
一种基于画像关联及本体相容匹配的就业推荐方法
2022-06-01 09:49
浙江工业大学学报 2022年3期
(浙江树人大学 信息科技学院,浙江 杭州 310015)
2021年我国应届毕业生人数达到909万,在疫情及国内外产业调整双重影响下,应届毕业生的就业问题尤为严峻。此外,由于信息不对等、人才培养规格以及产业脱节等原因造成的人才供给“双盲”困局[1]日渐严重。因此,国内外诸多学者将目光投向了个性化推荐技术[2],以期通过建立求职者与岗位之间的内在关联解决就业失衡的问题。García-Pealvo等[3]提出通过机器学习算法和聚类算法来构建简单的就业预测模型;陆佳雯等[4]和Ilich等[5]尝试通过人口统计学构建推荐算法,由于就业推荐的复杂性,算法的效果不佳且不能有效解决“冷启动”问题;刘双双等[6]和王龙等[7]采用协同过滤算法对历史就业信息进行分析,进而实现就业推荐,然而随着数据量的增加,算法效率下降明显。针对当前就业研究中存在的重“模型构建”轻“算法实用化”以及众多现有就业推荐方法存在的高复杂度及“冷启动”缺陷等问题,笔者借助用户画像简化就业关联规则,降低算法复杂度,并结合基于本体的相容匹配算法[8-9]解决“冷启动”问题。
1 就业画像关联
1.1 基于人口统计学的就业先验知识
基于人口统计学的推荐算法可以根据历史就业数据为新的就业对象推荐合适的就业岗位。即根据某待就业毕业生StuA在学习能力、实践能力和创新能力等表现上与历史就业信息库中的某些已就业学生StuB[]具有极高的相似度,则推定:与StuB[]签约岗位相似的新岗位也同样适合StuA。将以上潜在就业规律称作就业先验知识(Employment prior knowledge,EPK)。
推理1设S,J分别为已就业学生及签约岗位集合;S′i,J′i分别为待就业新生及新岗位,且有Employ(S,J),如满足Mach(S′i,S)≥β,Mach(J′i,J)≥γ,则可得出S′i⟹J′i。其中,Employ为雇佣关系;Mach为匹配算法;β,γ分别为学生与岗位的最小相似度阀值;“⟹”为强就业关联关系。
就业先验知识示意图以及基于画像的就业先验知识示意图分别如图1,2所示。

图1 就业先验知识示意图Fig.1 Schematic diagram of employment prior knowledge recommendation
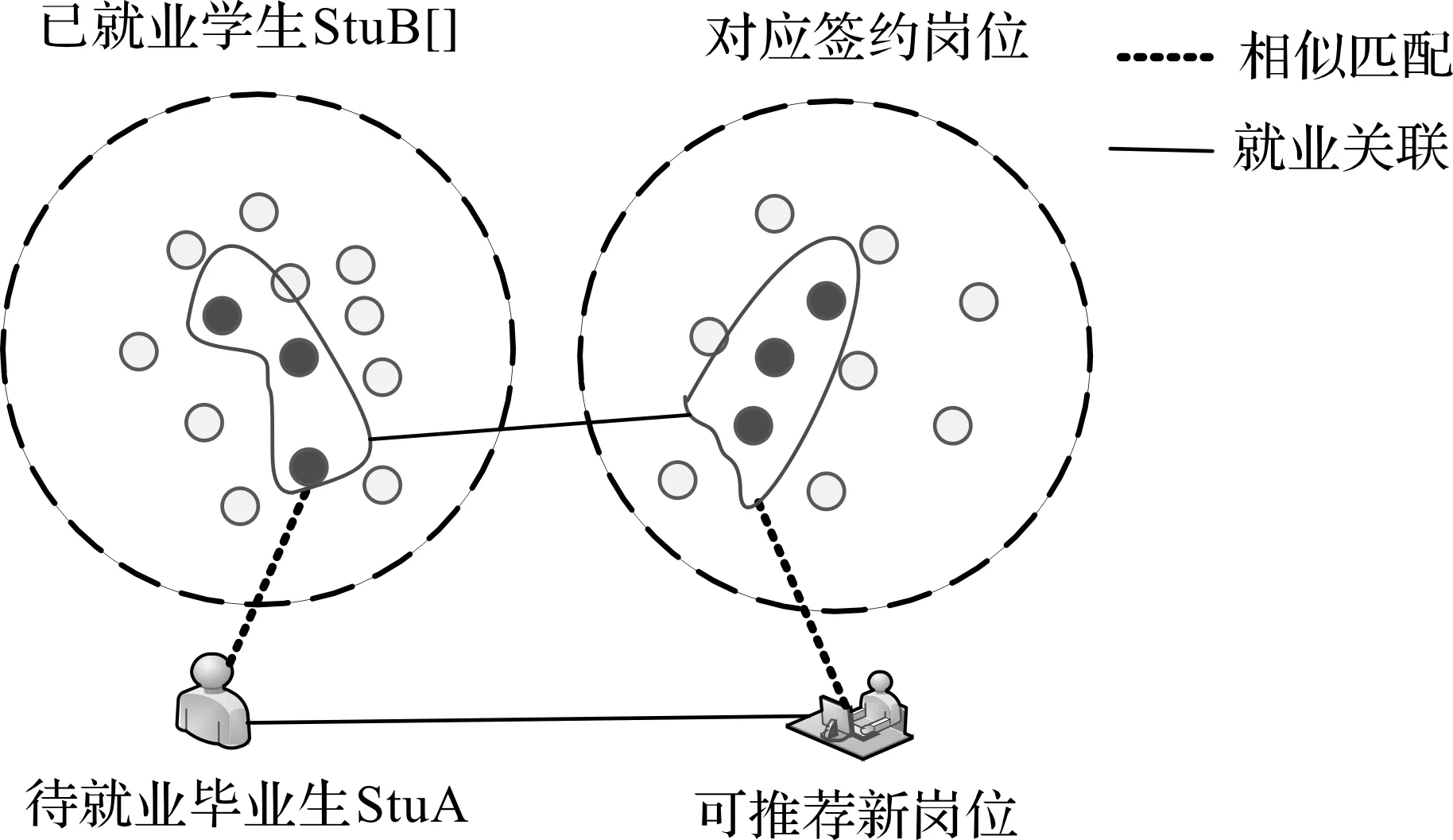
图2 基于画像的就业先验知识示意图Fig.2 Schematic diagram of employment prior knowledge recommendation based on profiling
1.2 就业画像及定义
在调用Mach函数进行就业对象和岗位相似度运算时,需要将S′i与S集合中所有毕业生依次进行匹配计算,其计算复杂度较高。为解决该问题,将海量的学生及岗位数据进行规约,将毕业生群体及岗位集合分别抽象为毕业生画像(简称StuProfiling)和岗位画像(简称JobProfiling),从而将个体相似度Mach(S′i,S)运算简化为画像相似度Mach(S′i,StuProfiling)运算。具体定义如下:
定义1设S为已就业毕业生集合,SA为S的子集,即SA∈S;β为相似度阀值。如SA内部各成员满足
则称StuProfiling为SA对应的一个画像,记为StuProfiling〈SA〉,同理可得JobProfiling〈JA〉。
1.3 基于画像的就业先验知识
构建毕业生画像及岗位画像将极大降低相似度计算的复杂度,进而可以将就业先验知识EPK提升为基于画像的就业先验知识。
