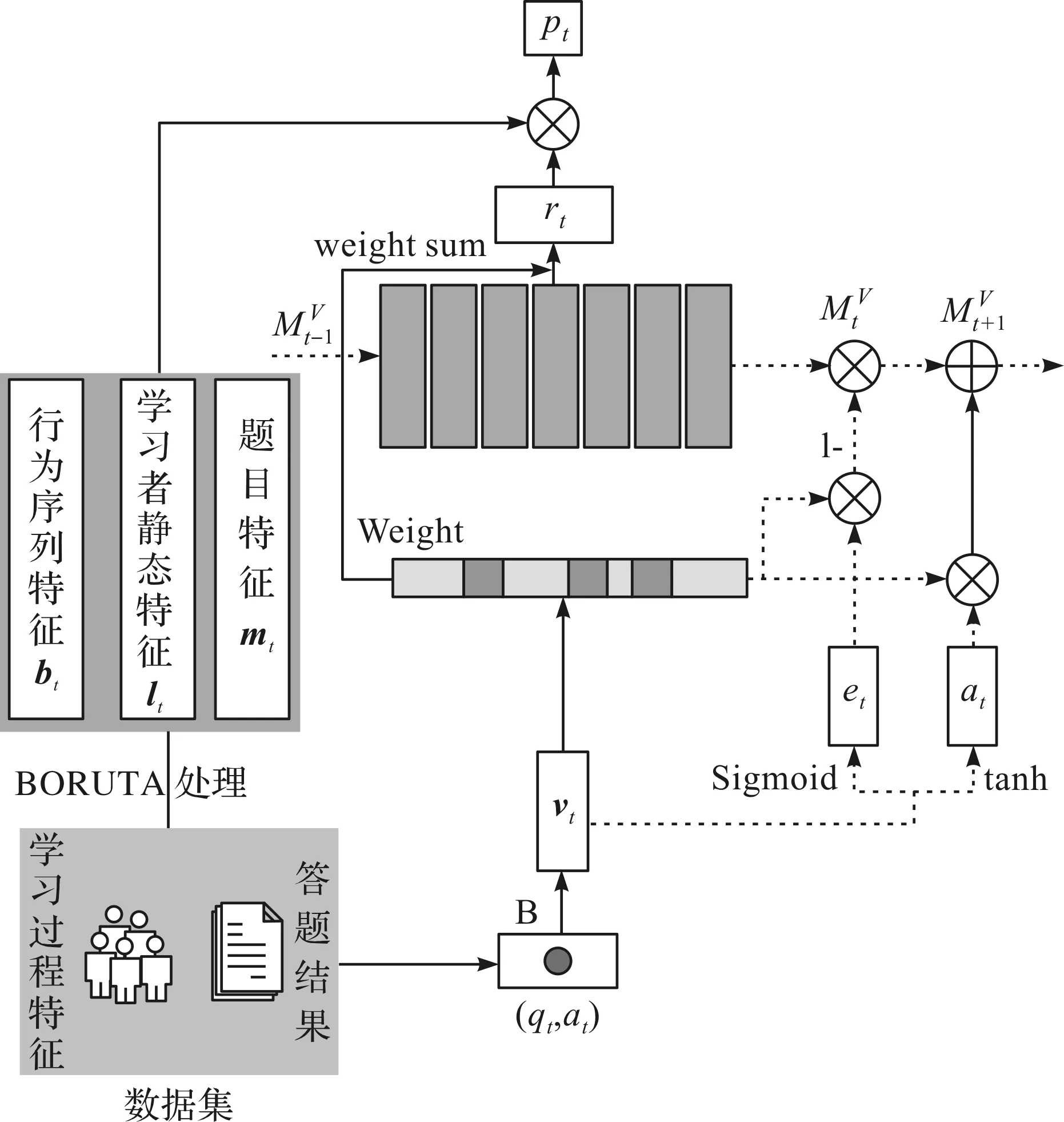
图4 融合多维特征的深度知识追踪模型Fig.4 A deep knowledge tracking model incorporating multi-dimensional features
3.2.1 计算知识概念权重
题目的独热编码通过构建题目的Embedding矩阵,获得其Embedding的向量表示,计算式为
(1)
按照式(1)计算题目的知识概念权重,首先将t时刻学习者遇到的问题q与一个已经训练好的Embedding矩阵A相乘,得到向量kt;然后将kt通过Softmax计算,得到注意力向量wt。
3.2.2 多维特征融合
DKVMN易拓展的优点为学习过程多维特征的融入提供条件。首先利用每个概念的知识状态来计算学习者的能力。具体来说,当DKVMN模型接收到一条学习记录时,将对学习者特征向量ft产生影响,因为ft是读向量rt和嵌入向量kt融合得到的结果,所以它既包含学习者对题目qt的知识状态信息,也包含qt的嵌入信息。通过神经网络处理傅立叶变换,可以用来推断学习者在题目qt上的能力。同样,题目qt的难度水平也可以通过将题目的嵌入向量kt传递给神经网络来获得。
基于注意力权重wt,DKVMN模型可以通过以下过程预测学习者正确回答题目qt的概率pt:
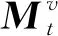
(2)
2) 将BORUTA特征通过Embedding矩阵处理得到向量表示,并与题目内容特征向量vt进行Embedding矩阵拼接。对学习者静态特征lt和题目特征向量mt进行拼接,将学习行为序列特征作为调节因子bit,计算式为
(3)
式中:∅为Sigmoid激活函数;bit=Sigmoid|bt|。bt的具体计算方法:挖掘出的有效学习行为是看学习视频和讨论区讨论,则学习行为序列特征向量为(学习视频,讨论),若学习者先看学习视频再打开讨论区讨论,然后又看了学习视频再进行答题,则这个学习者学习行为序列为bt=(2,1)。总体向量融合了学习者当前知识状态、当前题目内容特征和BORUTA的特征集。
3.2.3 知识状态矩阵更新

