
随机匿名的位置隐私保护方法
2015-06-15 17:08杨松涛马春光
哈尔滨工程大学学报 2015年3期
杨松涛,马春光
(1.哈尔滨工程大学计算机科学与技术学院,黑龙江哈尔滨150001;2.佳木斯大学信息电子技术学院,黑龙江佳木斯154007)
随机匿名的位置隐私保护方法
杨松涛1,2,马春光1
(1.哈尔滨工程大学计算机科学与技术学院,黑龙江哈尔滨150001;2.佳木斯大学信息电子技术学院,黑龙江佳木斯154007)
基于空间匿名区域的研究方法容易受到多查询攻击和推理攻击,从而带来隐私暴露问题。为了保证基于位置服务中的隐私安全,基于k⁃匿名思想,构建了随机k⁃隐藏集以满足位置k⁃匿名性和位置l⁃多样性。随机k⁃隐藏集是由离散的位置点组成,并且彼此之间的网格距离大于阈值s。利用私有信息检索协议保证了查询结果在检索过程中的隐私性,实现了服务提供者在无法知道用户精确查询结果的前提下为用户提供基于位置的服务。仿真实验验证了算法的安全性和有效性。
无线网络;移动通信;隐私保护;基于位置服务;位置k⁃匿名;私有信息检索;随机匿名
Hilbert Cloak(HC)[4]考虑用户分布的不均匀性对k⁃匿名的影响,提出了互易性概念。HC方法中使用连续的网格构建尽可能小的ASR来保证隐私,但是有以下缺点:1)没有考虑位置l⁃多样性问题,即多个用户可能出现在同一语义位置范围内[5];2)没有考虑用户的移动性,即仅适用于快照查询,易受到连续查询攻击[6⁃7];3)互易性属性仅能保证查询隐私,但是无法保障位置隐私和轨迹隐私[8]。
LBS系统在现实应用中,快照查询和连续查询经常交叉进行,增加了隐私保护的复杂性。攻击者也会相互勾结,导致用户的地理数据和社会化数据相互关联,同时攻击者通常具有大量的背景知识,先进的数据挖掘技术和强大的关联攻击造成了一些时空匿名技术方案的失效。最近研究将PIR理论引入LBS隐私保护领域。相对于其他隐私保护方法而言,基于PIR理论的隐私保护方法[9⁃11]有不揭露任何空间信息和抗关联攻击这2个优点。
1 系统结构
考虑到移动用户与LBS服务器之间的通信带宽非常有限,例如:3G上行速度为64~128 k,下行速度为2 M。如果传输大的结果集,需要花费较高的响应时间,不能满足LBS的实时性,因此,本文采用3层中心服务器结构。该结构(图1)包括3个部分,即移动客户端(mobile client,MC)、位置隐藏服务器(location cloak server,LCs)和LBS服务器(LBS server,LBSs)。MC与LCs之间使用安全通道传输数据(如SSL),LCs隐藏了查询发出者的身份标识、IP地址和位置信息。
图1所示的系统结构中,敌手攻击遵循Honest⁃but⁃Curious模型,即LBSs在严格执行协议和算法的前提下,同时使用收集到的位置信息和背景知识推断用户的敏感信息,甚至LBSs可能出卖用户的敏感信息给不友好的第3方。
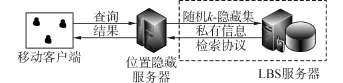
图1 系统结构Fig.1 System architecture
定义1 可信与半可信主体。设LBS系统中参与主体的集合为S={S1,S2,…,Sm},算法集合为A={A1,A2,…,An},协议集合为P={P1,P2,…,Pk},任意Si(i=1,2,…,m)严格执行算法Aj(j=1,2,…,n)或协议Pt(t=1,2,…,k)。如果Si(i=1,2,…,m)不会保留协议执行的中间过程并推导其他主体的隐私信息,则Si是可信主体,否则是半可信主体。
依照图1所示的系统结构,本文确定了4个基本假设如下:
假设1 LCs和MC是完全可信的。LBSs是半可信的,为用户提供服务,但是有可能直接或间接泄露用户的隐私信息;
假设2 敌手可以从公共数据库(例如:电话黄页,家庭住址等)获得一些先验知识。同时,敌手具备统计分析和推理能力,可以利用匿名信息和先验知识形成后验知识;
假设3 用户的分布是有规律的,但是分布密度是不均匀的,这是符合现实世界情况的,城市中心地带用户分布密集,而郊区用户数量较少;
假设4 LCs使用的匿名算法是公开的。
一个查询请求处理过程如图2所示。

