
基于Interlaken协议的高速数据流接口设计与性能分析
2011-05-21 00:42陈世文李玉峰杨柳青
电子设计工程 2011年13期
陈世文, 郭 通,李玉峰,2,王 鹏, 杨柳青,3
(1.解放军信息工程大学 河南 郑州450002;2.防空兵指挥学院 信息控制系,河南 郑州450052;3.中国移动河南信阳分公司 河南 信阳464000)
互联网链路速率的飞速发展对路由器线路接口板的设计不断提出新的要求。为解决线路接口板中器件间的高速数据交互问题,带时钟与数据恢复的新串行技术、差分信号技术等被普遍应用,使器件的数据总线速率从每管脚约100 Mb/s提升到每差分对管脚可达数Gb/s,从而使单个器件的数据流吞吐速率大大提高。在核心路由器40 Gb/s POS线路接口板的设计中,链路层处理芯片与转发、调度处理FPGA间的数据交互速率高,且要求采用8对差分线完成,每对差分线为一个通道,每通道速率需达到6.25 Gb/s。为满足这一器件间的高速数据流接口设计需求,除了考虑硬件设计工艺外,还必须采用高效率、高可靠的包传输互连协议,利用多个串行链接,完成具有通道化、流控背压和数据完整性保护能力的数据通信。系统设计中采用Interlaken协议[1],在FPGA中实现其功能IP核,传输时先将数据包切割成一个个突发数据字,前后加入控制字,然后将由数据字与控制字组成的突发按照每8字节一个通道进行条带化后成帧进行传输[2]。通过利用高端FPGA的高速通道和Interlaken IP核[3]设计技术,完成了链路层处理芯片与FPGA之间数据包的高速互联,满足系统40 Gb/s吞吐率的要求,并就不同应用场景中IP核关键参数与控制寄存器的配置进行了探索。
1 高速数据流接口需求分析
核心路由器40 Gb/s POS线路接口板原理框图如图1所示,链路层处理模块采用Cortina公司的CS1999芯片,内含Interlaken硬核。FPGA采用Xilinx V5系列器件XC5VTX240T[4],在FPGA内部实现高速串行连接、Interlaken接口协议与转发、调度处理等功能。链路层处理芯片和转发、处理FPGA之间按要求采用8对差分线连接,每对差分线速率为6.25 Gb/s。
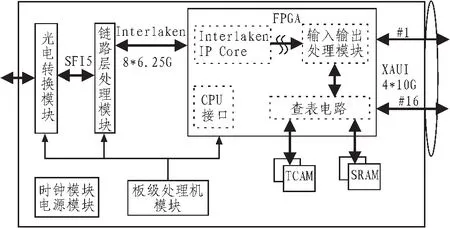
图1 40 Gb/s POS线路接口板原理框图Fig.1 Line interface board block diagram of 40Gb/s POS
2 高速数据流接口设计
2.1 Interlaken协议概述
Interlaken协议采用与SPI4.2[5]类似的简单包控制字结构和64 B/67 B编码,支持256个逻辑通道(可扩展至64 k)和带内、带外流控模式,串行通道数量与数据速率可扩展性强,具有频率可编程的连续元帧格式用来保证通道对齐、同步扰码器、时钟补偿和CRC校验。由于采用了数据突发层CRC24检验、通道层CRC32校验和数据扰频器,从而确保了数据完整性和链路鲁棒性。Interlaken的过程是:在发送端对数据包按一定数量的高速串行通道进行条带化后组成帧传送,在接收端由接收器件再重新解帧与组合还原原始数据。
其中,数据条带化的过程是:将数据包根据参数BurstMax,BurstMin,BurstShort切割成一个个突发数据字,前后加入相应的控制字,然后将由数据字与控制字组成的突发按照每8字节一个通道进行条带化,每个通道对应一个物理SerDes。
在成帧时,每个通道将条带化的突发字封装至其自带的“元帧”,根据帧长加入1个同步字,1个扰频器状态字,1个诊断字,1个或多个跳脱字。元帧结构如图2所示。

图2 元帧结构Fig.2 Meta frame structure
传输时通常都是发送一个长为BurstMax的突发数据,紧跟着一个控制字。最短突发的执行是通过在下一个突发控制字前加额外的空闲控制字而实现的,最小突发保证的最小间隔示意图如图3所示。

图3 最小突发间隔示意图Fig.3 Minimum burst interval diagram
2.2 FPGA中的Interlaken IP核
在FPGA中实现的高速通道与Interlaken IP核顶层模块框图如图4所示。

