
高光谱成像的多种类柑橘病虫药害叶片检测方法研究
2022-08-07 05:57吴叶兰管慧宁廉小亲于重重
光谱学与光谱分析 2022年8期
吴叶兰, 管慧宁, 廉小亲, 于重重, 廖 禺, 高 超
1. 北京工商大学, 中国轻工业工业互联网与大数据重点实验室, 北京 100048
2. 江西省农业科学院农业工程研究所, 江西 南昌 330200
引 言
柑橘在我国栽培面积广泛, 优良品种繁多[1]。 随着柑橘种植面积不断增加, 影响柑橘果树生长发育的病虫药害种类也逐渐增多, 导致柑橘产量降低, 品质变劣。 常见病害有溃疡病、 缺素病和煤烟病等, 虫害有红蜘蛛、 潜叶蛾等, 药害有除草剂、 杀螨剂等。 当前检测柑橘病虫药害主要有病理检测法和人工检测法, 成本高、 主观性强且效率低。 因此研究一种快速精准的多种类柑橘病虫药害检测方法, 对柑橘生长状况监测及病虫药害快速诊断识别有重要意义。
高光谱成像技术是一种融合光谱和图像信息的光电检测技术, 有分辨率高、 波段数量多、 信息量大等特点[2-3], 已广泛应用于农作物病虫害检测[4]、 品质鉴定[5]和生态环境保护[6]等方面。 兰玉彬等[7]结合Savitzky-Golay平滑和支持向量机(SVM)方法, 建立了柑橘黄龙病分类模型。 邓小玲等[8]为识别柑橘黄龙病植株, 分别使用BP(back propagation, BP)神经网络、 极限梯度提升树(XGBoost)、 逻辑回归和SVM算法搭建模型, 识别准确率均在93%以上。 Abdulridha[9]等将神经网络径向基函数用于柑橘溃疡病染病程度的检测, 得到不同阶段染病叶片分类模型。 刘燕德等[10]为判别柑橘黄龙病情等级, 实现无损检测, 结合最小二乘支持向量机(LS-SVM)和偏最小二乘判别分析(PLS-DA)方法建立分类模型, 模型误判率为5.6%。 孙旭东等[11]使用峰值比判别法和偏最小二乘判别法建立了柑橘正常、 黄龙病和缺素病三分类模型。 综合来看, 目前有关柑橘病虫药害识别的研究大多是单一症状检测与分级, 多种类柑橘病虫药害的快速精准分类识别研究较少。
针对正常叶片和产生危害较为严重的溃疡、 煤烟、 缺素三种柑橘病害叶片、 红蜘蛛虫害叶片、 除草剂药害叶片, 基于高光谱成像和机器学习技术, 采用多种预处理和特征波长提取方法, 构建柑橘病叶XGBoost和SVM检测识别模型, 对比分析实验结果, 确定最优模型, 为柑橘生长状况监测及病虫药害快速诊断识别提供理论基础。
1 实验部分
1.1 样本
样本全部来自江西省新余市渝水区柑橘果园, 采集时间为2020年10月初。 挑选大小相当的柑橘正常叶片60片, 溃疡病叶片50片, 缺素病叶片60片, 煤烟病叶片103片, 红蜘蛛叶片56片和除草剂危害叶片85片。
1.2 高光谱数据采集
选用美国SurfaceOptics公司生产的SOC710VP可见/近红外高光谱成像仪采集不同类型的柑橘叶片高光谱数据。 该系统主要由高光谱成像仪、 光源、 计算机、 样本、 载物台和电源等部件构成。 可采集波长范围为350~1 050 nm, 光谱分辨率为1.3 nm, 波段数为128个, 镜头类型为C-Mount, 焦距可调。 设定高光谱图像采集曝光时间为150 ms, 物距为57.6 cm, 扫描速度每秒30行, 32 s·cube-1, 原始图像尺寸大小为696×520。 为消除采集过程中由环境、 设备等引起的测量偏差, 利用光谱处理软件SRAnal710e进行灰板校正, 得到叶片的反射率数据。 对每个叶片的一个或多个发病区提取5×5感兴趣区域(region of interest, ROI), 一个ROI得到25个光谱信息样本, 六类柑橘叶片共提取690个ROI, 最终得到17 250个光谱样本。 样本的全部光谱曲线如图1所示, 平均光谱曲线如图2所示。

