
基于波束形成器输出比的自适应语音分离方法
2016-06-16 01:33刘志伟林嘉宇国防科技大学电子科学与工程学院长沙40073武警860部队盘锦2400
微处理机 2016年2期
庞 宇,刘志伟,林嘉宇(.国防科技大学电子科学与工程学院,长沙 40073;2.武警860部队,盘锦 2400)
基于波束形成器输出比的自适应语音分离方法
庞 宇1,2,刘志伟1,林嘉宇1
(1.国防科技大学电子科学与工程学院,长沙410073;2.武警8610部队,盘锦124010)
摘 要:运用波束形成的方法能够有效地从干扰和噪声中提取所需的语音信号,如最小方差无失真响应的方法。然而,为了避免应用波束形成器进行语音分离时所产生的信号抵消现象,当目标讲话者处于活动状态的时候,该波束形成器的适应性应处于暂停状态,这就需要对目标讲话者的语音活动状态进行分类。基于这种思想,首先从信号模型和系统模型出发,介绍了“波束形成器输出比”这个新量的相关概念和基于波束形成输出比的“BOR-VAC”新方法。而后对窗口值、阈值的选取和VAC模块的实现过程进行了详述。最后通过仿真实验实现并验证了这种基于波束形成器输出比的自适应语音分离新方法的高效性和可靠性。
关键词:语音分离;波束形成;双波束;语音活动性分类;波束形成器输出比;自适应控制
1 引 言
语音分离的目的是从嘈杂背景中提取出目标讲话者的声音。目前用于语音分离最普遍的三种方法是:①波束形成方法;②基于独立成分分析(ICA)的盲源分离(BSS)方法;③单声道分离方法。其中,波束形成技术利用了空间信息,BSS利用了信号的统计独立性,而单声道分离则利用了二进制掩蔽或者基于混合模型的技术。
尽管从20世纪50年代后的长期发展中出现了诸多算法,但语音分离仍然是实践中的一个难题。一个不可忽略的原因是,分离算法实际性能的好坏取决于前提条件。对目标讲话者活动性的判断作为其中重要的一项,在通常情况下仍然是一种假设[1]。这里所研究的算法就在于消除这一假设,并应用解决方案来实现基于波束形成方法的自适应语音分离系统。
众所周知,波束形成是一个使用传感器阵列的多功能空间滤波方法。在语音分离中,波束形成系统对输入信号应用权向量(即波束形成器)来获得输出。其权向量应满足预先定义在不同方向上的功率响应要求[2]。例如,一个MVDR波束形成器的权向量就应满足:在与目标讲话者的方向上功率响应一致的同时,化[3]。这使得MVDR波束形成器可以对非平稳信号进行高性能分离,如语音信号。然而,应用MVDR波束形成器进行语音分离时最常见的问题是信号抵消现象,即当目标讲话者的状态是活动的同时波束形成器的适应性也为开启状态,那么所需信号在输出时将被抵消掉[4]。
为了减小这种现象的发生,这里提出了一种暂停策略。由于人们在交谈过程中的语音活动状态会无规律的改变,因此必须首先确定在每个输入音段中的讲话者,称其为“语音活动性分类”(VAC)的问题。为使波束形成器拥有自适应机制,对于语音活动性分类问题的自动解决方案至关重要。
2 自适应波束形成系统概述
2.1信号模型