图2 查询处理过程Fig.2 Query processing
2 随机位置隐藏
定义2 (k,s)受限查询Q(k,s),Q(k,s)以6元组形式表示,形式化表示为

式中:u代表用户身份的假名;l代表用户的当前位置坐标;t代表当前查询时间;c代表用户的查询内容;s代表用户要求的网格距离;k代表用户要求的匿名度。
如果位置集合满足Q(k,s)中的k、s要求,则称该位置集合为(k,s)受限位置集合,记为S(k,s)。
定义3 随机k⁃隐藏集(kRCS)。kRCS可以形式化表示为

式中:SID代表kRCS的标识符;S(k,s)={l1,l2,…,lk},li(i=1,2,…,k)代表用户ui的当前位置。
定义4 网格距离(D)。用户之间的网格距离可以形式化表示为

式中:ni、nj分别代表用户ui、uj的当前位置ui.l、uj.l所在网格的序号。
为了方便计算,本文将平面空间划分为网格图形式,为每个网格赋予一个序号。以图3为例,在4×4的网格图上随机分布了20个移动用户。u1~u20是周期性地向LCs更新位置信息的移动用户,假设用户u3发出k=5,s=2的查询,则kRCS={SID,(u3.l,u9.l,u12.l,u15.l,u10.l),c,t},kRCS算法形成的S(k,s)不是唯一的,这样有利于增强抗LBSs推理攻击的能力。
LCs通过执行kRCS算法来实现查询用户的位置隐藏。具体过程如下:
1)LCs接收到查询请求Q(k,s),提取参数l、s和k,构建kRCS。初始状态下位置集合S(k,s)为空集,LCs将l加入S(k,s);
2)从每个网格内选取一个当前用户的位置并将其加入集合T,要求T中任意2个元素之间的D必须大于s;
3)判断T中元素个数是否满足用户要求的k值,如果满足要求,则随机选择k-1个元素加入S(k,s),扰乱S(k,s)中元素的顺序,否则位置隐藏失败;
4)提取参数t、c,与S(k,s)和新生成的kRCS的标识符共同构成kRCS;
5)LCs发送kRCS给LBSs,用于检索服务。

图3 4×4空间分区样例Fig.3 4×4 space partitioning example
3 私有检索
定义5 候选结果集(CS),LBSs对S(k,s)中的每一个位置元素进行最近邻查询或k⁃最近邻查询,查询结果集合为CS,形式化为

式中:ri是S(k,s)中第i个位置的查询结果,ri以m位的字符串表示。
本文方法中,k值的大小会影响CS的尺寸,k值较大,CS也较大。LCs对CS求精的方式会增加LCs的计算负担和LCs与LBSs之间的通信负载。同时,候选结果集是LBSs推断用户位置和身份的重要依据。因此,本文采用PIR检索技术,服务器无法确定用户u对第i条记录感兴趣。为了便于PIR检索,CS以m×k位矩阵表示,即MR=[r1,r2,…,rk]。MR的第i(i=1,2,…,k)行数据构成新的t×t位矩阵Mi,则MR=[M1,M2,…,Mm]T。类似于可计算PIR协议中秘密检索1位数据的方法,分别检索m个矩阵中的数据,从而将可计算PIR协议从秘密检索1位数据扩展为秘密检索m位数据。PIR检索过程如下:
1)LCs随机选取k位自然数N,且N=q1q2,q1,其中q2是k/2位素数,产生查询信息y=[y1,y2,…,yt],yb属于二次非剩余集(QNR),yi属于二次剩余集(QR),且b≠j,并将y发送给LBSs;
2)LBSs分别计算M1,M2,…,Mm,

