
基于图卷积网络的偏振图像伪装人员检测方法研究
2024-01-27 13:41黄启恒王勇
电脑知识与技术 2023年36期
黄启恒 王勇


摘要:针对伪装人员检测中颜色纹理相似、姿态复杂、局部遮挡严重和传统偏振特征参量存在干扰等问题,提出一种基于图卷积网络的偏振图像伪装人员检测算法。首先,将图映射模块、图卷积模块和图逆映射模块等构建图卷积偏振信息提取网络,提取四方向偏振图像的伪装人员全局偏振特征表示;然后,设计金字塔池化网络融合多尺度偏振特征,并采用分类检测网络对伪装人员识别检测;最后,自建三类伪装模式人员数据集进行检测研究。实验结果表明,所提算法的检测精度相比于经典检测算法都取得明显的提升,有效改善伪装人员检测效果。
关键词:目标检测;偏振成像;深度学习;偏振特征;图卷积网络
中图分类号:TP391.41 文献标识码:A
文章编号:1009-3044(2023)36-0004-05
开放科学(资源服务)标识码(OSID)
0 引言
伪装人员检测是一项新兴的计算机视觉任务,其目的是识别通过伪装技术隐藏于背景环境中的人员,并定位其在图像中的位置。随着多种多样的伪装方式应用于军事领域,具有伪装模式的目标检测难度逐步增加,近年来,虽然通用目标检测算法[1]取得了优异的检测效果,但是在伪装目标检测研究中仍然存在许多挑战,主要包括伪装目标与周围环境之间的边缘相融和颜色高度相似等困难。针对此类困难,本文将主要研究基于军事伪装模式的人员检测算法。
当前的伪装目标检测算法[2-6]主要基于可见光RGB图像提出的,这些检测算法可大致分为两类:基于手工设计特征的伪装目标检测算法[2-4]和基于深度学习特征的伪装目标检测算法[5-6]。其中,由于受到伪装目标固有的纹理特征与环境背景存在巨大差异的启发,一部分基于手工设计特征的检测算法主要集中于提取纹理特征表示伪装目标。例如,SONG等人[2]提出一种包括亮度、纹理方向和熵组成的伪装纹理描述子,再通过特征的权值结构相似度来衡量伪装纹理的性能。文献[3]提取局部的灰度共生矩阵表示纹理特征,然后采用分水岭分割算法检测伪装目标。另一部分基于手工设计特征的检测算法[4]则是提取多尺度的颜色、强度和LBP算子特征表示伪装目标与背景,再计算并融合局部与全局的显著性图来评估伪装目标检测的性能。随着深度学习网络展现出优异的性能,已有部分伪装目标检测算法采用卷积神经网络[5-6]等实现伪装目标的特征表示。
由于可见光RGB图像中伪装目标与背景的颜色、纹理信息差异度甚小的局限性,并且伪装人员相比静态伪装目标存在姿态复杂、局部遮挡严重等问题,使得现有的伪装目标检测器难以获取伪装目标区分性的特征表示。为了准确地检测伪装人员,受偏振光能反映物体固有属性的启发,本文利用偏振图像中伪装人员与背景的差异性,提取偏振特征信息来增强伪装人员与背景的可具区分性表示。虽然现有的偏振特征信息提取方法能利用斯托克斯(stokes)参量有效提取偏振度参量、偏振角参量表示目标,但是由于伪装人员在复杂的背景环境中的偏振度与偏振角信息较弱,如图1所示,采用偏振度与偏振角特征信息表示伪装人员不能有效提升伪装人员检测正确率。因此,受图卷积神经网络具有处理图结构数据优势的启发,本文提出一种基于图卷积网络的偏振图像伪装人员检测算法,获取四个方向(0°,45°,90°和135°)原始偏振图像之间的弱耦合关系,弥补偏振度与偏振角特征信息在非正交方向信息的丢失,提取伪装人员丰富的全局偏振特征信息表示,从而提高伪装人员检测正确率。
综上所述,本文研究工作的主要贡献有:1)针对伪装人员与背景环境的颜色纹理相似、姿态复杂、局部遮挡等问题,本文提出了一种基于图卷积偏振特征提取网络的伪装人员检测算法,学习伪装人员的全局偏振特征信息,增强伪装人员与背景的特征差异,提高伪装人员检测精度。2)针对伪装目标数据集当前只集中于基于可见光RGB图像,本文构建了基于偏振图像的三类伪装模式人员数据集(Multicam数据集、Woodland数据集和ACU数据集)用于偏振信息提取与伪装人员检测的研究。3)本文算法在三个伪装人员数据集上进行大量的验证对比实验,实验结果表明,本文算法的检测精度AP50(%)在Multicam数据集、Woodland数据集和ACU数据集上分别达到90.6%、93.7%、94.5%,均优于大部分经典的检测算法。
