
基于υ-SVM的汽轮机热耗率回归模型研究
2014-09-22 02:05王惠杰陈林霄孙美琪杨新健
动力工程学报 2014年8期
王惠杰, 陈林霄, 李 洋, 孙美琪, 杨新健
(1.华北电力大学 电站设备状态监测与控制教育部重点实验室,保定071003;2.广东惠州天然气发电有限公司,惠州516082)
热耗率一直作为研究和衡量电厂热经济性的重要指标[1],如今很多电厂都可以对其进行实时监测,但是电厂运行人员对可控边界参数的调节往往只能依赖于运行经验和常规技术手册,难以通过对可控边界参数优化得到最佳的运行状态参数[2].由于传统的计算方法应用的参数众多,涉及一系列相变和能量转换等过程,很难定性得出某些参数与重要经济性指标间的直接关系,往往需要依靠细致的数据挖掘手段[3].文献[4]阐述了应用支持向量机建立强关联性参数与热耗率的回归模型.由于机组能耗与运行工况、环境条件、机组功率和设备状态等存在强烈的耦合以及可控边界参数决定内部参数的特性,可通过调节可控边界条件来实现针对热耗率的参数优化.因此,可以选取可控边界参数建立热耗率回归模型,通过可控参数的调节可以更清楚地反映热耗率的变化,从而得出最佳运行工况.笔者基于υ-SVM建立了可控边界参数与热耗率的回归模型,为进行机组耗差分析和可控边界参数优化工作开辟了新的途径.
1 支持向量机
支持向量机又称SVM,是Vapnik等人根据统计学习理论中结构风险化最小原则提出的.SVM的基本思想是从线性可分情况下的最优分类超平面(见图1)发展而来的.机器学习算法的实际风险由经验风险和置信范围2部分组成,经验风险与学习机器的复杂程度(即VC维数h)成反比,而置信范围与h成正比.因此,只有选择一个合适的VC维数h,使两者之和最小才能得到最小的实际风险.将函数集构造成一个函数子集序列,使各子集按照VC维的大小排列,即H1⊂H2⊂…⊂Hn⊂…,每个Hi的VC维数hi为有限值,于是有h1≤h2≤ …≤hn≤…,兼顾考虑经验风险和置信范围,从而取出最小实际风险,这就是结构风险最小化的思想[5-7],其示意图见图2.在hx处取得经验风险和置信范围的平均最小值,不会出现过学习和欠学习现象,泛化能力很强.
