行政记录整合的贝叶斯分层记录链接模型及应用
2016-08-04 05:42丁东洋周丽莉
统计与信息论坛 2016年7期
丁东洋,周丽莉
(南昌大学a. 廉政研究中心;b. 公共管理学院,江西 南昌 330031)
行政记录整合的贝叶斯分层记录链接模型及应用
丁东洋a,b,周丽莉a
(南昌大学a. 廉政研究中心;b. 公共管理学院,江西 南昌 330031)
摘要:记录链接的技术问题与统计理论密切相关,尤其是在建立记录链接分类规则时需要构建统计模型,识别关键变量以完成数据匹配。在贝叶斯框架下构建分层模型整合行政记录,通过多元回归可以实现匹配错误率的估计,而且一对一限制下的记录链接允许通过模块反映记录信息的来源变化,基于MCMC模拟的后验分布计算方便,有助于提高数据整合效率。
关键词:记录链接;贝叶斯方法;分层模型
一、引 言
行政记录指的是政府行政部门记录的关于自然人或其他实体的信息,如人事档案、户口薄、纳税登记表、单位地址目录等。行政记录的统计开发是政府各部门贯彻落实《统计法》的重要措施,而其中的重要工作就是行政记录整合。行政记录整合是指将不同行政部门的行政记录进行链接,形成统一完整的名录库,在整合过程中需要借助记录链接技术。记录链接(Record linkage)指的是把来自不同数据库的同源记录,通过直接和间接识别码将记录链接起来的技术,是把两个或两个以上的单一记录整合成一个综合记录的过程。
记录链接理论在行政记录上的应用无疑是一次重要的技术创新。国外许多政府统计机构已经开始积极适应大数据时代的变化和要求,应用现代化信息技术,使用记录链接技术整合行政记录。运用记录链接方法时,如果行政记录中需要链接的数据有着准确无误并且相同的识别码,那么链接的过程十分容易操作。但是如果直接识别码有误或缺失,记录链接的技术问题需要结合统计理论来解决。由于对行政记录的研究尚属一个较新的领域,大部分文献集中于行政记录的统计开发前景和名录库建设等问题[1]。但是关于用于行政记录整合的记录链接技术研究较少,尤其是贝叶斯框架下的分层模型构建和后验分布模拟等问题都有待深入研究。
二、记录链接理论及模型
(一)记录链接的Fellegi-Sunter模型
下面用一个简单的例子来说明整合行政记录时应用记录链接技术的原因。表1中来自不同行政部门的3对记录代表3个自然人。在前两种情况下,两对人有相类似的姓名、地址和年龄。在整合这种类型的行政记录时我们希望能够通过统计模型识别判断并进行匹配。在第三种情况下,对应记录的详细信息我们可能会知道该对的第一条记录是一个20年前医学专业的大学生。第二条记录来源于一个曾就读于江西医学院的工作在湖北的医生信息。这与一个之前在不同城市大学中就读于医学院的信息相关联。综上可以发现,运用良好的自动化方法能够确定前两对信息代表同一个人。将自动化的方法和人类的思维理解相结合,可能确定第三对是同一个人。记录链接技术的主要目的就是识别行政记录匹配与否,并确定是否需要进一步人工审查。
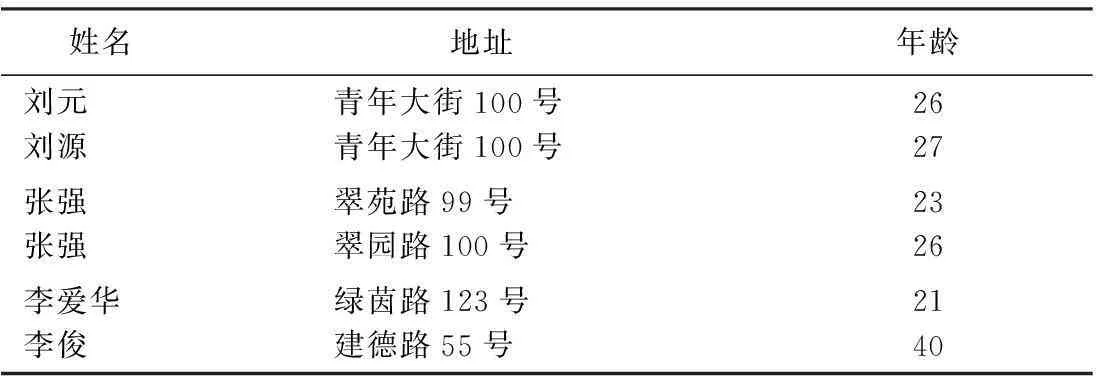
表1 行政记录整合的基本形式示例
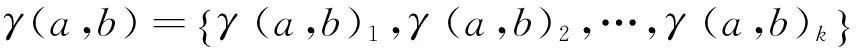
R(γ)=p(γ(a,b)k|(a,b)∈M)/p(γ(a,b)k|(a,b)∈U)
(1)
上式表示在记录链接中文件匹配时出现比较结果γ(a,b)k的概率与不匹配时出现比较结果γ(a,b)k的概率的比值,其中γ(a,b)k是配对信息,例如行政记录中关于某个人住址的街道名称和门牌号码。比率R(γ)或它的任何单调函数(比如自然对数)为匹配权重。
(二)匹配错误率估计
在估计匹配错误率之前,首先需要利用全概率公式计算:
p(γ)=p(γ|M)p(M)+p(γ|U)p(U)
(2)
