
嵌入注意力机制的多尺度深度可分离表情识别
2023-01-12 11:48宋玉琴高师杰曾贺东熊高强
北京航空航天大学学报 2022年12期
宋玉琴, 高师杰, 曾贺东, 熊高强
(西安工程大学 电子信息学院, 西安 710600)
面部表情识别作为人机智能交互系统的关键技术,是当前人工智能的重要研究课题。 传统的表情识别主要是应用机器学习方法人为设计特征,最后用分类算法判定表情。 提取特征的方法主要有局部二值模式(local binary pattern, LBP)[1]、主成分分析法(principal component analysis, PCA)[2]、Gabor 小波变换[3]、尺度不变的特征变换(scale invariant feature transform, SIFT)[4]、灰度共生矩阵(gray-level co-occurrence matrix, GLCM)[5]等。常用的分类算法有支持向量机(support vector machine, SVM)[6]、K 近邻算法(K-nearest neighbor,KNN)[7]等。 上述方法特征提取与表情分类是2 个分开的过程,效率较低,且其特征提取受到人为因素影响,容易丢失部分表情特征,特征提取的不完备使得最终分类效果一般。
基于深度学习的表情识别,其特征提取与表情分类可同时进行。 李勇等[8]基于LeNet-5 优化网络模型,将网络中提取的低层特征与高层特征相结合,在CK +数据集上取得了83.74%的识别率。 Mollahosseini 等[9]将AlexNet 与GoogleNet 网络融合,增加了网络的深度和宽度,在CK + 数据集上取得了93. 20% 的识别率。 Jung 等[10]通过输入人脸外貌特征与人脸关键点联合训练网络,增强了特征提取的多样性,在CK +数据集上取得了97.25%的识别率。
研究表明,更深更宽的卷积神经网络能够有效提高表情识别率,但随着网络深度的增加,会出现梯度爆炸和梯度弥散的现象,导致模型训练难以收敛。 对此,何凯明等[11]提出了深度残差网络(ResNet),有效缓解了网络性能退化和梯度爆炸等问题。 受此启发,本文构建了残差网络嵌入CBAM[12](convolutiona block attention module)的多尺度深度可分离表情识别网络。 通过叠加多层深度可分离卷积层来代替5 ×5、7 ×7、9 ×9 等大卷积核,提取不同深度的特征信息,降低网络运算参数,采用CBAM 注意力机制提高网络模型对关键表情特征的敏感度,提升网络中面部表情特征权重,剔除无关的冗余特征,提升网络的鲁棒性。同时,通过恒等映射有效缓解了网络中的梯度问题,提高网络收敛速度。
1 表情识别网络模型
1.1 CBAM 注意力机制
注意力机制是模仿人类在浏览时专注自己感兴趣的事物而忽视无关事物的特性。 CBAM 注意力机制由通道注意力与空间注意力串联组合而成。 其中,通道注意力关注的是有意义的输入特征,空间注意力关注的是最具信息量的特征部分。
假设输入特征F大小为H×W×C,H、W和C分别为特征的长、宽和通道数。 通道注意力如图1所示。 首先,特征F分别进行最大池化(Maxpool)和平均池化(Avgpool)后,特征变化为1 ×1 ×C,再分别输入共享权值的多层感知器(multi-layer perception, MLP),其中隐藏层为降低参数运算设置C/r个神经元,r为缩减倍数,激活函数为ReLU。 然后,将经MLP 运算后并相加的特征采用Sigmoid 激活函数完成映射,得到权重系数MC。 最后,将输入特征与MC相乘,得到完成通道注意力的新特征。

图1 通道注意力模块Fig.1 Channel attention module
空间注意力如图2 所示。 首先,特征F分别经最大池化和平均池化后,并在通道上完成拼接,得到H×W×2 的特征。 然后,将其输入到卷积核为7 ×7、Sigmoid 激活函数的卷积层,得到最终的权重系数MS。 最后,F与MS相乘便可得到完成空间注意力的新特征。
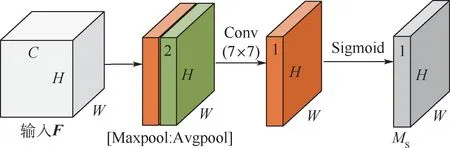
图2 空间注意力模块Fig.2 Spatial attention module
1.2 嵌入CBAM 的多尺度深度可分离卷积残差块
本文提出的嵌入CBAM 的多尺度深度可分离卷积残差块如图3 所示,其中,深度可分离卷积由点卷积(pointwise convolution, PW)和深度卷积(depthwise convolution, DW) 组成,如图中A_Conv2d 和B_Conv2d 所示。 假设输入F′特征类型为H×W×C。 以本文采用的卷积核为例,F′特征经N个点卷积,其参数量为H×W×C×N,通过卷积核为3 ×3 ×1 的深度卷积,参数量为H×W×C×3 ×3,因此,深度可分离卷积的计算量为H×W×C×3 ×3 +H×W×C×N。 特征F′经卷积核为3 ×3 ×N标准卷积运算,其参数量为H×W×C×3 ×3 ×N。 深度可分离卷积与标准卷积参数运算量对比如式(1)所示。 采用深度可分离卷积神经网络替代标准卷积使得网络模型的参数减少1/8 ~1/9,从而轻量化网络模型。

