
应用支持向量机预测绞股蓝茶浸提液中药用成分的含量*
2013-08-06 00:31娄和强吕洪飞
浙江师范大学学报(自然科学版) 2013年4期
孙 彬,娄和强,姜 曌,吕洪飞
(浙江师范大学化学与生命科学学院,浙江金华 321004)
绞股蓝(Gynostemma pentaphyllum)系葫芦科绞股蓝属多年生草质藤本植物.该属植物目前全世界已知有16种3变种,分布于我国南部、越南北部、韩国南部和日本.我国已知有14种3变种[1],主要分布于陕西、云南、贵州、湖南、湖北、山东等省.绞股蓝是一种国家卫生部公布的药食两用植物[2],除了作为传统中药材治疗高血压、高血脂等心脑血管疾病外,绞股蓝叶代茶饮也历史悠久,长期饮用明显具有增强免疫力、调节人体生理机能、减缓衰老、降血压、降血脂、预防癌症等保健功效.因此,绞股蓝加工成干品作为一款保健茶也是其主要的消费形式.
支持向量机(SVM)是1988年首次由Vapnik[3]提出的,如径向基函数网络和多层感知器网络一样,可应用于非线性回归及模式分类.由于支持向量机在模式识别方面的出色表现,已成功应用于手写识别技术[4]、微粒鉴别技术[5]、面部识别技术[6]、植物分类[7]等方面,农业与食品技术领域[8]也有所涉及.LIBSVM是台湾大学林智仁等[9]开发设计的一个简单、易于使用和快速有效的支持向量机非线性回归与模式识别的软件包,能极大地简化支持向量机的应用过程,因而在机器学习领域颇受欢迎.在SVM模型的建立过程中,核函数的选择和参数优化直接影响模型的预测或者分类性能[10-11].径向基核函数(RBF)在支持向量机中的应用最为广泛[12].在参数优化方面,除了应用最广的网格参数寻优法[13],粒子群优化算法[14]和遗传优化算法[15]也能显著提高支持向量机的模型性能,达到模型参数的最佳选择的目的.
本研究的目的是通过建立数学模型来预测不同提取温度、时间和料液比下浸提绞股蓝细粉所得提取液中总黄酮、总酚的含量及其抗氧化活性,并通过比较不同核函数及不同参数优化算法下SVM模型的预测结果,寻求最佳的预测模型.本研究有助于优化草本茶的提取条件,并为工业上提取草本活性物质提供数学模型.
1 材料与方法
1.1 实验材料
市售绞股蓝茶,产于中国陕西省平利县的绞股蓝良好农业规范(GAP)生产基地,出产日期为2012年3月,在实验开始前置于零下20℃冰箱中密封保存.
1.2 提取过程和样品制备
首先,将绞股蓝茶研成细粉,过60目筛,弃粗存细.每份绞股蓝茶细粉称取0.5 g左右置于三角烧瓶中,按不同料液比要求加入不同体积的蒸馏水,并用保鲜膜封口.设置 50,55,60,65,70,75,80,85,90,95 和 100 ℃共11 个温度水平水浴加热,每5 min震荡摇匀1次.期间,按所要求的时间将相应的材料从水浴中取出,并及时用15℃冷水冷却,在室温下抽滤,收集滤液定容于50 mL容量瓶中,即得待测样品溶液.为了防止营养物质损失,提取液在分析完成之前均在4℃下保存.
1.3 总黄酮含量的测定
绞股蓝中总黄酮含量参考Bonvehi等[16]的比色法测定.取0.1 mL新鲜制备的绞股蓝茶浸提液,加入1.5 mL 甲醇,0.1 mL 20 g/L 氯化铝水溶液,0.1 mL 1 mol/L乙酸钾水溶液和3.2 mL蒸馏水,混匀,于室温放置30 min后,在415 nm波长下测定吸光度.按芦丁标准溶液测定的标准曲线计算提取液中的总黄酮浓度,最后以每1 g绞股蓝茶中含有芦丁的毫克数表示绞股蓝茶中的总黄酮含量(单位:mg/g).
1.4 总酚含量的测定
参考Emmons等[17]使用的福林酚比色法测定绞股蓝茶浸提液中的总酚含量.具体步骤如下:取0.1 mL制备不久的提取液,加入8.7 mL蒸馏水,0.5 mL 福林酚试剂和0.7 mL 200 g/L Na2CO3溶液,混匀,于40℃水浴锅中反应40 min后,在波长755 nm处测定吸光度.按没食子酸标准溶液测定的标准曲线计算提取液中的总酚浓度,最后以每1 g绞股蓝茶中含有没食子酸的毫克数表示绞股蓝茶中的总酚含量(单位:mg/g).
1.5 自由基清除能力的测定
绞股蓝茶浸提液的自由基清除能力以2,2'-二苯基-1-三硝基笨肼自由基(DPPH)的清除量来计算.操作步骤参考文献[18]:取0.1 mL绞股蓝茶浸提液,加入0.03 g/L DPPH甲醇溶液10 mL,封口摇匀,于黑暗中反应30 min后,在波长517 nm处测定吸光度.绞股蓝茶浸提液的自由基清除能力按如下公式计算:

自由基清除能力 =

r2=0.999 6.其中:A0为DPPH溶液黑暗中静置30 min后的吸光度;A1代表绞股蓝茶浸提液与DPPH溶液于暗处反应30 min后的吸光度;As代表浸取液本身的吸光值;自由基清除能力的单位为 μmol/g.
标准曲线由生育酚标准溶液测得.
1.6 支持向量机分析
LIBSVM软件包中集成了C-SVC(应用于模式分类),nu-SVC(应用于模式分类),one-class-SVM(应用于模式识别),epsilon-SVR(应用于非线性回归)和nu-SVR(应用于非线性回归)模型,其中C-SVC为默认选择模型.本研究内容均基于LIBSVM(3.12版)中的 epsilon-SVR 模型,通过Matlab(7.9.0.529版本,R2009b)实现.以下是 epsilon-SVR模型介绍:
Vapnik[3]于 1988 年提出,与大多数线性回归模型类似,例如最小二乘法,支持向量机的目的也是寻求一个数学模型

式(3)中,ω和b分别是权值向量和偏移量.
给定一个数据集(xi,yi),xi为输入向量,yi为xi相应的输出向量,模型(3)的参数最终通过最小化下式来确定:

式(4)中:n 是样本量;ξi和分别代表训练误差的上限和下限;常数项C(惩罚参数,C>0)决定了模型f(x)和差异大于容忍度ε的样本数量之间的平衡[19].
在给定的式(4)和式(5)中定义的模型优化函数可以通过拉格朗日乘子法转化为以下形式表现:

式(6)中:ai和(且≥0,≥C)为拉格朗日乘子;K(xi,xj)则被定义为核函数[20-21],而核函数有多个选择.因此,要使非线性向量集映射到一个线性回归的多维空间中,选择一个合适与否的核函数决定了其回归性能的优劣[22].在LIBSVM软件包中集成了4种基本的常见的核函数,列举如下:
1)线性核函数:

2)多项式核函数:

3)径向基核函数:

4)双曲线核函数:
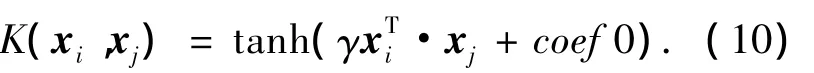
径向基核函数(RBF)是一个高斯函数,在4个核函数中应用最多.其中,在式(8)和式(10)中,本研究只涉及其默认参数,即coef 0=0.
支持向量机模型的预测性能是通过比较均方误差(MSE)及平方相关系数(r2)决定的,两者计算公式如下:

式(11)和式(12)中:n表示样本数量;f(xi)表示xi通过SVM模型所得的预测值;yi是真实值.在模型中作为输入和输出的数据均先归一化处理.
为了提高模型预测的精准度,优化核函数参数g和惩罚参数C是必不可少的.然而,目前并没有国际公认的模型参数优化方法.本文运用了最为广泛使用的网格参数寻优法.首先,将一对初始参数(C,g)代入模型中;然后,训练集被随机分配到k个相互排斥的大小相近的子集中;接着,模型用其中k-1个子集作为训练集,剩余的1个子集作为测试集,该过程重复k次,直至每个子集均作为测试集出现,记录下此过程中产生的最佳及平均交互验证均方误差(CV-MSE);最后,大量不同的(C,g)参数被代入模型重复进行以上步骤,选取均方误差最小的(C,g)值作为最佳模型参数[23].
除了网格参数寻优法外,本研究也尝试了另外2种启发式算法:遗传优化算法(GA)和粒子群优化算法(PSO).
遗传优化算法基于自然界进化演变的原理,最早由 Goldberg 等[24]引入,后经 Holland[25]证实.遗传优化算法是可以在复杂多维度搜索空间中寻求全局最优解决方案的参数优化算法.在遗传优化算法步骤中,寻找最优解是从一个初始化的潜在解决方案开始的,记为一个种群,而每一个种群则由一定数目的个体组成.因此,在第一代种群产生后,以优胜劣汰、适者生存的原理逐代演化产生越来越好的近似解.在每一代,根据问题域中个体适应度的大小选择个体,并通过遗传学的遗传算子进行选择、交叉和变异,产生出新的更优化的种群.最后,末代种群中的最优个体即是问题的最优解.
粒子群优化算法是1995年Kennedy和Eberhart[26]首次提出的,源于对鸟类捕食行为的研究.每个粒子都代表机制优化问题的一个潜在最优解,用速度、位置和适应度3个指标表示该例子的特征.适应度由适应度函数计算得到.Pbest被定义为一个搜索到最佳位置的粒子,即具有最佳适应度;而Gbest则是所有粒子均搜索到最佳位置上,即均具备最佳适应度.每个粒子都会朝着各自的最优位置移动,而全局的最优解则由粒子群中所有粒子搜索到的最佳位置决定[27].粒子的位置更新是通过自己现有的位置及速度计算的.速度算法如下所示:
式(13)和式(14)中:pi,d表示编号为 i的搜索到最佳位置的粒子;pg,d表示目前所有粒子处于全局最佳位置;t表示迭代次数;r1和r2表示2个范围在[0,1]的随机数函数;c1和c2为非负常数,称为加速因子;w为惯性权重,首次被文献[28]引进,用以平衡局部运算和全局运算;速度被限制在[-vmax,vmax]范围内,vmax是由当前和目标位置决定的边界值.综上所述,每个粒子的新位置由下式计算得到:

2 结 果
2.1 浸提结果分析
提取工艺可以被诸多因素优化,如提取时间[29-30]、提取温度[31-32]、料液比、提取溶液类型[33]和其他辅助技术[30].水提取由于其简单性和运营成本低,一直是生产工艺中使用最多的方法,一般国内植物性饮品的制作也都是基于水提取.目前,已有研究人员研究了草本提取物中的营养成分和抗氧化活性[34-35].支持向量机在食品科学领域已有大量应用,如:枣干的分类[36]、蛋白含量预测[37]、水果表面损伤检测[38-39]等.从现有的研究报道来看,本文通过SVM模型预测绞股蓝浸提液中生物活性成分含量的研究尚属首次.本研究的目的是为了论证支持向量机具有预测不同提取条件下浸提液中有效成分含量的潜力.
实验结果如图1所示,随着浸提时间、浸提温度的增加,绞股蓝茶浸提液中总酚含量、总黄酮含量及其清除自由基的能力总体上均有上升趋势.浸提温度越高,浸提液中各项指标升高得越快.