1 相关工作
1.1 偏振成像传感器
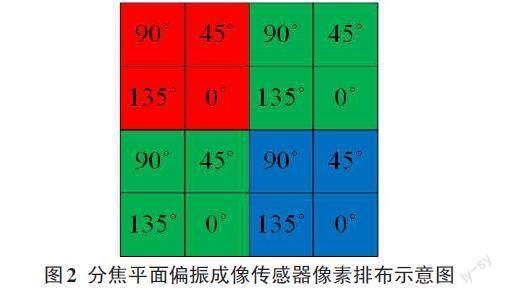
随着纳米制造技术的发展,分焦平面偏振成像技术近年来取得了进步。图2展示本文所用彩色偏振成像传感器的像素排布。与传统的彩色成像传感器相比,这类偏振传感器具有四个不同方向(0°,45°,90°和135°)的微偏振片均匀排列在表面,允许不同像素同时接收各种调制的光强度。在同一滤光片下由四个偏振片组成的像素为超级像素。通过选择超级像素中接收具有相同方向的偏振光的像素值,可以获取不同方向偏振光的四个原始偏振光强度图。超级像素以拜尔模式排列,因此可以通过传统的RGGB插值算法对这四个原始图像进行去马赛克,以获得0°,45°,90°和135°偏振方向的RGB强度图,图像大小为1024×1024。
1.2 线偏振光计算
使用偏振成像相机可以获得四个方向(0°,45°,90°和135°)偏振光强度分量:[I0]、[I45]、[I90]、[I135],从而能计算斯托克斯参量为:
[S0=12(I0+I45+I90+I135)S1=I0-I90S2=I45-I135S3=Ilh-Irh] (1)
其中,[S0]表示總光强度,[S1]表示0°和90°相互正交的线偏振光强度分量,[S2]表示45°和135°相互正交的线偏振光强度分量,[S3]表示圆偏振光,[Ilh]是左旋偏振光,[Irh]是右旋偏振光,由于人造目标的圆偏振特性并不明显,可忽略[7]。
利用[S0]、[S1]、[S2]三个参量可以计算提取偏振信息的两个常用参考度量,分别是偏振度(DoLP)和偏振角(AoP):
[DoLP=S21+S22S0AoP=12tan-1(S2S1)] (2)
其中,偏振度(DoLP)用于表示线偏振光强度在总光强中的比例,而偏振角(AoP)描述的是最强光矢量振动的方向。偏振度图像和偏振角图像可以通过对四个不同偏振方向的光强图像进行像素运算来获得。
1.3 伪装目标检测
早期的伪装目标检测集中于检测具有纹理、颜色、梯度和运动[8]视觉特征的伪装目标。在实际应用中,单一的视觉特征不能完全准确地表示伪装目标。因此,集成多种特征以提高检测性能[9]。此外,贝叶斯框架已被用于视频中的运动伪装目标检测[10]。尽管这些算法展现出一定的优势,但依靠现有的手工设计的特征表示检测方法在现实应用中往往会检测失败,因为它们只能在相对简单环境背景中实现检测。为此,采用了深度学习特征,并以端到端方式进行训练的模型来实现准确的伪装目标检测。例如,YAN等人[11]提出了一种称为MirrorNet的双流网络,用于具有原始图像和翻转图像的伪装目标检测,其潜在的动机在于翻转的图像可以为伪装目标检测提供有价值的信息。LAMDOUAR等人[12]通过深度学习框架利用运动信息从视频中识别伪装目标,该框架由两个模块组成,即可微分配准模块和运动分割模块。LI等人[13]提出了一种具有相似性测量模块的对抗性学习网络,用于对矛盾信息进行建模,增强了检测显著目标和伪装目标的能力。不同于现有的方法,本文算法将提出一种基于图卷積网络的偏振图像伪装人员检测方法,提取伪装人员全局偏振特征信息表示。
2 基于图卷积网络的偏振图像伪装人员检测方法
2.1 方法总述
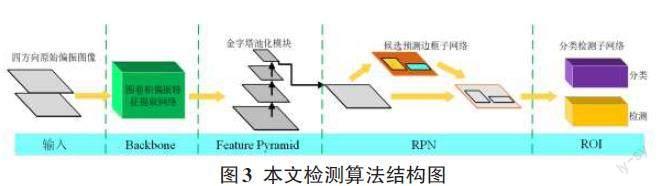
本文检测算法基于Faster-RCNN检测算法[14]提出的,如图3所示。其中,有效提取偏振图像中的偏振信息是提升伪装人员检测正确率的关键。受偏振信息能反映物体材质固有属性的启发,结合伪装人员与背景环境偏振信息存在巨大差异,本文提出一种基于图卷积网络的偏振信息提取与检测算法,利用图卷积网络学习全局偏振特征信息,提高伪装人员检测正确率。本文检测框架主要包括图卷积偏振信息提取网络、金字塔池化模块与检测器。四方向的偏振图像作为输入,经过图卷积偏振信息提取网络提取增强的全局偏振特征,然后输入金字塔池化模块进行多尺度融合得到特征图,最后将融合的特征图输入由候选预测边框子网络(RPN)和分类检测子网络(ROI)组成的检测器中进行伪装人员的分类与检测。