如果γ满足有条件的独立性假设,那么可以估计出属于M的概率p(γ|M),属于U的概率p(γ|U),以及比例p(M)。然后依据条件概率的计算公式可得匹配错误率:
(3)
对于潜在的类别而言,由于最大期望算法(EM)是一种无监督的学习方法,使用EM算法进行匹配的比例应该在5%以上[2]。不过匹配错误率估计程序可能只在两份文件中的名称、地址以及其他信息可以有效的汇集成对并精确地指定匹配时才能有效的运作。
三、贝叶斯记录链接方法
从统计方法的角度来说,两个或者两个以上的数据集的合并可以达到两个目的:一是为了获得一个更大的集成数据集;二是为了在附加信息的基础上执行后续的统计分析,该附加信息不能从两个数据集中的任何一个单独提取得到。第二种情形值得更加关注。
(一)贝叶斯记录链接技术
从贝叶斯统计推断视角对记录链接问题进行研究是当前国际研究的趋势,不仅理论成果丰富,应用效果也非常明显[3]。从统计推断角度分析,一个重要的原因是针对记录链接问题,贝叶斯统计推断思想具有一定的优势。记录链接问题的突出难点是链接结构的不确定性,此时以样本信息为主的经典频率统计方法就较难发挥作用,而具有较强适应性与灵活性的分层贝叶斯模型可以为链接模型估计过程中融入不可或缺的先验信息。因此,具有融合“先验信息”和“样本信息”进行稳健推断的贝叶斯方法成为解决记录链接问题的重要思想。
基于贝叶斯定理的记录链接方法,是通过蒙特卡洛马尔科夫(MCMC)模拟得到的后验分布推断匹配矩阵的相关参数,其重点在于从参数的联合后验分布获取模拟样本,以(γ,M,U;θ)表示,其中γ是匹配矩阵,M和U分别代表匹配组和不匹配组,θ代表模型中的参数向量。在数据整合过程中,首先对匹配矩阵γ进行点估计,然后用这个估计量来推断记录信息是否配对。值得注意的是,由于矩阵γ的特殊结构,没有显著的点估计值是有用的,因为需要对矩阵γ中的每一个元素γ(a,b)作出值为0或1的估计,γ的后验均值实质上是无效的。
如果将矩阵γ的联合后验分布中所体现的不确定性转移到后续的统计分析中,也就是说在确定信息匹配与否的过程中需要重点关注不确定性的影响,在一定程度上能够避免高估链接方法的精确度,这样对于不确定性的处理更为有效[4]。例如在匹配的过程中,首先需要考虑的是匹配向量γ的结果,而对于匹配结果是否确认为γ(a,b)值为0或1的估计需要依赖于文档A和B中详细记录信息的判别。也就是说,在联合后验分布(γ,M,U;θ)的推断过程中,不仅需要考虑记录链接过程中匹配向量γ(a,b)值为0或1,而且需要在所有参数的联合后验分布中提取一个样本,这两个因子都在MCMC算法中同时考虑,从而能够在产生后验样本的马尔科夫链中考虑到γ(a,b)和参数θ之间的信息反馈,体现出更加注重不确定性的影响。
(二)多元回归过程
根据上面论述的数据整合过程,下面建立多元回归框架。首先,设定一个与模型(1)相关的MCMC运算法则,也就是说,在每一次迭代时t=1,2,…,T,从它的完全条件分布中提取γt;然后,从完全条件分布中提取Mt,Ut;最后,从完全条件分布中提取θt。从回归的步骤中可以发现矩阵γ的边际后验分布将有可能受到θ信息的影响。在这个情况下θ的后验分布将对链接过程中涉及的不确定性作出解释。从理论角度上来说,该解释将所有变量和参数间的关系都潜在考虑在内,不确定性能够以一种正确的方式被解释。
矩阵γ的估计值不受模型中回归部分的影响。如果记录链接过程的主要目标是为了在附加信息的基础上执行后续的统计分析,整合记录在未来由于不同目的可以被重复使用,那么从计算的角度来看,由于在给定记录链接参数时,附加参数的完全条件分布必须派生出一个不同的统计模型,这样上述的多元回归框架就能够避免新参数的引进改变记录链接参数的完全条件分布[5]309-318。
四、分层贝叶斯记录链接的实现
下面将构建贝叶斯分层模型实现数据匹配,为了便于描述模型参数随行政记录变动而适时调整的情形,首先需要给出一对一匹配假定。