图1 不同浸提温度及浸提时间下股蓝浸提液中的总酚含量(料液比为1∶30)
从图2可知,自由基清除能力与总黄酮含量、总酚含量密切相关,两者的相关系数分别为0.941 6和0.931 5.有关抗氧化活性与酚类物质含量相关性的类似研究已有蔬菜[40]和药用植物[41]方面的报道.

图2 绞股蓝浸提液中总黄酮含量及总酚含量与自由基清除能力的相关性
2.2 不同核函数对预测结果的影响
本实验中,以绞股蓝茶的浸提时间、浸提温度和料液比作为输入向量,所得的浸提液中总黄酮含量和总酚含量及其自由基清除能力作为输出向量,建立了3个数学模型,用以分别预测绞股蓝浸提液中的总黄酮含量、总酚含量及其自由基清除能力.如表1所示,本实验涉及了11个不同的提取温度,每个温度下共设置了5个提取时间及3个不同的料液比.因此,每个模型均有165个数据点,其中随机选择120/165个数据点组成训练集,其余的45/165个数据点组成测试集.
如“材料与方法”部分所阐述的,选择一个合适的核函数是建立SVM模型的关键.本研究中最佳核函数的选择是通过比较模型在各自核函数下计算得到的相关系数和均方误差来进行的.因此,本实验尝试了几个不同项数的多项式函数和4个基本核函数分别构建的数学模型.表2是不同项数参数下的多项式核函数SVM模型的预测结果,其中多项式模型中项数参数d的范围为2~6;表3是在默认参数下(C=0,g=0),SVM模型对训练集和测试集的预测结果.

表1 绞股蓝茶浸提处理的温度-时间组合
从表2和表3可知:当d=2时,多项式核函数模型在预测总酚含量时达到最佳相关系数;而双曲线核函数下模型的预测结果最差,相关系数明显小于其他核函数下模型的预测结果:预测总酚含量时测试集的相关系数仅为0.378 5;预测总黄酮含量时的相关系数为0.447 3;预测自由基清除能力时的相关系数为0.314 1,而其均方误差却比其他的预测结果大.图3是SVM模型在不同核函数下预测绞股蓝茶浸提液中总酚含量时训练集和测试集的结果.表3和图3表明,径向基核函数下SVM模型表现出最佳的预测精度,其测试集相关系数分别达到了0.9396(预测总酚含量的结果),0.926 9(预测总黄酮含量的结果)和0.921 9(预测自由基清除能力的结果).径向基核函数的SVM模型不仅容易施行,而且能将非线性问题有效地映射到无限维空间达到回归或模式识别的目的.因为,径向基函数适合于处理非线性关系的问题[42].

表2 默认参数(C=0,g=0)下不同项数参数下的多项式核函数模型的预测结果

表3 默认参数(C=0,g=0)下不同核函数SVM模型的预测结果

图3 不同核函数SVM模型对绞股蓝茶浸提液总酚含量预测的训练集和测试集的回归结果
2.3 不同参数优化方法对预测结果的影响
为了进一步提高SVM模型的预测性能,参数优化是必不可少的.以预测总酚含量为例,不同参数优化算法下径向基核函数SVM模型的预测结果如图4所示.其中:图4(a)是通过网格优化算法优化参数得到的优化曲面;而图4(b)和图4(c)分别是由粒子群优化算法和遗传优化算法得到的均方误差(MSE)曲线.在粒子群优化算法下粒子系数设为20,迭代次数为100;遗传优化算法下种群大小设为20,进化代数值是100.