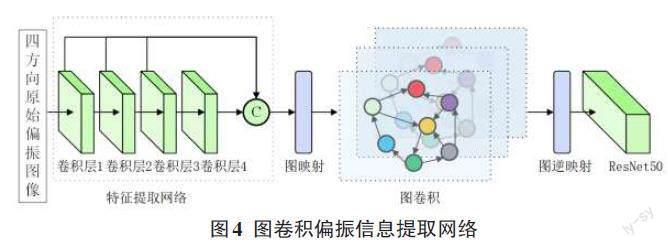
2.2 图卷积偏振信息提取网络
如图4所示,图卷积偏振信息提取网络主要由特征提取网络、图映射模块、图卷积网络模块、图逆映射模块和残差网络(ResNet50)[15]组成。
1)特征提取网络
特征提取网络由四层1×1的卷积块组成,卷积块由卷积层,批归一化层(BN层)和非线性激活函数ReLU函数组成。卷积块操作如式(3)所示:
[Fi=fconv(ReLU(BN(conv1×1(xi))))] (3)
式中[fconv(⋅)]表示卷积块完整运算,[xi]表示输入图像,[conv1×1(⋅)]是1×1卷积运算,[BN(⋅)]表示批归一化运算,[ReLU(⋅)]是非线性函数,[Fi]表示经过卷积块运算后的输出特征向量。本文的特征提取网络的输出特征向量是第四层卷积块的输出特征向量与第一层、第二层、第三层卷积块的输出特征向量进行像素相加操作而得到的。给定输入的四个方向的偏振图像表示为[x0,45,90,135],经过特征提取网络后得到输出向量[Fc],其运算过程如式(4)所示:
[F1=fconv(ReLU(BN(conv1×1(x0,45,90,135))))F2=fconv(ReLU(BN(conv1×1(F1))))F3=fconv(ReLU(BN(conv1×1(F2))))F4=fconv(ReLU(BN(conv1×1(F3))))Fc=F1⊕F2⊕F3⊕F4] (4)
式中[F1,F2,F3]分别表示第一层、第二层、第三层卷积块的输出特征向量。
2)图映射模块
图映射模块由一层1×1的卷积层和图映射表示操作组成。给定输入特征向量为[Fc∈Rh×w×c];首先,采用1×1的卷积层将特征向量转换成低维特征,表示为[Flc∈Rh×w×c];然后,利用图映射表示操作将特征向量转换为图节点嵌入表示[Vc∈Rc×k]。采用文献[16]的策略,将图映射表示操作参数化为[W∈Rk×c]和[Σ∈Rk×c]。其中参数[W]中的每一列[wk]表示第[k]个节点的可学习中心参数,具体来看,每个节点表示可通过式(5)计算:
[vk=v′kv′k2,v′k=1iqikiqik(fi-wk)/σk] (5)
其中[σk]是参数[Σ]的列向量,[v′k]是特征向量[fi]与[wk]残差值的加权平均。[vk]是第[k]个节点的表示,并且构成节点特征矩阵[V]的第[k]列。[qik]是特征向量[fi]到[wk]的软分配,可以用下式计算:
[qik=exp(-(fi-wk)/σk22/2)jexp(-(fi-wk)/σk22/2)] (6)
其中“/”表示逐位相除。图邻接矩阵是通过测量类内节点表示之间的亲和度来计算的:[Αintra=fnorm(VΤ×V)∈Rk×k],其中[fnorm]表示归一化运算。
3)图卷积网络模块
本文将[Vc]输入图卷积网络模块中进行图内推理来增强图表示,从而得到伪装人员的偏振特征表示。图卷积运算[fgc]的实现与文献[16]中相似:
[V′c=fgc(Vc)=g(AintracVcWc)∈Rc×k] (7)
其中[g(⋅)]是非线性激活函数,[Wc]是图卷积层可学习的参数,和[Aintrac]表示[Vc]图邻接矩阵。
4)圖逆映射模块
为了把增强后的偏振信息图表示映射回原始空间中,本文将重新访问图映射模块步骤中的分配值。具体来看,假定基于偏振图像伪装人员特征表示的分配矩阵为[Qc=qkcK-1k=0],其中[qkc=qic(h×w)-1i=0]。图逆映射运算可以定义为式(8):
[Fc=QcVΤc+Flc,Qc∈R(h×w)×k] (8)
其中[Fc]表示的是增强后伪装人员的偏振特征信息。最后,将[Fc]输入ResNet50网络中提取四个不同尺度的特征向量[F1c,F2c,F3c,F4c]。
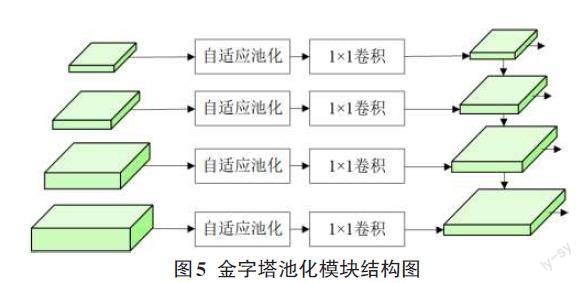
2.3 金字塔池化模块
