
基于BERT的风雹灾害实体识别与特征分析
2023-09-07 02:49陈靖铠顾家豪纪昌权苑豪杰
中国新技术新产品 2023年14期
陈靖铠 顾家豪 高 敏 纪昌权 苑豪杰
(中国矿业大学(北京)管理学院,北京 100083)
风雹灾害是我国影响范围最广的灾种,数据种类与数量丰富。由于文本中普遍存在记录不规范的问题,人工识别消缺的方法只能在有限范围内将部分数据转化为领域知识。
命名实体识别技术可以从海量异构数据中识别关键信息,目前已受到广泛关注。张芳从等[1]基于RoBERTa-WWMBiLSTM-CRF 模型不依赖人工特征解决了中文电子病历文本词识别不全的问题;王明达等[2]对城镇燃气事故文本进行主旨聚类划分后,通过BiLSTM-CRF-RL 模型提高识别质量。目前,已有学者对台风、地震、洪涝等灾害[3-5]进行文本分析与信息抽取工作。风雹灾害伴生气象较多,无法通过单一气象数据集进行训练。因此该文提出一种基于风雹灾害数据集的 BERT-BiLSTM-CRF 模型。使用Bert 模型训练得到多种语义特征的动态词向量后,输入BiLSTM 模型进一步提取上下文特征,连接CRF 模型输出全局最优识别结果。最后利用该文自建数据集中的相关实体,从时空间维度进行特征可视化分析,为风雹灾害应急管理与处置提供新思路。
1 研究方法
1.1 BERT 预训练模型
风雹灾害文本含有发生时间、地点及类型等语义信息,是灾害实体识别模型的训练基础。传统语义处理模型无法解决实体表述不一致和一词多意的问题。BERT 模型基于多层Transformer 架构具有双向编码能力,可以提取文本序列中的语义、结构等多种特征。
BERT 的输入为文本字符序列,输出向量词嵌入、段嵌入和位置嵌入3 个部分。词嵌入为字符对应的静态向量,段嵌入用于区分字符所属句子,位置嵌为表示字符位置信息的特征向量。BERT 训练包括2 个任务, MLM 任务内容为随机遮掩一句话中的部分字符后,通过上下文信息对该字符预测,提高模型词意理解。NSP 任务内容为随机选取部分语句,判断是否存在一定的相邻关系,可以让模型更好地理解句子间的关系。完成词向量预训练后,将文本序列向量化后输入BiLSTM 模型进行训练。
1.2 BiLSTM 双向长短时网络模型
BiLSTM 模型是由2 个LSTM 模型组成的,通过捕获双向语义信息,挖掘的语义特征更丰富。LSTM 引入了记忆细胞、输入门、输出门和遗忘门作为控制机制。各门控系数的计算如公式(1)~公式(3)所示。