图4 不同参数优化算法下径向基核函数SVM模型对绞股蓝浸提液总酚含量的参数优化结果

图5 不同算法参数优化后径向基核函数SVM模型对绞股蓝浸提液总酚含量预测的训练集和测试集回归结果

表4 不同参数优化算法下径向基核函数SVM模型的预测结果
图5为不同的参数优化方法下径向基核函数SVM模型预测绞股蓝提取液中总酚含量的训练集和测试集的回归结果.由表4可知,粒子群优化算法下径向基核函数SVM模型获得的测试集相关系数方面达到了最佳效果:预测总酚含量的相关系数为0.962 8,预测总黄酮含量的相关系数为0.979 7,预测自由基清除能力的相关系数为0.951 3.通过比较图3(c)和图5可知,参数优化可增加SVM模型的预测精度.在粒子群算法优化参数后,SVM模型预测总酚含量的测试集相关系数从0.939 6上升到0.962 8,预测总黄酮含量的相关系数从0.926 9上升到0.979 7,预测自由基清除能力的相关系数从0.921 9上升到0.951 3.此外,网格参数优化法下SVM模型预测总酚含量、总黄酮含量及自由基清除能力的测试集相关系数分别提高到了 0.957 2,0.977 9 和 0.917 0.遗传算法优化下SVM模型预测总酚含量、总黄酮含量及自由基清除能力的测试集相关系数分别提高到了 0.961 9,0.954 9 和0.942 3.
虽然3种参数优化方法下的预测结果无显著性差异[43],但如表4所示,通过比较训练集和测试集的预测结果,表明粒子群优化算法比其他2个算法具有更好的泛化能力.粒子群优化算法不仅在优化SVM模型中表现突出,在模糊云分类器[44]中的应用效果也十分明显.因此,通过粒子群优化算法优化的SVM预测模型可以凭借网络结构简单、收敛速度快、泛化能力强的特点而建立一个良好的数学模型.本研究结果表明,SVM模型不仅可以预测绞股蓝茶浸提液中的总酚、总黄酮等活性物质的含量及浸提液清除自由基的能力,而且获得了较为精确的预测结果.
3 讨论与小结
本研究通过SVM模型成功预测了绞股蓝水提取液中总酚和总黄酮的含量及其自由基清除能力.如表4所示,SVM模型的预测精度已达到了较高的水平,表明该模型可以用于预测绞股蓝茶浸提液中的总酚、总黄酮等活性物质的含量及浸提液的自由基清除能力.根据本实验结果,建议使用径向基核函数并用粒子群优化算法进行参数优化.SVM不仅可广泛用于天然植物提取物中总酚、总黄酮等活性物质的含量分析,也可推广应用于食品加工过程中营养物质的控制.
[1]卢金清,肖波,陈黎,等.分光光度法测定绞股蓝中总皂苷的含量[J].湖北中医杂志,2007,29(1):50.
[2]张涛,张育松.福建甜味绞股蓝茶的保健成分及其市场现状和展望[J].亚热带农业研究,2008,4(2):154-157.
[3]Vapnik V.Statistical learning theory[M].New York:John Wiley and Sons Inc,1988.
[4]Bahlmann C,Haasdonk B,Burkhardt H.On-line handwriting recognition with support vector machines—A Kernel Approach[C]//Eighth International Workshop on Frontiers in Handwriting Recognition(IWFHR'02).Washington:IEEE Computer Society,2002:49-54.
[5]Barabino N,Pallavicini M,Petrolini A,et al.Support vector machines vs multi-layer perceptrons in particle identification[C]//Proceedings of the European Symposium on Artifical Neural Networks.Belgium:D-Facto Public,1999:257-262.
[6]Guo Yingchun.An integrated PSO for parameter determination and feature selection of SVR and its application in STLF[C].Proceedings of the Eighth International Conference on Machine Learning and Cybernetics.Baoding:[Conference Publications],2009:359-364.
[7]Lü Hongfei,Jiang Wu,Ghiassi M,et al.Classification of Camellia(Theaceae)species using leaf architecture variations and pattern recognition techniques[J].PLoS One,2012,7(1):e29704.
[8]Lou Heqiang,Hu Ya,Wang Bin,et al.Dried jujube classification using support vector machine based on fractal parameters and red,green and blue intensity[J].International Journal of Food Science and Technology,2012,47(9):1951-1957.
[9]Chang C C,Lin C J.LIBSVM:a library for support vector machines[J].ACM TIST,2011,2(3):1-27.
[10]宋晖,薛云,张良均,等.基于SVM分类问题的核函数选择仿真研究[J].计算机与现代化,2011(8):133-136.
[11]郭雷,肖怀铁,付强,等.非均衡数据目标识别中SVM模型多参数优化选择方法[J].红外与毫米波学报,2009,28(2):141-145.
[12]李晓宇,张新峰,沈兰荪,等.一种确定径向基核函数参数的方法[J].电子学报,2005,33(12A):2459-2463.
[13]江伟,罗毅,涂光瑜,等.基于多类支持向量机的变压器故障诊断模型[J].水电能源科学,2007,25(1):52-55.
[14]杨朝霞,方健文,李佳蓉,等.粒子群优化算法在多参数拟合中的应用[J].浙江师范大学学报:自然科学版,2008,31(2):173-177.