金字塔池化模块主要进行不同尺度特征向量的提取,从而克服伪装人员姿态复杂的问题。在金字塔网络(FPN)[14]的基础上,本文设计了一种金字塔池化模块,主要由四个自适应池化分支组成,如图5所示。金字塔池化模块的输入向量为[F1c,F2c,F3c,F4c],经过自适应池化操作[Avepool(⋅)]后,再分别经过1×1卷积层运算[conv1×1(⋅)]后得到特征向量,如式(9)所示:
[Fp1=conv1×1(Avepool(F1c))Fp2=conv1×1(Avepool(F2c))Fp3=conv1×1(Avepool(F3c))Fp4=conv1×1(Avepool(F4c))] (9)
最后,输入金字塔网络中进行多尺度特征图的融合,具体来说,使用上采样操作将较高层级的特征图进行插值得到与相应低层级特征图尺寸相匹配的特征图,然后通过逐元素相加的方式将它们进行融合。
3 实验分析
为了验证本文算法检测伪装人员的准确率,本文构建了三个基于偏振图像的伪装人员数据集,并与目前大部分检测算法进行大量的对比实验。同时,对图卷积网络提取偏振信息的有效性进行验证实验。
3.1 实验设置
1)数据集
基于偏振图像的伪装人员数据集共由3类伪装模式、4712张偏振图像组成,其中可划分为1 506张图像的Woodland伪装人员数据集(Woodland)、1 706张图像的ACU伪装人员数据集(ACU)和1 500张图像的Multicam伪装人员数据集(Multicam)。数据集中的偏振图像由分焦平面彩色偏振相机(LUCID TRI050S-QC)采集得到,采用偏振图像去马赛克处理算法将原始偏振图像处理为四个方向偏振图像(0°,45°,90°,135°)。数据集中伪装场景主要包括树林、林地和灌木林等,季节包括春季、夏季和冬季等,伪装人员姿态复杂多变,部分遮挡场景较多,检测难度较大。训练集与测试集按照9:1比例划分,训练集由4 242张偏振图像组成,测试集由470张偏振图像组成。采集得到的原始偏振图像大小为2 048×2 048。
2)参数部署
本文所提算法基于Pytorch框架进行训练,调整训练阶段网络的输入图像(resize)宽高为640×640,训练最大迭代轮次(epoch)为100,初始学习率设置为0.001,每次迭代数量为16,训练时优化方法选择随机梯度下降法(SGD),在搭载8块NVIDIA GTX 1080Ti的服务器上训练本文所提出的网络模型时长约18小时。
3)评价准则
本文采用检测精度AP来评价模型算法,其表示伪装人员的检测正确率。检测精度AP由精确率和召回率计算,精确率[P]计算公式为:
[P=TPTP+FP] (8)
召回率[R]计算公式为:
[R=TPTP+FN] (9)
其中TP表示被正确地预测为伪装人员的个数,FP表示被正确地预测为非伪装人员的个数,FN表示被错误地预测为非伪装人员的个数。而检测精度AP则为:
[AP=1μr∈μpin(r)] (10)
式中,[μ]表示给定召回率[R]的个数,[pin(r)]表示大于给定召回率在所有召回率中对应的最大精确率。
3.2 对比实验分析
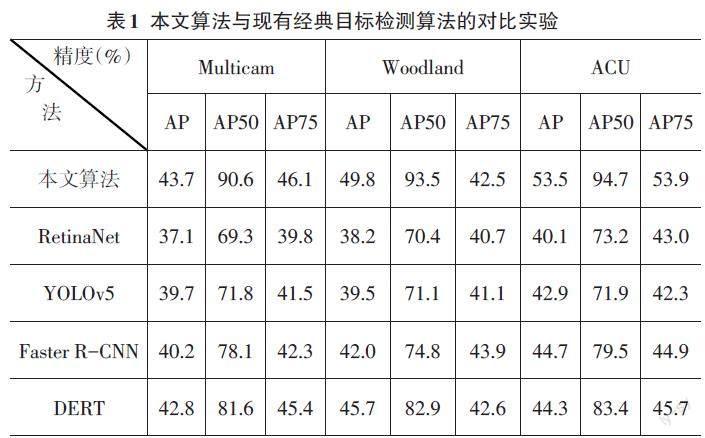
为了验证本文所提算法的伪装人员检测正确率,将本文算法与现有的经典目标检测算法RetinaNet[17]、YOLOv5[18]、Faster R-CNN[14]和DERT[19]在Woodland数据集、ACU数据集和Multicam数据集上进行对比实验。实验结果如表1和图6所示,表中为检测精度AP(%)、AP50(%)和AP75(%),加粗数据为每一列中的检测精度的最高值;图6中红色边框表示在三个数据集上伪装人员的检测结果(为了便于读者阅读,本文将偏振图像转化为RGB图像进行展示检测结果)。
从表1中可以看出,本文算法的检测精度AP(%)、AP50(%)和AP75(%)在三個数据集上均高于四种经典目标检测算法检测精度,其中,本文算法检测精度AP(%)在Multicam数据集、Woodland数据集和ACU数据集分别高于DERT算法0.9%、4.1%和9.2%。虽然这四种算法在通用目标检测精度较好,但是由于伪装人员的颜色、纹理信息高度相似性,很难提取伪装人员的可区分性特征表示,导致伪装人员检测精度不高。而本文算法将基于偏振图像提取伪装人员的差异性偏振特征,有效提升检测精度。