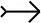
1.4 画像关联就业先验知识库构建
根据就业画像StuProfiling及JobProfiling定义,结合就业先验知识,构建基于就业画像的关联知识库(简称KBProfiling-AR,Knowledge base based on profiling association rule),具体定义如下:
定义2设StuProfiling〈S〉为已就业毕业生S集合的一个画像;JobProfiling〈J〉为S对应签约岗位J集合的一个画像,则有
KBProfiling-AR={KB1,KB2,KB3,…,KBi,…,KBN}
式中:KBi=StuProfiling〈S〉⟹JobProfiling〈J〉。
2 本体相容匹配算法
2.1 本体匹配算法
本体匹配是两个同源本体实例的映射过程,可以由四元组表示,即
〈c1,c2,r,k〉c∈[simple-data,c],r∈[=,⊆,∩,⊥],k∈[0,1]
(1)
式中:c1,c2为两个同源的本体概念实例,由基本数据类型(包含string,integer,float,date,bool,enum等)和本体概念实例嵌套而成;r为c1和c2映射关系,包含相等、包含、重叠和不相关4种情形;k为r的关联程度。String的匹配可以通过字符串相等、海明距离、字符串包含、文本分析及自然语言处理等方式计算相似度;integer,float,date,bool等类型则直接通过数值运算方式计算匹配关系;enum则通过上下位关系、同反义关系、成员及部分整体关系等方式进行匹配计算。
2.2 本体的相容匹配算法
一般的本体匹配比较呆板,只返回0,1结果,为了使匹配过程更具“语义”特性,引入“相容匹配”[10]的概念,具体定义如下:
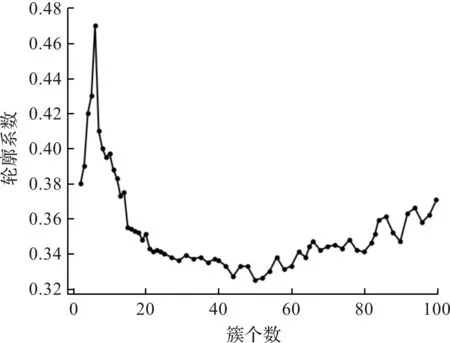
定义3C1,C2分别指隶属同一分类体系的两个概念实例模式,若C1经过结构层次展开后各叶子节点值的约束比C2更宽松,则C1语义包容C2,记为C1 引入“相容匹配”后,需要对原有的概念描述结构进行拓展,增加“方向”侧面,该侧面的值包含向上、向下两类,意指向上还是向下兼容,例如求职者期望薪资属性的侧面方向设为“向上”,如果值为6 000元,当用人单位的岗位薪资为7 000~10 000元时,则视为满足。将本体概念实例C1和C2的匹配过程称为本体相容匹配算法(简称OCMA,Ontology conceptintance matching algorithm)。 根据基于画像的就业先验知识推荐的PK_RecProfiling理论,为了获取适合就业对象A的推荐岗位,需要通过OCMA算法对待就业对象与就业画像关联知识库KBProfiling-AR中所有规则的左部学生画像StuProfiling以及待推荐岗位与KBProfiling-AR所有右部岗位画像JobProfiling分别进行相容匹配运算。其匹配过程是:双方逐级分层展开,自下而上对每个概念实例对应的Slot槽值进行相容匹配运算,进而通过迭代获取最终匹配结果WMach,即 (2) 式中:ResultSlot为槽的匹配结果,ResultSlot∈{0,1}。 OCMA算法使用相容匹配替代常规的值进行运算,使匹配结果更具语义特性。使用“基于简单将0和1的迭代匹配结果”来反映整体概念实例整体匹配度有违就业对象及岗位各属性在就业实践中的比重差异性,为此引入权重参数模型Modelw对OCMA算法进行改进,得到w-OCMA算法,改进后的匹配度WMach计算方法为 (3) 式中:ResultSlot为槽的匹配结果,ResultSlot∈{0,1};wi∈Modelw。 