设麦克风阵列为M元,P(P≥2)个声源中的两个为主要讲话者,hp,m为讲话者p(p∈{1,2,...,P})与麦克风m(m∈{1,2,...,M})之间的室内脉冲响应,sp为来自讲话者p的原始信号的矢量样本,vm为麦克风m所接收到的噪声,k(k∈{1,2,...,Nf})为频率窗口指数,q(q∈{1,2,...})为帧指数,X,S,H,V为时域中相关分量的频域系数,则其信号在频域中的多路径模型为:
X(k,q)=∑pp =1Sp(k,q)Hp(k)+ V(k,q)(1)
如果只使用两个波束形成器来记录两个目标讲话者,那么该系统被称作“双波束系统”(BiBeam){W1,W2},其中Wp(p∈{1,2})是目标讲话者p所对应的波束形成器。
如果双波束系统被赋予一个多路径输入信号X(k,p),那么该系统的输出包含两个波束形成器的输出{Y1(k,p),Y2(k,p)},其中
Yp(k,p)= WHp(k,p)X(k,p)(2)
2.2系统模型
图1展示了所提出的用于两个主要讲话者语音分离的自适应波束形成系统。该系统包含两个模块:①用来识别活动讲话者的VAC模块;②语音分离模块。当给定一个多路径输入信号X后,VAC模块首先识别两个讲话者的语音活动状态。然后VAC模块将处理结果送入第二个模块,以便系统决定W1和W2这两个适应性波束成形器各自的开关状态。最后,每个适应性波束形成器从输入信号中分离出想要的信号。
第二个模块中的两个适应性波束形成器是两个MVDR波束形成器,其中波束形成器Wp负责分离讲话者p的语音,其值为[2]:
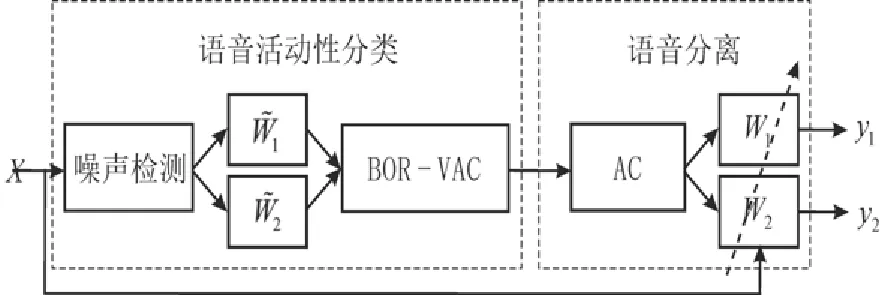
图1 自适应波束形成系统示意图
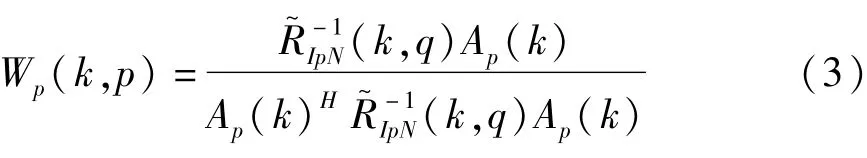
这里的R~IpN是干扰和噪声协方差矩阵的一个估计,Ap是讲话者p的方向向量。为了保持较高的语音分离性能,MVDR的权矢量需要定期与不断更新的R~IpN相适应。设u(u∈(0,1))为遗忘速率,则有R~IpN的更新依据下列公式[5]:
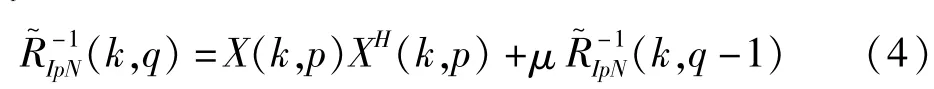
3 算法研究与实现
3.1波束形成器输出比
对双波束系统加载一个多路径输入信号X(k,p),则输出信号中两个波束形成器的输出功率之比叫做“波束形成器输出比”(BOR)。那么,在长度为k的频率窗口中,帧长为q的两个输出信号,则一个长度为l的片段的BOR为:
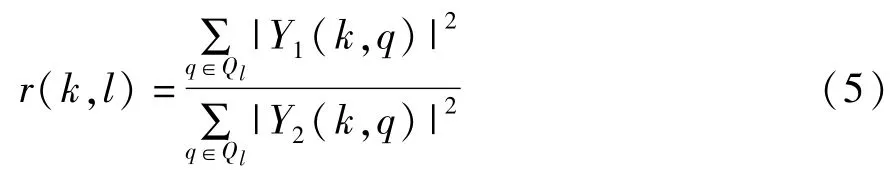
这里的Ql是片段l中帧指数的集合。注意到,在此定义中,双波束系统可以使用任何波束形成方法。
在图2中,输入信号中包含两个讲话者和白噪声,它们合成一个无混响的记录环境。上图展示了基于MVDR双波束系统计算出的BOR值,下图展示了两个讲话者语音的原始参照信号。图中的BOR值展示了两个讲话者的语音活动性不断变化时所表现出的特性,即当只有1号讲话者(SP1)是活动的时候,BOR达到一个很大的值;当只有2号讲话者(SP2)是活动的时候,BOR达到一个很小的值;当两个讲话者同时是活动的时候,BOR在中间值范围内波动。从而根据BOR的值可以辨别不同的语音活动性事件。