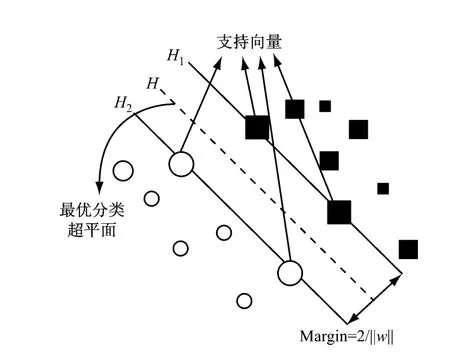
图1 最优分类超平面示意图Fig.1 Schematic diagram of optimal separating hyperplane
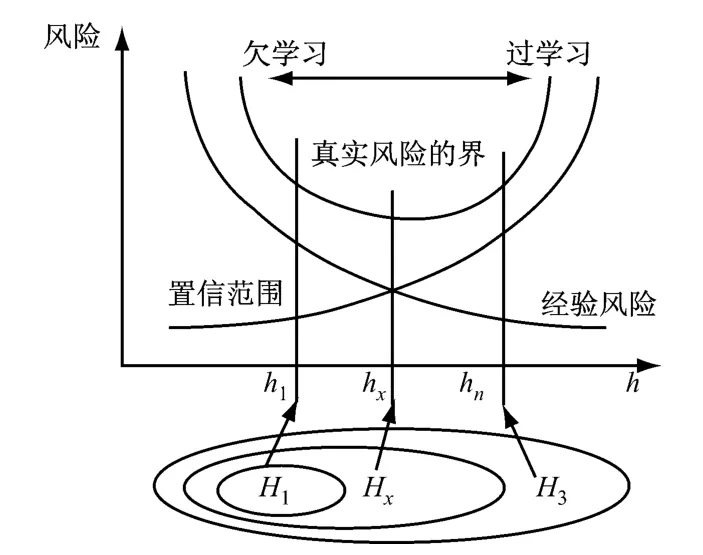
图2 结构风险最小化示意图Fig.2 Schematic diagram of structural risk minimization
考虑应用线性回归函数[8]:
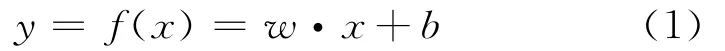
拟合数据{xi,yi},其中i=1,2,…,l,xi∈Rn,yi∈R,为了使式(1)平坦,解下面的凸优化问题[9]:
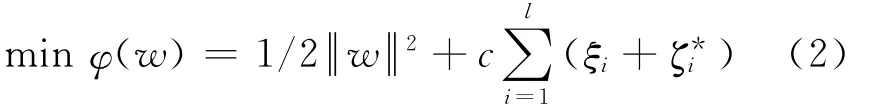
满足约束:
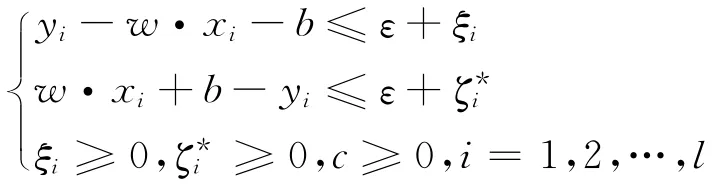
在二次型优化函数的非线性约束条件中引入拉格朗日乘子αi、、ηi和η*i,将线性可分问题转化为其对偶问题,通过非线性映射Ψ(x)映射到高维特征空间F,在F中求解最优回归函数.在最优回归函数中选取合适的核函数K(x,xi)代替高维空间的向量内积Ψ(xi)·Ψ(x),从而实现非线性变换后的线性拟合.此优化问题转化为[10]
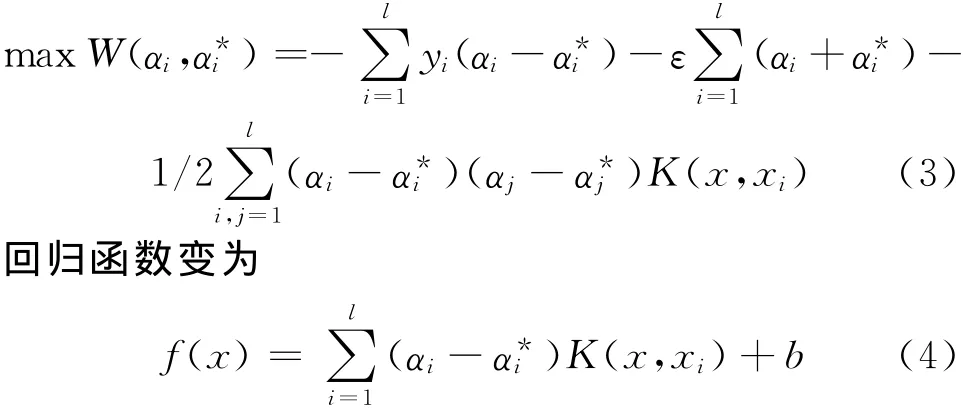
为了在高维特征空间中构造最优分类超平面,只需计算支持向量和特征空间中向量的内积,也就是以核函数的方式来计算.应用核函数的最大好处是将非线性分类平面转化为高维特征空间里的线性平面来处理[11],如图3所示.
目前主要应用的核函数有:(1)多项式函数,K(x,xi)=[(x·xi)+1]d,d 代表多项式分类器的阶数.(2)径向基函数(RBF),K(x,xi)=exp{-|xxi|2/σ2},每个基函数的中心对应着一个支持向量,算法 自 动 确 定.(3)Sigmoid 函 数,K(x,xi)=tanh[v(x·xi)+c],该算法自动确定隐层节点数,不存在神经网络的局部极小点问题.