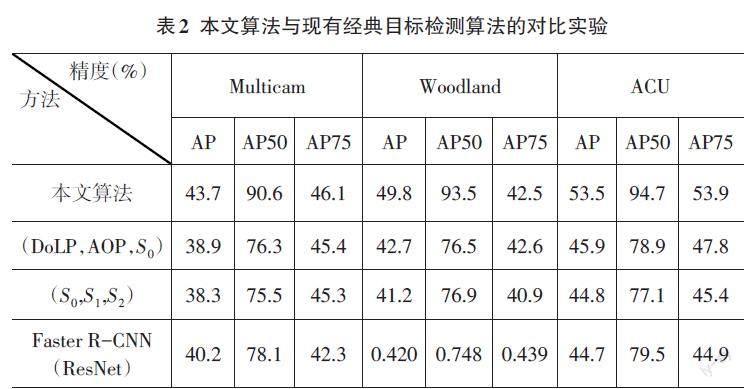
3.3 消融实验分析
为了验证图卷积网络学习偏振图像中伪装人员的全局偏振信息的效果,将本文的图卷积偏振信息提取网络与传统的偏振特征偏振度、偏振角等进行验证对比实验。如表2所示,表中第二行表示是将偏振度图(DoLP)、偏振角图(AoP)与总强度图([S0])组合作为检测器的输入进行实验的检测精度AP(%)、AP50(%)和AP75(%)的结果。第三行是将斯托克斯参量[S0]、[S1]和[S2]组合作为检测器的输入进行实验的检测精度结果。第四行是没有采用图卷积网络提取偏振特征,而是利用卷积神经网络ResNet[15]提取偏振特征后进行伪装人员检测的精度结果。
从表中可以看出,本文算法的检测精度AP(%)、AP50(%)和AP75(%)均高于传统偏振特征参量图像组合和斯托克斯参量图像组合,同时,也优于利用卷积神经网络ResNet[15]提取偏振特征的检测精度。实验结果表明,本文算法中的图卷积网络能有效利用非正交方向的偏振特性之间关系,学习获得伪装人员与背景的差异性特征表示,从而有效提高检测精度。
4 结束语
为了解决和克服伪装人员颜色纹理相似、姿态复杂、局部遮挡严重,以及传统偏振特征参量在伪装模式下的干扰性等问题,本文提出一种基于图卷积网络的偏振图像伪装人员检测算法架构,该架构主要包括图卷积偏振信息提取网络、金字塔池化网络和检测器三部分组成。利用图卷积网络学习偏振图像中的全局偏振特征表示,增强伪装人员与背景的差异性信息。构建了三类伪装模式的自建伪装人员数据集,通过大量实验表明,本文所提算法检测精度均优于现有的经典检测算法,有效提升伪装人员检测的正确率。
本文仅针对伪装人员检测进行了实验验证,在其他伪装模式和伪装目标中还应继续研究。后续基于偏振图像的伪装人员检测研究工作还将进一步探索更多伪装模式下的偏振特性表示,对于算法模式的鲁棒性与泛化能力还将继续研究提升。
参考文献:
[1] 史宇.利用深度学习进行目标检测[J].电脑知识与技术,2022,18(24):88-90.
[2] SONG L M,GENG W D.A new camouflage texture evaluation method based on WSSIM and nature image features[C]//2010 International Conference on Multimedia Technology.Ningbo,China.IEEE,2010:1-4.
[3] BHAJANTRI N U,NAGABHUSHAN P.Camouflage defect identification:a novel approach[C]//9th International Conference on Information Technology (ICIT'06).Bhubaneswar,India.IEEE,2006:145-148.
[4] XUE F,CUI G Y,HONG R C,et al.Camouflage texture evaluation using a saliency map[J].Multimedia Systems,2015,21(2):169-175.
[5] LE T N,NGUYEN T V,NIE Z L,et al.Anabranch network for camouflaged object segmentation[J].Computer Vision and Image Understanding,2019,184:45-56.
[6] FAN D P,JI G P,SUN G L,et al.Camouflaged object detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle,WA,USA.IEEE,2020:2774-2784.
[7] 曾恒亮,张孟伟,刘征,等.利用偏振特性因子的偏振成像目标探测实验[J].光电工程,2016,43(2):22-26.