式中:r代表行号,并将Zi={zi[1],…,zi[t]},i=(1,…,m)发送给LCs;
3)依据欧拉准则,LCs分别计算

如果式(3)为“真”,则zi[r]∈QR,Mi[r,b]=0,否则,zi[r]∈QNR,Mi[r,b]=1。
4 分析与验证
LBS系统中,服务质量和隐私保护不存在合作的可能,存在的研究工作都基于“零和博弈”的观点。同时,查询样例和查询结果集合是攻击者推断用户位置隐私的直接依据。本文从3个角度分析提出的随机匿名方法的抗攻击能力和服务质量。
1)时空匿名角度。本文提出的随机匿名方法中,生成kRCS的集合覆盖了整个服务区域,S(k,s)内的元素是离散的和随机的,同时满足了位置k⁃匿名性和位置l⁃多样性。用户可以提高k值和s值以实现扩大匿名区域范围,增强隐私度。由于方案中不采用ASR方式,进而不会遭受连续多查询攻击和推理攻击。
2)查询结果角度。可计算PIR协议的安全性基于二次剩余假设,如果N是2个素数的乘积,即N=q1q2,q1、q2是大素数,那么计算模N的平方根等价于对N进行因子分解,区分二次剩余和二次非剩余的概率很小。LBSs根据kRCS检索到的CS驻留在LBSs的缓存内。在LCs与LBSs之间执行PIR协议过程中,LCs从CS中秘密获得查询用户需要的服务信息,攻击者关联查询用户位置和查询内容的概率为1/k。所以,本文方法不会遭受关联攻击。
3)服务质量角度。匿名时间、匿名成功率、服务时间和通信量是影响服务质量的4个基本要素。kRCS算法的匿名时间和匿名成功率主要取决于网格划分的精细度和k值。网格越密,匿名时间越长,匿名成功率越高。k值越大,匿名时间越长,匿名成功率越低。kRCS算法比较简单,在线性复杂度的时间内即可完成位置匿名。通常情况下,网格数量和移动用户数量远远大于用户的隐私要求。因此,在本文方法中,匿名成功率不是关注的主要问题。服务时间包括PIR检索时间和LBSs查询时间。PIR检索时间必然延长了总的服务响应时间,也可以在有限多项式时间内完成。但是,PIR协议带来了高度的隐私性,符合服务质量与隐私之间均衡的理念。LBSs查询采用简单的单点最近邻查询技术,优于范围查询方法,简化了LBS服务器的查询处理过程。LCs与LBSs之间的通信量取决于CS的尺寸和k值。
图4为随机匿名方法与基于ASR的方法比较。如图4(a)所示,随着匿名度k值的增加,kRCS、HC[4]和PG[5]的匿名区域的覆盖面积均变大,kRCS匿名算法产生的用户覆盖面积变化明显。而且kRCS的匿名覆盖面积远大于其他二者。kRCS匿名算法以构建随机匿名集的方式实现匿名,在不降低匿名度的情况下,覆盖面积变大增加了匿名的安全性。如图4(b)所示,kRCS、HC和PG在平均匿名时间上没有太大的差异,k值与匿名时间成正比关系。如图4(c)所示,随着用户数量N值的增加,因为更容易实现匿名,HC和PG的覆盖面积变小,kRCS的覆盖面积变化不明显。

