
基于Hadoop集群的DDoS攻击分布式检测架构设计
2022-07-03 06:01李合军
中国新技术新产品 2022年6期
李合军
(湖南环境生物职业技术学院,湖南 衡阳 421005)
0 引言
随着恶意网络入侵问题的不断加剧,如何有效防范DDoS 攻击已成为信息安全领域的重点问题。传统检测需要消耗过多本地防护资源,无法对海量数据进行实时监测,单点故障也极易引发系统崩溃,因此其不适用于动态化的云环境。对日渐复杂的DDoS 攻击来说,本地普通检测防护设备已难以应对,增加硬件又会增加成本,因此具有可扩展性的分布式技术就逐渐成为打造低成本DDoS 攻击防御体系的最优选择。在分布式检测系统(Hadoop Distributed File System,HDFS)中,各子节点(DataNode,DN)依靠网络连接处于资源共享状态,计算基础良好,非常适合拓展性能。Hadoop非常适合用于处理海量数据,具有高效、可靠和容错高的优点,弥补了传统检测的不足。基于此,该文设计了一种基于Hadoop 集群的DDoS 攻击检测系统架构,可融合多源数据,并能够对数据进行统一分析与处理。该系统包括数据预处理、攻击检测以及效果评估等部分,各部分在功能上保持独立。该系统能够从数据中快速挖掘高价值信息,处理能力强且扩展性良好。
1 系统总体架构
如图1 所示,该文基于DDoS 攻击检测算法设计了针对Hadoop 集群的DDoS 攻击检测系统架构,主要包括数据收集、数据预处理以及数据分析3 个服务器。在分布式环境中,管理节点(NameNode,NN)的各检测节点都要参与检测,各检测节点也由这些服务器组成,并且各检测点具有独立的DDoS 攻击检测功能。数据收集服务器负责收集原始异常流量数据,过滤集群内控制信息和数据交换,收集可疑流量,利用Ibpcap 库解析源数据包,并将数据存储至HDFS内;数据预处理服务器将收集到的流量数据转换为数据处理标准格式,完成特征输入前的预处理工作,包括计算单位流量的特征熵值与归一处理等;数据分析服务器负责完成数据分析工作,使用GA-SVM 模型对处理后的特征熵值进行预测,并对结果进行分析,检测其是否存在DDoS 攻击,并判断攻击类型。
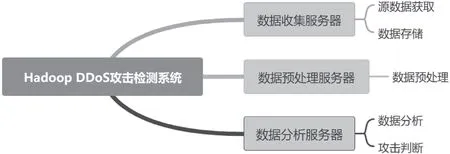
图1 Hadoop DDoS 攻击检测系统架构
从攻击形式上分析,如果NameNode 集群中多于半数的子节点出现宕机,那么就会产生严重的集群拒绝服务问题。所有检测点运行攻击检测后,可在特点时间内将各子节点的检测情况上传至汇总节点,汇总节点对其进行分析,判断集群受到DDoS 攻击的情况并做出响应。当检测系统开启后,NameNode 集群中的各子节点开始检测,检测联盟根据检测结果调整频率,再根据节点存活情况增添(删除)节点。NameNode 检测点主要负责本机流量检测,具体流程如下:1) 可以将各检测点的频率设置为10 s~60 s,如果某子节点连续多次未能检测到DDoS 攻击,应将间隔时间增加10 s。2)如果检测到DDoS 攻击,应将间隔时间减少10 s。3) 按照间隔将结果持续发送给汇总节点,并每隔10 s 汇总最新结果。4) 集群中检测到DDoS 攻击的检测点占总检测点的比例为最终检测结果,即正常(≤5%)、轻度(6%~25%)、中度(26%~45%)以及重度(≥46%)。
