
基于模糊拟合图像驱动的苗族服饰图像分割算法
2022-09-15 06:49黄成泉周丽华
现代纺织技术 2022年5期
冯 润,黄成泉,胡 雪,周丽华,郑 兰
(贵州民族大学,a.数据科学与信息工程学院;b.工程技术人才实践训练中心;c.民族医药学院,贵阳 550025)
图像分割作为图像处理与计算机视觉领域中一个重要的阶段[1],主要是将图像分成若干个不相交的区域,然后提取出感兴趣特征的一项关键技术。而主动轮廓模型作为图像分割的重要方法之一,由于其具有灵活选择约束力和作用域、统一开放式的描述形式等优势,在图像分割领域中得到了广泛的应用。目前,已有的主动轮廓模型图像分割算法的优化中,主要针对合成图像和医学图像分割等主流应用,针对少数民族服饰图像分割算法与优化的研究案例较少。其中,部分是基于C均值模糊聚类[2]、基于块匹配的协同优化方法[3]与基于阈值分割法[4]的少数民族服饰研究,基于主动轮廓模型[5]的少数民族服饰图像分割的研究较少。
在过去的研究中,人们提出了许多经典的主动轮廓模型,主要分为基于边缘的模型和基于区域的模型。在基于区域的模型中,Chan-Vese(CV)模型[6]作为最经典的模型之一,假设待处理图像具有均匀的强度,并且可以根据强度特征划分为几个不相交的子区域,从而达到对均匀图像进行有效的分割。但是,该模型不能很好的处理强度不均匀的图像。随后,众多学者提出了许多基于区域的模型,例如:基于图像局部信息的局部二值拟合(Local binary fitting, LBF)模型[7]、基于局部图像拟合(Local image fitting, LIF)模型[8]、基于模糊能量的主动轮廓(Fuzzy energy-based active contour, FEAC)模型[9]以及基于混合与局部模糊区域边缘的主动轮廓分割(Region-edge-based active contours driven by hybrid and local fuzzy region-based energy, HLFRA)模型[10]等,这些模型都能够很好的处理具有强度不均匀的自然、合成与医学图像。如前所述,虽然基于区域的主动轮廓图像分割算法在自然、医学与合成等图像的分割上取得了非常丰硕的研究成果,但对少数民族服饰图像进行分割的研究较少。如刘其思等[11]采用变分水平集算法对服饰图案轮廓进行边缘检测和分割,结果表明,基于变分水平集算法相较于传统的分割方法更为准确有效,但是使用变分水平集算法难以满足复杂图案分割的需求。侯小刚等[5]通过融合形态学连通域标记和CV模型,提出了一种民族服饰图案纹样元素分割的方法。该方法与其他自动分割算法相比更为有效,但是想要在较高边界召回率的情况下实现较高的分割准确率还存在一定差距。
综上所述,与主动轮廓模型在处理自然、医学与合成图像等主流图像相比,苗族服饰图像作为一种特殊的图像类型,具有绣线纹理、种类繁多、形状复杂度高、色彩差异大以及服饰图像的不善保存导致获取的图像存在破损与不清晰等问题,采用现有的主动轮廓模型图像分割技术对苗族服饰图像进行分割并未取得较好的分割结果。同时,由于基于全局的主动轮廓模型不能很好的分割灰度不均匀的图像,基于局部的主动轮廓模型存在对初始位置敏感以及容易陷入局部极小值等问题。因此,以主动轮廓模型为基础的苗族服饰图像分割面临着极大的挑战。针对这些问题,本文在HLFRA模型[10]的启发下,提出了一种基于模糊拟合图像驱动的苗族服饰图像分割算法,在一定程度上对少数民族服饰图像分割算法的研究提供参考。