图3 嵌入CBAM 的多尺度深度可分离卷积残差块(基础块)Fig.3 Multi-scale depthwise separable convolution residuals embedded in CBAM(Basic Block)

A_Conv2d 和B_Conv2d 均由卷积层、批归一化层(batch normalization)、ReLU 激活层组成。 其中,批归一化层通过归一化每批数据,缓解深层神经网络中梯度消失的问题,提升网络模型的非线性表达。 ReLU 激活函数能有效改善梯度的弥散问题,增强网络模型的收敛效率。 本文利用2 层A_Conv2d 和B_Conv2d 的叠加代替一个5 ×5 的卷积核,利用3 层A_Conv2d 和B_Conv2d 的叠加代替一个7 ×7 的卷积核,使用4 层A_Conv2d 和B_Conv2d 的叠加代替一个9 ×9 的卷积核,从而丰富网络提取特征的多样性,在每个通道后嵌入CBAM,并对不同通道进行特征融合。 CBAM 能提高网络表情相关特征的权重,剔除冗余特征,提升特征的有效性。 通过恒等映射缓解深层网络梯度弥散和梯度爆炸的问题,提高网络训练的收敛速度,输入X在经过卷积激活等图中运算输出为F(X)。 若输入X与输出F(X)的特征维度相同,则直接加和。 若维度不同,则与输出F(X)维度一致,最终输出H(X) =X+F(X)。
1.3 表情识别网络总体模型
本文提出的残差网络嵌入CBAM 的多尺度深度可分离表情识别网络如图4 所示,由1 个卷积核为3 ×3 ×64 的卷积层、8 个Basic Block、全局平均池化层(Golbal Average Pooling)和全连接层(FC)等构成。 其中,Basic Block 的卷积核的个数依次为64、64、128、128、256、256、512、512。 全局平均池化层能生成与分类类别相对应特征图,增强特征图与类别的一致性,对每个特征图求和取均值,最终输入到Softmax 分类层。 此外,全局平均池化可看做对模型的网络结构整体进行正则化,从而提高模型的泛化性能。
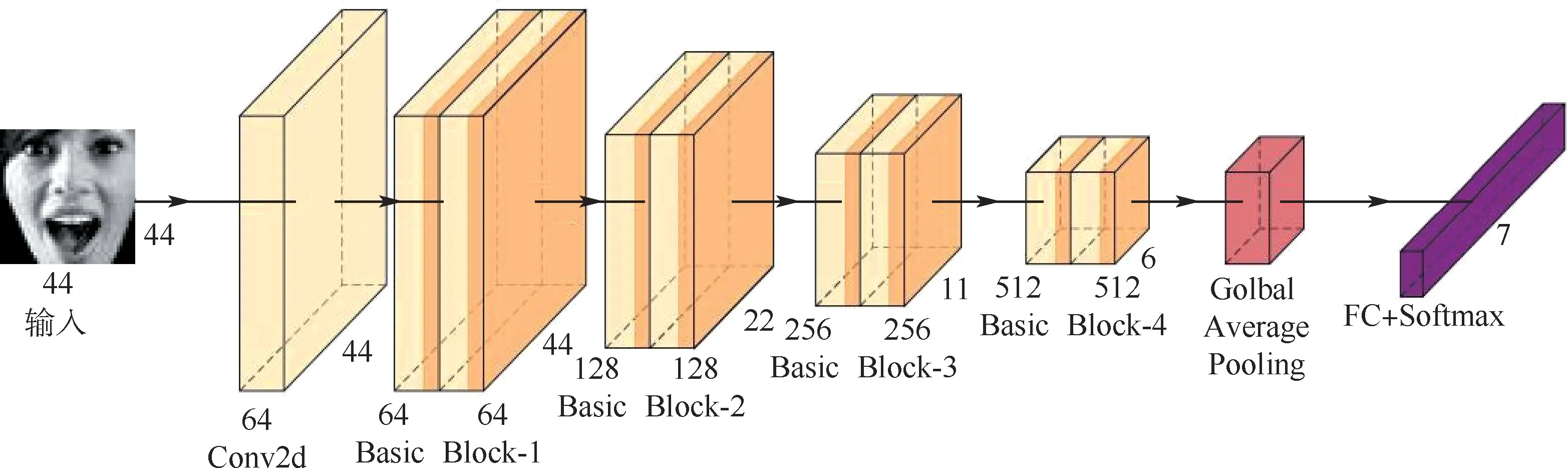
图4 基于残差网络的嵌入CBAM 的多尺度深度可分离表情识别网络结构Fig.4 Structure of multi-scale depthwise separable facial expression recognition network embedded in CBAM based on residual network
网络损失函数选用交叉熵(cross-entropy)损失函数, 其能度量预测的概率与真实的差异情况,交叉熵损失越小,则模型预测的准确率越高。交叉熵损失函数表示为