1.1 数据收集服务器
数据收集服务器是DDoS 攻击检测模型的基础,负责收集Hadoop 中的异常流量信息,提取数据包中的有效信息,并将提取后的数据包信息存储在HDFS 内,以便后续有序地开展深入处理工作。
一般采用第三方库Pcap4j 打开Pcap 文件获取IP 包,对TCP/IP 四元组进行解析。Pcap4j 属于Java 库类型,一般用于调试Pcap本地方法,基于Windows的实现形式为Winpcap,基于Unix/Linux的实现形式为Libpcap。因为该文使用Ubuntu,所以通过Libpcap 获取指定网卡(根据IP 情况),在应用层捕获各类网卡的数据包。基于Libpcap 库,Pcap4j 对Libpcap进行封装,可让其更易执行底层监控。
因为研究方向是Hadoop 集群,所以需要将解析完成后的IP 数据进行文本存储。服务器根据特定时间调用写文件API,把有效信息存储进HDFS 内。如图2 所示,HDFS 写流程的简要步骤如下:1) 向NameNode 发送写文件远程调用指令。2) 检查文件是否已存在,如果没有问题,就可直接写入Editlog。3) Client 将DataNode 与Data 发送至最近节点。4) 对DataNode 进行Pipeline 写入,每当DataNode 写完“块”信息后就返回确认信息。5) 数据写完后发送信号,数据收集程序在系统触发后开始运行,并将之前解析完的IP 数据写进HDFS(data/packet)目录内。
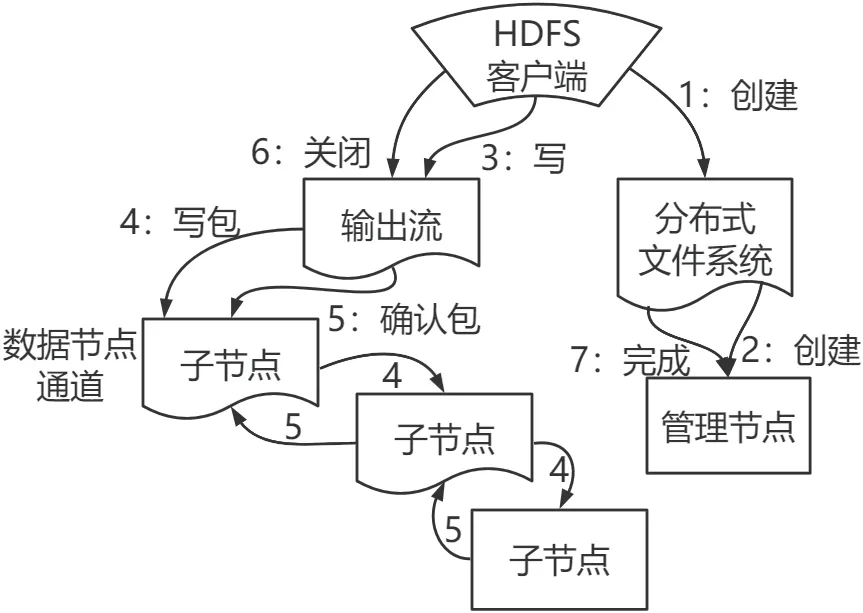
图2 HDFS 写流程概况
1.2 数据预处理服务器
数据预处理服务器对完成解析的流量数据进行预处理,一般使用Scala 语言完成预处理任务。预处理读取解析完成后的数据包,将时间戳、TCP/IP 四元组合并在一起,重组成格式化的单位流量组。服务器通过Spark 平台完成整个计算过程,具有分布、高速等特点。
虽然Hadoop 与Spark 同属大数据框架体系,但是二者的实现目的却不尽相同。严格来说,Hadoop 作为一个分布式数据框架,可构建基于分布式存储的管理、计算等部件,能够将巨大数据集分散至多个子集中。一般来说,这些子集是由廉价设备组成,这样既能减轻维护负担,也让数据存储计算更便捷。Spark 则是一个分布式计算框架,如果要代替Hadoop 的MapReduce,那么Hadoop 生态依然占据核心地位。Spark 的核心是分布式数据集(Resilient Distributed Dataset,RDD),其属于一种虽不可改变、但亦可分类的并行计算集合。RDD 包括Transformation 与Action。Transformation 将已存的RDD 生成为另一个RDD,当程序发现Action 时才可执行代码;Action 则是负责代码触发工作。在数据预处理服务器中,通过textfile()将文本转换为RDD,在HDFS 中读取完成解析后的数据包,Spark 封装各类算子,并通过这些算子来处理RDD。