et=Singmoid(Wev+t)
(4)
at=tanh(Wavt+t)
(5)
式中:We为擦除权重;Wa为添加权重;t为学习者做题时间离散化值。最终经过先“擦除”后更新的过程,学习者的知识状态动态更新过程表达式为
(6)
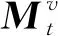
模型优化目标是模型对学习者答题的预测结果pt与答题的真实值at之间的差异最小化,二者的交叉损失函数值要最小。模型采用动量梯度下降法来进行优化,实现对模型高效训练,计算式为
L=-∑t[atlogpt+(1+at)log(1-pt)]
(7)
4 结果与讨论
通过在公共数据集和实际教学中开展实验,验证融合学习过程多维特征的知识追踪方法有效性、可解释性和实际应用效果。
4.1 公共数据集实验与结果讨论
各方法在各数据集上的AUC值如表1所示。对于公共数据集,使用了Zhang等[15]提供的经过处理的数据,表1描述了这些数据集的相关信息。在知识追踪领域研究工作中均使用AUC(Area under curve)作为评价指标,且AUC作为性能度量在机器学习领域凭借其优越的性质受到广泛的关注,因此通过AUC值来评价知识追踪方法性能的优劣[21]。在模型实现过程中,使用Adam优化器进行训练,所有数据集均按照7∶3进行训练集与测试集的切分,所有模型均训练10次。实验是在NVIDIA1080 Ti GPU的环境中基于tensorflow和keras实现表中的知识追踪方法。
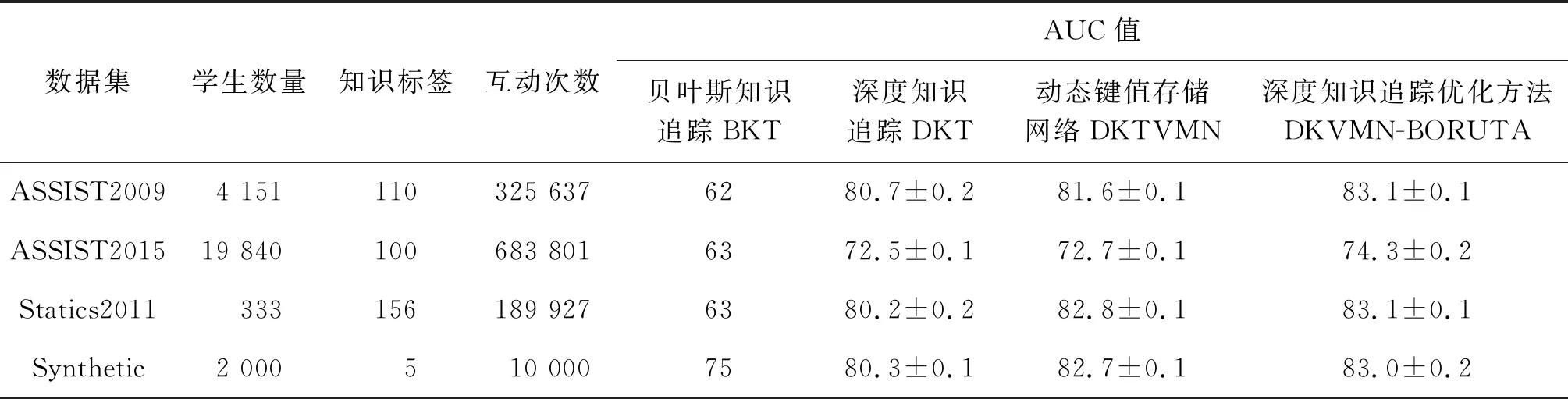
表1 4个数据集及AUC值Table 1 Four data sets and AUC values
由表1可知:笔者提出DKVMN-BORUTA模型的AUC值在4个公共数据集上远优于贝叶斯知识追踪模型,也优于其他两种深度知识追踪模型,说明设计的DKVMN-BORUTA有更好的性能。一方面,DKVMN-BORUTA融入的多维特征弥补了传统知识追踪模型对学习过程简单的数理逻辑建模问题,能够更好地模拟学习者的真实状态;另一方面,学习过程中的多维特征融入DKVMN模型后能够更好地评估学习者的知识状态。由于公共数据集难以验证融合学习过程多维特征知识追踪模型的可解释性和支撑实际教学中的作用,因此选择实证研究进一步验证分析。
4.2 实证研究与结果讨论
收集了浙江某高校2020年3—6月C语言moodle平台课程数据,共9 000次答题记录。数据集包含了学生详细的学习记录、学生信息和学习资源信息,具体数据信息如表2所示。