改进后的w-OCMA算法虽然有效地解决了就业匹配过程中槽的差异性问题,但这种差异性是通过反映“就业领域普式认知结果”的权重Modelw来体现的。在就业实践中,个体对于岗位各属性的偏好存在重大差异,为此引入兴趣度参数模型Modeli更有助于解决推荐的个性化问题。将改进后的w-OCMA算法称作wi-OCMA算法,其对应的匹配度WMach计算式为 (4) 式中:wi∈Modelw;Ii∈Modeli;ResultSlot∈{0,1}。 根据PK_RecProfiling理论可知:通过基于就业画像关联知识库KBProfiling-AR的wi-OCMA运算及推理可以实现就业的智能推荐,具体智能就业推荐模型框架如图3所示。 图3 基于就业画像关联知识库的智能就业推荐模型示意图Fig.3 Schematic diagram of intelligent employment recommendation model based on KBProfiling-AR 基于就业画像关联知识库KBProfiling-AR的就业智能推荐的基本过程是:1) 通过某待就业学生StuNoJob与就业先验知识库KBProfiling-AR中的StuProfiling集合进行相容匹配运算;2) 获取对应的学生画像集StuProfilingGetJob;3) 根据关联知识库KBProfiling-AR推理获取相应的已招聘岗位画像集JobProfilingFinish;4) 结合权重Modelw和兴趣度Modeli将JobProfilingFinish与新岗位集合JobSetNew进行相容匹配运算,并对匹配度进行排序,返回匹配度较高的结果,即得到推荐给StuNoJob的岗集。 为实现就业双向智能推荐,需要采集“就业相关数据”以便为就业画像、就业关联知识库KBProfiling-AR以及权重参数Modelw提供基础数据支持。同时,需要采集“岗位搜索/访问/应聘记录”提取兴趣度参数Modeli。具体的就业数据获取及处理方式如图4所示。 图4 就业数据获取及处理示意图Fig.4 Schematic diagram of employment data acquisition and processing 就业数据获取及处理步骤如下: 1) 数据获取。通过“浙江省生源及就业方案管理系统”“教务管理系统”“素质拓展管理平台”“毕业生就业调查系统”“学工综合系统”等系统可获取生源、课程成绩、素质拓展分以及在校过程等数据;通过“第三方就业平台”、各院校“校园招聘平台”等可获取岗位搜索关键字记录、访问及收藏历史、应聘记录等数据。 2) 数据加工。首先通过数据清理、过滤和集成等步骤对数据进行预处理;然后为降低数据分析复杂度,剔除与就业相关度不大的数据,如学号、姓名和身份证号等,并保留学位、生源地、政治面貌、英语水平、计算机水平、课程成绩、素质拓展分(含技能与证书、品德修养、科教活动、文体与团学任职等)以及奖惩等信息,构建以专业能力、学习能力、实践能力、协作能力、创新能力和品德修养等为特征的毕业生能力模型支撑数据[11],同时剔除单位名称、岗位名称和入职时间等无用信息,保留用人单位性质、隶属行业、用人单位所在地、职位类别、是否对口、学历要求和薪资待遇等为主要特征的岗位特征模型。 3) 语义转化。为达到通过wi-OCMA算法实现智能匹配的目的,必须将关系数据转化为含有语义特性的本体概念实例。