式中:g(xi)为模型输出预测值;yi为输入xi真实值;C为样本数;L为计算后的交叉熵损失值。
如图4 所示,向模型输入预处理过后的44 ×44 ×3 的图像,经过第1 个卷积处理后特征格式为44 ×44 × 64,经过8 个Basic Block 特征图为6 ×6 ×512,最终送入到全连接层和Softmax 分类层得出表情类别。 网络模型的特征变化如表1所示。
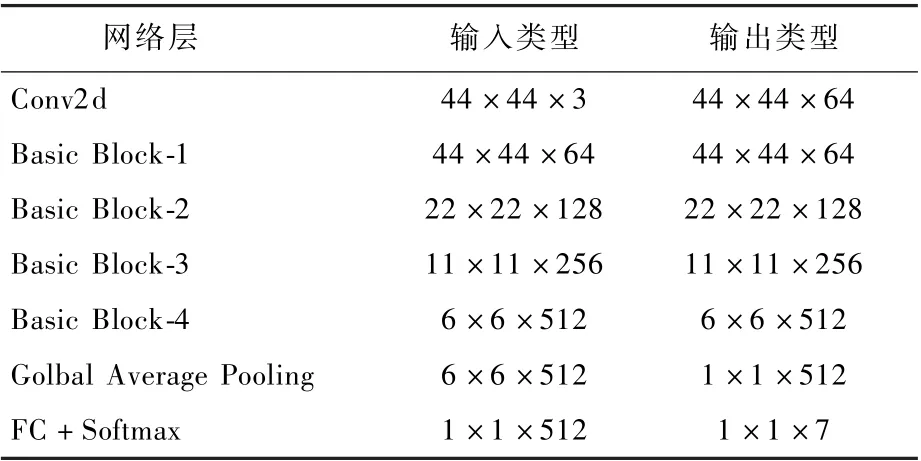
表1 表情识别网络特征参数Table 1 Feature parameters of expression recognition network
2 实验环境与结果
本文设计的网络在Ubuntu18.04 LTS 系统下使用Pytorch 深度学习框架完成搭建,实验硬件平台如下:CPU 为AMD Ryzen 5 3600X,主频为3.8 GHz,内存为32 GB,GPU 为显存11 GB 的NVIDIA GTX 1080TI,选用Fer-2013 和CK +公开表情数据集进行表情识别网络模型的训练与测试。
2.1 数据集选择与处理
Fer-2013 数据集[13]是Kaggle 面部表情识别比赛提供的一个数据集,包括训练集图像28 709 张,公共验证集与私有验证集均3 589 张图像,图像的像素都为48 ×48。 该数据集包含愤怒(4 953 张)、厌恶(547 张)、恐惧(5 121 张)、快乐(8 989 张)、悲伤(6 077 张)、惊喜(4 002 张)和中立(6 198 张)7 类表情,各类表情如图5 所示,每列为一类表情,其同类表情的面部姿态、年龄、表情强度、肤色有明显的差异,并且很多人脸有被眼镜、帽子、手等物体遮挡,这样更符合真实场景下的人脸表情,使用该数据集更能说明算法模型的泛化性能。