图4 随机匿名方法与基于ASR的方法比较Fig.4 The comparison of k⁃RCS and ASR⁃based methods
图5 为POIs对查询效率的影响结果。如图5(a)所示,随着兴趣点POIs数量和k值的增加,平均查询时间增长。如图5(b)所示,k值越大,候选结果集越大,则kRCS和ASR⁃based方法查询处理时间越长,PIR⁃ based[9]方法不受k值的影响,kRCS的平均检索时间在k<30时优于PIR⁃based方法。如图5(c)所示,随着POIs数量增加,ASR⁃based方法的候选结果集变大,kRCS的候选结果集不受POIs数量的影响,PIR⁃based方法的候选结果集虽然不受k的影响,但是受到POIs数量的影响。
5 结束语
位置k⁃匿名和位置模糊是典型的隐私保护技术,分别保护查询隐私和位置隐私。但是,以往研究方法中主要是以匿名框的形式掩盖用户的真实位置,匿名框的相交和重叠会带来多查询攻击和推理攻击。本文提出一种随机匿名的位置隐私保护方法,采用3层匿名器结构和k⁃匿名技术,不产生匿名框,以离散匿名集的形式同样可以达到位置k⁃匿名和位置模糊的效果。设计了kRCS匿名算法,该算法使用离散点的位置构成位置隐藏集合,实现了k⁃匿名集合中用户的离散性和随机性,在保证查询用户匿名度的前提下,提高了匿名区域的覆盖面积,同时并不牺牲用户的服务质量,能够满足位置k⁃匿名、位置l⁃多样性,达到了位置隐私和查询隐私的双重保护目标,提高了隐私安全性和匿名效率。采用了PIR协议,对LBSs查询候选结果集进行秘密检索,保证了查询结果的隐匿性。采用简单的单点最近邻查询技术简化了LBSs的查询处理过程。实验验证了该方法隐私安全强度高于基于匿名框的方法,计算效率高于基于PIR的匿名方法。
[1]周傲英,杨彬,金澈清,等.基于位置的服务_架构与进展[J].计算机学报,2011,34(7):1156⁃1171.ZHOU Aoying,YANG Bin,JIN Cheqing,et al.Location⁃based services:architecture and progress[J].Journal of Computers,2011,34(7):1156⁃1171.
[2]SHIN K G,JU X,CHEN Z,et al.Privacy protection for us⁃ers of location⁃based services[J].IEEE Wireless Communi⁃cations,2012,19(1):30⁃39.
[3]BENISCH M,KELLEY P G,SADEH N,et al.Capturing location⁃privacy preferences:quantifying accuracy and user⁃burden tradeoffs[J].Personal and Ubiquitous Computing,2011,15(7):679⁃694.
[4]KALNIS P,GHINITA G,MOURATIDIS K,et al.Preven⁃ting location⁃based identity inference in anonymous spatial queries[J].IEEE Transactions on Knowledge and Data Engi⁃neering,2007,19(12):1719⁃1733.
[5]BAMBA B,LIU L,PESTI P,et al.Supporting anonymous location queries in mobile environments with privacy grid[C]//Proceedings of the 17th International Conference on World Wide Web.Beijing,China,2008:237⁃246.
[6]林欣,李善平,杨朝晖.LBS中连续查询攻击算法及匿名性度量[J].软件学报,2009,20(4):1058⁃1068.LIN Xin,LI Shanping,YANG Zhaohui.Attacking algo⁃rithms against continuous queries in LBS and anonymity measurement[J].Journal of Software,2009,20(4):1058⁃1068.
[7]NUSSBAUM D,OMRAN M T,SACK J.Techniques to pro⁃tect privacy against inference attacks in location based serv⁃ices[C]//Proceedings of the 3rd ACM SIGSPATIAL Inter⁃national Workshop on Geo⁃Streaming.New York,USA,2012:58⁃67.
[8]霍峥,孟小峰.轨迹隐私保护技术研究[J].计算机学报,2011(10):1820⁃1830.HUO Zheng,MENG Xiaofeng.A survey of trajectory priva⁃cy⁃preserving techniques[J].Journal of Computers,2011(10):1820⁃1830.
[9]GHINITA G,KALNIS P,KHOSHGOZARAN A,et al.Pri⁃vate queries in location based services:anonymizers are not necessary[C]//Proceedings of the 2008 ACM SIGMOD In⁃ternational Conference on Management of Data.Vancouver,Canada,2008:121⁃132.
[10]KHOSHGOZARAN A,SHAHABI C,SHIRANI H.Loca⁃tion privacy:going beyond k⁃anonymity,cloaking and ano⁃nymizers[J].Knowledge and Information Systems,2011,26(3):435⁃465.
