
一种基于动态时序划分的视频理解方法
2024-01-27 13:41董淑慧
电脑知识与技术 2023年36期
关键词:语言
董淑慧
摘要:近年来,随着语言-视觉模型的快速发展,结合视觉编码器和大语言模型进行视频理解的方法极大超越了传统的视频行为分类模型。由于大语言模型可以很好地进行信息的归纳和推理,因此可以将视频帧的特征输入大语言模型,从而得到每一帧的场景描述,最终整理成一个视频的详细信息。尽管上述方法可以得到一个视频非常详尽的描述,但是却忽略了视频中不同场景的重要性,从而无法准确理解视频中的关键信息。文章提出了一种基于动态时序划分的视频理解方法,首先根据场景对视频进行切片,然后通过一个自适应的重要性评估网络计算每个视频切片的重要性得分,最后基于重要性得分将每个视频切片的特征进行加权平均得到最终的视频特征。相较于直接提取视频特征的方法,该方法所获取的视频特征结合了不同视频片段的重要性,更容易理解视频中的关键信息。该方法在多个视频理解基准上进行实验,均获得5%~10%的提升,充分证明了该方法在视频理解中的有效性。
关键词:语言-视觉模型;动态时序划分;视频切片;视频理解
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)36-0019-03
开放科学(资源服务)标识码(OSID)
0 引言
视频是人类进行信息传递过程中一个非常重要的载体,它结合了视觉、音频、文本等信息,即使是一个很短的视频片段,也集成了丰富的信息量。因此,设计一个机器用于理解视频是研究人员一直努力的目标。相较于图像理解而言,视频数据最大的难点在于时序信息难以编码。时序信息表示的是不同视频帧之间信息的变化,这是视频特征需要表示的一个关键信息。
为了能够有效地编码视频中的时序信息,以前的研究工作主要有两种方法。其中一种是使用3D卷积神经网络(简称 CNN)直接对视频进行编码[1-2],这种方法完全依赖于卷积网络,能够学会如何提取不同帧之间的时序信息。随着近些年来视觉编码器性能的飞速发展,图像编码器能够提取到泛化性能很强的图像特征,因此直接对单帧图像特征进行池化也能够获取到视频的特征[3]。第一种方法获取到的视频特征依赖于训练卷积网络过程中的下游任务,对于不同的下游任务都需要重新训练。第二种方法可以直接使用一个预训练模型对视频进行编码,不需要重新训练,可以很好地泛化到不同的下游任务。
上述的两种视频特征提取的方法都存在一个问题,这些方法无法获取到视频在不同片段中的重要性。例如,在一部电影这种长视频中,重要的关键情节只占其中的一小部分,如果對所有时间都采用相同的做法进行编码,则无法准确理解电影中的核心情节。为了解决上述方法所存在的问题,本文提出了一种基于动态时序划分的方法,首先根据情节对视频进行切片,然后再计算不同切片之间的重要性。本方法结合了上述两种方法的优点,既能够结合连续多帧的信息,又能够关注到每一帧中的细节。
1 基于动态时序划分的时序理解方法
1.1 视频理解框架
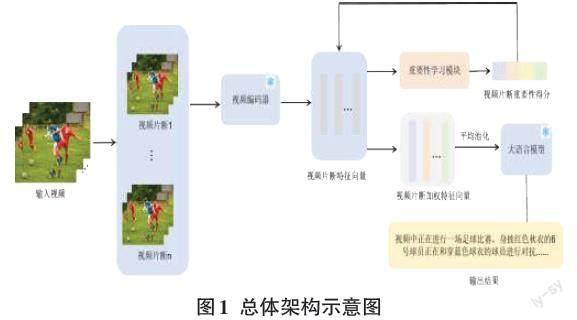
在本文提出的视频理解框架中,最主要的思想是通过重要性学习模块区分不同视频片段的重要性,内容更丰富的视频片段在最后的视频特征中占有更大的比重。这种方法可以让大语言模型在理解视频的时候更着重于关键内容,使得大语言模型输出更符合视频内容的描述。具体结构如图1所示。
整个流程分为三个部分,完整的视频记作[V],首先使用视频切片工具PySceneDetect[4]将视频切成多个片段,[V={v1, v2, ...,vn}],这样可以根据不同的情节独立编码视频。然后使用视频编码器[Fv]对每个视频片段提取特征,由于当前已经有很多泛化性能很强的视频编码器,因此这里直接加载预训练的模型参数[5],并且冻结该部分。具体的计算过程如式(1)所示。
[E={e1, e2, ...,en} = Fv(V), E∈Rn×d] (1)