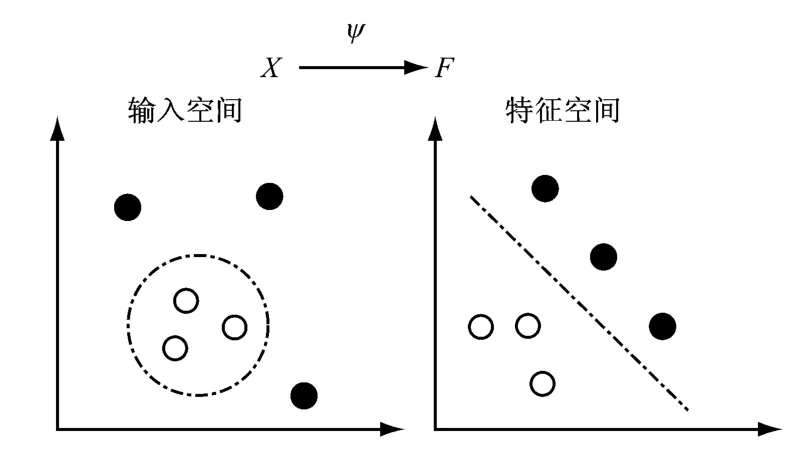
图3 输入空间的非线性分类映射到特征空间的线性分类Fig.3 Mapping from nonlinear classification in input space to linear classification in feature space
2 基于SVM建立模型
2.1 数据的预处理
基于数据挖掘的火电机组历史运行数据既包括稳定工况下的运行数据,也包括机组启停和变负荷时的瞬态数据.考虑到测量手段和精度的影响,采集到的数据中不免存在失真数据.因此,要对采集的历史数据进行预处理[12].
由于“稳定工况”没有统一的界定,稳态检测根据ASME机组性能试验规程进行,采样周期为10~15min时,规定各主要参数在稳定工况下的波动范围如表1所示.

表1 性能试验规程定义的稳定工况[13]Tab.1 Steady-state range specified in performance test code
在处理采样数据中有误差、失真和不完整的数据时,采用模糊粗糙集[13]的方法,具体内容参考文献[14].
2.2 输入输出参数
输入参数的选择原则是选择与输出参数具有强关联度的参数,而与输出参数关联度小的参数应尽可能不选[15].汽轮机组额定工况下热耗率的计算公式[16]为
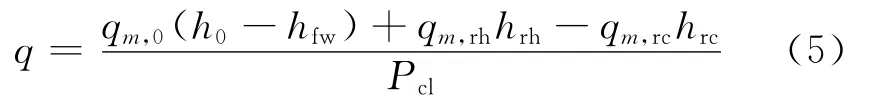
式中:qm,0为主蒸汽质量流量,kg/s;h0为主蒸汽焓,kJ/kg;hfw为锅炉给水焓,kJ/kg;qm,rh为再热蒸汽管道热端质量流量,kg/s;hrh为再热蒸汽热端焓,kJ/kg;qm,rc为再热蒸汽管道冷端质量流量,kg/s;hrc为再热蒸汽冷端焓,kJ/kg;Pcl为发电机输出功率(即机组功率),kW.
由卡诺循环效率η=1-T2/T1可知,平均吸热温度T1降低,平均放热温度T2不变,卡诺循环效率降低,热耗率升高.由此可知,主蒸汽温度t0和再热蒸汽温度t1是影响热耗率的重要因素.从式(5)也可以看出,h0是直接影响热耗率的参数之一,又因h0=u0+p0v,其中u0为热力学能,可推知主蒸汽压力p0和主蒸汽温度t0影响热耗率.再热减温水能防止再热器超温,但是降低了吸热段的吸热量,卡诺循环效率降低,热耗率升高.提高凝汽器的真空,可以尽可能多地使蒸汽中的热能转换为机械能,减少冷源损失,提高循环热效率.凝汽器真空是关系到汽轮机组安全性和经济性的重要指标,循环水流量和循环水温度又是影响凝汽器真空的重要参数,因此循环水温度和循环水流量是与热耗率有密切关系的可控边界参数.从式(5)可知,主蒸汽质量流量和再热蒸汽质量流量也与热耗率密切相关,但是由于现有仪器很难准确测量暂且不考虑.
通过以上分析可知,机组功率、主蒸汽压力、主蒸汽温度、再热蒸汽温度、循环水入口温度、循环水质量流量和再热减温水质量流量等7个参数与热耗率有直接或间接的强关联性,因此将这7个参数作为模型的输入参数,热耗率作为模型的输出参数.
2.3 灰色关联度模型关联性验证
以上述输入参数作为子序列,热耗率作为母序列建立灰色关联度模型进行验证.已知机组负荷与热耗率具有强关联性,将其作为子序列进行参照,以增强对比性[17].