[15]吴景龙,杨淑霞,刘承水,等.基于遗传算法优化参数的支持向量机短期负荷预测方法[J].中南大学学报:自然科学版,2009,40(1):180-184.
[16]Bonvehí J S,Torrent M S,Lorente E C.Evaluation of polyphenolic and flavonoid compounds in honeybee-collected pollen produced in spain[J].J Agric Food Chem,2001,49:1848-1853.
[17]Emmons C L,Peterson D M,Paul G L.Antioxidant capacity of oat(Avena sativa L.)extracts.2.In vitro antioxidant activity and contents of phenolic and tocol antioxidants[J].Journal of Agricutural and Food Chemistry,1999,47:4894-4898.
[18]Maisuthisakul P,Pongsawatmanit R,Gordon M H.Assessment of phenolic content and free-radical scavenging capacity of some Thai indigenous plants[J].Food Chemistry,2007,100(4):1409-1418.
[19]Üstün B,Melssen W,Oudenhuijzenb M,et al.Determination of optimal support vector regression parameters by genetic algorithms and simplex optimization[J].Analytica Chimica Acta,2005,544(1/2):292-305.
[20]Belousov A,Verzakov S,Frese J V.A flexible classification approach with optimal gen eralisation performance:support vector machines[J].Chemometrics and Intelligent Laboratory Systems,2002,64(1):15-25.
[21]Smola A J,Schölkopf B.A tutorial on support vector regression[J].Statistics and Computing,2004,14(3):199-222.
[22]Vapnik V.The nature of statistical learning theory[M].New York:Springer-Verlag,1995.
[23]Duan Kaibo,Keerthi S S,Poo A N.Evaluation of simple performance measures for tuning SVM hyperparameters[J].Neurocomputing,2003,51:41-59.
[24]Goldberg D E,Holland J H.Genetic algorithms in search,optimization,and machine learning[J].Machine Learning,1988,3(2/3):95-99.
[25]Holland J H.Adaptation in natural and artificial systems:An introductory analysis with applications to biology,control,and artificial intelligence[M].Oxford:University of Michigan Press,1975.
[26]Kennedy J,Eberhart R.Particle swarm optimization[J].Neural Networks,1995,4:1942-1948.
[27]Guo Guodong,Li S Z,Chan K L.Face recognition by support vector machines[C]//Proceedings of IEEE International Conference on Automate Face and Gesture Recognition.Washington:IEEE Computer Society,2000:196-201.
[28]Shi Yuhui,Eberhart R.A modified particle swarm optimizer[C]//Evolutionary Computation Proceedings,1998.IEEE World Congress on Computational Intelligence.Anchorage:IEEE,1998:69-73.
[29]Maeda-Yamamoto M,Nagai H,Suzuki Y,et al.Changes in O-methylated catechin and chemical component contents of"Benifuuki"green tea(Camellia sinensis L.)beverage under various extraction conditions[J].Food Science and Technology Research,2005,11(3):248-253.
[30]Pan Xuejun,Niu Guoguang,Liu Huizhou.Microwave-assisted extraction of tea polyphenols and tea caffeine from green tea leaves[J].Chemical Engineering and Processing,2003,42(2):129-133.
[31]Sharma V,Gulati A,Ravindranath S D.Extractability of tea catechins as a function of manufacture procedure and temperature of infusion[J].Food Chemistry,2005,93(1):141-148.