(一)一对一匹配限制

先验信息和数据通常可以从之前的记录链接操作中获得,模块的设定与行政记录的具体形式有关。例如在一些人口普查记录链接的应用中,模块通常以区域方式划分,模块的变动导致记录链接参数也产生显著变动[6]。当从两个记录文件中获得同一个人的记录信息进行匹配时,链接参数将出现跨区域一致的情形,从而可以判断两份记录是相匹配的。这种情形很有可能就是我们上述的同一个人的学习所在地和工作所在地有所不同。在分层模型中采用模块索引不同区域的做法,使得匹配概率的计算相比传统方法更为准确。就经验而言,完全一致的记录在匹配对中的概率高于不匹配对,而且单个字段完全一致的概率在匹配对中比非匹配对中更高:p(γ(a,b)=1|(a,b)∈M)>p(γ(a,b)=1|(a,b)∈U)。从逻辑上说,在模块s中匹配对的数量nms一定比文件A(nas)和B(bas)中记录的数量要低。所以,在模块s中出现一个匹配的概率PsM小于等于最小值除以匹配对的数量乘积nas×bas。这种限制条件可以帮助我们在后验分布模拟中有效地降低估计误差。
(二)分层贝叶斯记录链接模型
1.模型构建。在贝叶斯框架下,首先根据式(2)利用全概率公式计算p(γ),称为链接模型中的比较向量。分层模型需要在模块S=1,2,…,s中指定参数分布。下面以常见的贝塔分布作为先验信息,信息域一致的概率同样被允许随模块而变化:
psMk=p(γ(a,b)k=1|M,s)~beta(αsMk,βsMk)
(4)
并且
psUk=p(γ(a,b)k=1|U,s)~beta(αsUk,βsUk)
(5)
二者跨模块、域和类的情形下均相互独立。贝塔分布中参数的下标如sMk分别表示模块s、匹配组M和第k个匹配对。同时依据参数限制条件存在psMk≥psUk。分层分布是建立在参数贝塔分布的变形基础之上(贝塔分布的变形可详见Larsen, 2004),基本形式如下:
其中βsMk=eτsMkLogit-1(1-θsMk)。上面的限制并不意味着θsMk≥θsUk,而是仅约束参数psMk和αsM=eτsMLogit-1(θsM)。这也是使得先验分布同时需要满足θsMk≥θsUk这一约束条件。在模块s和psM中属于类别M的概率被赋予一个贝塔(αsM,βsM)先验分布。这一分层分布与其他分层是相互独立的:
同时psM要小于na和nb的较小值除以配对的数量。按照之前的设定αsM=eτsMLogit-1(θsM)以及βsM=eτsMLogit-1(θsM),如果没有满足上述的假定,较小的样本容量和跨模块较大的可变性将使得推断结果不够稳健。

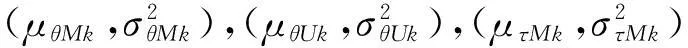

第四步,循环下面的步骤1至步骤3,直到推断值的分布收敛于目标后验分布。
1.对于S=1,2,…,s,在给定指标Is以及(αp,βp)值的条件下基于条件分布推断ps。具体而言,ps|Is,αp,βp~beta(αp+nms,βp+min(nas,nbs)-nms)。
2.对S=1,2,…,s和k=1,2,…,K,从其给出当前指标Is,模块s中的比较向量γs以及赋值(αsOk,βsOk),O∈(M,U)的条件分布中推断psMk和psUk。具体而言:
psMk|Is,γs,αsMk,βsMk~beta(αsMk+∑sIabγk(a,b),βsMk+∑sIab(1-γk(a,b)))
psUk|Is,γs,αsUk,βsUk~beta(αsUk+∑s(1-Iab)γk(a,b),βsUk+∑s(1-Iab)(1-γk(a,b)))
3.对于S=1,2,…,s,k=1,2,…,K,使用MH算法首先推断参数θsMk和τsMk的值,然后推断参数θsUk和τsUk的值,最后从其完全条件分布中推断Is和nms的值。