图4 Interlaken顶层模块框图Fig.4 Block diagram of Interlaken top-level module
Interlaken IP核顶层模块由接收和发送两个模块组成。接收模块从串行通道接收Interlaken比特流,去除Interlaken封装,并将512位宽原始数据流提交给用户,供后面的FPGA逻辑处理。发送模块接收用户侧512位宽包原始数据,按照Interlaken规范封装数据,并将封装数据发送至串行通道,通过控制/配置输入对数据进行封装。状态/控制接口用于设置接口特性并监视其操作。包括:接收元帧状态信号,接收错误状态信号,发送速率限制信号,CRC32诊断检测信号(用于监测每个通道的工作状态是否正常),Interlaken接收状态信息,Interlaken发送状态信息,发送多重使用比特,接收多重使用比特,发送流控输入,接收流控输入,发送FIFO门限等。
2.3 接口时序关系
发送端总线接口同步接收任意长度的包原始数据,所有信号都与clk上升沿同步。一个65字节包发送端采样波形时序示意图如图5所示。

图5 发送波形采样时序示意图Fig.5 Timing diagram of the transimitting waveform samples
接收端总线接口同步接收包原始数据。一个65字节包接收端采样波形时序示意图如图6所示。
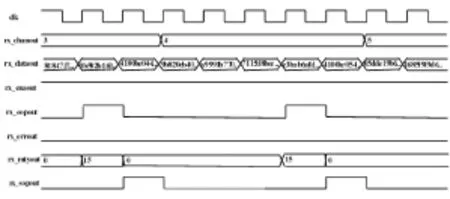
图6 接收波形采样时序示意图Fig.6 Timing diagram of the receiving waveform samples
3 高速数据流接口实现
3.1 实现方案
按照自顶向下的设计思路,给出发送侧硬件电路模块级设计方案,如图7所示。

图7 发送侧硬件电路模块设计示意图Fig.7 Hardware circuit design module of transmit block
其中,速率调整缓存模块接收用户侧送来的传送数据,若用户侧发送速率高于Interlaken传送速率,则调整该模块的输出速率,并对新进入数据缓存;数据切割模块按照Interlaken协议的切割算法和控制与状态模块配置的Burstmax、Burstmin和 Burstshort参数对输入数据包进行切割;突发字组装模块按照8字节数据字格式将切割后的数据组装成数据字,同时按照控制字格式和控制与状态模块的配置信息组装相应的控制字;CRC24模块完成协议层CRC24(x24+x21+x20+x17+x15+x11+x9+x8+x6+x5+x+1)[6]计算;突发组合模块基于CRC24计算结果和突发字组装结果完成一次突发组合;条带化模块将输入突发字按照条带数量实施条带化,每8字节数据轮询发送至N个条带;64/67模块按照64B/67B编码格式对各个条带数据进行编码;同步和跳脱模块按照同步和跳脱字的结构及下发的控制状态组成各条带新帧的同步字和跳脱字;CRC32对各条带原帧进行CRC32计算并生成新的诊断字,计算多项式[6]为:x32+x28+x27+x26+x25+x23+x22+x20+x19+x18+x14+x13+x11+x10+x9+x8+x6+1
加扰模块根据当前扰码状态字加扰数据流;组帧及对齐模块根据原帧结构组成原帧,并根据需要决定是否实施通道对齐;serdes模块是串行/解串行模块,完成并串转换,将高速串行数据输出。控制与状态模块对各协议层处理模块和帧层处理模块进行控制和配置。
Interlaken协议硬件处理在性能上要以线速转发处理为目标,对 40字节分组来说,Interlaken接口为 OC-768(40 Gb/s)时,线速分组时间仅为8 ns,可见,要实现对OC-768或者更高速率的Interlaken接口支持,必须引入并行流水线硬件设计技术,由此,上述模块级设计中遵循两个原则:
1)次序保证原则 该原则要求在任务划分过程中,必须保证各串行子任务在处理时间上的顺序性,以保证IP分组得到正确处理;
2)并行处理原则 在次序保证原则的基础上,该原则要求所有可并行处理的子任务作并行处理,以缩短IP分组的处理时间。
遵循上述两个原则,可进一步对各个模块内部作更深入的电路设计,本文不再给出。接收流程与发送流程相反,模块设计也相反,本文也不再给出。
3.2 基于XILINX FPGA的实现思路
目前,高端FPGA普遍支持高速串行/解串行模块,例如XILINX V5 FPGA[5]的 GTX 可支持 6.25 Gb/s,而 Altera Stratix IV GX FPGA[7]的GTX可支持6.5 Gb/s。下面以XILINX V5 FPGA实现40 Gb/s接口为例,给出Interlaken接口FPGA内部实现思路。
1)根据接口速率选定配置方案,常见的为8×6.25 G和16×3.125 G,其中 8×6.25 G 使用 tile数量是 16×3.125 G 的 1/2,但单对差分线速率达到6.25 G,对PCB设计要求高。确定配置后,即可选定tile,若选择8×6.25 G则可尽量选择4个相邻tile,以便tile时钟可以公用。
2)设计系统数据宽带和时钟方案:若内部总线为32,单个lane内部的处理时钟需达到6.25 G/32,与GTX的发送和接收时钟同步;此外,用户侧时钟和数据配置时钟和总线既要满足带宽需求:>40 G,又要满足频率要求:>(8×6.25 G)/32,常见配置为512宽带或者256宽带,总线频率为200 MHz。
3)选择GTX功能模块并例化GTX核:PCS部分BYPASS 8 B/10 B,选择gearbox模块,并选择其模式为外部顺序控制,PMA部分选择PISO,并根据需要配置预加重和均衡等。
4)按照2.1实现除serdes之外Interlaken协议处理模块。
5)将Interlaken协议处理模块和gTX核对接,完成整个设计。
4 测试数据与性能分析
高速通道硬件设计和Interlaken IP核是满足系统吞吐率要求的关键因素,为验证系统功能,采用的基本调试与测试方法是:通过上位机单板处理软件控制链路层商用芯片PRBS或固定负载的定长包和变长包作为数据源,发出数据包,由FPGA Interlaken核接收端经FIFO打环再由核发送端送回商用芯片,并对发送包与接收包进行统计对比分析。表1是在40 Gb/s速率下,突发分割参数BurstShort=64,BurstMax=256时,各种数据包长的发送接收传输测试数据。
由表1可以看出,当BurstShort=64,BurstMax=256时,40Gb/s速率下,各种包长的数据报环回时无丢包发生。证明高速通道硬件设计满足要求,相应的Interlaken IP突发配置参数下性能可以达到40 Gb/s的吞吐率。

