
大数据与车险反欺诈模型构建
2015-04-24 08:02卢文龙
上海保险 2015年1期
卢文龙
中华联合财产保险股份有限公司
大数据与车险反欺诈模型构建
卢文龙
中华联合财产保险股份有限公司
保险欺诈几乎自保险诞生之日起就如影随形,而且随着经济的发展和科技的进步,欺诈形式更隐蔽,手段也更多样。一起起保险欺诈案件如巨坝之蝼蚁,不仅侵蚀着保险公司的利益,而且扰乱了正常的经济秩序。严厉打击保险欺诈,已经成为行业共识。保险公司在与不法分子“道高一尺,魔高一丈”的反复较量中,反欺诈投入越来越大,科技化水平越来越高。本文将以大数据应用为蓝本,就如何构建车险反欺诈模型作一介绍。
一、问题的提出
(一)欺诈数量呈上升趋势
马克思曾经说过,如果有300%的利润,就会有人铤而走险,甘冒上绞刑架的危险。在巨大的利益和不良动机的驱使下,保险欺诈如洪水猛兽咆哮而来,而且欺诈案件数量呈逐年上升态势。下表为某保险公司近三年欺诈案件情况的统计。数据显示,该公司保险欺诈金额呈逐年增长态势,且增幅扩大。这从一个侧面反映了行业反欺诈形势十分严峻。
保险欺诈也是全球性问题。比如英国,2006年保险欺诈金额占总赔款金额的比例为23%,2008年则上升到了27%,这其中还不包括虽有怀疑但无法拒赔的案件。
(二)欺诈类型日趋多样
从目前情况看,保险欺诈类型呈多样化、隐蔽化趋势。就车险而言,主要有以下几种情形:伪造事故现场骗赔、更换驾驶员骗赔、车辆套牌骗赔、虚构第三者骗赔、重复索赔、“倒签单”骗赔、扩大损失骗赔、 伪造理赔单证骗赔等等。骗赔形式五花八门,给反欺诈工作带来了较大挑战。传统的反欺诈手段已经难以适应当前反欺诈工作的需求。如何快速锁定欺诈案件,并有针对性地开展调查,是行业亟待攻破的难题。

表 某保险公司近三年欺诈案件情况统计
(三)欺诈案件呈团伙化趋势
现阶段的保险欺诈分工更细、专业性更高,呈团伙化作案趋势,也就是业内所说的串谋欺诈。就车险欺诈案件而言,可能会涉及被保险人、维修厂、医疗机构等多个串谋方,甚至保险公司员工、公安机关也会参与其中。串谋方往往与保险公司共同拥有一部分客户资源(如车主既可能是保险公司的客户,也可能是修理厂的客户),导致串谋方为了维护其所谓的“客户利益”,不经意间就成了骗赔的参与者。由于保险欺诈加入了串谋方利益,导致欺诈金额越来越高,保险公司的反欺诈成本也随之增高。同时,由于串谋方多为专业机构,欺诈的专业性更高,反欺诈难度越来越大。当前,随着经济全球化的不断发展,有的欺诈案件已经呈现出跨国作案的趋势,给欺诈案件的取证调查、损失追偿带来较大不便。
就保险公司而言,如何防范和抵御保险欺诈,主要取决于自身的反欺诈能力。传统的反欺诈主要依托理赔人员的责任心和工作技能,但是随着反欺诈难度的不断加大,单纯以理赔人员为主导的反欺诈模式,既费时又费力,而且反欺诈成效难以保证。行业需要探索新的保险反欺诈技术,弥补单纯依赖人力的不足。
二、大数据应用
(一)大数据在保险领域的应用
大数据又称海量数据,是指涉及的资料量规模巨大,无法通过目前主流软件工具撷取和处理,需要通过新的处理模式才能具有更强的决策力、洞察力和流程优化能力的信息资产。
目前,大数据已经在各行各业有了广泛应用,涉及金融、航空、医疗、气象预报、灾害预警等多个领域。具体到保险领域也将大有作为。
一是承保环节,可以快速高效地获取投保人、被保险人的个人信息,准确判断其投保意图和出险概率等,防范风险于未然。
二是保险期间,可以通过大数据网络及时获知被保险人或保险标的风险状况的变化情况,以便采取有针对性的防范措施。
三是出险时,通过大数据应用,建立反欺诈模型,实现案件与大数据“记忆”的比较,快速准确地获取相关情况及数据,有效识别欺诈案件。