1 相关模型
1.1 FEAC模型
针对基于全局的主动轮廓模型缺乏分割亮度不均匀图像的能力以及基于局部的主动轮廓模型对初始轮廓的位置敏感与容易收敛到局部最小值等问题,Lv等[12]提出了一种基于分数阶扩散边缘指标和模糊局部拟合图像的模糊主动轮廓模型。模糊能量函数表示为:
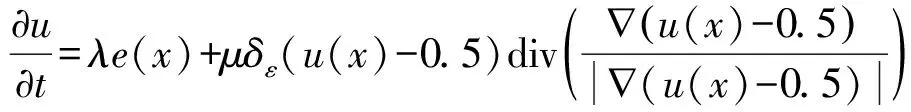
+vspfL(I(x))δε(u(x)-0.5)+γspfG(I(x))
(1)
式中:λ、μ、ν和γ为正常数,div(·)为散度运算符,u(x)为伪水平集函数,e(x)表示局部模糊能量项,spfG(I(x))和spfL(I(x))分别表示全局和局部符号压力函数,定义为:
e(x)=(m1(x)-m2(x))

(2)
(3)
spfL(I(x))=
(4)
式中:IFLFI(x)=u1(x)m1(x)+u2(x)m2(x)表示模糊局部拟合图像,W(x)=1/(1+exp(-M(x)))用于缩放I和IFLFI之间的Kulback-Leibler散度,c1、c2、m1(x)和m2(x)分别表示全局和局部内外强度平均值。
FEAC模型具有灵活的初始化方法,并且能很好的解决具有弱边界的图像以及容易陷入局部最小值等问题。同时,该模型在分割具有亮度不均匀的合成图像和真实图像方面能得到令人满意的结果。但是,当存在大部分目标对象与背景区域非常相似的情况时,该模型不能很好地进行分割。
1.2 HLFRA模型
为了分割具有高噪声和强度不均匀的图像,Fang等[10]在FEAC模型[9]的基础上提出了一种基于混合和局部模糊能量的区域边缘主动轮廓模型。该模型的能量函数由区域能量和边缘能量两部分组成,区域能量激励初始伪水平集函数向目标边界移动,边缘能量用于精确检测目标边界。能量函数定义为:
F(u)=FR(u)+FE(u)
(5)
其中,FR(u)表示区域能量,FE(u)表示边缘能量,分别定义为:
(6)
FE(u)=β1L(u-0.5)+β2P(u-0.5)
(7)
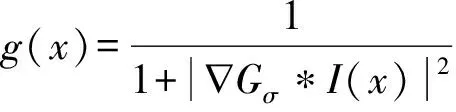
通过固定fb、fs、c1和c2,公式(6)相对u(x)最小化,得到隶属度函数为:
u(x)=
(8)
然后根据区域能量ΔF的变化来更新隶属度函数u(x)。
在HLFRA模型中,区域能量能够引导演化曲线向目标边界运动,边缘能量使演化曲线精确地停在物体边界上,该模型还通过计算新旧能量函数的差值来更新伪水平集函数。实验结果表明,HLFRA模型能够有效地从高噪声和强度不均匀的合成和真实图像中提取目标,且凸区域能量保证了分割结果与初始条件无关。
2 本文算法
2.1 能量函数构造