3.2BOR-VAC方法
进一步注意到,由于SP1-BOR和OVL的支集能被很好的分离开来,所以上面的SP1-OVL-SP2三种事件分类问题可以被简化为SP1-OVL和SP2-OVL两个子分类事件。特别地,将SP1中的BOR记作r1,将SP2中的BOR记作r2。每个子分类SP1-OVL(SP2-OVL)都使用一个阈值θ1(θ2)和一个频率窗k1(k2)来实现。对于给定一个长度为l的输入片段,VAC所做出的决策如下,并称其为BOR-VAC方法:
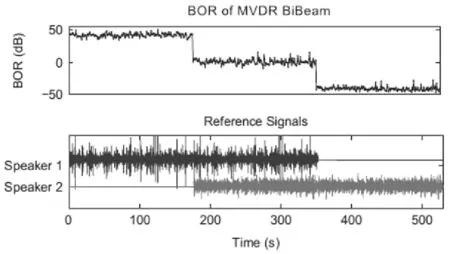
图2 MVDR双波束系统中BOR分布示意图

3.3窗口值和阈值选取
在频率k下,令f(Rk0)(r),g(Rk0)(r),f(Rk2)(r),g(R
k2(r)分别为OVL-BOR和SP2-BOR的概率密度函数和累积密度函数。在一个值为k的频率窗中,如果SP2-OVL有一个阈值θ2,令α为当OVL为真时决策为SP2的概率(误报率),β为当SP2为真时决策为OVL的概率(漏报率),则有:
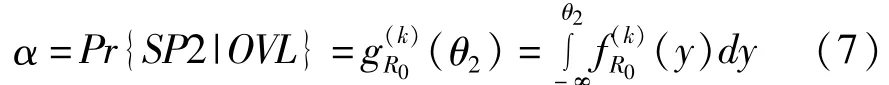
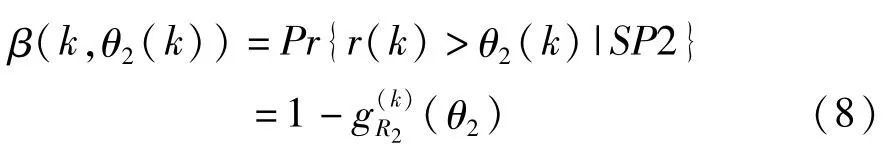
在一个分类问题中,总是试图将误判概率最小化。当给定一个期望的误报率α后,遵循以下步骤可以找到最优的窗口值k2和阈值θ2:
(1)在每个值为k的频率窗中,计算误报点θ2(k):g(k)R0(θ2)=α
(2)在每个值为k的频率窗中,计算β(k,θ2(k))
(3)选择最优的窗口值k2,使得:k2= argminkβ (k,θ2(k))
(4)选择阈值:θ2=θ2(k)
鉴于BOR的精确分布难以获取,这里利用语音活动性事件z(z∈{0,1,2})近似为高斯分布的对数分布log-BOR[6],RL,z(k)为其随机变量,则有RL,z(k)~N(μz(k),σ2z(k))。令erf为误判函数,则RL,z(k)的累积密度函数为[7]:
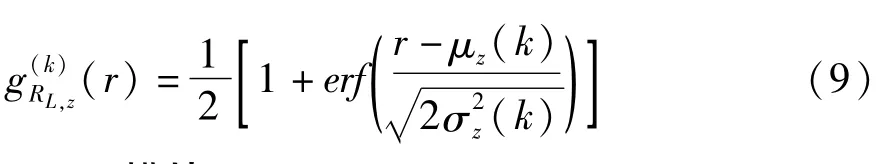
3.4VAC模块
图3中的ABS系统应用BOR-VAC方法实现自动AC机制的详细处理过程:
(1)多路径输入信号X通过噪声检测组件,其中的非纯噪声信号被长度为、重参数为的FFT变换为频域信号;
(2)在所选择的值为k1和k2的频率窗(分别对应子分类SP1-OVL和SP2-OVL)中,CBF双波束组件{W~1,W~2}对两个讲话者进行波束形成处理,而后输出{Y~1,Y~2};
(3)在BOR-VAC组件中,计算每个长度为LS、重叠参数为L~S的片段在以上两个频率窗中的log-BOR值rL(k1,l)、rL(k2,l),并将其与阈值θ1、θ2比较,从而利用分类规则(6)确定该片段均衡的VAC决策。
(4)在VAC模块的最后阶段,由于log-BOR值是针对重叠参数为L~S的片段计算所得,因此结果中将出现输入样本与片段一对多的情况,时域转换器根据多数投票算法从众多片段中选取相应片段作为样本的最终分类结果。
