
基于多粒度表征藏文古籍文档版面分析方法研究
2024-01-27 13:41白玛旺久格桑多吉扎西多吉杨欣
电脑知识与技术 2023年36期
关键词:注意力机制
白玛旺久 格桑多吉 扎西多吉 杨欣

摘要:藏文古籍文档版面分析是对文档图像中插图、文本段、文本行、标题等区域信息进行分析并提取的一种方法,是古籍数字化的重要研究课题。相较其他语种的历史文档,藏文古籍文档版面布局呈现出版面结构更加复杂、字体形状和大小风格多样化等特点。该文针对藏文古籍文献特征,构建手写体、印刷体、木刻雕版三种版面结构及字体不同的藏文古籍图像数据集,并将基于CNN和VIsion Transformer并行架构的AFFormer通用语义分割模型迁移到藏文古籍版面分析任务上。在合并数据集上不同版面区域的6个类别平均交并比MIoU达到93.6%。通过实验表明,AFFormer模型对藏文古籍版面分析数据集上的粗粒度版面区域和细粒度文本行检测与提取性能优于其他语义分割的基线模型,该方法在藏文古籍版面分析任务上具有较高的可行性。
关键词:藏文古籍;版面分割;多粒度;注意力机制
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2023)36-0001-03
开放科学(资源服务)标识码(OSID)
0 引言
文档图像的版面布局分析是OCR任务的重要分支,是计算机视觉领域的一个长期研究课题,早期主要是基于规则[1]及机器学习[2]方法进行分割和提取。传统方法适用于简单布局文档分割解析,在处理复杂场景的版面分析仍面临诸多挑战。随着深度神经网络的蓬勃发展,深度学习算法在解决自然语言处理、计算机视觉任务上展现出了强大的可行性。DLA任务可视为经典的视觉对象检测和分割问题,利用卷积神经网络、全卷积神经网络、Transformer以及多模态的视觉特征来解决复杂文档版面布局解析[3]。ChenKai[4]提出基于卷积神经网络的历史文档版面分割方法,在像素级别数据上获得了较好的分割效果。Sofifia[5]提出基于深度学习的通用文档分割方法,该方法针对版面分割出来的不同区域进行特征提取,对提取结果进行分类,实现区域的判别。随着版面分析领域的深入研究,也涌现出优秀的传统方法与深度学习方法结合的版面分析算法。其中, Yang等人[6]提出多模态全卷积版面分析网络,输入文档图像及对应的文本内容,通过编码器得到下采样的视觉特征图,解码器采用文本編码特征向量以及视觉特征图,输出像素级别类别分割结果,在不同数据集的DLA任务上取得良好的性能。
基于深度学习的文档对象检测(DOD)在外语、中文等语种的古籍文档数据集以及印刷体文档数据集上的研究非常成熟,而藏文信息数字化研究相对滞后,文档版面分析任务仍处于研究阶段,藏文古籍文档版面分析主要集中在文本行切分、图像和文本块分割等单粒度任务上。文献[7-8]分别提出基于连通分量分析藏文历史文献文本行切分方法、基于轮廓跟踪以及基于广度优先搜索扩展生长算法的藏文古籍文本行分割的方法,但仍无法有效地解决藏文古籍文档上相邻文本行之间的粘连问题,导致行级分割错误。文献[9]提出了一种基于支持向量机(Support Vector Machine,SVM)版面分割方法,将图像滤波切分为图像块提取特征并训练,然后用SVM对待分割图像中的图像块进行分类,根据分类结果得到粗略版面分割结果,在粗略版面分割结果的基础上结合投影法获得精确版面分割结果,这种方法只能局限在简单单粒度的版面分析任务上。针对以上问题,文献[10]利用判别式对抗网络(Discriminative Adversarial Networks,DAN)框架,提出以语义分割的像素分类实现藏文木刻板古籍文档的版面分割、文本区域检测,该方法在藏文古籍版面结构单一的木刻板古籍文献的文本区域检测与提取具有较好的表现。
上述版面分析算法对于与之相对应的数据集是有效的。然而,不同藏文古籍版面具有不同的特点,版面元素的多样性导致分割效果不佳,如何利用现有深度学习方法实现对藏文古籍图像版面分析,完成图文分割,仍是需要解决的难题之一。
针对收集到的多字体、多风格的手写体、印刷体以及木刻雕版的藏文古籍版面图像数据集,本文使用一种鲁棒的、基于多粒度表征的数据表示方法,将藏文古籍中的文本表征分解为文本区域和文本行两个层次分明又相互关联的不同粒度表示。其中,细粒度表征从局部出发,能更准确地捕获文本位置内部空间信息,结合从全局出发的粗粒度表征方法,可为细粒度表征提供更加鲁棒的结构信息。
从版面布局分析,藏文古籍文档面临结构复杂、图文粘连、风格差异大、图文低质残缺、在手写古籍文档中上下文本行粘连度大、字体大小不一等情况,因此本研究采用CNN和Vision Transformer并行架构的AFFormer分割模型进行像素嵌入和原型表示作为特定的可学习局部描述,取代解码器,保留高分辨率特征上丰富的图像语义特征,最后将不同的语义分割模型应用于藏文古籍版面分析任务上,并对比不同模型的分割效果。