式中:Ft、It、Ot为遗忘门、输入门、输出门系数;σ为sigmoid神经网络层,系数值域为[0,1],控制信息量大小,1 代表全部通过。Xt为输入的t时刻文本序列向量,Ht-1为输入的上一时刻隐状态向量。Wx、Wh为各门控的权重参数,b为各门控的偏置参数。Xt由BERT 生成,Ht-1来自上一时刻的LSTM 单元,以Ht为例进行计算,如公式(4)所示。
式中:Ct为t时刻记忆细胞状态;Ot为t时刻输出门系数;tanh 为tanh 神经网络层,其计算结果Ht为向量形式。
输入门计算系数后生成候选状态向量,与遗忘门处理后的上一时刻细胞状态拼接后,将当前时刻细胞状态更新为Ct,其计算如公式(5)~公式(6)所示。
式中:为t时刻候选状态向量;Ct为t时刻细胞状态向量;Ct-1为t-1 时刻细胞状态向量。
LSTM 训练流程如下:输入当前时刻文本与上一时刻单元的隐状态,遗忘门与输入门将根据各自系数决定丢弃、增添部分信息后,拼接生成当前时刻细胞状态,用于下一个LSTM 单元训练,输出门根据细胞状态计算隐状态向量,输入Softmax 层解码后得到当前时刻预测标签。
1.3 CRF 条件随机场模型
BiLSTM 模型可以处理长距离文本的上下文依赖关系,但是无法处理标签之间的关系。例如B-DATE 标签只能出现在时间实体的首端,但是BiLSTM 输出结果中可能存在I-DATE 位于B-DATE 之前。CRF[6]具有长距离依赖性和交叠性特征表达能力,可以处理不同标签之间的依赖关系,修正BiLSTM 的部分错误输出。将灾害文本预测标签序列通过全连接层后输入CRF 模型后,训练更新输出矩阵计算预测得分,最后CRF 将根据得分高低输出对应最优预测标签。得分计算如公式(7)所示。
式中:T为标签yi后标签为yi+1的得,P为字符i预测为标签yi的得分。
1.4 BERT-BiLSTM-CRF 模型
在BERT-BiLSTM-CRF 组合模型中,BERT 根据灾害文本序列输出对应的组合表征向量,BiLSTM 模型利用该向量,通过前向LSTM 与后向LSTM 双向编码学习风雹灾害文本中的依赖关系与语义特征,将前向、后向特征向量序列合并后输入CRF 模型,对该序列进行全局最优归一处理,得到文本最优预测标签序列,完成实体识别。整体流程如图1 所示。
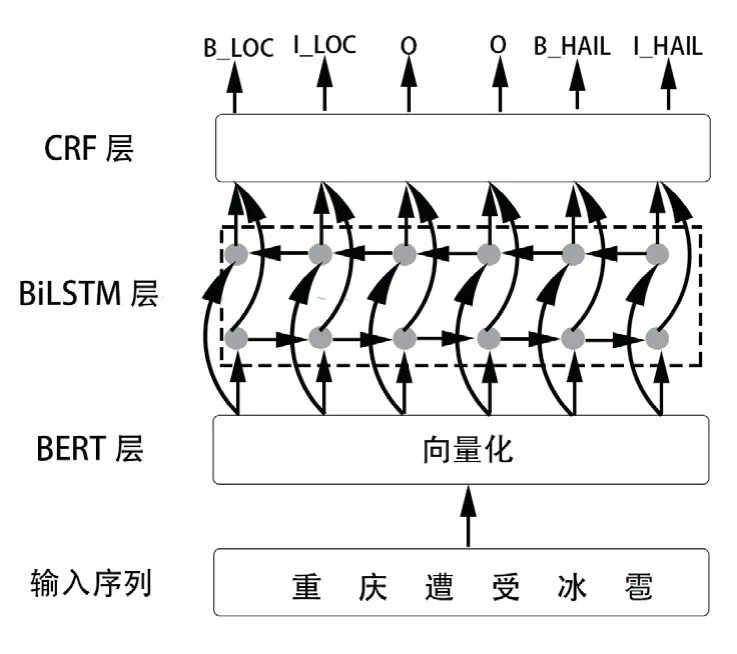
图1 模型结构
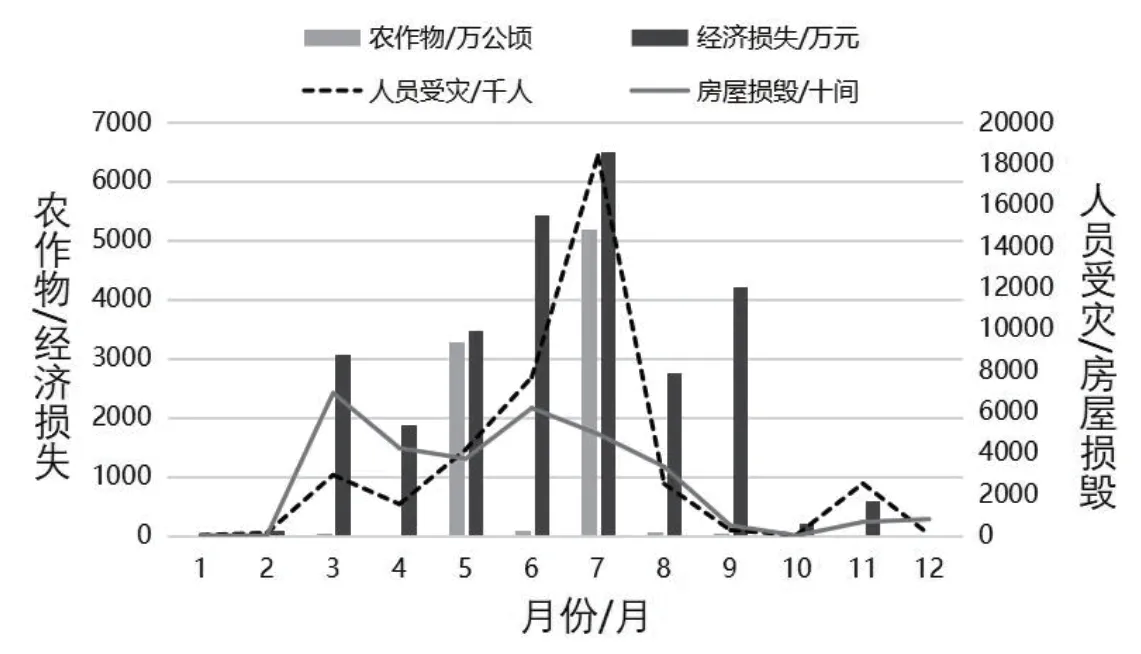
图2 灾情时间图
2 试验数据
2.1 数据获取