灰色关联度分析的基本原理是对动态过程发展态势的量化分析,通过对系统内时间序列有关统计数据几何关系的比较,确定参考数列和若干个比较数列的几何形状相似程度来判断其联系是否紧密,它反映了曲线间的关联程度.与参考数列关联度越大的比较数列,其发展方向和速率与参考数列越接近,与参考数列的关系越紧密.关联度分析的基本步骤参考文献[18].计算结果见表2.
从计算结果可以看出,所选参数均与热耗率具有很强的关联性,可以作为回归模型的输入参数.
2.4 SVM类型的选择
在使用SVM进行回归运算时,只有ε-SVM和υ-SVM两类算法,取某600MW火电厂680组历史数据,一半数据为训练数据,另一半数据为测试数据.其他参数取默认值,求出模型输出热耗率的相对误差,选取相对误差较小的SVM类型.本文相对误差定义为
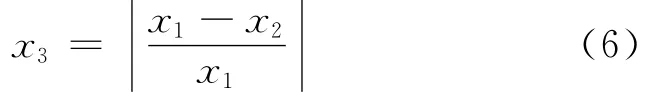
式中:x1为真实值;x2为计算值.
回归预测结果如表3所示,υ-SVM的相对误差较小,因此选择υ-SVM进行回归运算.
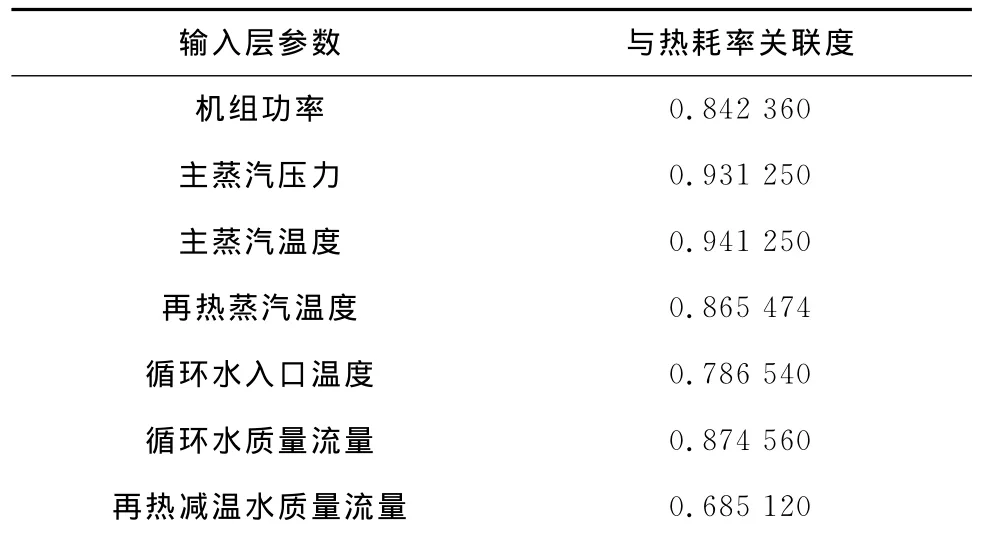
表2 参数关联度计算数据汇总Tab.2 Calculation results of relevance degree for various parameters

表3 不同类别SVM的回归预测结果Tab.3 Comparison of regression accuracy between ε-SVM andυ-SVM model
2.5 核函数的选择
核函数的选取对模型的准确性起着决定性的作用,由于边界参数与热耗率之间复杂的非线性关系,很难推算出分布函数,这给核函数的选择带来一些困难.分别采用前文提到的3种核函数来建立支持向量回归模型,比较这些模型输出热耗率的回归精度,其他参数均为默认值,采用择优选取的方法.不同核函数的SVM回归结果见表4.