表1 速率为40 Gb/s时的发送与接收包数据Tab.1 Number of transmiting and receiving packets at 40 Gb/s wire-speed
为验证Interlaken IP核突发分割参数配置对数据吞吐率的影响,在不同速率下对各种包长的数据包进行了大量测试。其中,特定分割参数(BurstShort=192,BurstMax=256)时,得到的定长数据包在各种速率下的传输性能测试数据特性图如图8所示。

图8 不同速率下的数据包丢包率(BurstShort=192,BurstMax=256)Fig.8 Packet loss rate under different Rates(Burstshort is 192 and BurstMax is 256)
由图8可以看出,当BurstShort=192,BurstMax=256时,在38Gb/s速率以下,各种包长的数据包无丢包发生。在40Gb/s速率时,某些包长的数据包存在丢包现象。说明IP核突发分割参数配置对数据吞吐率有影响,因此需要在应用时优化IP核的参数配置。
5 结束语
在核心路由器40 G POS线路接口板设计任务中,基于Interlaken协议,利用Xilinx V5TX240T FPGA的GTX高速通道完成了链路层处理芯片与转发、处理FPGA之间数据包的高速互联,采用8个高速通道,每通道速率6.25 Gb/s,满足了系统40 Gb/s吞吐率的要求。下一步的研究思路是:在实际网络环境中,综合考虑数据流的流长分布特征与IP核参数的关系,实现参数的在线可重构配置,基本方法是将数据传输效率与正确率的统计结果反馈给单板软件,利用单板软件和处理机接口,对Interlaken核的参数进行修改,以数据包的包长分布、数据包流量以及包速率为主要特征,建立应用现场的包分布特征模型,从而实现IP核关键参数与控制寄存器的自适应、动态可重构配置。
[1]Cortina,Cisco.Interlaken protocol definition, version 1.2[EB/OL].(2008-10-07).http://wenku.baidu.com/view/90303e 3610661ed9ad51f31a.html.
[2]Cisco.Interlakentechnology:new-generationpachetinterconnect protocol[EB/OL].(2007-03-08).http://read.pudn.com/downloads139/doc/comm/596874/Interlaken_White_Paper-March_2007.pdf.
[3]ASIC Interlaken IP Core.SLE interlaken SLE interlaken IP key features[EB/OL].(2007-01).http://www.siliconlogic.com/pdfs/SLE_Interlaken_IP_Data_Sheets.pdf.
[4]XILINX.Virtex-5 FPGA rocketIO GTX transceiver user GuideUG198[EB/OL].(2009-10-30).http://www.datasheetarchive.com/datasheet-pdf/0100/DSA00219189.html.
[5]Optical internetworking forum.System packet interface level 4(SPI-4)Phase 2:OC-192 system interface for physical and link layer devices[EB/OL].(2001-01).http://www.docin.com/p-213161926.html.
[6]Castagnoli G,Brauer S,Herrmann M.Optimization of cyclic redundancy-check codes with 24 and 32 parity bits[J].IEEE Transactions on Communications,1993,41(6):883-892.
[7]Altera Corporation.Stratix IV device handbook.[EB/OL](2011-04).http://www.altera.com.cn/literature/hb/stratix-iv/stx4_5v4.pdf.
猜你喜欢
电脑与电信(2021年9期)2021-12-21
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
山西地震(2019年1期)2019-03-20
网络安全和信息化(2018年4期)2018-11-09
新农业(2016年23期)2016-08-16
系统工程与电子技术(2016年2期)2016-04-16
西北工业大学学报(2015年3期)2015-12-14
中国光学(2015年1期)2015-06-06
中国卫生(2014年7期)2014-11-10
