
基于CNN-LSTM模型的中国碳排放量实时预测研究
2022-10-30 01:42张学清乔小燕李潇怡
中阿科技论坛(中英文) 2022年10期
张学清 李 芳 张 绚 乔小燕 李潇怡
(1.山东工商学院数学与信息科学学院,山东 烟台 264005;2.山东工商学院统计学院,山东 烟台 264005;3.山东工商学院计算机科学与技术学院,山东 烟台 264005)
2021年4月22日世界地球日,习近平总书记在以视频方式出席领导人气候峰会时,首次全面系统阐释人与自然生命共同体理念,为加强全球环境治理提出中国方案,指明应对环境挑战助力实现碳中和[1]。
目前国内对于碳排放相关问题的研究主要从影响因素、行业、地区、方法这四个方面展开。从影响因素来看,徐军委(2013)从全国视角,运用LMDI模型,探究了我国二氧化碳排放增长的现状及其形成的原因,依据测算结果分析了减排目标实现的可能性[2]。马宏伟等(2015)针对我国人均二氧化碳排放,运用了STIRPAT方法对影响我国人均二氧化碳排放的因素进行了实证研究[3]。
从行业来看,碳排放主要是化石燃料的燃烧造成的,而钢铁行业、交通运输业、电力行业目前仍然依赖于化石能源的供能,关于这些行业的研究较为集中。高春艳等(2021)介绍了多种钢材碳排放分析理论和核算方法等,以及如何选取碳排放因子的数值[4]。曾晓莹等(2020)对交通碳排放时空分布格局进行研究,采用探索性空间数据分析(ESDA)方法,同时考虑空间单元的差异性,构建地理加权回归(GWR)模型分析了交通碳排放影响因素的时空异质性[5]。
从研究方法上来看,对于分析影响因素和预测都可以使用传统的STIRPAT模型[2],目前将深度学习的方法应用于碳排放的研究也越来越多。针对碳排放预测问题,学者们也运用了多种方法模型,包括赵成柏等(2012)使用的ARIMA和BP神经网络组合模型[6],王珂珂等(2020)使用的WOA-ELM模型[7]等等。
国外关于碳排放相关问题的研究主要从碳排放影响因素分解及碳排放量预测方法两个方面展开。Chekouri(2020)利用STIRPAT模型以阿尔及利亚为例对碳排放的驱动因素进行研究,结果表明人口数量是造成碳排放的首要因素[8]。国外主要用于碳排放量预测的方法有灰色模型、机器学习算法、情景分析法三种。Ding等(2017)提出改进的灰色多变量模型,避免了传统灰色模型预测不准确、适应性差等不足[9]。Chiroma等(2015)应用神经网络预测OPEC石油消费的碳排放量,利用混合布谷鸟搜索算法优化神经网络中的参数,预测结果为OPEC成员国经济发展和结构调整提供参考[10]。
目前关于碳排放量的预测还没有一个公认的统一的预测模型,通过阅读文献,可以发现CNN-LSTM模型对居民价格消费指数、短时交通流、中国消费者信心指数以及股票指数问题在预测方面展示出优越的性质,结合碳排放量数据的特性,本文将构建一个基于CNN-LSTM模型的中国碳排放量实时预测模型。通过使用多层CNN网络提取碳排放影响因素的空间特征,并运用LSTM网络捕捉碳排放量的时间依赖特征,优化算法机制进行模型的优化训练,模型采用碳排放量影响因素数据作为数据集进行预测是可行的,深度学习神经网络也可对宏观数据进行处理,实现对各个领域的预测。
1 CNN-LSTM神经网络模型
1.1 CNN卷积神经网络模型
CNN是深度学习中常用的一种前馈式神经网络,它是由多层神经网络扩展延伸而来。在大量数据输入的基础上,它能够有效提取数据特征,得到有用的数据。
学者们探索了CNN在时间序列预测中的应用,发现其噪声容忍度十分优秀。在时间序列预测中通常采用的是一维CNN,把卷积核视为一个窗口,在时间序列数据上进行窗口滑动,提取局部序列段并与权重进行点乘,持续不断输出计算得到的序列特征,从而进行池化下采样,进一步过滤数据中对于预测无益的噪声信息,使得预测性能得到优化。
1.2 LSTM长短期记忆网络模型
LSTM属于递归神经网络(RNN),是由RNN改进而来的一种特殊的循环神经网络。基础的循环神经拥有普通神经网络所没有的自连接隐藏层结构,可以用前一时刻的隐藏层状态更新当前时刻的隐藏层状态,这使得RNN适用于处理时间序列数据。但随着时间序列长度的增加,RNN会因“忘记”早期的时序信息而变得难以训练,出现梯度消失或梯度爆炸。LSTM的提出,在一定程度上解决了RNN无法记住早期时间序列信息的问题[6]。相比之下,LSTM解决了RNN无法充分利用历史信息的问题,常用来解决长期依赖问题。
LSTM共拥有四层以特殊方式进行交互的神经网络层,细胞状态以类似传输带的形式贯穿这四层神经网络,神经网络层对细胞进行很小的线性变换,因此细胞状态很容易保持信息的不变性。模型的第一步通过遗忘门决定要从细胞状态中丢弃、保留哪些信息,该决定由sigmoid函数筛选t层输入值和上一层输出值 及经过遗忘门后仍保留的长期状态中的信息。当同时获取到的信息后,将采用激活函数对数据进行处理。同时,遗忘门将这个结果传递给上一层细胞长期状态,其输出遗忘门值的表达式为:


以上就是LSTM的整个运行原理,其内部的权重和参.数通过神经网络的反向传播不断调整优化得到,进而生成LSTM预测模型。
2 中国碳排放预测模型及其结果
2.1 数据的选取与处理
2.1.1 数据的选取
通过文献研究及综合前人筛选的中国碳排放影响因素,梳理得到碳排放的影响因素有人口数量、富裕程度、技术水平、城镇化水平、产业结构、能源消费总量及化石燃料消费占比。
以上碳排放影响因素中,技术水平难以实现量化,即便量化也容易出现以偏概全的情况。学者们通过不断地研究、改进得到的与碳排放相关的影响变量,基本涵盖了全国生产生活所有的碳排放量,但是存在指标过于宏观、指标单位不一致的问题,可能会降低碳排放量的预测精度。为此,本研究重新设置了相关指标,涵盖了生产生活的六个方面,其含义及计算方法如表1所示。

表1 中国碳排放量影响因素
本文数据来源于全球实时碳数据Carbon Monitor官网。数据集来源于几个关键的排放部门:电力部门(占总排放量的39%)、工业生产(28%)、地面运输(18%)、航空运输(3%)、船舶运输(2%)和居民消费(10%)。这是第一次根据动态和定期更新的活动数据,对这六个部门进行每日排放估计。这是因为有了最近的活动数据,如每小时的发电量、交通指数、飞机位置和天然气分布,并假定排放量的每日变化是由活动数据驱动的,而排放因素的贡献如政策实施和技术转变,因为它们在较长的时间范围内演变,可以忽略不计。
2.1.2 数据的处理
(1)获取数据
从全球实时碳数据Carbon Monitor官网上获取2019年1月1日至2020年11月30日中国碳排放量的数据作为模型测试数据,共700条数据集。
(2)归--化处理
为了避免获取数据中的某些异常值使模型难以收敛,同时让CNN-LSTM模型收敛得更快更稳定,本研究对碳排放:量的相关数据进行了归--化处理,使CNN-LSTM的输入值处于[0,1]区间。归一化处理公式为数据归一化处理公式:

(3)数据还原
在训练结束后对模型进行评估时,采用公式(8)对归一化后的数据进行还原(即逆归一化)处理,以便评估模型预测值的误差。

2.2 模型构建
本研究构造的CNN-LSTM模型的第一部分搭建了2个卷积层、1个最大池化层和1个展平层。在提取数据进行训练时,基于一周碳排放量数据以及不同影响因素的数据变化情况,且要保证数据预测的准确性,对比用一周、三周的数据预测的效果后,最终将输入层高度设置为14,也就是两周。通过滑动窗口的训练机制,每滑动一步,将输入14×7窗口大小的训练集数据进入卷积1层。后期LSTM部分则采用LSTM网络对展平层输入的时序数据进行建模,最终得到中国碳排放量连续7天的实时预测结果。
第二部分则采用LSTM网络对展平层输入的时序数据进行建模,将卷积神经网络捕捉到的特征序列通过LSTM的多次叠加计算,最终得到中国碳排放量连续7天的实时预测结果。CNN-LSTM中国碳排放量实时预测模型运行的整个过程如图1所示。
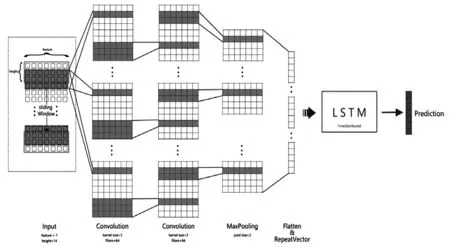
图1 CNN-LSTM运行流程图
为了将本研究构建的模型更好地运用到真实数据预测过程中,将数据的前80%划分为训练数据,后20%划分为测试数据。在训练过程中,训练周期以三周为单位,前两周多变量数据作为模型的训练输入,后一周碳排放总量作为验证输入,以两周数据预测后一周数据,采用交叉验证的方法,训练集和验证集不断调整模型参数,把MAE和MAPE作为模型损失值,通过反向传播误差信息进行迭代权重更新,不断优化卷积内核中的参数、权重及LSTM的参数信息的参数直至收敛,完成模型的训练。在测试阶段,20%的测试数据用于评估最终训练完成的模型的泛化能力。
总而言之,CNN-LSTM碳排放实时预测模型是将两个模型结合在一起,其模型内部的运行原理不变,充分利用了两者的优势,弥补了不足。数据部分采用了碳排放相关影响因素每天的数值,得到的是碳排放量每天的实时预测值,数据与方法的恰当结合最终得到了能用于预测实时碳排放量的较好的模型。
2.3 模型参数设置
CNN-LSTM深度神经网络通过最小化碳排放量的预测值与实际值(真实值)之间的误差进行训练。对于损失函数定义为:

其中表示输出的碳排放量预测值,y表示真实值,W、b表示待学习的参数,Loss的隐含意义是预测的残差,本研究的目标是使得Loss=0(或尽量小)。
根据损失函数值最小化原理,需要对CNN-LSTM模型的超参数进行设置,它在一定程度上影响了该模型的预测性能。经过反复地试验、调整,最终确定了相对较优的超参数和激活函数,同时为了调整多变量数据输入和一维数据的输出维数转化,配置了Repeat-vector层和TimeDistributed层。
2.4 结果分析
2.4.1 拟合结果分析
CNN-LSTM模型下对应时段中国碳排放量的预测结果与实际值对比如图2所示。可以看出,预测值的波动趋势大体与实际值的波动趋势一致,可见CNN-LSTM模型对碳排放量的预测表现较好,该模型具有较强的泛化性能。

图2 CNN-LSTM模型验证集预测值与实测值对比图(133天)
2.4.2 预测结果
根据模型可得到一周内每天碳排放量预测值,显示一周内的波动差值大概在0.5以内。
3 模型性能的评估
3.1 模型评价方法
本文CNN-LSTM模型的预测评价方法主要采用较为常用的均方误差MSE和平均绝对百分比误差MAPE来进行预测的评价分析。评判误差大小的标准:MSE和MAPE值越小,其预测误差越小。
3.2 模型评估结果
通过CNN-LSTM模型得到的一周内碳排放量预测误差在合理范围内且偏小,具体数值如表2所示。

表2 一周内中国碳排放量预测误差
3.3 不同模型性能对比
通过对比不同模型对碳排放量进行预测得到的均方根及平均绝对误差值可知,不同模型按两者从小到大排列顺序为CNN-LSTM<WOA-ELM<ELM<BPNN。根据误差值越小精度越高的原理,得到不同模型按预测精度降序排列为CNN-LSTM>WOA-ELM>ELM>BPNN。结论证实了采用CNN-LSTM预测碳排放量具有更高的精度,模型可行性高,可用于对中国每天的碳排放量进行实时预测。
4 结论及建议
4.1 结论
(1)本文构建的CNN-LSTM预测模型具有较小的误差值,在碳排放量预测精度上优于WOA-ELM和BPNN模型,既解决了CNN难以记忆早期时间序列信息的问题,又克服了LSTM预测数据信息精度不足的缺陷,具有较强的泛化性能。
(2)通过该模型可以预测到每一天实时的碳排放量,由此可以通过每天的碳排放量监控与碳排放相关的生产活动,对比年度、季度甚至月度的碳排放量数据,本研究得到的每日碳排量数据更具有时效性,便于及时调控各生产活动的碳排放量,也为进一步如何采取相关措施有效降低碳排放量、实现碳中和提供了分析数据。
4.2 政策建议
(1)积极调控可控因素可以有效控制碳排放总量数值。短期碳排放量的数值,容易受到碳排放生产端和消费端的控制,但长期来看,要把碳达峰与碳中和综合考虑,既不能为了短期数值,限制相关企业的发展,也不能放任碳排放总量达峰,造成生态环境的破坏后,再考虑碳减排。
(2)各个地区要因地制宜,积极探索适合本地区的碳中和措施。
(3)积极推动碳排放权的交易市场建设。国家要不断完善交易机制,进一步规范全国碳排放权的登记、交易、结算活动。加快建立各项行政法规、市场标准,积极对接国际碳排放权交易市场,为全球碳排放交易市场提供中国智慧、中国方案和中国标准。
(4)应该大力鼓励节能减排等相关技术的研究与创新。
(5)提高公众环保低碳意识,培养绿色健康生活方式。
(6)在后疫情时代,我们面临着全球未来重构与转型发展。全球碳中和目标将会对相关产业及金融业产生深远影响,我们应该提前做好准备,积极面对全球投资的机遇和挑战,以对碳排放量精确地掌握,应对挑战、抓住机遇,促进企业绿色生产,满足人民对美好生活的向往和追求。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
现代电力(2022年2期)2022-05-23
中学生数理化·高二版(2022年4期)2022-05-09
煤气与热力(2021年6期)2021-07-28
看世界·学术上半月(2020年9期)2020-09-10
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2017年12期)2017-04-23