因此,需要根据中华人民共和国人社部下发的《公共就业服务指标体系》关于“用人单位基本信息表、招聘岗位信息表”的标准,使用OIL本体建模语言,建立毕业生及岗位描述本体。RO-Mapping机制将存储于关系数据库中的毕业生及岗位数据转换成相应的本体概念实例,并以XML文档格式加以存储。 为获得抽象化的就业画像,需要对具化的毕业生能力模型及岗位特征模型相关的属性进行离散化,对分类、量化和布尔等属性通过泛化、离散化以及0-1投影等方式进行预处理,例如:对毕业生的各项能力值按0~5等级进行归一量化处理,调用Python提供的sklearn模块中的K-means聚类[12]模块,通过拐点法获取最佳K值,依据K值对数据进行归约重组,从而获得毕业生StuProfiling画像集。同样,使用该方法可生成岗位JobProfiling画像集。 就业画像关联规则可以使用Apriori[13]关联规则挖掘算法获取。该算法通过使用频繁项集的先验特性逐层搜索迭代,收集满足最小支持度和最小置信度的就业关联规则。首先通过Python对所有历史就业数据进行分析,结合最小支持度和集合元组数即可获得已毕业学生及岗位的频繁项集;然后基于频繁项集挖掘强关联规则,通过最小支持度和最小置信度的阈值进行筛选,获得可信的就业画像关联规则。 因为目前浙江省的就业数据缺乏就业画像及关联规则所需的充足而有效的特征数据,所以笔者通过省内2所高校近3年24 832名毕业生的生源、课程成绩和素质拓展分等就业相关数据,运用“基于就业画像关联及本体相容匹配的就业推荐方法”对2 000名2022届毕业生进行小规模检测,关键实验步骤如下。 构建以所在专业PRO、专业能力ZY、学习能力XX、实践能力SJ、协作能力XZ、创新能力CX和品德修养PD为主体的毕业生模型学生画像。将学生成绩(专业必修课、实训环节、公共课及选修课)及素质拓展分(技能与证书、品德修养、科教活动、文体与团学任职)按级差归约为1~5(分别代表合格、差、中、良、优)5个等级,专业PRO根据教育部学科分类表中二级学科按1~38进行量化,得到21 321条有效学生画像支撑数据,并按表1进行相应的映射。 表1 画像数据支撑表Table 1 List of StuProfiling 因为专业PRO的枚举项较多,且对基于毕业生能力模型的画像影响较小,所以调用Python的sklearn模块中的K-means函数对21 321条6元组[ZY,XX,SJ,XZ,CX,PD]数据进行分析。当X轴的簇个数设置为100时,所绘制的不同K值和对应总的簇内离差平方和的折线图效果最佳,如图5所示,当簇为37个时拐点最为明显,故将求职者画像划分成37个簇最为合适。进而通过K-means(n_clusters=37)进一步分析得到37条StuProfiling学生画像,每条画像形如:{‘ZY5’,‘XX4’,‘SJ2’,‘XZ3’,‘CX4’,‘PD4’},其成员分别代表专业能力5分(优)、学习能力4分(良)、实践能力4分(良)、协作能力3分(中)、创新能力4分(良)、品德修养4分(良)。按同样方法可得到33条岗位画像,每条画像形如:{‘XZ3’,‘DQ2’,‘DY4’,‘XL2’,‘GW21’},分别代表公司性质3(外企)、所在地区2(长三角)、待遇2(良)、岗位类型21(IT业)。 