图5 Fer-2013 数据集的表情示例Fig.5 Sample expression diagram of Fer-2013 dataset
CK +数据集[14]是面部表情识别的代表性数据集之一,其在实验室条件下采集,较为严谨可靠。 数据集包括123 人的593 个图像序列,展示了表情从平静状态到峰值的过程,其中327 个为带有标签表情序列。 本文实验选取除中立表情外的其他7 种表情,提取表情序列中最后3 帧,并将其处理为48 ×48 像素的图像,如图6 所示。 这7 种表情共有981 张图像,包含愤怒(135 张)、厌恶(177 张)、恐惧(75 张)、快乐(207 张)、悲伤(84 张)、惊喜(249 张)和藐视(54 张)。

图6 CK +数据集的表情示例Fig.6 Sample expression diagram of CK + dataset
为提高网络的泛化性能,实验对Fer-2103 数据集和CK +数据集进行了数据增强。 如图7(a)所示,在训练网络模型时,将训练集的图像随机裁剪为44 ×44 大小,其中随机裁剪掉的为紫色部分,并进行水平翻转,将数据集扩充数据为原来的2 倍后输入网络进行训练。 如图7(b)所示,为提高网络模型的鲁棒性能,在进行测试集验证时,将输入图像分别在左上角、左下角、四边、右上角和右下角进行裁剪,裁剪部分如图7(b)中紫色部分所示,得到5 张44 ×44 大小的图像,并水平翻转,得到10 倍数据,将处理后的图像输入模型得到类别概率求和并取均值,其最大概率分类为最终表情类别。

图7 Fer-2013 训练集与测试集的数据增强示例Fig.7 Sample figure of data enhancement of Fer-2013 training set and test set
2.2 实验过程与结果
在Fer-2013 数据集上训练时,网络超参数如下:实验共迭代300 次,初始学习率设为0.01,批量大小设为32,50 次迭代后,每8 轮迭代学习率衰减为之前的0.8 倍。 在公共验证集上测试优化网络权值,在私有验证集上测试模型,评估模型性能。 混淆矩阵如图8 所示。 本文算法在Fer-2013数据集得到73.89%的准确度,快乐(91%)、惊喜(84%)、中立(74%)等表情因相对其他表情具有明显的面部特征从而获得较高的识别率,而厌恶(69%)、愤怒(64%)、悲伤(64%)和恐惧(58%)4 种表情之间误判率相对较高,其主要原因是:这些表情本身就有较高的相似性,人类也难以辨认陌生人的这4 类表情。
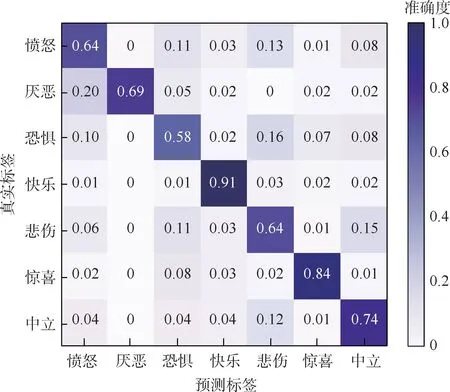
图8 Fer-2013 私有验证集表情分类的混淆矩阵Fig.8 Confusion matrix of expression classification in Fer-2013 private validation set
此外,这些表情图像数据相对其他表情较少,类别数据的不均衡导致网络训练不充分,也是影响其识别率的重要因素。
在CK + 数据集上训练时,因其数据较少,故采用十折交叉验证,实验以9 ∶1 的比例将数据集分为训练集和测试集,训练集882 张图像,测试集99 张图像。 实验共迭代200 次。 训练批量大小设为64,前50 次迭代其学习率为0. 01,之后每8 轮迭代,学习率衰减为之前的0. 7 倍。 其测试集混淆矩阵如图9 所示。 本文算法在CK + 数据集得到97. 47% 的准确度,快乐(100%)、惊喜(99%)、厌恶(98%)、愤怒(97%)等均有较高的识别率。 恐惧(95%)、藐视(93%)、悲伤(92%)等表情因受类别数据不均衡和本身易混淆的影响,识别率相对较低。