[32]Xia Tao,Shi Siquan,Wan Xiaochun.Impact of ultrasonic-assisted extraction on the chemical and sensory quality of tea infusion[J].Journal of Food Engineering,2006,74(4):557-560.
[33]Yau N,Huang Y.The effect of membrane-processed water on sensory properties of Oolong tea drinks[J].Food Quality and Preference,2000,11(4):331-339.
[34]Yang Xingbin,Zhao Yan,Yang Ying,et al.Isolation and characterization of immunostimulatory polysaccharide from an herb tea,Gynostemma pentaphyllum Makino[J].Journal of Agricultural and Food Chemistry,2008,56(16):6905-6909.
[35]Nagai T,Myoda T,Nagashima T.Antioxidative activities of water extract and ethanol extract from field horsetail(tsukushi)Equisetum arvense L[J].Food Chemistry,2005,91(3):389-394.
[36]Lou Heqiang,Hu Ya,Wang Bin,et al.Jujube classification using support vector machine based on fractal parameters and red,green and blue intensity[J].International Journal of Food Science and Technology,2012,47(9):1951-1957.
[37]Wu Di,He Yong,Feng Shuijuan,et al.Study on infrared spectroscopy technique for fast measurement of protein content in milk powder based on LS-SVM[J].Journal of Food Engineering,2008,84(1):124-131.
[38]Zheng Hong,Lü Hongfei.A least-squares support vector machine(LS-SVM)based on fractal analysis and CIELab Aparameters for the detection of browning degree on mango(Mangifera indica L.)[J].Computers and Electronics in Agriculture,2012,83:47-51.
[39]Lü Hongfei,Zheng Hong,Lou Heqiang,et al.Bruise detection on red bayberry using fractal analysis and support vector machine[J].Journal of Food Engineering,2011,104(1):149-153.
[40]Kaur C,Kapoor H C.Anti-oxidant activity and total phenolic content of some Asian vegetables[J].International Journal of Food Science and Technology,2002,37(2):153-161.
[41]Pietta P,Simonetti P,Mauri P.Antioxidant activity of selected medicinal plants[J].Journal of Agricultural and Food Chemistry,1998,46(11):4487-4490.
[42]Hong W,Dong Yucheng,Chen L,et al.SVR with hybrid chaotic genetic algorithms for tourism demand forecasting[J].Applied Soft Computing,2011,11(2):1881-1890.
[43]Alba E,Garcia-Nieto J,Jourdan L,et al.Gene selection in cancer classification using PSO/SVM and GA/SVM hybrid algorithms[C]//Evolutionary Computation,2007.Singapore:IEEE,2007:284-290.
[44]Lü Hongfei,Pi Erxu,Peng Qiufa,et al.A particle swarm optimization-aided fuzzy cloud classifier applied for plant numerical taxonomy based on attribute similarity[J].Expert System,2009,36(5):9388-9397.
猜你喜欢
食品工业(2022年1期)2022-02-21
四川蚕业(2021年3期)2021-02-12
中成药(2018年1期)2018-02-02
恋爱婚姻家庭·养生版(2017年12期)2017-12-07
中成药(2017年8期)2017-11-22
中成药(2017年10期)2017-11-16
恋爱婚姻家庭(2017年36期)2017-07-22
中成药(2017年4期)2017-05-17
江苏农业科学(2017年4期)2017-05-08
农业与技术(2016年24期)2017-04-20