由于风雹灾害领域目前缺少现成语料库,因此首先需要获取有关数据。各地气象局发布的灾情报告包括发生时间、发生地点和受灾情况等权威信息,是自然灾害数据分析的重要文本。该文搜索风雹等关键词,爬取相关报告180 余篇。由于语料中包括报道人、报道来源等大量无关信息,为增强模型识别效果,人工清洗上述噪声数据;同时对半结构化数据进行人工拼接组合。完成上述处理后形成本次试验风雹灾害语料集,共计65534 字符。
2.2 数据划分与标注
建立语料集后,按照8 ∶2 的比例划分训练集与测试集。命名实体识别任务属于序列标注任务范畴,需要对文本标注后训练,标注结果包括实体类别、起始位置和结束位置3 个部分的内容。目前,标注方法有BIO 法、BMES 法和BIOES法。在BIO 标注法中,B-xxx 代表某实体开头字符,I-xxx代表某实体的中间或者结尾字符,O 代表不属于任何实体的无关字符。BMES 与BIOES 标注法对实体边界进一步划分,实现单个字符实体的标注。该试验数据中单个字符实体出现频率较低,因此采用BIO 方法。该文参照国家标准《自然灾害承灾体分类与代码》(GB/T 32572—2016)、《自然灾害灾情统计第2 部分:扩展指标》(GB/T 24438.2—2012),设置大风、冰雹、大雨、雷电4 类灾害实体,发生时间、发生地点、受灾人员、受灾房屋、受灾农业、经济损失6 类灾情实体,共10 类实体。综上所述,该试验所用训练集字符总数51237 个,实体总数5265 个;测试集字符总数14296 个,实体总数1 371 个。
3 试验分析
3.1 参数设置
该试验计算机配置为AMD Ryzen 7 PRO 4750U 处理器,16GB 内存,Windows10 操作系统,编程语言Python3.6,TensorFlow1.14.0 框架,使用Adam 优化器调整参数。在BiLSTM 前后加入dropout 层防止过拟合,添加对抗训练提升模型鲁棒性。分层设置学习率可以提高识别效果,将 BiLSTM学习率设置为BERT 学习率的500 倍,具体参数见表1。
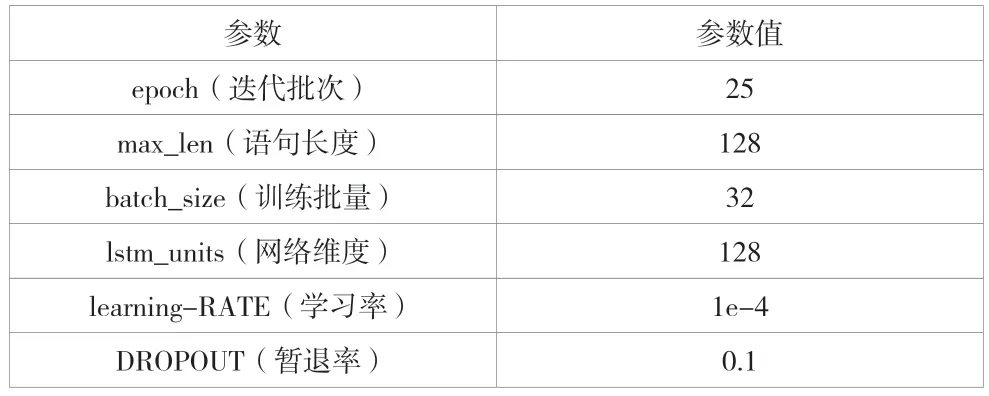
表1 试验参数设置
3.2 评价体系
该文使用精确率(Precision),召回率(Recall),F1值三种指标评价模型精度。精确率代表模型预测结果中正确实体所占比例, 召回率代表输入数据后被正确识别实体所占比例。在命名实体识别任务中通常希望模型兼顾精确率与召回率,F1值可以综合反映模型识别效果,值越高模型综合性能越好。各指标计算如公式(8)所示~如公式(10)所示。