[8] MONDAL A.Camouflaged object detection and tracking:a survey[J].International Journal of Image and Graphics,2020,20(4):2050028.
[9] JIANG Z H.Object modelling and tracking in videos via multidimensional features[J].ISRN Signal Processing,2011,2011:173176.
[10] ZHANG X,ZHU C,WANG S,et al.A Bayesian approach to camouflaged moving object detection[J].IEEE Transactions on Circuits and Systems for Video Technology,2017,27(9):2001-2013.
[11] ZHANG L,DAI J,LU H C,et al.A Bi-directional message passing model for salient object detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA.IEEE,2018:1741-1750.
[12] LAMDOUAR H,YANG C,XIE W D,et al.Betrayed by motion:camouflaged object discovery via motion segmentation[C]//Proceedings of the Asian Conference on Computer Vision,2020.
[13] LI A X,ZHANG J,LV Y Q,et al.Uncertainty-aware joint salient object and camouflaged object detection[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Nashville,TN,USA.IEEE,2021:10066-10076.
[14] REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[15] HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas,NV,USA.IEEE,2016:770-778.
[16] KIPF T N,WELLING M.Semi-supervised classification with graph convolutional networks[EB/OL].[2022-10-20].https://arxiv.org/abs/1609.02907.
[17] LIN T Y,GOYAL P,GIRSHICK R,et al.Focal loss for dense object detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(2):318-327.
[18] 王楊,曹铁勇,杨吉斌,等.基于YOLO v5算法的迷彩伪装目标检测技术研究[J].计算机科学,2021,48(10):226-232.
[19] SIRISHA M,SUDHA S V.TOD-Net:an end-to-end transformer-based object detection network[J].Computers and Electrical Engineering,2023,108:108695.
【通联编辑:谢媛媛】
猜你喜欢
江苏教育·中学教学版(2016年11期)2016-12-21
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
科学与财富(2016年28期)2016-10-14
现代电子技术(2015年14期)2015-07-22