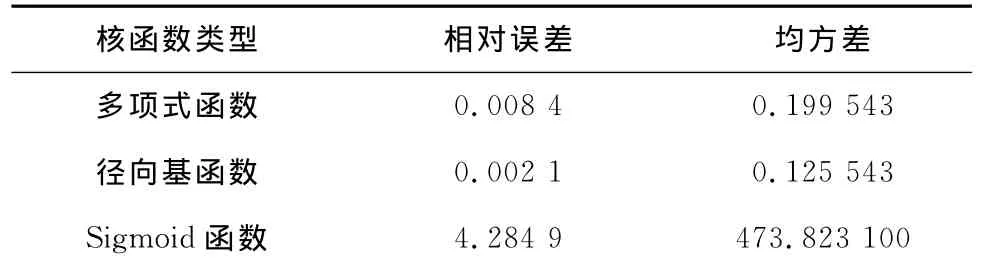
表4 不同核函数的SVM回归结果Tab.4 SVM regression results with different kernel functions
从表4可以看出,Sigmoid函数不适合作为回归模型的核函数,多项式函数回归的相对误差大于径向基函数,因此选取径向基函数作为本次模型的核函数.
2.6 参数的设定
在Libsvm平台上,对于核函数为径向基函数的υ-SVM,可设定的参数为c和g,如式(2)所示,c值的大小对模型的影响很大,g为核函数中的γ函数设置.参数的选取通过预测的相对误差决定,测试结果见图4和图5.由图4和图5可知,当c=87、g=2.7时,回归相对误差最小.

图4 参数c回归相对误差Fig.4 Relative error of parameter c regression
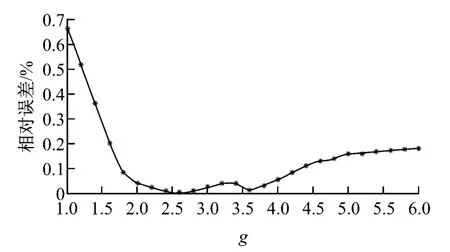
图5 参数g回归相对误差Fig.5 Relative error of parameter gregression
3 实例应用
通过以上对比分析,在Libsvm工具箱里选取υ-SVM类支持向量机,径向基函数作为核函数,核函数中的γ取2.8,c值取90,取340组数据为训练数据建立回归模型,另外340组数据为测试数据,部分参数见表5.由于数值较大,为避免溢出,在数据应用时都要进行归一化处理,再对回归结果进行反归一化处理.回归值的相对误差如图6所示.
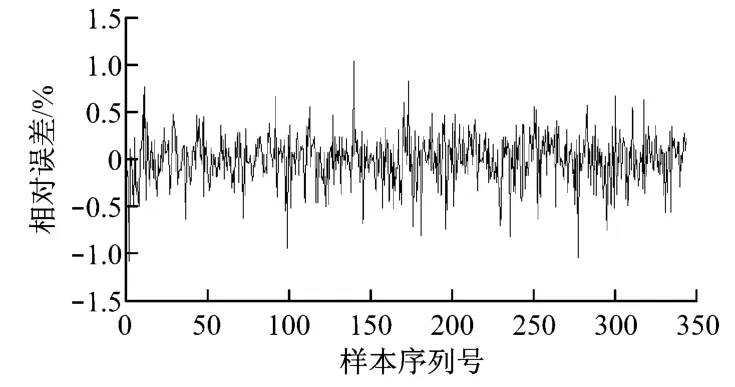
图6 热耗率回归值相对误差Fig.6 Relative error of heat rate regression
3.1 υ-SVM模型与BP神经网络模型的比较
在理论优化原则方面,SVM采用结构最小化原则,而BP神经网络则采用经验最小化原则.虽然SVM和BP神经网络都能够逼近非线性函数,但是仍有很大不同.陈林霄等[19]建立了BP神经网络模型,并与υ-SVM模型进行对比,在不同训练样本数目的情况下,两者回归相对误差如表6所示.从表6可以看出,BP神经网络的训练相对误差较小,但是测试相对误差随着训练样本数的减少而逐渐增大;υ-SVM模型的训练相对误差和测试相对误差基本维持稳定,分别保持在0.15%和0.22%左右.通过比较发现SVM具有小样本学习能力强、高维非线性数据处理性好、泛化能力强的特点.