图1 六类叶片样本全部光谱曲线
根据光谱曲线分析可知, 六类叶片的光谱曲线呈现典型绿色叶片特征, 总体趋势相同。 由于叶绿素吸收作用, 在500 nm附近的蓝紫光区域和680 nm附近的红光区域有两个强吸收带; 由于叶绿素反射作用, 在550 nm附近呈现一个反射率峰, 720 nm后形成高反射率台阶, 这部分叶绿素对植物生理变化反应最为灵敏, 常用来区分植物种类和诊断植物所受胁迫状态。 因不同病虫药害叶片光谱曲线有交叉重叠区域, 仅依据光谱曲线无法准确区分类别, 需后续光谱数据处理和建模。
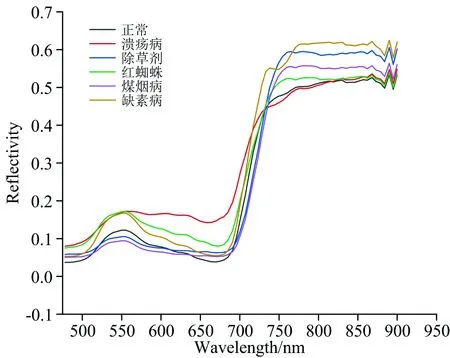
图2 六类叶片样本平均光谱曲线
1.3 预处理与数据降维
为消除噪声和谱线漂移等干扰, 分别采用一阶求导(first derivative, 1stDer)、 多元散射校正(multiplicative scatter correction, MSC)和中值滤波(median filtering, MF)三种方法对原始的高光谱数据进行预处理[11]。 对预处理后的数据分别采用竞争性自适应重加权(competitive adapative reweighted sampling, CARS)算法[12]和主成分分析(principal component analysis, PCA)算法[13]进行特征波长提取, 减少全波段光谱数据冗余信息, 降低模型复杂度并提高分类准确率。
1.4 分类算法
支持向量机(support vector machines, SVM)算法在解决小样本、 非线性、 高维模式等问题上具有优势, 广泛应用于高光谱数据处理与建模[14]。 极限梯度提升树(eXtreme gradient boosting, XGBoost)是一种可最大化利用集群资源且高度灵活的梯度提升优化算法, 支持并行化和正则化, 具有训练速度快、 识别精度高等特点。 XGBoost具体建模过程如下[15]。
(1)设光谱数据D={(xi,yi)}(|D|=n,xi∈Rd,yi∈R)为n×d的矩阵, 其中n为样本数,d为特征维度,xi为第i个样本数据。
(2)XGBoost算法的目标函数为
(1)
式(1)中l(·,·)为损失函数,Ω(·)为正则化项,c为常数可忽略不计。 (3)将目标函数泰勒展开为
(2)
(3)
式(2)和式(3)中,gi和hi分别为l(·, ·)一阶导数和二阶导数,γ为复杂度参数,λ为人工设置固定系数,T为叶子结点数,w为每个叶子结点权重。

(4)
(5)
以Obj*最小为原则选择最佳切分点, 根据式(5)遍历计算所有特征, 构建新的决策树模型, 并不断拟合先前模型的偏差, 直至拟合效果达到最佳。 XGBoost在建模过程中能生成特征重要性指数, 可用来评估每个波长的重要程度, 标识特征波长。 常用的特征重要性指数有特征分裂次数(FScore)、 平均增益值(Gain)和平均覆盖率(Cover), 在此选用FScore作为评价指标确定特征波长。
2 结果与讨论
2.1 特征波长选取
采用CARS算法选取特征波长, 迭代次数和蒙特卡罗采样次数分别设置为1 000和50。 图3以原始光谱为例给出了CARS算法选取特征波长的过程, 其中, 图3(a)反映了随采样次数增加筛选出的特征波长个数不断减少。 图3(b)显示交叉验证均方差(RMSECV)在采样初期随采样次数缓慢减小, 后期逐步增大, 说明在采样后期淘汰了影响病叶分类准确率的关键波长, RMSECV应取最小值。 图3(c)显示采样次数为33时RMSECV值最小, 该处对应的特征波长子集最优。 表1给出了Origin-CARS, 1stDer-CARS, MSC-CARS, MF-CARS特征波长提取结果, 分别为10个、 5个、 12个和10个。