[11]WANG S,CHEN C,TING I,et al.Multi⁃layer partition for query location anonymization[C]//Proceedings of the 2012 IEEE International Conference on Systems,Man,and Cybernetics.Seoul,Korea,2012:378⁃383.
Random anonymity method for location privacy protection
YANG Songtao1,2,MA Chunguang1
(1.College of Computer Science&Technology,Harbin Engineering University,Harbin 150001,China;2.Colleges of Information&Electronic Technology,Jiamusi University,Jiamusi 154007,China)
The methods that are based on the anonymous spatial region are vulnerable to multiple queries attacks and inference attacks,which result in the privacy exposure issues.In order to ensure the location⁃based privacy se⁃curity,this paper constructed the random k⁃cloak set to meet requirement of location k⁃anonymity and location l⁃di⁃versity.Random k⁃cloak set is composed of discrete dots of location,and the grid distance between dots is greater than the threshold value s.Private information retrieval employed in the study guaranteed privacy in retrieval pro⁃cessing,and achieved the goal that the server provides the location⁃based service for users on the premise of not knowing user's query results.Simulation experiments verify the security and validity of this method.
wireless networks;mobile communication;privacy protection;location⁃based services;location k⁃ano⁃nymity;private information retrieval;random anonymity
10.3969/j.issn.1006⁃7043.201311024
http://www.cnki.net/kcms/detail/23.1390.U.20150109.1654.019.html
TP393
A
1006⁃7043(2015)03⁃0374⁃05
2013⁃11⁃11.网络出版时间:2015⁃01⁃09.
国家自然科学基金资助项目(61472097);黑龙江省教育厅科学技术研究基金资助项目(12541788);佳木斯大学重点资助项目(Lz2013⁃010).
杨松涛(1972⁃),男,副教授,博士研究生;
马春光,E⁃mail:machunguang@hrbeu.edu.cn.可能汇聚成一点,在稀疏区域,k⁃ASR可能很大。
基于位置的服务(location⁃based services,LBS)是移动互联网中的典型应用,包括定位和电子地图等技术。在哪里(空间信息)、和谁在一起(社会信息)、附近有什么资源(信息查询)是LBS系统中最基本的内容[1]。为了了解周边兴趣点(points of interest,POIs)信息,用户必须向LBS服务器提供位置信息和服务内容。然而,LBS提供者可能主动推理用户敏感信息并将其出卖给一些商业机构,导致LBS提供者不可信成为了危及用户位置隐私的主要原因。目前,LBS隐私保护是研究的热点问题,有效地推动了位置隐私保护的研究[2]。一些研究方法实现了位置隐私,但是个人隐私与服务质量产生新的冲突,换句话说,用户必须在隐私保护和精确服务之间做出权衡。尽管基于策略的方法对位置数据的收集、存储和使用等方面做出了规定,但是,执行这些政策通常超出了用户的控制[3]。本文提出了一种随机位置隐藏的隐私保护方法,采用可信匿名器结构和k⁃匿名技术,使用随机离散匿名集的方式取得更大的覆盖面积,满足了位置k⁃匿名和位置l⁃多样性,保证了用户的位置隐私,但是不会增加计算量和通信负载。查询候选结果集是LBS提供者推断用户敏感信息的重要依据,本文采用可计算私有信息检索协议(private information retrieval,PIR)秘密检索候选结果集,保证了用户查询结果的隐私性。
位置k⁃匿名模型中的位置k⁃匿名强度取决于k值的大小,一般来说,k值越大则用户的精确位置坐标与查询信息的关联度越小,然而服务质量越差。位置k⁃匿名混淆了匿名查询和位置隐私的概念,k⁃匿名可以切断查询内容和用户身份的关联,但是无法保证用户位置轨迹隐私。k值的大小不依赖于匿名空间区域(a⁃nonymous spatial region,ASR),在用户密集区域,k⁃ASR
马春光(1974⁃),男,教授,博士生导师.
猜你喜欢
小猕猴学习画刊·下半月(2021年3期)2021-05-20
人民长江(2019年3期)2019-10-20
收藏界(2019年2期)2019-10-12
电子制作(2018年18期)2018-11-14
专利代理(2016年1期)2016-05-17
学习月刊(2015年6期)2015-07-09
学习月刊(2015年14期)2015-07-09
植物保护(2012年1期)2012-02-28
质量与标准化(2010年5期)2010-05-03
质量与标准化(2010年3期)2010-05-03