视频编码器输出的每个视频片段的特征向量[E={e1, e2, ...,en}],每个特征向量的维度为[d]。为了得到不同视频片段在完整视频中的重要性得分,将每个视频片段输入到一个重要性学习模块[Fs]。为了让模型的结构尽可能简洁,这里使用一个多层感知机(简称MLP)来实现重要性学习模块。重要性学习模块输出的是每个视频片段的重要性得分记为[S]。如式(2)所示。
[S={s1, s2, ...,sn} = Fs(E), s1+ s2+ ...+sn = 1] (2)
得到每个视频片段特征向量的权重得分之后,将得分分别乘上对应的特征向量,然后对加权之后的特征向量进行平均池化,得到最终完整视频的特征向量T。相较于最大值池化而言,平均池化更加适合视频理解任务。因此在一个完整的视频中,虽然重要的情节占其中很大的比例,但是情节平淡的视频片段也能够帮助大语言模型更全面地分析视频的内容。如式(3)所示。
[T=1n1n(s1e1 +s2e2 +... + snen )] (3)
最后,需要将完整的视频特征输入大语言模型中,最终输出视频详细的描述。在早些年的大语言模型如GPT-3[6]中,模型的输入限制只能是文本特征,并不支持视觉信息的理解。后续有一些工作如CLIP[5]在大批量的图像-文本对中预训练多模型,从而可以对齐文本特征与视觉特征。于是这种思想被引入大语言模型中,由于视觉特征可以对齐到文本特征,因此可以将视觉的特征直接输入大语言模型中,得到图片或者视频中内容的描述[7]。
1.2 重要性评估模块
在视频内容分析的流程中,重要性评估模块扮演着关键角色。此模块的核心任务是评估每个视频片段在整个视频中的重要性,为后续的视频理解和特征提取提供依据。具体实现上,这一模块采用了多层感知机(MLP)的结构,它能有效地学习和识别视频片段的重要性特征。这个模块是整个框架中唯一需要参数调整的模块,由于视频编码器和大语言模型参数都是冻结的,所有该方法的训练是极其轻量化的。
首先,从视频编码器提取出的特征向量被输入重要性评估模块。多层感知机通过其多层结构对这些特征进行深度分析,从而评估每个视频片段的重要性。这一过程通过一系列的非线性变换,使得模型可以捕捉到视频片段中复杂的、层次性的特征。
输出的是每个视频片段的重要性得分,这些得分反映了各个片段对于整体视频内容理解的贡献度。通过这种方式,模型能够区分哪些片段是关键的(如剧情高潮、重要事件等),哪些则相对次要。这种分辨能力对于后续的特征融合和视频理解至关重要,能够确保大语言模型在分析视频时关注到最关键的内容。
除了上述的作用外,重要性评估模块还有一个重要的功能是进一步对齐视觉特征和文本特征。由于视觉编码器和大语言模型都是分别进行预训练,这两个模型并不在一个特征空间中。如果直接将视觉编码器输出的特征向量直接输入大语言模型,会造成极大的语义偏差。在引入重要性评估模块之后,在训练过程中除了学习不同视频片段的重要性得分之外,同时也在不断拉齐视觉编码器和大语言模型之间的特征偏差。
1.3 大语言模型
在视频内容分析的最后阶段,大语言模型的作用是将处理过的视频特征转化为详细的视频描述。这一过程标志着从纯视觉信息到文本描述的转换,是理解和表述视频内容的关键步骤。
早期的大型语言模型,如GPT-3,主要限于处理文本信息,无法直接处理视觉信息。但随着技术的发展,出现了如CLIP这样的多模态预训练模型,它们能够在大规模图像-文本对数据上进行预训练,实现视觉特征与文本特征的对齐。这種技术的发展使得大语言模型能够直接处理视觉信息。
在整个视频理解流程中,经过重要性评估和特征提取后,视频的视觉特征被转换为与文本特征相对齐的格式。这些特征随后被输入大语言模型中。模型利用其强大的文本生成能力,结合输入的视觉特征,生成对视频内容的详细描述。这种描述不仅包括视频的基本内容,还能深入揭示视频的情感色彩、叙事结构等更加复杂的层面。
总之,大语言模型在视频内容分析中的应用,极大地拓展了其在多模态理解领域的可能性,为视频内容的深度理解和描述提供了强有力的工具。