(5)VAC模块将信息传递给AC组件,MVDR双波束组件立即对两个讲话者进行语音分离,并得出结果。)
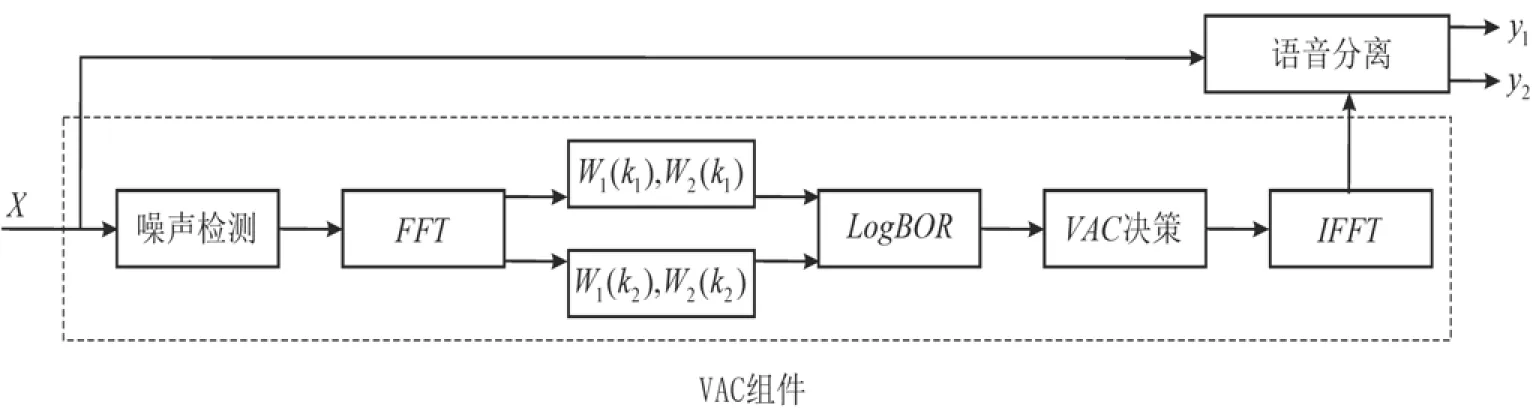
图3 VAC模块处理过程
4 仿真验证
现有两个讲话者位于距麦克风阵列中心的距离大约80cm,分开角度为50°的两个位置。在仿真实验中,针对SP1、OVL和SP2三类事件,BOR-VAC系统使用各事件1分钟长的数据进行训练。将合成数据的误报率设定为0.01,CBF双波束中使用的FFT长度大约32ms,具有50%的重叠。合成录音使用的片段长度为60帧(大约1s),实验结果如图4所示。
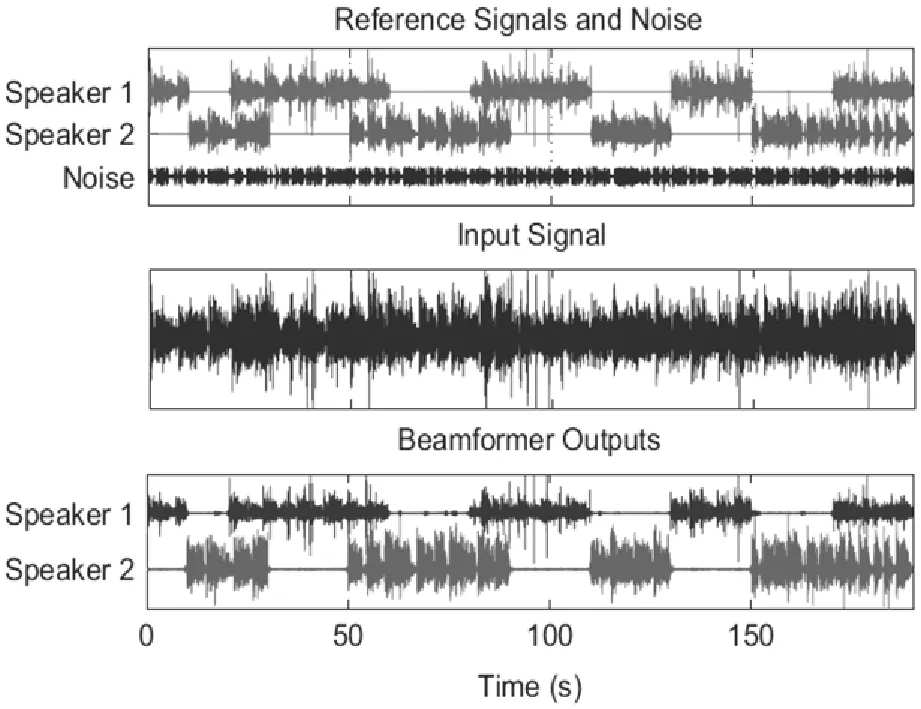
图4 基于BOR的自适应语音分离
5 结束语
研究并实现了一个基于语音活动性分类自适应机制的新型语音分离系统,基于新式的VAC可行性解决方案设计的自动VAC模块是该系统的重要组成部分,该方法的核心元素是BOR这个新的量值。通过利用基于BOR-VAC方法所得的VAC结果,实现了MVDR波束形成器适应性的自动控制。这种单独基于波束形成方法的VAC解决方案不仅具有较低的复杂性,而且分别在合成语音和真实记录数据中都实现了较高的分类精度。
参考文献:
[1]E Vincent,S Araki,F Theis,G Nolte,P Bofill,H Sawada,A Ozerov,V Gowreesunker,D Lutter,N Q Duong.The signal separation evaluation campaign(2007-2010):achievements and remaining challenges[J].Signal Process,2012,92(8):1928-1936.
[2]H L V Trees.Optimum Array Processing Part IV of Detection,Estimation,and Modulation Theory[M].1st ed.Wiley-Interscience,2002.
[3]K Kumatani,T Gehrig,U Mayer,E Stoimenov,J McDonough,M Wolfel.Adaptive beamforming with a minimum mutual information criterion[C].IEEE Trans.Audio Speech Lang.Proc,2007,15(8):2527-2541.
[4]H Cox.Resolving power and sensitivity to mismatch of optimum array processors[M].J.Acoust.Soc.Am.,1973,54(3):771-785.