表2 浙江某高校2020年3—6月C语言在线课程数据Table 2 Data of C language online courses in a university in Zhejiang from March to June 2020
利用收集的数据集对DKVMN-BORUTA进行训练。该课程的练习题目均由拥有多年教学经验的老师编写,题目包括判断、单选和多选3种题型。题目设置充分参照项目反应模型,具备较好的区分度,不存在题目过于简单或者过难的现象,该题目集下知识点掌握率低于0.4被认为是未掌握该知识点。研究者和授课教师在6月课程结束时向部分学习者提供该课程中各知识点掌握情况,向部分学习者提供知识状态的同时还提供学习支持服务建议。实证研究结果如表3所示。

表3 实证研究结果Table 3 Results of empirical study
由表3可知:在数据总量较少的情况下,笔者设计的深度知识追踪优化方法在预测性能上有较大优势,在AUC值、ACC值和MSE值上均领先于其他知识追踪方法,这说明设计的知识追踪方法能充分利用学习过程多维特征更好的模拟学习者答题状态。
为了验证所提出的知识追踪方法有良好的可读性,随机抽选一名学习者A并输出其回答涵盖知识点题目的具体掌握情况,该学习者学习过程中的知识状态变化过程如图5所示。图5中,横坐标为答题序号;纵坐标为掌握程度,数值越大,掌握程度越强。

图5 学习者A的知识状态变化过程Fig.5 The process of knowledge state change of learner A
同时,为了验证该方法能否有效帮助学习者找出薄弱知识点并达成个性化学习目标,对学习者开展了对照组实验。将学习者划分为3组,对照组A为不给学习者提供知识状态信息,不为其提供精准教学支持服务;对照组B为学习者提供知识状态信息,不为其提供精准教学支持服务;实验组C为既提供知识状态信息,也提供精准教学支持服务。实证研究中精准教学支持利用利用改进粒子群算法,针对学习者的薄弱知识点向学习者进行学习资源推荐,针对性的给予学习支持[22]。精准教学支持持续2周,过程中持续收集学习者的学习数据,2周结束后对3个实验组进行课程综合测验,测验结果如表4所示。

表4 实证研究对照实验结果Table 4 Empirical research results of controlled experiments
由表4可知:对照组B和实验组C的测验成绩明显高于对照组A,且对照组B和实验组C的复习时间明显少于对照组A。这说明笔者提出的知识追踪方法是有效的,可以及时准确地发现学习者的薄弱知识点,学习者可以基于此进行有针对性的高效复习,避免知识迷航。由图5和表4可知:实验组C的平均成绩略高于对照组B,且平均复习时间也少于对照组B,这说明提出的知识追踪方法有良好的可解释性,能够运用学习者的多维特征和知识状态进行精准教学,有效帮助学习者提高学习效率。
融合学习过程多维特征的知识追踪优化方法可以准确及时地掌握学习者的知识状态。教学者根据实际题目和知识点情况确定知识状态阈值,并根据学习者知识状态和特征给予针对性的学习支持。由此也说明融合学习过程多维特征的知识追踪方法不仅增强了知识状态的可解释性,而且可以更好地服务精准教学。
5 结 论
借助BORUTA特征选择模型,挖掘学习过程中的多维特征,在DKVMN模型基础上构造学习行为序列特征网络、学习者静态特征网络和题目特征网络,设计融合学习过程多维特征的深度知识追踪优化方法DKVMN-BORUTA,并通过公共数据集和教学实证研究验证该方法服务性能上的优势和实际教学应用的有效性。未来,研究者将着力构建更具可解释性的知识追踪优化方法和精准教学应用模式,提升学习者在线学习效果。
猜你喜欢
电脑知识与技术(2022年11期)2022-05-31
当代陕西(2021年16期)2021-11-02
意林·少年版(2020年2期)2020-02-18
知识文库(2019年24期)2019-12-30
现代职业教育·职业培训(2019年6期)2019-10-09
领导文萃(2019年8期)2019-04-19
金桥(2018年3期)2018-12-06
读友·少年文学(清雅版)(2018年12期)2018-04-04
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