图9 CK +测试集表情分类的混淆矩阵Fig.9 Confusion matrix of expression classification in CK + test set
为验证本文算法的先进性,在Fer-2013 和CK +公开表情数据集上,与近年其他表情识别算法进行对比,对比结果如表2 所示,本文构建的网络模型具有更强的泛化性能。 此外,因为Fer-2013 数据集存在较多的受遮挡面部图像,且存在部分表情标签误分的问题,模型在Fer-2013 数据集准确度整体相对CK +数据集较低。
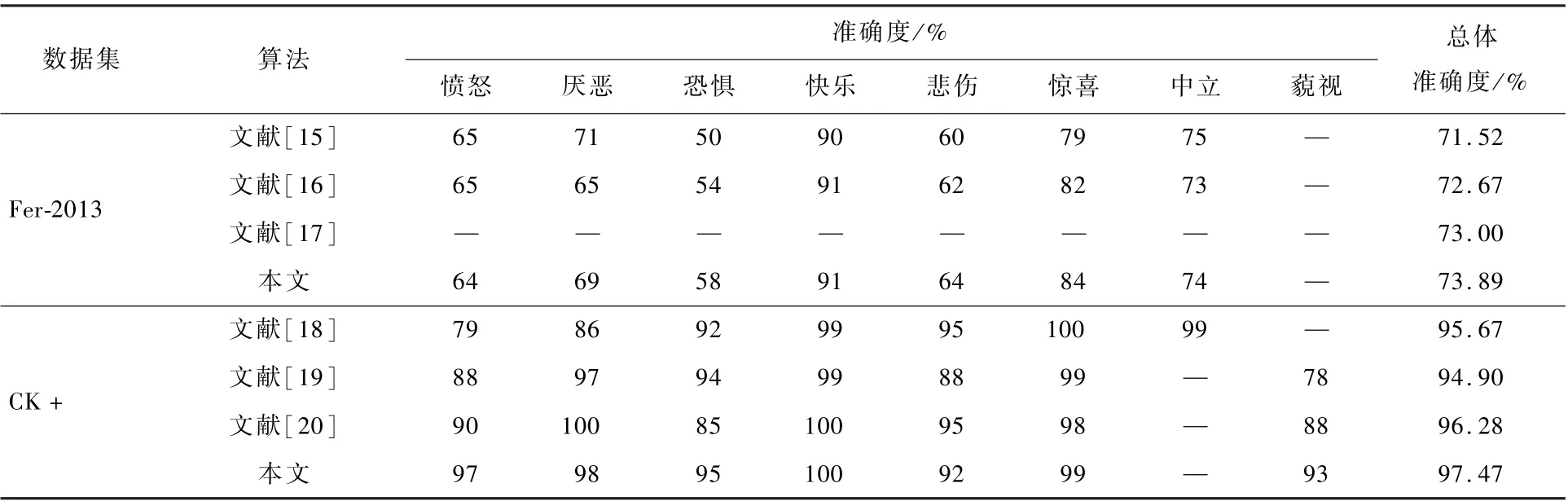
表2 本文算法与其他表情识别算法的准确度对比Table 2 Comparison of recognition rates between proposed algorithm and other expression recognition algorithms
2.3 消融实验
为进一步验证CBAM 注意力机制与多尺度卷积结构特征提取的有效性,实验通过增删Basic Block 中不同通道的卷积结构与注意力机制进行实验验证。 实验在Fer-2013 和CK + 数据集上训练时,网络中的超参数与2.2 节中一致。 消融实验结果如表3 所示,表3 中的A、B、C、D 分别表示不同尺度的卷积模块,如图3 所示,此外ACBAM、B-CBAM、C-CBAM、D-CBAM 分别对应A、B、C、D 卷积模块后添加CBAM 注意力机制。 由表3 分析可知,随着Basic Block 中通道由A 增加到ABCD 通道,2 个数据集上表情识别率均有明显提升,验证了通过提取多尺度的表情特征能有效提升表情的识别率。 此外,随着Basic Block 各各个通道依次增加CBAM 注意力机制,数据集上的表情识别率稳步提升。 验证了嵌入CBAM 注意力机制能有效提升网络中表情特征的表达,削弱了网络中无关特征的权重。

表3 消融实验Table 3 Ablation experiments
3 结 论
本文设计的嵌入CBAM 多尺度深度可分离残差表情识别网络,通多层小卷积层的叠加来代替大卷积核,在丰富了特征信息同时,有效缩减了网络训练参数,通过注意力机制进行特征的筛选,提升有效特征的表达权重,有效提高了表情识别率,网络模型具有较高的泛化性。
后续将通过生成式对抗网络进行数据增强,丰富面部表情样本的多样性,从而提高表情识别网络的训练效率。 对因表情数据类别数据不均衡,导致网络无法均衡训练部分参数的现象展开研究,进而提升网络模型的泛化性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
四川大学学报(自然科学版)(2021年6期)2021-12-27
计算机应用(2020年12期)2020-12-31
甘肃教育(2020年22期)2020-04-13
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
中国交通信息化(2018年3期)2018-06-13
中国高新技术企业(2017年5期)2017-05-05
第二课堂(课外活动版)(2016年2期)2016-10-21
文苑(2015年9期)2015-09-10