2 实验结果
2.1 实验条件与基准
为了更加全面、公平地评估本文提出的方法,采用与Video-ChatGPT[8]相同的评测基准。基于ActivityNet-200[9]数据集,来定量评估该方法生成文本描述的准确性。这个评测基准会从5个方面来衡量模型的性能,分别是信息的准确性、细节的完整性、上下文理解、时序理解以及回复一致性。并且会从两个主要的对比实验来观察该方法的特性,第一个对比实验是比较与当面最先进方法的一些差距,第二个实验是对比添加与不添加重要性评估模块对最终结果的影响。
2.2 对比结果分析
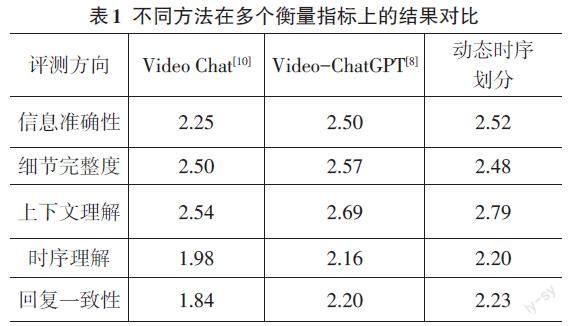
通过与当前最先进的视频理解方法在多个衡量角度的对比,可以看出本文提出基于动态时序划分的视频理解方法在很多方面有着非常明显的优势。具体如表1所示。
实验结果表明,动态时序划分方法在视频内容分析中整体上表现出色,尤其在上下文理解、时序理解和回复一致性方面优于以往的Video Chat和Video-ChatGPT方法。它通过更精确地分析视频的内容结构,能够更有效地理解视频内容的上下文和时间发展,从而在保持信息准确性和回复一致性方面表现更好。虽然在细节完整度方面略逊于Video-ChatGPT,这是因为重要性评估模块会减弱一些平淡情节对最终视频描述的影响,但其在处理具有复杂时序和上下文关系的视频内容方面的整体优势是明显的。
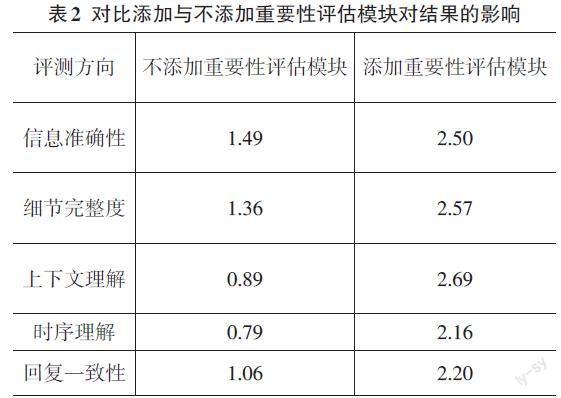
从表2的实验对比可以看出,添加重要性评估模块显著提升了视频内容分析的性能。在所有评测方向上,使用重要性评估模块的方法比不使用时表现得更好。具体来说,信息准确性、细节完整度、上下文理解、时序理解和回复一致性都有了显著的提升。这些改进突出了重要性评估模块在视频分析中的关键作用,特别是在理解视频内容的上下文和时序方面。通过准确评估每个视频片段的重要性,这一模块有效地指导了整个分析过程,确保了结果的准确性和一致性,同时也提高了对视频细节的完整捕捉。这表明在视频内容分析中,重要性评估模块是不可或缺的一个环节。
从结果中还能看出,如果没有添加重要性评估模块,在所有评测方向都会有极大的性能下降。这也充分证明了重要性评估模块不仅仅能够帮助大语言模型更好地理解视频,而且还在对齐视觉特征与语言特征中起到的关键作用。如果没有该模块,视觉特征和语言特征之间有着较大的偏差,从而导致在所有的评测中都展现了极差的结果。
3 结束语
为了解决以往视频理解方法中都忽略了不同情节重要性的问题,本文提出了一种基于动态时序划分的视频理解方法。通过重要性评估模块对不同视频片段进行打分,然后将得分作为权重对视频片段特征进行加权平均,从而得到最后的视频特征。融合了不同视频片段重要性的视频特征输入大语言模型,能够更好地帮助大语言模型去理解视频中重要性更高的情节。同时,重要性评估模块也帮助模型能够更好地对齐视觉特征与语言特征,从而得到更准确的结果。最后,本文从5个评估方向全面对比最先进方法的结果,证明了该方法在视频理解中的有效性。
参考文献:
[1] TRAN D,BOURDEV L,FERGUS R,et al.Learning spatiotemporal features with 3D convolutional networks[C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago,Chile.IEEE,2015:4489-4497.
[2] FEICHTENHOFER C,FAN H Q,MALIK J,et al.SlowFast networks for video recognition[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).Seoul,Korea (South).IEEE,2019:6201-6210.