在上述模型的启发下,本文提出了一种新的基于模糊拟合图像驱动的苗族服饰图像分割算法。使用0.5水平集作为演化曲线[9,10,12],将图像域Ω分成内部Cin(u>0.5)和外部Cout(u<0.5)两个相邻区域。由于全局图像信息能够处理灰度均匀的图像,局部图像信息在灰度不均匀方面起着重要作用。因此,结合全局与局部图像信息在模糊区域中拟合出模糊局部与全局图像,并将原始图像和拟合的模糊局部与全局图像在Kullback-Leibler散度方面的图像差异构造模糊能量函数。然后通过图像局部与全局内外区域的像素灰度归一化类内方差构造自适应权重系数。接下来,添加了一个正则项与一个长度项,并在其中引入一个边缘检测器。最后,通过标准梯度下降法[13]最小化能量函数,并给出了算法的具体步骤。所提出的能量函数定义为:
E(u)=Ffe(u)+Fedge(u)
(9)
式中:Ffe(u)是模糊能量函数,Fedge(u)由正则项与长度项组成。
2.1.1 模糊能量函数
模糊能量函数由局部与全局模糊能量项组成。不同于HLFRA模型中混合局部模糊能量,本文在其基础上,拟合出模糊局部与全局图像。并依据FEAC模型通过Kullback-Leibler散度来量化原始图像与拟合图像之间差异的方法,通过原始图像与两幅模糊拟合图像在Kullback-Leibler散度方面的图像差异构造局部与全局模糊能量项。同时,通过自适应权重系数来自动调节局部与全局模糊能量项之间的参数。模糊能量函数定义为:
(10)
式中:第一项是全局模糊能量项,能对灰度均匀的图像进行分割。第二项是局部模糊能量项,分割灰度不均匀的图像。wg和wl为两个权重系数,满足wg+wl=1。ILFR(x)与IGFR(x)表示模糊局部与全局拟合图像,分别定义为:
IGFR=c1[u(x)]m+c2[1-u(x)]m
(11)
ILFR=m1[u(x)]m+m2[1-u(x)]m
(12)
这里IGFR与ILFR可以认为是原始图像I在全局与局部窗口内的模糊逼近,c1和c2为全局强度平均值,m1和m2为局部强度平均值,u(x)表示模糊隶属度函数,分别定义为:
(13)
(14)
u(x)=
(15)
式中:[u1(x)]m=[u(x)]m、[u2(x)]m=[1-u(x)]m,m为每个模糊隶属度的加权指数,w(x,y)为空间权重,α1、α2、β1和β2为正加权参数。
在式(10)中,为了根据图像的均匀程度来自动调整全局与局部模糊能量项之间的参数,从而构建了一个自适应权重系数。不同于Jiang等[14]和Han等[15]基于全局图像轮廓曲线内外区域的像素灰度归一化类内方差来定义权重系数,本文在此基础上结合了局部图像轮廓曲线内外区域的像素灰度归一化类内方差来表示:
(16)
式中:a1、a2分别表示图像全局轮廓曲线内外区域像素灰度的类内方差,b1和b2分别表示图像局部轮廓曲线内外区域像素灰度的类内方差,分别定义为:
(18)
式中N表示整个图像区域的像素数。
2.1.2 正则项与长度项
在式(9)中,将边缘检测器g分别引入正则项与长度项,以此来获得光滑的轮廓曲线,平滑图像边缘。分别表示为:
Fedge(u)=μLg(u=0.5)+νPg(u=0.5)
(19)
这里,μ、ν为常数,Lg(u=0.5)表示水平集函数的长度项,Pg(u=0.5)表示符号距离函数的正则项,定义为:

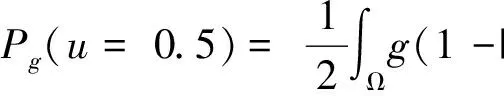
2.2 能量函数求解
本文通过标准梯度下降法最小化式(9)中的能量函数,对于固定的c1、c2、m1和m2,E(u)相对于u(x)最小化:
(22)
这里e1和e2分别为:
(23)
(24)
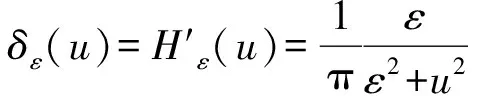
2.3 算法步骤描述
本文算法的具体计算步骤为:
a)输入指定的图像,并输入初始参数:即迭代次数IterNum、局部窗口(2k+1)×(2k+1)的大小k、常数ε、时间步长Δt、权重μ、ν、α1、α2、β1、β2和边缘检测器g;
b)初始化水平集,将其设置为u0(x)>0.5与u0(x)<0.5两个部分;
c)使用式(15)计算u(x)的伪水平集函数,并使用式(13)计算两个全局变量平均值c1和c2以及式(14)计算两个局部变量平均值m1和m2;
d)通过式(11)、(12)、(23)、(24)、(10)分别计算IGFR、ILFR、e1、e2和模糊能量函数Ffe(u),并通过式(16)计算权值wg和wl;
e)对于正则项Pg和长度项Lg分别使用公式(21)、(20)进行计算;
f)结合式(9),更新能量函数;
g)重复步骤c)-f),直到迭代完成。
3 实验结果与分析
为了验证本文算法的有效性,本节设计4组实验进行分析,即自然图像分割比较分析、苗族服饰图像的分割、苗族服饰图像分割比较分析、不同初始形状与位置的苗族服饰图像分割。依据自然图像与苗族服饰图像之间的图像性质以及图像的获取方式等关联,特别是具有纹理的自然图像与苗族服饰图像有异曲同工之处。因此,首先将本文算法在自然图像上进行验证,来体现所提出的算法在主动轮廓模型图像分割上的优势,实验数据集来自Describable Textures Dataset(DTD)数据集[16]和MSRA数据集[17]。然后,进一步将本文算法运用于选取的苗族服饰图像上,验证本文算法的分割性能以及对初始轮廓曲线的位置与形状的稳定性。苗族服饰图像数据集来源于北京服装学院民族服饰博物馆(http:∥www.biftmuseum.com/),该博物馆收藏有中国各民族的服装、饰品、织物、蜡染、刺绣等一万余件,还收藏有近千幅20世纪20~30年代拍摄的极为珍贵的彝族、藏族、羌族的民族生活服饰的图片。在其中选取了关于贵州省苗族服饰的局部图像(包括苗族蜡染、刺绣、混合与简单图像)。
实验在MatlabR2016a编程环境下,以3.3 ghz的Intel(R)内核和8 gb的计算机内存,在PC机上运行。实验中固定参数:伪水平集函数u(x)在内部和外部区域分别设置为0.7和0.3,模糊隶属度的加权指数m=2。常规参数:局部加权系数w(x,y)被(2k+1)×(2k+1)窗口截断,局部加权窗口k=1,迭代次数上限为30,时间步长Δt=0.02,最小正常数ε=1,长度项与正则项的加权参数μ=0.1和ν=0.8,图像全局内外权重α1、α2与局部内外权重β1和β2需根据图像进行调整。其他对比模型除特殊说明外,其余参数均参考原文设置。
3.1 比较算法与评价指标