图5 学生画像支撑数据簇内离差平方折线图Fig.5 Student portrait support data cluster dispersion square line graph 调用Python的Apriori算法构建频繁集生成函数generate_L(data_set,K,min_support),其中data_set对应21 321条经过归约量化的形如[PRO,ZY,XX,SJ,XZ,CX,PD,XZ,DQ,DY,XL,GW]的就业数据,将K设为元组个数12,不断调整最小支持度min_support的值,并将37个学生画像[SP1,SP2,…,SP37]与返回的频繁项集作比对,发现当min_support=0.1,最小置信度min_conf=0.54时,返回的频繁项集的左部(学生数据)包含的SP个数最多,从而得到如表2所示的R1~R121共计121条就业画像关联规则。将元组数为7,右部为1的频繁项集的最小支持度作为右部对应岗位属性的权重参数,得到以下参数:待遇0.12,学历0.41,岗位0.17,区域0.14,单位性质0.16,因为专业对岗位推荐有很大影响,所以人为设置成2.5。兴趣度参数需要毕业生对岗位的评价,目前缺乏有效的评价数据,本实验暂时不予考虑。 表2 就业画像关联规则列表Table 2 List of association rule 首先,从2 000名测试的2022届毕业生中选取某位学生Stui,对该生的画像支撑数据进行归约,并与R1~R121的左部进行比对,返回匹配度最高的关联规则Rj〈SPk,JPn〉,其右部JPn即为Stui的拟推荐岗位画像,将JPn实例化;然后,通过调用wi-OCMA算法与654 309条供测试的岗位概念实例进行匹配,根据匹配度取前100条记录作为Stui的推荐岗位。2 000名测试对象对应的前200条推荐结果的平均权重为3.11(最高为4.27,即所有元组成员权重的累计),平均每条记录耗时0.017 1 s。 笔者提出的毕业生能力模型是对就业画像实用化的有力探索,实验结果证明:借助画像关联及本体相容匹配技术进行就业智能推荐具有一定的可行性。在缺少有效交互的情况下,笔者方法依然能获得较好的推荐结果,在解决毕业生就业的“冷启动”问题方面具有良好的效果。由于在调用wi-OCMA算法进行就业匹配前已经完成了就业画像以及画像关联规则的挖掘工作,从而将目前国内学者研究较广的“求职者—历史就业案例—推荐岗位”转化为“求职者—就业画像—推荐岗位”的匹配模式,降低了运算量,极大地提高了推荐算法的运行效率。然而,受目前我国教育信息化程度以及就业数据规范性等现实约束,数据完整性以及画像复杂度对就业画像及就业关联规则的挖掘质量具有重大决定性作用。今后需要加强毕业生就业能力以及岗位胜任能力模型的理论研究及方法探索,以期获得更为智能高效的就业画像及就业推荐方法。2.3 基于权重Modelw的w-OCMA算法
2.4 基于兴趣度Modeli的wi-CMA个性化推荐算法
3 基于就业画像关联及本体相容匹配的就业推荐模型
4 基于就业画像关联及本体相容匹配的就业推荐方法的实现过程
4.1 就业数据的获取与处理

4.2 就业画像生成
4.3 就业画像关联规则获取
5 就业推荐方法的实验步骤
5.1 建立画像描述模型

5.2 就业画像的生成
5.3 画像关联规则获取

5.4 就业相容匹配
6 结 论
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
齐鲁艺苑(2022年1期)2022-04-19
社会科学战线(2022年1期)2022-02-16
客联(2021年9期)2021-11-07
哈哈画报(2021年10期)2021-02-28
海外文摘·艺术(2020年22期)2020-11-18
非公有制企业党建(2020年10期)2020-10-27
瞭望东方周刊(2017年7期)2017-03-01
岁月(2016年5期)2016-08-13
延河(下半月)(2014年1期)2014-02-28