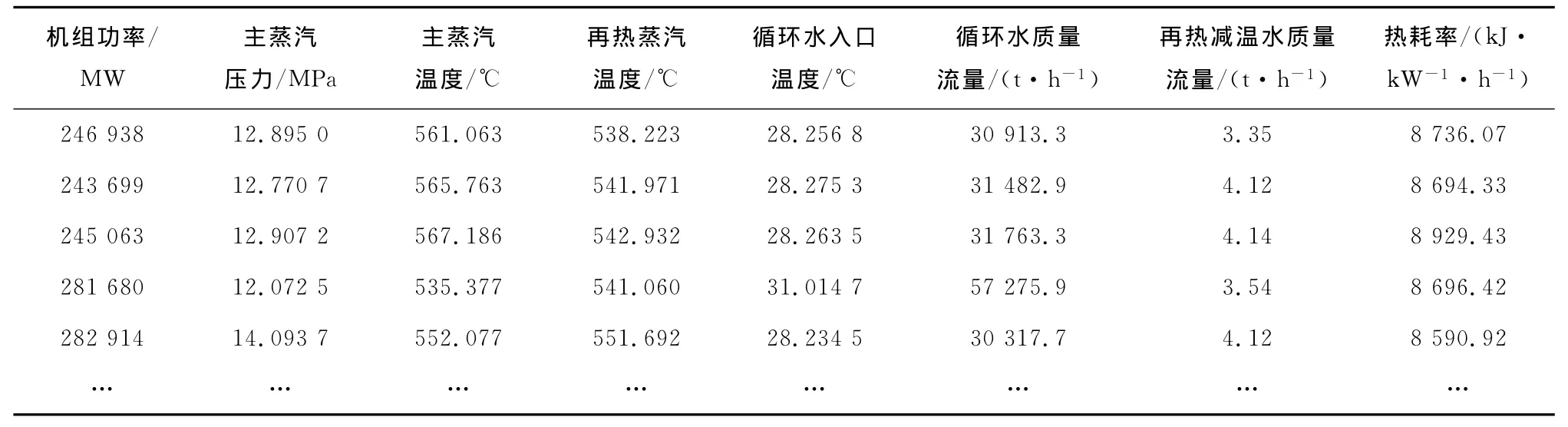
表5 部分参数列表Tab.5 List of main parameters
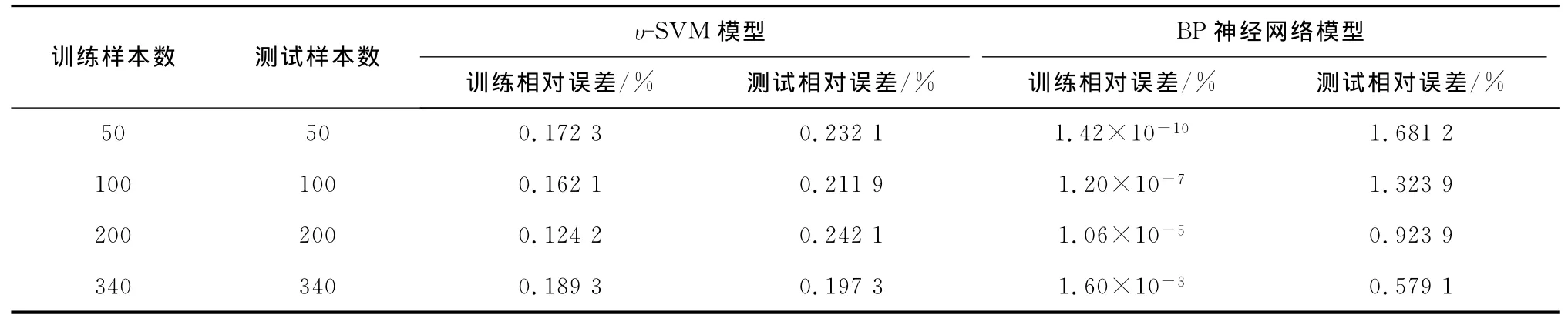
表6 υ-SVM模型与BP神经网络模型回归相对误差的比较Tab.6 Comparison of regression relative error betweenυ-SVM and BP neural network model
3.2 鲁棒性分析
由式(5)可知,热耗率是由许多参数共同决定的,每一个参数的变化都将影响计算的精确性.尤其是在主蒸汽质量流量和再热蒸汽质量流量的测量上存在很大误差,因此,实时计算出的热耗率误差也将很大.在对υ-SVM的鲁棒性分析上,采用对输入参数增加随机变量的方法,对比热耗率的变化情况.总共输入350组数据,对每一组数据里的一个随机参数附加5%的随机变量,回归结果如图7和图8所示.