1.3 数据分析服务器
数据分析服务器的主要工作在于利用计算好的流量特征熵值与训练后的攻击检测模型对特征进行分析。该服务器主要具备数据分析与攻击判断2 个功能。
在训练过程中,指定一个支持向量,将训练数据转换为RDD,并对该数据进行分“块”化处理,同时扩展至多服务器并开始训练,结束后存储模型。当SVM 算法模型训练结束后,应将训练后的序列化文件存储在HDFS 中。当进行检测时,各子节点应加载模型,将样本特征值转换为RDD,并通过DDoS 检测在各子节点上开启分布检测。检测流程如下:1) 加载训练后的GA-SVM 模型。2) 数据包在Spark 中加载完成后转换为RDD 集合。3) 统一RDD 数据,对其进行格式化与熵值化处理,随后将其转换为攻击检测特征向量。4) 各子节点使用GA-SVM 模型预测攻击检测特征向量。5)Spark 汇总节点上的预测结果。
NameNode 节点能够定量区分DDoS 攻击,Hadoop 集群的攻击判断包括程度判断与类型判断。所有节点在DDoS 检测完成之后,将检测结果汇总到指定节点,并根据集群检测结果来判断攻击程度。对攻击类型来说,需要根据单节点的检测类型进行明确分类,所有节点通过GA-SVM 模型来判断攻击类型。此后,汇总节点将这些攻击类型消息分批发送至各子节点,子节点再将检测到的类型集合发送至汇总节点,汇总节点将信息并集后作为Hadoop 集群捕获的DDoS 攻击流量类型。
2 系统评估
结果表明,该系统能够实现对DDoS 攻击进行检测的目标,并适用于大数据处理。采用基于互信量的并行DDoS 攻击检测,从节点数量与误判率2 个方面对提高DDoS 攻击检测准确率进行科学验证。同时,通过数据预处理及MapReduce框架对算法进行并行化处理,从而提高基于Hadoop 集群的DDoS 检测效率。综上所述,针对DDoS 攻击检测进行系统架构设计,可以获得良好的检测结果,且具有较好的应用性。最后分析哪些请求数据发生攻击的可能性最高,从而预防系统安全,保障系统数据的安全性与完整性。
2.1 效率评估
使用Linux 进行入侵检测分析,Linux 包括防火墙、Messages 以及Wtmp/utmp。防火墙记录所有流入与流出的数据包,对检测DDoS 入侵具有积极意义;Messages 包括系统启动过程中的日志,可记录系统整体信息。此外,Mail、Cron 及Auth 等都记录在Messages 中;Wtmp/utmp 则记录签入与签出系统的具体时间。该设计采用1 000 M 数据进行预处理,经过预处理后,各项数据都得到一定精简,防火墙日志、Message 日志以及 Wtmp/utmp 日志的数据总量减少了15%,能够缩短之后DDoS 攻击检测分析的时间,提高系统效率。