(二)大数据应用于反欺诈工作需解决的若干问题
1.欺诈风险信息库的建立
大数据应用于反欺诈工作的直接体现就是欺诈风险信息库(也称为数据平台)的建立,这是建立反欺诈模型的基础和前提。就好比厨师能否做出一桌好菜,既取决于厨师的手艺,也取决于原材料的质量好坏和是否充足。欺诈风险信息库是否足够强大,取决于数据量的大小及其规范性和完整性。目前,由于各保险公司的信息录入要求和提取方式不尽相同,所以统一行业理赔服务标准和评价指标体系,实现理赔基础信息尤其是欺诈风险信息的无缝对接、可实时查询和有效回溯,是建立欺诈风险信息库的重要保障。
2.客户理赔信息的共享
目前,我国中外资保险经营主体有一百多家,仅财险经营主体就有六十多家,市场竞争之激烈有目共睹。千方百计获取客户信息、主动挖掘客户,是各保险经营主体参与市场竞争的主要手段。出于竞争的考虑,各保险经营主体都极不情愿让竞争对手获知本公司的客户信息。所以,共享客户信息并确保有效加密,是大数据应用面临的难点。要解决好这一问题,需要保险监管部门的有效监管、社会各界的大力支持,更需要各保险经营主体的积极配合和强力推动。
3.商业保险和社会保险之间信息的实时对接
商业保险和社会保险有很多区别,就数据性质而言,社会保险有很多商业保险难以企及的优势:一是社会保险数据更全面。社会保险的对象是所有劳动者,具有强制性和法定性,参与投保的群体很大,这正是大数据应用的前提条件。二是社会保险数据质量更高。社会保险由政府主导,很多信息可以在政府部门间实现数据交换和验证,参保人造假空间很小,数据质量更高。三是社会保险数据更权威。随着社会保险管理体制的不断健全,与社会保险相关的政策信息日臻完善,充分体现国家一段时期的政策导向,更具权威性。所以,实现商业保险和社会保险之间信息的实时对接,可以充分利用社会保险的信息资源,进一步丰富大数据模型的风险处置工具箱。
4.客户隐私的保护
客户隐私保护已经成为一个时代课题,每天无休止的垃圾短信和骚扰电话已经让我们不胜其烦,这些都是客户隐私泄露产生的后果。2013年,某大型保险公司因数据泄露产生的负面影响至今让人心有余悸。所以,确保客户信息安全,有效应对数据“裸奔”,是大数据应用必须解决的难题。
5.大数据风险的防范
相信很多人都了解光大证券的“乌龙指事件”。该事件不仅导致上证综合指数在一分钟内上涨超5%,对公司经营业绩也产生了重大影响。光大证券称,该事件的直接原因是公司在使用其独立的套利系统时出现了问题。“乌龙指事件”给大数据应用敲响了警钟,一个小小的技术问题就可能引发灾难性的后果。
三、保险欺诈的风险因子
对车险理赔大数据进行分析,结合反欺诈工作实际,可以总结出车险欺诈的主要风险因子,这是建立反欺诈模型的重要依据。就目前车险市场状况而言,保险公司常用的车险欺诈风险因子主要包含小碰撞却产生大损失、车辆损失与报告的交通事故无关、被保险人购买的是最新型的汽车、出险车辆是破旧老车、出险时间离保险起讫较近、短期内车辆连续出险多次、出险时间是夜间、报案人与驾驶员不一致、车辆多次出险但驾驶员不同、车辆批增险种后出险、同一报案电话涉及不同的出险车辆、非被保险人代报案、代领赔款等近40种。
这些风险因子大部分都是定性因子,要将其代入反欺诈模型,关键是要把定性因子合理地转化为定量因子。在数据转化过程中,要重点关注以下几点:一是风险因子的定量分析直接影响风险结果,需要专业人员科学评估并反复验证。二是数据转化过程中既要保证重要信息占一定权重,又不能为了突出某一方面的风险,而弱化了其他风险。例如不能因为过于关注案件是否夜间出险,而忽略了车型老旧等风险因素。