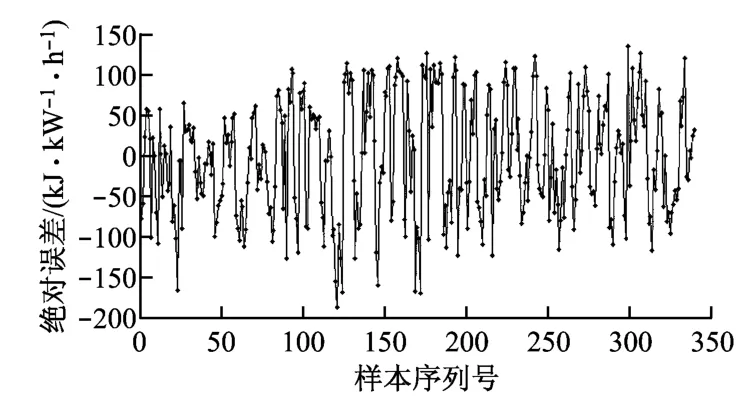
图8 热耗率回归值绝对误差Fig.8 Absolute error of heat rate regression
在增加了5%随机变量的情况下,通过式(5)计算所得热耗率的绝对误差基本在400kJ/(kW·h)左右.由图8可以看出,支持向量机模型的回归值与真实值的绝对误差基本在50kJ/(kW·h)左右,最大相对误差也未能超过190kJ/(kW·h),说明参数的小幅波动对回归模型的影响很小.在实际连续数据的采集下,采用υ-SVM回归模型是十分有利的.
3.3 规律性分析
选取关联度较强的机组负荷和循环水质量流量做规律性分析,其余各输入参数取定值,带入建立好的υ-SVM回归模型,回归结果如图9和图10所示.
由图9和图10可以看出,热耗率随着机组负荷和循环水质量流量的增大均为递减趋势,符合实际规律.但是局部规律性有些变化,这些变化可能是由于样本数据中的噪声和失真数据,也有可能是因为在变化单一参数的过程中,其他参数不符合定值规律造成的.
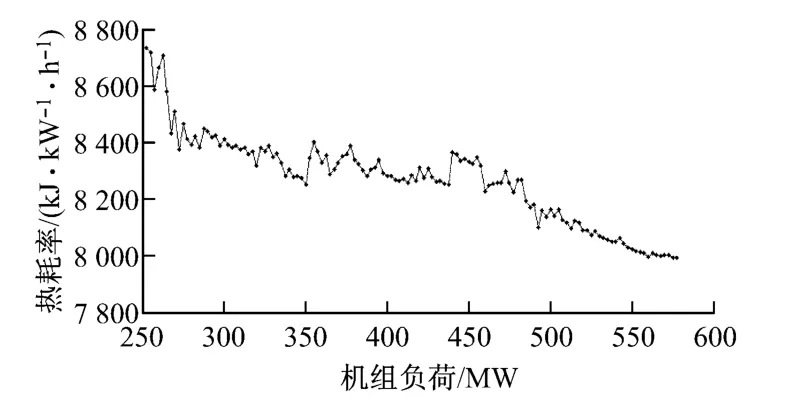
图9 机组负荷-热耗率图Fig.9 Load vs.heat rate

图10 循环水质量流量-热耗率图Fig.1 0 Circulating water flow vs.heat rate
4 结 论
(1)基于结构风险最小化的支持向量机建立回归模型时,泛化能力优于BP神经网络,尤其是在小样本情况下,效果更加突出.
(2)υ-SVM模型只应用了包括热耗率在内的7个参数,与传统计算模型相比,大大降低了对已知参数的要求.
(3)在输入参数增加5%随机变量的情况下,υ-SVM模型的输出值保持稳定,具有很好的鲁棒性.在测试连续实际数据的情况下,相对于传统的热耗率计算模型具有明显的优势.
(4)υ-SVM模型的整体规律性较强,符合实际规律,但是局部规律性较差,主要与样本数据(噪声、失真等)有关或者是因为在变化单一参数的过程中,其他参数不符合定值规律.
[1]郑体宽.热力发电厂[M].北京:中国电力出版社,2008.
[2]张春发,王惠杰,宋之平,等.火电厂单元机组最优运行初压的定量研究[J].中国电机工程学报,2006,26(4):36-40.ZHANG Chunfa,WANG Huijie,SONG Zhiping,et al.Quantitative research of optimal initial operation pressure for the coal-fired power unit plant[J].Proceedings of the CSEE,2006,26(4):36-40.