由于本文是将主动轮廓模型探索性的运用于苗族服饰图像的分割,因此将本文算法与基于区域的主动轮廓模型,如LBF模型[7]、LIF模型[8]、局部与全局拟合图像(Local and global fitted image, LGFI)模型[18]和HLFRA模型[10]进行实验验证,并综合量化评价指标与视觉效果对算法的性能进行对比分析和结果讨论。
为了定量评价上述模型的分割效率和准确性,使用迭代过程中所需的分割时间、迭代次数、Dice相似性系数[19](Dice similarity coefficient, DSC)和敏感性系数(Sensitivity, SN)对分割结果进行定量评价[20]。其中迭代次数与分割时间的多少主要体现了算法的收敛程度,算法的收敛速度快,则相应的迭代次数与分割时间会得到很大程度的降低。相反,如果算法的收敛速度慢,则迭代次数与分割时间也会增加。DSC反映的是算法的分割结果与真值结果之间的相似度,SN反映的是正确检测超声区域像素点和标准区域像素点总和的比值。DSC与SN两个评价指标的值都在0到1之间,值越大,表明检测结果精度越高。分别定义为:
(25)
(26)
式中:∩是交集运算符,N(·)是封闭集的像素数,A是给定算法的分割结果,B为真值分割结果,TP和FN分别表示真阳性和假阴性。
3.2 自然图像分割比较分析
为了体现本文算法的性能,将本文算法与基于区域的主动轮廓模型,即LBF模型、LIF模型、LGFI模型和HLFRA模型在自然图像上进行对比实验。图1中图像1至图像6的实验参数α1、α2、β1和β2分别设置如下:(1.0, 0.5, 1.0, 0.5)、(0.01, 0.01, 1.0, 1.0)、(1.0, 0.5, 1.0, 0.5)、(1.5, 2.5, 1.0, 2.5)、(1.5, 2.5, 1.5, 2.0)、(0.5, 3.0, 1.0, 3.0)。分割结果如图1和表1所示,图1中显示了不同模型与本文算法对自然图像的分割结果,第1列是具有初始轮廓曲线的原始图像,第2列到第6列分别显示的是LBF、LIF、LGFI、HLFRA模型与本文算法的最终演化结果。表1显示的是不同模型在图1中6幅图像的迭代次数与分割时间。

图1 不同模型对自然图像的分割结果
由图1与表1的分割结果可以看出,LBF模型相较于LIF模型来说分割结果相对较好,但是LBF模型所需的分割时间却比LIF模型要高。LIF模型由于只运用了图像的局部信息,在分割多目标图像时容易导致边界泄露,从而导致分割效果不佳,但是所需的分割时间较为可观。LGFI模型的分割结果较差,由于LGFI模型运用了局部与全局图像信息,所以其分割所需的时间最多。HLFRA模型能有效的对图像进行分割,但是也存在一些不理想的地方被分割出来的情况。由于HLFRA模型是通过计算新旧能量函数的差值来更新伪水平集函数,所以只需要较少的迭代次数与分割时间。在本文算法中,结合了局部与全局模糊拟合图像在Kullback-Leibler散度方面的图像差异构造了模糊能量函数,同时在模糊局部与全局项之间考虑自适应权重。从而提高了本文算法对灰度均匀与不均匀图像的分割精度与效率。此外,还在能量函数中添加了一项正则项与长度项来获得光滑的轮廓曲线,平滑图像边缘。因此,本文算法相较于其他的模型来说,能够很好的对图像进行分割。并且只运用常用的标准梯度下降法最小化能量函数,就能获得较少的分割时间与迭代次数。