[5]I McCowan.Robust speech recognition using microphone array(Ph.D.thesis)[D].Queensland University of Technology,Australia,2001.
[6]N T Thuy,W Cowley,A Pollok.Voice activity classification using Beamformer-Output-Ratio[J].2012 Australian Communications Theory Workshop,IEEE,2012:105-110.
[7]M H DeGroot,M J Schervish.Probability and Statistics [M].3rd ed.Addison Wesley,2002.
Automatic Adaptive Speech Seperation Method Based on Beamformer-output-ratio
Pang Yu1,2,Liu Zhiwei1,Lin Jiayu1
(1.College of Electronic Science and Engineering,National Defense Technology University,Changsha 410073,China;2.The Armed Police 8610,Panjin 124010,China)
?
Abstract:The beamforming method can be used to effectively extract the desired speech signal from interference and noise.However,to avoid signal cancellation,the classification for the speakers' voice activity status is required.In this paper,we study and implement a new method based on beamformer-output-ratio,and construct an automatic adaptive beamforming system to implement speech separation.The simulation verifies the reliablity of the algorithm.
Key words:Speech separation;Beamforming;BiBeam;Voice activity classification;Beamformer-output-ratio;Adaption control
DOI:10.3969/j.issn.1002-2279.2016.02.011
中图分类号:TN912.3
文献标识码:A
文章编号:1002-2279(2016)02-0037-04
作者简介:庞宇(1987-),男,辽宁省盘锦市人,工程硕士,主研方向:现代通信技术。
收稿日期:2015-06-25