[3] WANG Y,LI K C,LI Y Z,et al.InternVideo:general video foundation models via generative and discriminative learning[EB/OL].[2023-03-10].2022:arXiv:2212.03191.https://arxiv.org/abs/2212.03191.pdf.
[4] Pyscenedetect:Video scene cut detection and analysis tool[EB/OL].[2023-05-10].https://www.scenedetect.com/.
[5] RADFORD A,KIM J W,HALLACY C,et al.Learning transferable visual models from natural language supervision[EB/OL].[2023-03-10].2021:arXiv:2103.00020.https://arxiv.org/abs/2103.00020.pdf.
[6] BROWN T B.Language models are few-shot learners[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Red Hook, NY, USA. Curran Associates Inc,2020.
[7] LI J N,LI D X,XIONG C M,et al.BLIP:bootstrapping language-image pre-training for unified vision-language understanding and generation[C]//International Conference on Machine Learning,2022.
[8] MAAZ M,RASHEED H,KHAN S,et al.Video-ChatGPT:towards detailed video understanding via large vision and language models[EB/OL].[2023-03-10].2023:arXiv:2306.05424.https://arxiv.org/abs/2306.05424.pdf.
[9] HEILBRONB G F C,ESCORCIA V,NIEBLES J C.Activitynet:A large-scale video benchmark for human activity understanding[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:961-970.
[10] LI K C,HE Y N ,WANG Y,et al.Videochat:Chat-centric video understanding[EB/OL].[2023-06-02].https://arxiv.org/pdf/2305.06355v1.pdf.
【通聯编辑:谢媛媛】
猜你喜欢
延安大学学报(自然科学版)(2020年1期)2020-12-16
学苑创造·A版(2019年5期)2019-06-17
小学生作文(中高年级适用)(2018年3期)2018-04-18
疯狂英语·新策略(2017年8期)2017-05-31
华北电力大学学报(社会科学版)(2016年4期)2016-12-01
新闻传播(2016年10期)2016-09-26
玉溪师范学院学报(2015年1期)2015-08-22
语文知识(2014年10期)2014-02-28
海外英语(2013年2期)2013-08-27
学苑创造·A版(2009年4期)2009-05-27