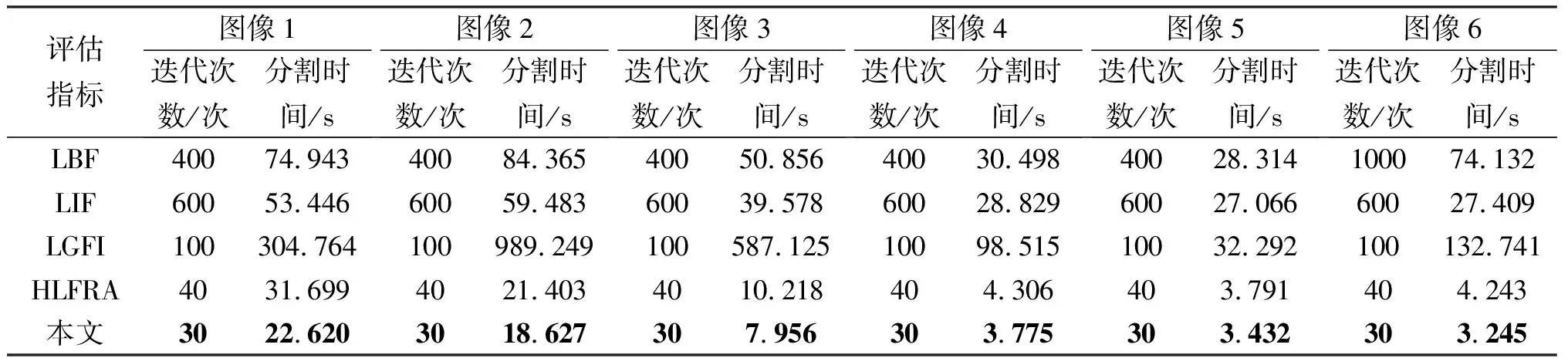
表1 不同模型在图1中6幅图像的分割时间与迭代次数
分割精度的DSC与SN系数如表2所示。从 表2 可以看出,本文算法相较于其他模型来说,具有较好的分割效果。对应图像分割结果的相似性系数与敏感性系数分别能达到0.978与0.981以上,分割结果的平均值与LBF、LIF、LGFI和HLFRA模型相比分别提高了39.8%、67.2%、44.6%与5.8%。
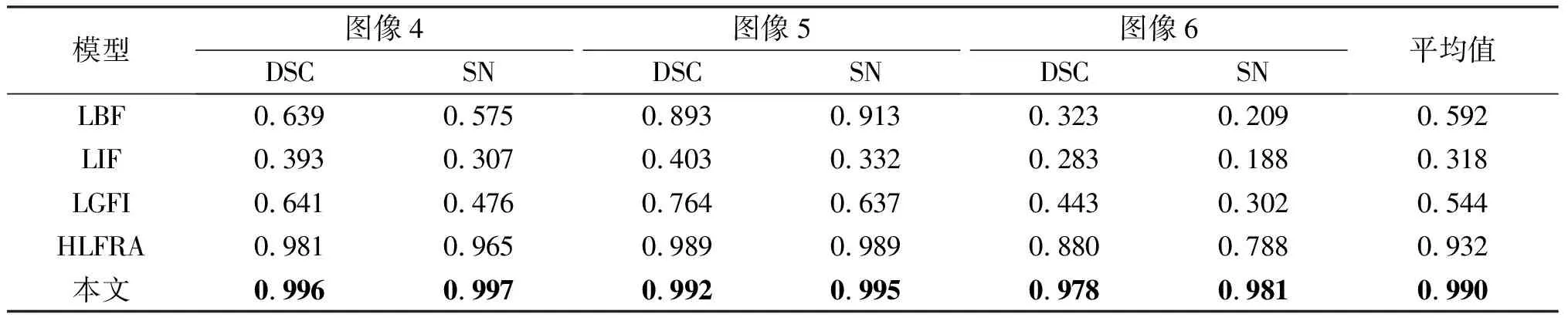
表2 不同模型在图1中图像4到图像6的DSC与SN系数
3.3 苗族服饰图像的分割
不同类型的苗族服饰图像对分割结果也有一定的影响,如蜡染图像中具有图像破损、图像不清晰、图像形状复杂等问题,刺绣图像具有绣线纹理影响、图像色彩差异较大等问题,以及混合与简单图像中不同类型图像之间、图案具有污点等问题的影响,这些问题都有可能导致得到的分割结果不理想。为了验证本文算法对不同类型苗族服饰图像的分割性能,将本文算法运用在不同类型的苗族服饰图像上进行分割。如图2所示,其中实验参数α1、α2、β1和β2设置如下:除刺绣图像中第一幅图像与第二幅图像以及混合与简单图像中第三幅图像分别设置为(0.5, 2.5, 2.5, 2.5)、(1.5, 0.5, 1.5, 0.5)、(2.2, 2.0, 0.8, 0.7),其他图像的参数均设置为(0.01, 0.01, 1.0, 1.0)。
在图2中,第1行、第3行与第5行分别显示的是具有初始轮廓曲线的原始蜡染图像、原始刺绣图像与原始混合及简单图像,第2行、第4行与第6行分别显示的是本文算法的分割结果。从分割结果看出,由于图像不清晰、图像破损、绣线纹理以及图像色彩差异较大等问题的影响,导致部分分割结果不太理想,如蜡染图像中第二幅图像由于图像的破损,导致一些不理想的区域被分割出来;刺绣图像中第三幅图像由于图像的色彩差异较大,部分区域未能被提取出来等。但是,基于总体的分割结果而言,提出的算法在不同类型的苗族服饰图像上具有较好的分割结果。
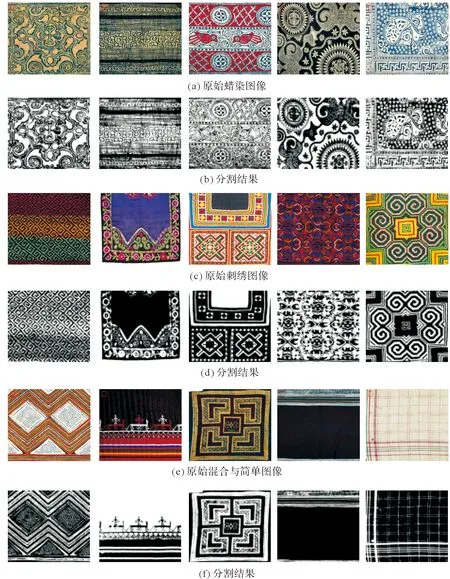
图2 不同苗族服饰图像的分割
3.4 苗族服饰图像分割比较分析
为了验证本文算法对不同类型苗族服饰图像分割性能的差异性,将本文算法与基于区域的主动轮廓模型进行比较。图3中图像1到图像9的实验参数α1、α2、β1和β2设置如下:图像1为(2.0, 2.2, 0.8, 0.7)、图像2至图像9设置为(0.01, 0.01, 1.0, 1.0)。图3显示的是不同模型在苗族服饰图像上的分割结果。其中,图像1到图像3为蜡染图像,图像4到图像7为刺绣图像,图像8到图像9为简单与混合图像。第1列显示的是具有初始轮廓曲线的原始图像,第2列到第6列分别显示的是LBF、LIF、LGFI、HLFRA模型与本文算法的最终演化结果。从分割的结果看出,提出的算法都能对这九幅图像进行有效的分割。虽然一些特别细微地方的分割结果不是特别理想,但是相较于其他模型而言具有较好的分割效果。