图3 原始光谱CARS选取特征波长过程

表1 CARS和PCA提取特征波长
采用PCA算法选取特征波长, 用留一交叉验证法确定最优主成分, 前4个主成分的累计贡献率达到99.8%以上, 交叉验证准确率达97%, 能够代表柑橘叶片的绝大部分光谱信息。 图4以原始光谱为例, 给出了PCA的前4个主成分载荷曲线, 每条曲线的波峰和波谷位置处载荷绝对值最大, 该处对应的波长即为筛选出的特征波长。 表1给出了原始及预处理后的光谱数据经PCA降维后得到的4组特征波长, 均为7个。
2.2 分类模型对比分析
基于全波段使用XGBoost算法, 构建FS-XGBoost分类模型; 特征波段使用SVM算法, 采用随机法设置训练集与测试集比例为3∶1, 分别构建CARS-SVM和PCA-SVM分类模型, 对比分析实验结果。
由于XGBoost模型参数较多, 通过网格搜索确定模型最优参数为: num_round=750, eta=0.6, max_depth=7, 采用10折交叉验证进行训练。 在模型训练过程中XGBoost可进行特征选择, 将各波长的使用次数(Fscore)作为特征重要性的指标, 筛选出最佳特征波长组合优先用于模型训练和测试。 图5以原始光谱为例给出了特征重要性排名前20的波段, 可以看出, 重要性较高的波段集中在700~760 nm间, 与2.1节提取出的特征波段范围一致, 佐证了直接输入全波段光谱信息搭建XGBoost模型的合理性。

图4 原始光谱前4个主成分载荷曲线

图5 XGBoost特征重要性筛选
图6给出了在不同预处理方法下全波段数据XGBoost建模结果。 所有模型中, 溃疡病和缺素病的识别效果最好, 识别率均在99%以上; 红蜘蛛识别率均在95%以上; 除草剂和煤烟病的识别率略低。 原始数据经预处理后, 除草剂和煤烟病识别率波动较大。 六类叶片光谱数据经MF预处理后, 整体识别效果最好, MF-FS-XGBoost建模效果最优, 识别率均在90.50%以上。

图6 全波段数据XGBoost建模结果
图7给出了特征波段数据SVM建模结果, CARS-SVM和PCA-SVM模型的输入特征波长数均在5~12个范围内, 与全波段数据相比降低了模型复杂度, 提高了运算效率。 分析可知, 正常、 溃疡病和缺素病叶片识别率均稳定在99%左右, 红蜘蛛叶片也达95%以上; 除草剂和煤烟病识别效果较差, 识别率在72%~90%范围内; CARS-SVM模型优于PCA-SVM, 其中Origin-CARS-SVM模型建模效果最好; 但SVM模型识别率整体低于XGBoost模型。
使用整体分类准确率(overall accuracy, OA)、 召回率(recall)和模型训练时间(train-time)评估XGBoost和SVM模型的识别效果, 表2给出了两类模型的评估结果。