1 数据构建
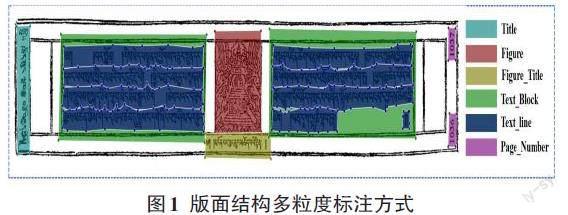
在藏文古籍数字化研究领域中,标注后的图像数据集资源极度稀缺,然而深度学习任务依赖大量的标注数据集来提高模型性能及泛化能力。本文对藏传佛教资源中心(TBRC)发布的藏文古籍文献扫描图进行分类收集,选择2 000张图像数据进行处理,由手写、印刷体、木刻雕板三种藏文古籍文档版面数据类型,采用Labelme图像标注工具对藏文古籍版面进行多点标注,文档版面布局分为背景(Background)、标题(Title)、插图(Figure)、文本块(Text_Block)、文本行(Text_line)、图标题(Figure_Title)、页码(Page_Number)。藏文古籍文献版式多样,文本区域和非文本区域、相邻文本行及相邻字丁之间粘连度大,存在严重的背景干扰或者前景遮挡等情况,影响文本行定位的鲁棒性,因此采取多粒度标注方式。版面布局信息及文本行轮廓标记如图1所示。
图像版面元素标注后生成JSON格式的标注文件,根据原始藏文古籍图像标签坐标生成对应的mask标签图,将数据集转换成模型所对应的输入格式,最终构建2 000张藏文古籍版面分析数据集(Tibetan Ancient Book Layout Analysis Dataset,简称TABLAD),其中手写体藏文古籍版面数据集800张图片、印刷体藏文古籍版面数据集530张图片、木刻雕版藏文古籍版面数据集670张图片。最后,按照8:1:1的比例划分为训练集、验证集、测试集,以便进行模型训练和评估。
2 AFFormer分割模型
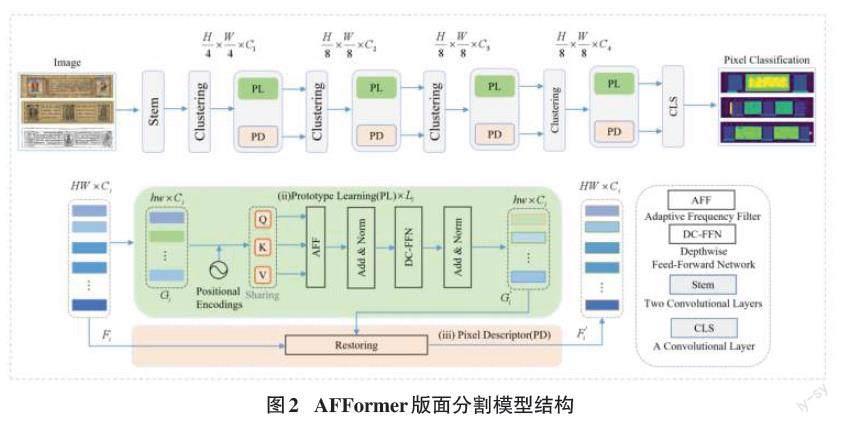
传统语义分割任务主要集中在設计有效的解码器,AFFormer模型采用无头轻量级结构,网络模型总体架构如图2所示。通过引入自适应频率滤波器和卷积神经网络来提升模型的性能和效率,利用基于Transformer的原型表示(Prototype Representations,PR)作为特定可学习的局部描述,去掉解码器,保留高分辨率特征上的丰富图像语义。通过去除解码器来压缩计算量,但在并行结构的精度受到低计算资源的限制,因此该网络采用卷积神经网络(CNN)与Vision Transformer进行像素嵌入和原型表示来节省计算成本,并引入自适应频率滤波器代替标准自注意力机制,增强特征图的边缘信息,从而提高分割的精度。在藏文古籍版面分割任务上,首先输入图像进行补丁嵌入并CNN提取语义特征,将特征聚类为原型特征,通过并行的Transformer网络自注意力机制来捕捉频率信息,最后CNN将圆形表示转换为像素描述。用原型语义来描述像素语义信息,在每个阶段给定一个特征[F∈RH×W×C],将初始化[G∈Rh×w×c]作为图像原型,其中,G中的每个点作为局部聚类中心,其对应区域[α2]中进行加权初始化,公式如下所示:
[G(s)=i=0nwixi]
其中,F表示输入图像嵌入后的特征,G表示原型特征,[n=α×α,wi表示xi]的权重。
3 实验分析
3.1 实验环境及参数设置
本文在自定义四种数据集上进行性能对比,训练过程均基于Ubuntu 20.04.2 LTS操作系统, Python 3.8.17,Pytorch 1.13.1,CUDA 11.7,cuDNN 8.7.1,NVIDIA GeFore RTX 2080Ti GPU 环境下进行实验。
3.2 评价指标
文档版面布局分析任务实质上是多分类任务,文章采用语义分割模型的评估标准对藏文古籍文档扫描图像的粗粒度版面布局和细粒度文本行区域的分割检测结果进行评价。本文藏文古籍版面分割数据集包含背景有7个类别,表示为k+1,i表示真实值、j表示预测值、pij表示i预测为j,计算每一个类别的平均交并比(Mean Intersection over Union,MIoU),计算公式如下所示。
[IoU=intersectionunion=A⋂BA⋃B]
[MIoU=1k+1i=0kTPFN+FP+TP=1k+1i=0kpiij=0kpij+j=0kpji-pii]
其中,TP(True Positive)表示将正类预测为正类,FN(False Negative)表示将正类预测为负类,FP(False Positive)表示将负类预测为正类。
3.3 实验效果
本文构建了三种不同风格的藏文古籍版面数据集,使用UNet、Knet、DeepLabV3+、Segformer、PSPNet、Mask2former、AFFormer模型进行对比实验,从平均交并比(MIoU)指标可以看出AFFormer模型在三种数据集上的分割效果比其他模型有显著提升,在手写体、印刷体、木刻板三种版面数据集上MIoU分别达到93.39%、97.89%、94.89%。具体实验效果可视化如图3所示。