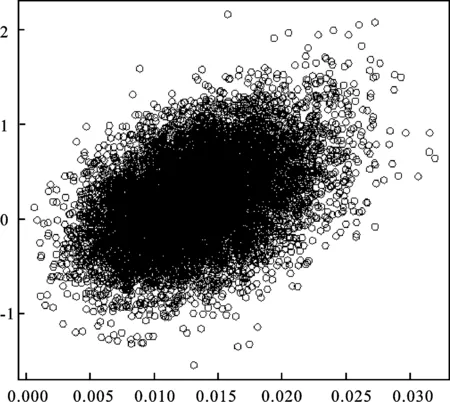
最后一步,确定算法停止与否。需要注意的是一对一限制是强加于矩阵I,在模块S=1,2,…,s中匹配类别的大小由nms≤min(nas,nbs)以及0 (三)在行政记录整合中的应用 为了说明上述方法的有效性,我们对现实中的一组行政记录进行整合分析。数据包括300个记录,基本信息包括姓名拼音,出生年、月、日。为了有效匹配,将记录信息分解为5个变量,姓名分开记录为姓和名的拼音,年、月、日分开记录。截取部分信息如表2。 表2 行政记录数据信息示例 1.数据整合的准备工作。行政记录整合的重要工作之一就是合并记录或者是删除重复数据。依据上述的贝叶斯记录链接方法,行政数据中配对的任一记录如果有缺失值,整合后的记录中都以无真实值“NA”表示。而整合模型中对这些“NA”值的处理方式都是默认为数值0,记录链接的结果用1表示记录匹配,0表示不匹配,比如表2中的记录1和记录2的链接结果为0。 当行政记录数据量庞大,或者关注记录信息中部分变量的时候,以采用分块的方法进行数据整合。比如表2中的数据,在我们进行数据整合的时候,假设第一步只关注生日是否相同。那么在进行匹配的时候,将比较对象限定为后面的三个变量:年、月、日。例如记录1和记录2的出生日期相同,那么在分块比较的时候,二者链接结果为1。 表3 匹配概率的频数分布表 根据设定的阈值0.6,最终匹配的个数为26个。接下来还需要根据贝叶斯链接方法中匹配错误率的计算检验数据整合效果。在贝叶斯框架下,根据模型(4)可以采用吉布斯抽样进行估计,过程简洁清晰,并且适用于计算任何精度的后验推断。图1给出了横轴为α和纵轴为β的10 000次模拟散点图,收敛效果明显,最后的估计值应该位于图中黑色区域的中心。 图1 后验分布模拟散点图 推断结果α=0.013,β=0。进而计算得到匹配的精度为0.998 4,就此数据来说,匹配错误率较低,整合效果理想。 五、结论与展望 贝叶斯记录链接方法能够有效利用分析人员的链接经验,尤其在行政记录整合的分层模型中,利用模块变动反映行政记录信息的来源变化,有助于提高匹配错误率的估计精度。此外,如果在似然函数中使用一对一匹配限制,可以采用MH算法模拟推断匹配状态指标,相比传统计算方法更易操作实现。将贝叶斯分层链接方法应用到人口普查及其他来源的行政记录数据中将极大地提高数据整合效率。在实际应用中,分析人员选取记录链接参数的先验分布时有多种选择,甚至可以使用实验数据不断调整先验分布。 最后要说明的是,与记录链接模型相关的两个扩展有待进一步研究。首先,可以考虑拓宽匹配变量比较的定义,面对行政记录的具体形式,今后需要允许将更详细的信息如家庭结构等变量作为比较指标;其次,放宽分层模型的限制条件,允许在一对一匹配限制之外的模块调整,使得分层模型能够更好地适应两个以上行政记录文件的匹配错误率估计。 参考文献: [1]Maria J,Sören E,Mats B.Testing Methods of Record Linkage on Swedish Censuses[J].Journal of Quantitative and Interdisciplinary History,2014(3). [2]Lahiri P,Larsen M D. Regression Analysis with Linked Data[J].Journal of the Acoustical Society,2005,100(1). [3]Tancredi A,Liseo B.A Hierarchical Bayesian Approach to Record Linkage and Population Size Estimation[J].Annals of Applied Statistics,2011(2). [4]许永洪.