图7 SVM特征波长数据建模结果
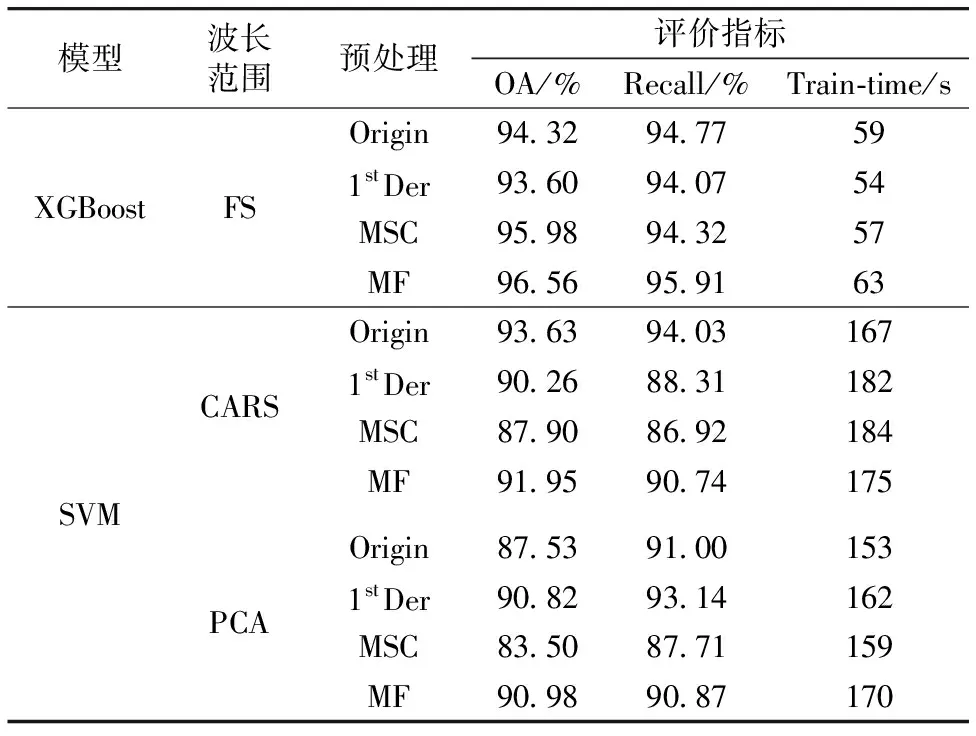
表2 XGBoost和SVM建模结果
分析可知, XGBoost模型的OA和Recall均高于SVM模型, 模型训练时间短, 效率高, 综合性能好。 其中MF-FS-XGBoost建模效果最佳, OA为96.56%, Recall为95.91%, Train-time为63 s。 经两种降维方法提取特征波长后建立的SVM模型中, CARS识别效果最优, 其中Origin-CARS-SVM的OA为93.63%, Recall为94.03%, Train-time为167 s。 特征波长建模结果较全波段数据差是因为提取的特征波长均集中在700~790 nm间, 波长范围窄, 忽略了其他有效波长, 包含的信息量少于全波段数据。 综上, XGBoost模型识别效果和运算效率均优于SVM, FS数据建模效果优于特征波长, MF-FS-XGBoost模型最优。 XGBoost模型比传统SVM更适合柑橘病叶分类, 解决了由于光谱重合率高出现的病叶种类误判问题。
3 结 论
为检测识别六种柑橘病虫药害叶片, 获取各类叶片的高光谱成像数据并进行预处理, 利用CARS和PCA算法筛选特征波长, 建立FS-XGBoost, PCA-SVM和CARS-SVM模型, 结果表明: (1)MF预处理效果优于1stDer和MSC, MF-XGBoost和MF-SVM模型OA均在90.98%以上; (2)与PCA相比, CARS算法降维效果更好, CARS筛选的特征波长为5~12个, PCA为7个, CARS-SVM的OA整体较PCA-SVM高1%~5%; (3)XGBoost模型检测效果优于SVM, MF-FS-XGBoost模型识别效果最好, OA为96.56%, 模型运算效率高, 分析可知XGBoost模型采用全波段输入, 可自动优先选取较好的特征波长建模, 无需提前降维处理, 降低了模型复杂度。 研究表明, 采用高光谱成像技术结合机器学习方法进行多种类柑橘病虫害识别是可行且有效的, 为柑橘病虫药害快速无损检测和防治提供理论依据。
猜你喜欢
航天返回与遥感(2022年2期)2022-05-12
世界农药(2019年3期)2019-09-10
今日农业(2019年10期)2019-01-04
今日农业(2019年10期)2019-01-04
电子制作(2018年2期)2018-04-18
制导与引信(2017年3期)2017-11-02
电子制作(2017年8期)2017-06-05
中国老区建设(2016年3期)2017-01-15
浙江柑橘(2016年4期)2016-03-11
浙江柑橘(2016年2期)2016-03-11