[3]王宁玲.基于数据挖掘的大型燃煤发电机组节能诊断优化理论与方法研究[D].北京:华北电力大学,2011.
[4]王雷,张欣刚,王洪跃,等.基于支持向量回归算法的汽轮机热耗率模型[J].动力工程,2007,27(1):19-23.WANG Lei,ZHANG Xingang,WANG Hongyue,et al.Model for the turbine heat rate based on the support vector regression[J].Journal of Power Engineering,2007,27(1):19-23.
[5]VAPNIK V.统计学习理论的本质[M].张学工,译.北京:清华大学出版社,2000.
[6]沈曙光,王广军,陈红,等.最小支持向量机在系统逆动力学辨识与控制中的应用[J].中国电机工程学报,2008,28(5):85-89.SHEN Shuguang,WANG Guangjun,CHEN Hong,et al.Application of RLS-SVM in identification and control for inverse dynamics of system[J].Proceedings of the CSEE,2008,28(5):85-89.
[7]MARC G.Classes of kernels for machine learning:a statistics perspective[J].The Journal of Machine Learning Research,2002,2:299-312.
[8]邓乃扬,田英杰.数据挖掘中的新方法——支持向量机[M].北京:科学出版社,2004.
[9]王春林,周昊,周樟华,等.基于支持向量机的大型电厂锅炉飞灰含碳量建模[J].中国电机工程学报,2005,25(20):72-76.WANG Chunlin,ZHOU Hao,ZHOU Zhanghua,et al.Support vector machine modeling on the unburned carbon in fly ash[J].Proceedings of the CSEE,2005,25(20):72-76.
[10]CRISTIANINI N,SHAWE-TAYLOR J.支持向量机导论[M].李国正,王猛,曾华军,译.北京:电子工业出版社,2004.
[11]SCHOLKOPF B,MIKA S,BURGES C J C,et al.Input space versus feature space in kernel-based methods[J].IEEE Transactions on Neural Networks,1999,10(5):1000-1017.
[12]李蔚,仁浩仁,盛德仁,等.300MW火电机组在线能耗分析系统的研制[J].中国电机工程学报,2002,22(11):85-89.LI Wei,REN Haoren,SHENG Deren,et al.Developing a software for analyzing on-line the energy-loss for 300MW unit[J].Proceedings of the CSEE,2002,22(11):85-89.
[13]中华人民共和国机械电子工业部.GB 10184—1988电站锅炉性能试验规程[S].北京:国家技术监督局,1989.
[14]TSANG Eric,ZHAO S Y.Decision table reduction in KDD:fuzzy rough approach[J].Transactions on Rough Sets XI,2010,5946:177-188.
[15]王惠杰,张春发,宋之平,等.火电机组运行参数能耗敏感性分析[J].中国电机工程学报,2008,28(29):6-10.WANG Huijie,ZHANG Chunfa,SONG Zhiping,et al.Sensitive analysis of energy consumption of operating parameters for coal-fired unit[J].Proceedings of the CSEE,2008,28(29):6-10.
[16]沈士一,庄贺庆,康松,等.汽轮机原理[M].北京:中国电力出版社,1992.
[17]郭江龙 ,张树芳,姚力强,等.汽轮机性能预测BP神经网络输入层神经元筛选方法[J].汽轮机技术,2010,52(2):147-149.GUO Jianglong,ZHANG Shufang,YAO Liqiang,et al.A method for screening input nodes in BP artificial neural network on performance forecasting of steam turbine[J].Turbine Technology,2010,52(2):147-149.
[18]刘思峰.灰色系统理论及其应用[M].3版.北京:科学出版社,2004.
[19]陈林霄,王惠杰,杨新健.基于改进型BP神经网络的火电机组初压优化[J].节能,2013,32(11):53-56.CHEN Linxiao,WANG Huijie,YANG Xinjian.Initial pressure to optimize BP neural network based on improved thermal power[J].Energy Conservation,2013,32(11):53-56.
猜你喜欢
设备管理与维修(2022年21期)2022-12-28
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
机电信息(2021年5期)2021-02-22
魅力中国(2016年52期)2017-09-01
中国核电(2017年1期)2017-05-17
小猕猴智力画刊(2017年4期)2017-05-04
军事文摘·科学少年(2017年1期)2017-04-26
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