式中:Tp为模型识别出的正确实体数量;Fp为模型识别出的错误实体数量;FN为模型没有识别出的实体数量。
3.3 试验结果
使用BERT-BiLSTM-CRF 模型训练后在测试集上的各指标表现见表2。在四类灾害实体的识别结果中,雷电、冰雹、大雨实体识别效果较好,F1值均在90%以上,原因为雷电、冰雹、大雨三类实体的语义较为简单,表达形式固定。例如,雷电实体在语料中的表述集中在“雷电”、“雷暴”两词,大雨实体集中在“大雨”、“暴雨”等词。大风实体的精确率很高但召回率较低,F1值仅有87.80%,主要原因是训练集中该实体数量明显低于其他灾害实体数量,影响模型训练。在6 类灾情实体的识别结果中,仅有发生地点实体指标较差,F1值88.4%。发生地点精确率召回率较低的主要原因是实体过长,语义表述复杂,例如 “东北地区西南部”,“德宏傣族景颇族自治州陇川县”。通过扩充数据量,或者针对性地迁移训练可以解决上述问题。受灾人员、受灾房屋、受灾农田和经济损失等灾情实体为数值型数据,表达形式固定且具有明显边界特征,因此F1值相对较高。为测试模型泛化能力,随机选取一篇近期新闻报道进行试验,识别结果见表3,结果说明该模型具有良好识别效果。

表2 训练指标

表3 识别结果
为了体现BERT-BiLSTM-CRF 模型在风雹灾害领域实体识别任务中的优势,在相同数据集下使用CBOWBiLSTM-CRF 与Skip-gram-BiLSTM-CRF 模型进行试验,结果见表4。与CBOW-BiLSTM-CRF 模型相比,该文模型识别精确率、召回率、F1值分别提高5.04%、1.47%、3.26%;与Skip-gram-BiLSTM-CRF 模型相比,三类指标分别提高3.87%、0.77%、2.31%。结果表明BERT 模型可以根据语料全局语义关系更好地捕捉语义、句法等相关性特征,生成的词向量更准确丰富、解释性更强,识别效果更好。

表4 对比结果
4 风雹灾害特征分析
Power Query 是用于数据获取与查询的Excel 插件,可在无规律文本中提取处理信息。灾害类别、时间、地点实体可以直接使用,但是受灾人员、受灾房屋、受灾农业、经济损失4 类灾情实体须提取数字进行统计,使用“数字=Text.Remove([灾情实体],{"一".."龟"})”函数对4 类实体的中文字符进行剔除,保留可运算数字类型数据。Power Query中的中文字符以Unicode 形式连续储存,在所有汉字中“一”的Unicode 最小,“龟”最大,利用该特性移除所有中文字符,提取后使用Excel 统计,结果见表5。