行政记录和政府统计的多视角研究[J].统计研究,2012(4). [5]Larsen M D. Record Linkage Using Finite Mixture Models[C]//Gelman A, Meng X L. Applied Bayesian Modeling and Causal Inference from Incomplete-Data Perspectives.New York:Wiley,2004. [6]胡桂华.人口普查覆盖误差估计方法综述[J].统计与信息论坛,2013,28(9). (责任编辑:李勤) 收稿日期:2015-11-18 基金项目:江西省高校人文社会科学重点研究基地项目《行政记录数据的开发及其在政府统计中的应用研究》(JD1412);教育部人文社会科学研究青年基金项目《信贷约束与学习行为交互作用下金融外部性对逆周期监管的影响研究》(15YJC630194);国家自然科学基金青年项目《逆周期资本监管框架下考虑跳跃行为的信用风险度量研究》(71401069) 作者简介:丁东洋,男,满族,辽宁抚顺人,经济学博士,副教授,研究方向:贝叶斯数据分析方法与风险管理技术; 中图分类号:O212.8∶C916.1 文献标志码:A 文章编号:1007-3116(2016)07-0030-06 Bayesian Hierarchical Record Linkage Model and Its Application in Administrative Records Integration DING Dong-yanga,b, ZHOU Li-lia (a. Center for Anti-Corruption Studies; b. School of Public Administration, Nanchang University, Nanchang 330031, China) Abstract:Technical issues about record linkage require a combination of statistical theory to resolve, especially in the establishment of record linkage classification rules, we need to build a statistical model to identify critical variables in order to complete the data match. Build hierarchical model to integrate administrative records under the Bayesian framework, can estimate matching error rate by multiple regression, and allows block to reflect the change of information sources under restriction of one to one integration, the posterior distribution calculated based MCMC simulation is convenient, help to improve the efficiency of data matching. Key words:record linkage; Bayesian methods; hierarchical model 周丽莉,女,江西临川人,经济学博士,副教授,研究方向:国际金融市场与风险管理方法。 【统计理论与方法】