车险欺诈风险因子会随着保险市场环境、公司经营管理状况以及国家法律法规和诚信体系建设进程而改变,不同时期有不同特征,而且各地区由于民风民俗和地理环境等不同,也有较大差异。所以,设定风险因子不能“一刀切”,而应结合公司实际情况,因时因地而定。
四、反欺诈模型的建立及应用
(一)反欺诈模型运行原理
基于欺诈案件的风险因子和大数据支持,再经过一定的数据处理,就可以建立反欺诈模型。反欺诈模型建立后,就可以形成一个闭环式的案件循环处理系统。如下图所示。
闭环式案件循环处理系统主要有四个处理环节:一是对日常处理的欺诈案件进行综合分析,提炼出欺诈案件风险因子;二是根据提炼的风险因子,设立数理识别模型,实现风险状况量化处理;三是将日常处理案件导入识别模型,经过一定的数理运算,识别出疑似欺诈案件并进行验证处理; 四是根据新的欺诈案件风险状况提炼新的风险因子,不断丰富反欺诈模型,如此循环往复。
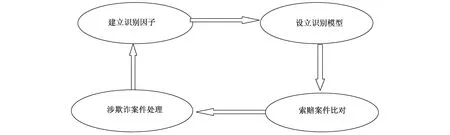
图 保险期诈案件循环处理系统
(二)主要的反欺诈模型简介
最早的欺诈风险识别主要集中在统计回归工具的应用,如PROBIT模型、LOGIT模型, 它们是最早的反欺诈模型。20世纪90年代末至21世纪初,通过进一步扩展模型参数和识别因子,一些功能强大的反欺诈模型相继出现,如AAG欺诈识别模型、决策树模型、RIDIT欺诈识别模型、专家识别系统等。
目前应用较为广泛的是专家识别系统,该模型能够处理非线性数据,能够随时调整风险因子,提高识别效能,而且具有缩短学习曲线的效应。
(三)反欺诈模型主要功能
就当前车险反欺诈工作现状而言,反欺诈模型应至少具备以下三项主要功能:
1. 防范理赔风险
主要是实现风险预警和风险定位。一是通过将欺诈风险因子植入反欺诈模型,实现高风险案件的理赔前自动风险预警,以便采取有针对性的处置措施。二是根据已有的风险规则,对高风险案件赋予相应的风险分值,进一步提高案件风险识别效率,也为后续的KPI考核提供依据。三是对于已经处理过的风险因素,反欺诈模型应保留修改轨迹,为后续的理赔稽查提供参考。
2.提高理赔效率
车险反欺诈模型可以帮助我们有效识别欺诈案件,但是案件风险点和真实性还需要人工确认。车险反欺诈模型不能成为提高理赔效率的羁绊,更不能因风险认定错误而影响了客户服务水平。所以,快速准确地锁定欺诈案件及其主要风险点,逐案生成赔案审核报告,应是车险反欺诈模型的一项基本功能。
3.规范理赔操作
车险反欺诈模型以准确、完整的理赔基础数据为运行条件,如果基础数据质量不高,可能无法有效识别风险。所以,应对此类案件设置较高的风险分值。这是一个相互作用、互为推动的过程。较高的风险分值会促使理赔人员规范理赔操作,尤其对于一些关键信息,可以设置为强制必录字段。理赔操作规范了,就会将一部分风险控制在前端,理赔管理水平自然也随之提高,这是建立车险反欺诈模型的终极要求。
大数据是信息时代的宠儿,以大数据为基础,构建日益完善的反欺诈模型,一定可以在保险反欺诈领域大有作为。
猜你喜欢
眼科新进展(2022年12期)2022-12-29
四川劳动保障(2021年8期)2021-12-02
成都信息工程大学学报(2021年3期)2021-11-22
四川劳动保障(2021年4期)2021-07-22
四川劳动保障(2021年5期)2021-07-19
四川劳动保障(2021年3期)2021-06-09
装备制造技术(2021年1期)2021-05-21
中国外汇(2019年16期)2019-11-16
中国外汇(2019年10期)2019-08-27
公民与法治(2016年24期)2016-05-17
