
基于UML的软件规模度量
2016-11-14 02:05代余彪
中国科技信息 2016年21期
基于UML的软件规模度量

飞速发展的计算机技术使得计算机的应用领域迅速扩大,因此,在各具体应用领域内开发的软件系统越来越多,规模不断地增长, 复杂程度增大。分析、评估现有软件系统的可维护性、可靠性、可修改性和复杂性来降低后续类似系统的开发代价、提高软件系统的质量提供了依据, 软件度量是解决该问题的一种有效方法。
通过度量软件生命周期中各种不同的元素来衡量软件的规模,为项目管理者提供项目的各种重要信息,也给此后的评估活动的奠定了基础。功能点分析是一种通用的规模度量方法,但是其需要专业人员的操作,而且复杂度的等级划分是不连续的,这与实际的情况有较大的不同,因此,本文对其进行研究。
功能点分析及其问题分析
功能点分析
使用功能点分析度量软件的规模是按照功能特征来进行的,通过需求分析获得的系统功能及描述功能特征的用例图和时序图等来计算该系统的功能点即规模。主要通过外部应用接口和内部应用复杂度以及系统的总体性能特征来完成,由两个部分组成:即未调整的功能点数及加权因子。未调整的功能点对外部输入、外部输出、外部查询、内部逻辑文件和外部接口文件进行计数。在确定了它们的类型后,就要为其指定级别,事务功能类型(EI,EQ和 EO)的复杂度级别取决于被更新或引用的参考元素类型的个数以及数据元素类型的个数;ILF和EIF的级别取决于记录元素类型RET和数据元素类型DET的个数。各功能的复杂度等级及其权值的规定参照文献。
问题分析
功能点分析是一种通用的度量软件规模的方法,而且已经成为软件度量的标准,但是它仍然存在以下3个方面的问题,具体表现在:
1) 度量的复杂性
由于采用FPA进行规模度量的规则非常复杂,需要专业的人员进行评估;并且度量的规则是用简单的自然语言描述的,因此,度量结果很容易受度量者的主观影响;
2)复杂度分类存在模糊性
根据DET, RET和 FTR的复杂程度将5种功能元素归类为低,中和高,这样的复杂度划分容易实现,但是存在模糊性。例如:表1中的软件项目有2个ILF:ILF2和ILF3,他们都有2个RET,但是ILF2有50个DET, ILF3有20个DET。依据复杂性权重矩阵,它们具有相同的复杂度并且分配相同的权重值10,然而,ILF2比ILF3多了30个DET,应该更复杂。
3)复杂度分类存在不连续性
两种不同的复杂度分类的权重值是不连续的,即使他们仅有1DET的差别。表1中的软件项目有2个ILF:ILF1和ILF2,他们都有2个RET,但是ILF1有51个DET,ILF2有50个DET。依据复杂性权重矩阵,ILF1的复杂度为高分配权重值15,ILF2的复杂度为中分配权重值10,然而,ILF1仅比ILF2多了1个DET,权重值却多5。
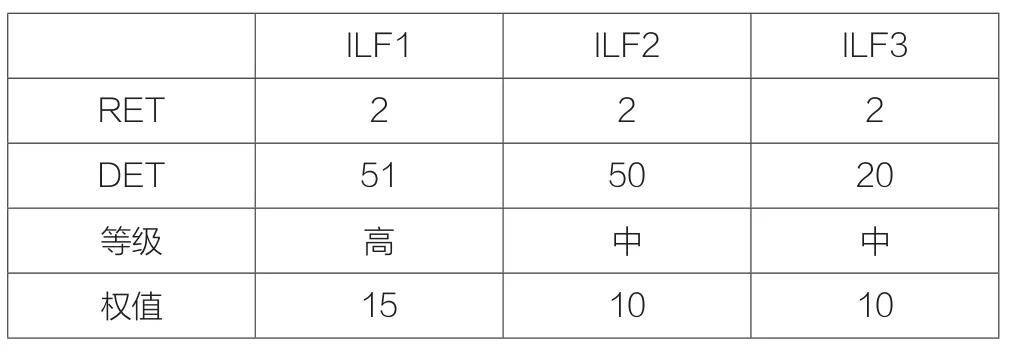
表1
为了解决问题1,本文采用UML来辅助评估过程,借助于系统分析中的类图来简化度量规则;采用边界模糊的的方法来解决问题2和3。
改进的功能点分析
UML是一种通用的分析设计方法,本文用类图来辅助进行功能规模的计算,功能点分析是一种广泛应用的软件规模度量方法,但是度量的结果容易受度量工作者的主观影响,导致不同的人对同一项目的规模度量可能有很大的产生较大的差距;而且度量过程需要专业的人员实施,代价较大;为了使规模度量简单易行,将需求的分析的结果作为度量的依据,并分析出规模与分析之间的度量规则,这样不仅不会增加太多的工作量,而且度量结果不受主观因素的影响。,所以,本文以此为基础进行规模度量。具体规则如下:
(1) 计算数据类型的功能点数
计算数据类型功能点主要通过实体类来计算,但并不是每一个实体类都算做一个文件。计算实体类为一个文件依据以下的规则进行:
1) 若该类与其它类仅存在关联关系不存在组成、聚集和继承关系,则记为一个文件;
2) 若该类与其它类存在组成关系,则表示整体的类计为一个文件,而每一个部分类分别看作为整体类的一个记录元素;
3) 若该类与其它类存在继承关系,且父类是抽象类,则父类计为子类的记录元素;
4)若该类与其它类存在继承关系,且父类是具体类,则父类计为一个文件,同时计为子类的一个记录元素。
(2)计算事务类型的功能点数
事务类型的复杂度由系统时序图中执行者与边界类和边界类与数据库文件之间的消息交互来计算。
(3)复杂度划分的处理
针对复杂度在划分上是分断的,不是连续的,若该结果在同一项目中出现,可能导致度量结果的不准确。本文采用一定的方法将不同复杂度的权值的边界进行模糊化解决该问题。下面以ILF的复杂度计算为例来说明这种方法。ILF的功能复杂度评价矩阵如表2所示,各复杂度等级对应的功能点数如表3所示。
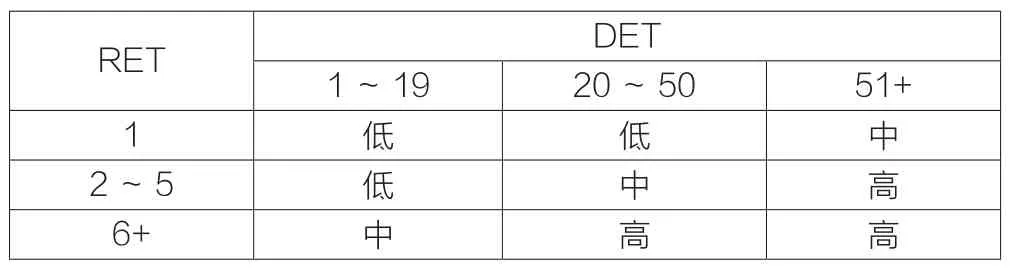
表2 ILF的功能复杂度评价矩阵

表3 复杂度等级对应的功能点数
从表中可以看出:影响复杂度等级的因素有RET和DET的数量,首先说明DET的变化对模糊化权值得影响,因为对于相同的RET,DET的数量越多说明越复杂,即功能点数随着DET的增加而增加,因此,将边界左右的5个DET进行模糊化,本文采用线性的方法实现模糊化。对RET对复杂度的影响,是用同样的方式进行,最后将所得的权值进行加权平均得到最终的功能点数。
根据该关系可计算出3个ILF文件对应的功能点数为:ILF1为10.75,ILF2为10.5, ILF3为8.5。
应用举例
医院管理系统的规模被计算采用本文的方法,在此以内部逻辑文件的功能点计算为例来说明改进的方法与原始方法的区别,计算结果如表4所示:
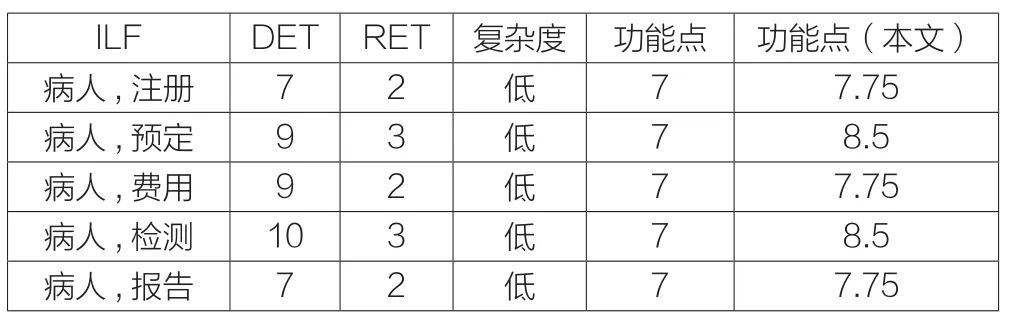
表4 内部逻辑文件的功能点
结语
为了解决传统FPA方法在计算过程中需要专业人员及工作量大的问题,提出了根据UML中的类图、时序图、用例图计算功能点的规则;同时,为了解决功能要素复杂度划分不连续的问题,提出了利用边界模糊化的方法来改进的复杂度权值计算方法。
10.3969/j.issn.1001- 8972.2016.21.023
猜你喜欢
厦门大学学报(自然科学版)(2022年4期)2022-07-15
上海文化(文化研究)(2022年3期)2022-06-28
现代装饰(2020年7期)2020-07-27
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
小学生导刊(低年级)(2016年11期)2016-11-14
商(2016年28期)2016-10-27
火控雷达技术(2016年1期)2016-02-06
数学大王·中高年级(2014年7期)2014-08-06