从时间角度看,风雹灾害属于强对流天气,与大风、暴雨、冰雹、雷电灾害联动发生,主要集中在5—7 月。平均人员伤亡以冰雹为最高,平均农作物受灾平均以冰雹为最高,平均房屋损毁以大风为最高,平均经济损失以冰雹为最高。使用微词云软件对每篇语料的地点实体进行词频统计后,设置三类频次梯度,利用词频结果分析全国风雹发生情况。从空间角度看,风雹灾害发生范围覆盖全国,中西部地区发生频率较高,甘肃云南两省发生次数最多。
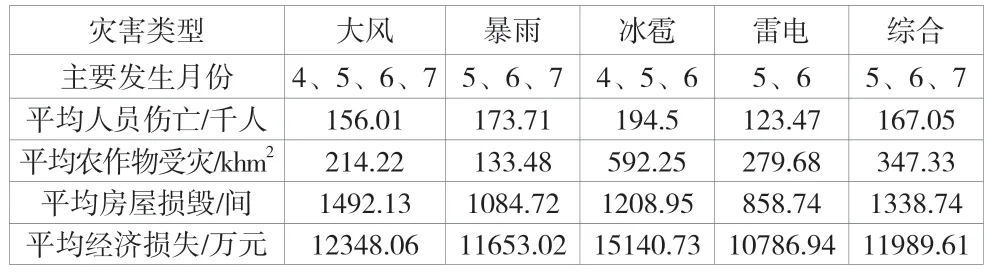
表5 灾情统计
使用Power Query 清洗获取统计数据后,选取月份作为维度绘制灾情数据如图2 所示。从灾情发生特征角度看,风雹灾害全年发生,高发期集中在3—9 月。 3、6、7 月份房屋损毁较多,7—8 月受灾人口较多,5、7 月农作物受灾面积较高,6—7 月经济损失最高的月份,主要原因是处于农忙时期。与表5 进行对比,不同气象灾害具有不同的时间特征,3—4 月发生较频繁的灾害为大风,对房屋的损毁较大,5—7 月4 种灾害都时有发生,因此受灾最严重时也多集中在这个时间段。
5 结语
该文的研究主要基于风雹灾情报告文本,在数据集较少、文本不规则的情况下使用Bert-BiLSTM-CRF 模型,有效识别测试集中相关实体,为风雹灾害处置与减灾提供便利。
自然灾害领域文本具有信息分散、随机性强的特点,目前基于神经网络的实体识别方式仍然存在数据文本单一且收集困难、人工处理数据工作量大、识别结果关联规则利用不足等问题。
针对现有研究的不足,该文提出相应的改进措施:1)扩充数据量,针对非规范化、非标准化的文本数据进行强化学习、迁移训练,进一步提高模型泛化能力。2)实体识别层面结果不足以进行全方位特征支撑起分析,在获得高质量的实体后,对实体关系进行抽取后进一步分析更复杂的关联特征,同时构建风雹灾害知识图谱,为应对灾情提供充足的知识储备。
猜你喜欢
东方剑·消防救援(2022年7期)2022-07-16
农业灾害研究(2022年1期)2022-05-07
东方剑·消防救援(2022年1期)2022-01-17
中国石油石化(2021年16期)2021-10-14
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
少儿美术(快乐历史地理)(2018年7期)2018-11-16
高原山地气象研究(2016年2期)2016-11-10
公民与法治(2016年17期)2016-05-17