4 结束语
为了解决藏文古籍版面上的图、文本、标题以及上下文本行之间粘连导致边缘轮廓不清晰、上下文信息丢失等问题,本文在藏文古籍版面特点基础上,构建手写体、印刷体、木刻雕版三种不同版面及字体风格的版面分析数据集,并采用多粒度方式标注版面元素位置信息。为了探索藏文古籍版面区域更细粒度的多尺度特征,本文使用卷积神经网络CNN与Transformer融合模型AFFormer版面分割网络。该网络结构轻量化同时能够精准分割藏文古籍版面区域以及多字体古籍文本行,提高对古籍版面区域特征的表征能力,相比文献[10]提出的藏文古籍木刻版文本区域提取方法,AFFormer模型在手写体、印刷体、木刻雕版三种数据集上细粒度文本行区域的检测提取上MIoU均提升5%,表明该算法能较好地平衡不同版面区域分割精度,在藏文古籍多粒度版面分割任务上可行并且有效。
参考文献:
[1] FRANK LE BOURGEOIS,ZBIGNIEW BUBLINSKI,HUBERT EMP-TOZ.A fast and efficient method for extracting text paragraphs and graphics from unconstrained documents[C].ICPR, 1992;272–276.
[2] ANGELIKA GARZ,MARKUS DIEM,ROBERT SABLATNIG.Detecting text areas and decorative elements in ancient manuscripts[C].ICFHR,2010:176–181.
[3] WEI LIU,DRAGOMIR ANGUELOV,DUMITRU ERHAN,et,al.Ssd:Single shot multibox detector[C].ECCV, 2016:21–37.
[4] CHEN K,SEURET M,HENNEBERT J,et al.Convolutional neural networks for page segmentation of historical document images[C]//2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR).Kyoto,Japan.IEEE,2017:965-970.
[5] ARES OLIVEIRA S,SEGUIN B,KAPLAN F.dhSegment:a generic deep-learning approach for document segmentation[C]//2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR).Niagara Falls,NY,USA.IEEE,2018:7-12.
[6] YANG X,YUMER E,ASENTE P,et al.Learning to extract semantic structure from documents using multimodal fully convolutional neural networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu,HI,USA.IEEE,2017:4342-4351.
[7] ZHOU F M,WANG W L,LIN Q.A novel text line segmentation method based on contour curve tracking for Tibetan historical documents[J].International Journal of Pattern Recognition and Artificial Intelligence,2018,32(10):1854025.
[8] 李金成,王筱娟,王维兰,等.结合文字核心区域和扩展生长的藏文古籍文本行切分[J].激光与光电子学进展,2021,58(2):113-123.
[9] 任方针,王秀友,朱弋,等.基于SVM的藏文古籍版面分割[J].阜阳师范大学学报(自然科学版),2021,38(2):92-96.
[10] 贡去卓么,才让加,三知加.基于语义分割的藏文古籍文檔文本区域检测[J].计算机仿真,2022,39(5):448-454.
【通联编辑:代影】
猜你喜欢
计算机应用(2019年3期)2019-07-31
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
现代电子技术(2018年8期)2018-04-13
智能计算机与应用(2017年5期)2017-11-08