使用Hadoop 集群将改进后的算法嵌入MapReduce,从运行时间与处理效率2 个方面对结果进行对比。该设计采用Nursery 数据集复制的手段分别产生了不同的数据集,并组成不同的集群运行。如图3(a)所示,并行计算使运行时间缩短,运行时间与机器数成正比。如图3(b)所示,当数量为100 M 时,效率没有明显提高,但随着数据量的不断增加,效率有明显的上升趋势。由此可知,在采用并行计算的基础上,增加数量能够有效提高计算效率。
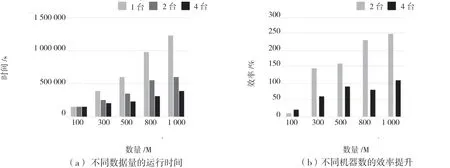
图3 不同数量的时间与效率
2.2 算法评估
如图4 所示,比较2 种算法的节点数量,结果表明,针对DDoS 攻击,改进后的算法生成节点数低于ID3 算法,由于ID3 算法均生成45 节点,因此该设计提出基于互信量的算法更接近最小规则库的决策树。同时,也表明该算法在属性选择时可以选择更适宜的分割点。此外,训练时间与节点数也呈正比,节点数越少,训练时间也就越短。因此,改进算法后生成时间所消耗的时间也低于ID3 算法。
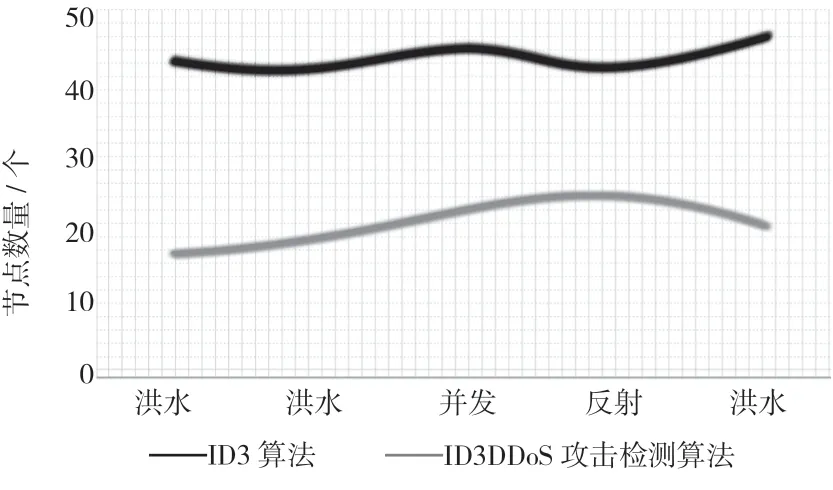
图4 节点数量比较
如图5 所示,比较2 种算法的误判率,结果表明,针对DDoS 攻击,改进后的算法误判率显著降低,保持在0.6%~1.9%。尤其是最常见的几种DDoS攻击的误判率也大幅下降。由此可知,该设计提出的基于互信量的算法在DDoS攻击检测误判率方面有较好的效果,可以在一定程度上提高准确率。
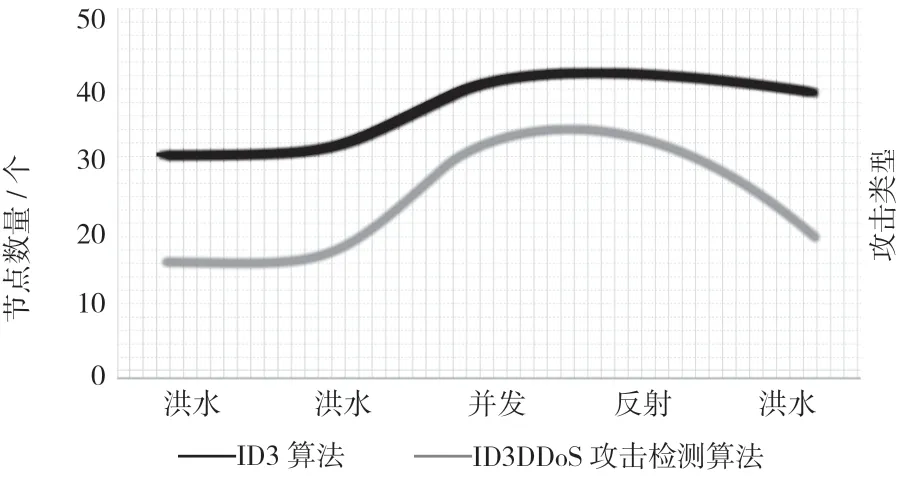
图5 误判率比较
3 结语
实验研究发现,扩展Hadoop 集群可以提高集群整体性能,增加节点数量也可以提高集群工作效率。此外,HDFS“块”信息的大小也与集群处理速度具有紧密的关系,增大“块”信息可加快集群运行速度,集群处理大容量数据的效果明显低于小容量数据。结果表明,该系统架构设计中的检测框架和算法对DDoS 攻击的检测效果良好,但也存在不少优化空间。一方面,在检测流量与DDoS 攻击的过程中,因为受条件制约,测试方案缺少高流量环境,所以无法完全保证能够在现实环境中有良好的表现,仍须对检测结果进行验证;另一方面,为了使检测具有高效性,选取普遍化的IP与端口,虽然在算法提升方面排除了部分对结果影响不多的因素,但是还应深挖DDoS 的攻击特点,以便减少漏报率。综上所述,针对基于hadoop 集群的分布式DDoS 攻击检测尚存在许多待研究的方向,希望借此为他人工作提供借鉴。
猜你喜欢
军事运筹与系统工程(2019年4期)2019-09-11
网络安全和信息化(2018年4期)2018-11-09
电子制作(2018年11期)2018-08-04
制导与引信(2017年3期)2017-11-02
中国交通信息化(2017年3期)2017-06-08
环境科技(2015年6期)2015-11-08
电网与清洁能源(2015年2期)2015-02-28
深圳信息职业技术学院学报(2013年3期)2013-08-22
电子设计工程(2011年24期)2011-06-09