进一步使用分割所需的时间与迭代次数定量评估了LBF、LIF、LGFI、HLFRA模型与本文算法对图3中9幅图像的分割性能。如表3所示,本文的方法对所测试图像的分割时间都优于其他模型,只需要较少的迭代次数与分割时间就能对图像进行分割。这是由于本文算法采用模糊局部与全局拟合图像同原始图像的差异构造了一个模糊能量函数,因此极大的降低了分割所需的时间。HLFRA模型从分割时间与迭代次数来看,具有较好的性能。LGFI模型相较于LBF模型与LIF模型来说迭代次数最少,但分割时间却最多,因此LGFI模型在分割时间上不占优势。LIF模型的迭代次数比LBF模型与LGFI模型多,但是所需的分割时间却最少,所以LIF模型在分割时间上比LBF模型与LGFI模型好。
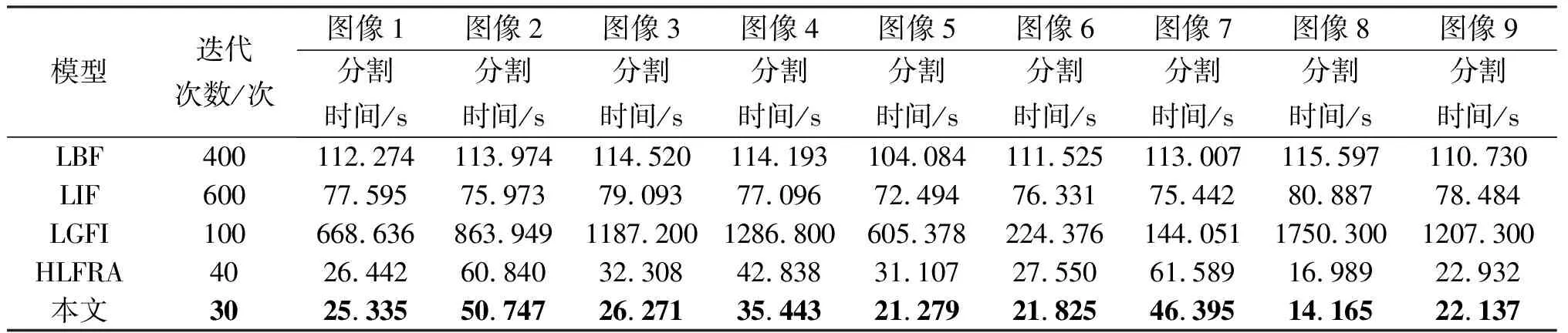
表3 不同模型在图3中9幅图像的迭代次数与分割时间

图3 不同模型在苗族服饰图像上的分割结果
3.5 初始化的鲁棒性
初始曲线的形状和位置对分割结果也有一定的影响。因此,在具有不同初始形状和位置的苗族服饰图像上,对初始曲线的形状与位置的敏感性进行评估。实验参数α1、α2、β1和β2设置为:(1.5, 0.1, 1.5, 0.5)。通过保持所有参数不变,对图4中显示的具有不同初始形状和位置的服饰图像进行测试。其中,第1行与第3行是具有不同初始形状和位置的原始图像,第2行和第4行是最终分割结果。结果显示,对于不同初始形状和位置的最终轮廓具有几乎相同的分割结果,表明本文算法对初始轮廓的放置与形状具有鲁棒性。

图4 不同初始形状与位置的苗族服饰图像
4 结 论
本文针对苗族服饰图像的分割,提出了一种基于模糊拟合图像驱动的苗族服饰图像分割算法。在一定情况下起到发展苗族服饰的作用,这对苗族服饰图案的保护、传承和发展有重要的理论和实际意义。为了体现本文算法的有效性,首先,在自然图像上与其他基于区域的主动轮廓模型进行实验评估。结果表明,本文算法具有较好的分割性能。然后,将本文算法应用于苗族服饰图像的分割。实验结果表明,本文算法在苗族服饰图像的分割中具有较好的分割结果,并且对水平集函数的初始化具有鲁棒性。但是,本文提出的算法在分割苗族服饰图像时同样存在一些问题。作为探索性的研究,本文在以苗族服饰图像为对象进行分割算法的研究时,仅仅考虑了简单的苗族服饰图像的形状、纹理与色彩等图像信息。对于图案具有复杂度特别高、纹理非常突出、存在较严重的破损与色彩差异特别大等问题的苗族服饰图像的分割结果中,存在少量漏分割与过分割的现象。这也将是今后的重点研究方向。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
装备制造技术(2020年1期)2020-12-25
制造技术与机床(2019年11期)2019-12-04
金桥(2018年4期)2018-09-26
乡村地理(2018年4期)2018-03-23
乡村地理(2018年4期)2018-03-23
中国交通信息化(2017年4期)2017-06-06
焦点(2015年12期)2016-01-26
读者(乡土人文版)(2015年10期)2015-12-13
