
基于稀疏学习的kNN分类
2017-01-05 02:18龚永红文国秋程德波朱永华
广西师范大学学报(自然科学版) 2016年3期
宗 鸣,龚永红,文国秋,程德波,朱永华
(1.广西师范大学计算机科学与信息工程学院,广西桂林541004;2.广西区域多源信息集成与智能处理协同创新中心,广西贵港537000;3.桂林航天工业学院信息工程系,广西桂林541004;4.广西大学计算机与电子信息学院,广西南宁530004)
基于稀疏学习的kNN分类
宗 鸣1,2,龚永红3,文国秋1,程德波1,2,朱永华4
(1.广西师范大学计算机科学与信息工程学院,广西桂林541004;2.广西区域多源信息集成与智能处理协同创新中心,广西贵港537000;3.桂林航天工业学院信息工程系,广西桂林541004;4.广西大学计算机与电子信息学院,广西南宁530004)
在kNN算法分类问题中,k的取值一般是固定的,另外,训练样本中可能存在的噪声能影响分类结果。针对以上存在的两个问题,本文提出一种新的基于稀疏学习的kNN分类方法。本文用训练样本重构测试样本,其中,l1-范数导致的稀疏性用来对每个测试样本用不同数目的训练样本进行分类,这解决了kNN算法固定k值问题;l21-范数产生的整行稀疏用来去除噪声样本。在UCI数据集上进行实验,本文使用的新算法比原来的kNN分类算法能取得更好的分类效果。
稀疏学习;重构;l1-范数;l21-范数;噪声样本
0 引言
模式分类是人工智能和模式识别中的一个基本问题。其主要考虑的问题:给定N个已知类别的C类样本,对于任意给定的测试样本,如何确定其类别,从而完成模式分类。迄今为止,已有很多分类器被提出,其中最具代表性的是最近邻(NN)分类器,其将测试样本归为与其距离最近的样本所在的类[1]。kNN (k-Nearest Neighbor)算法是一种应用广泛的分类方法,它是最近邻算法的推广形式。kNN算法的核心思想:如果一个样本在特征空间中的k个最相似的样本中的大多数属于同一个类别,则该样本也属于这个类别。
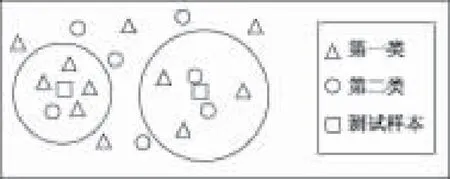
图1 二类分类问题,k=5时情形Fig.1 Binary classification with a fixedk value, i.e. k=5
本文发现传统的kNN算法每次都用同样k个数目的训练样本对测试样本进行分类,这在应用中通常不合实际。图1以二类问题为例,在kNN算法中,k固定取5,对于左边的测试样本分类,显然被分为第一类;对于右边的测试样本分类,其也被分为第一类;然而与其最邻近的两个训练样本都是属于第二类,此时由于k固定取5,将其分为第一类可能不合理,应将其分为第二类更准确,即此时k取2比较合理。因此,本文认为固定k对每一个测试样本不合理,k的取值应该由数据的分布决定,而且决定的方法不是人为设定,应是学习数据而得到的。此外,认为样本之间是存在相关性的,考虑样本间的相关性更能揭示数据特点,对于每个测试样本,应该用与之相关的训练样本对其进行分类。为此,本文用训练样本重构测试样本得到训练样本与测试样本之间的相关性关系,并用lasso(the least absolute shrinkage and selection operator)正则化因子产生稀疏性[2-4],实现对每个测试样本用经过稀疏选择的训练样本来对其进行分类,从而解决经典kNN算法中k值固定问题。另外,基于数据集中存在噪声数据[5]的可能性,本文通过l21-范数产生整行稀疏性,实现用经去除噪声的训练数据集对测试样本进行分类。因此,本文提出基于稀疏学习的kNN分类算法——kNN classification based on sparse learning ,简记为SL-kNN。该算法不仅考虑了样本之间的相关性,并利用稀疏学习实现训练样本子集选择,从而可以较好地解决kNN算法中k值固定问题和样本中含噪声问题。
1 基于稀疏学习的kNN分类
1.1 重构
本文假设有训练样本空间X∈Rn×d,n为训练样本数目,d为特征数目;测试样本空间Y∈Rm×d,m为测试样本数目,d为特征数目;投影矩阵W∈Rn×m。一般我们用线性模型拟合训练数据集,常用最小二乘法,即:
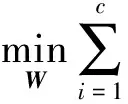
(1)
这里‖·‖F是Frobenius矩阵范数,yi∈Rd×1,wi是W的第i列向量。
所谓重构指的是用一组线性无关的向量的线性组合来近似地表达一个给定的向量[6-7],这里就是用训练样本重构测试样本,分类问题中yi一般为类标签,W表示类标签Y与训练特征X之间的函数关系。而在本文中yi表示第i个测试样本,经过重构过程得到的矩阵W表示训练样本X和测试样本Y之间的相关性,即相关系数。W中元素值wij表示第i个训练样本与第j个测试样本之间的相关性大小,wij>0时代表正相关,wij<0时代表负相关,wij=0时代表不相关;如果W中某列向量有r个元素值不为0,则分类时k应取r,并用对应的这r个训练样本来对相应的测试样本进行分类,对于其他测试样本,同理可得到各自的k值,这就解决了kNN算法中k值固定问题,但目标函数(1)得出的W不是稀疏的。
1.2 稀疏学习
我们通常用最小二乘损失函数来确定线性模型中的向量参数W,即:
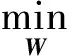
(2)
该损失函数是凸的,其解为W*=(XXT)-1XYT,但是其中的XXT不一定可逆,需要加上一正则化因子对其正则化以使XXT可逆。本文添加lasso解决此问题,同时lasso被证明能使结果W产生稀疏性,这称为元组稀疏(elementsparsity)[2,8-9],对每个测试样本稀疏选择相应的训练样本来进行分类,从而解决了上面提到的k值固定问题。另外,添加l21-范数用来使W产生整行的稀疏,即行稀疏(rowsparsity)[10],用来去除噪声样本。因此可以得到以下经过正则化的目标函数:
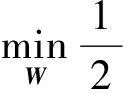
(3)
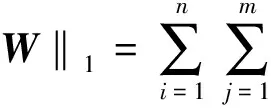
目标函数(3)可以求解,求出的W一般具有如下形式,简单举例:

W表示训练样本与测试样本之间的相关性,行代表训练样本,列代表测试样本。W第一列有3个值不为零,说明第一个测试样本和第一、三、五个训练样本相关,应该用这3个训练样本对第一个测试样本进行分类,即此时k=3。同理分别对第二、三个测试样本进行分类,得到相应的k=2、k=1,这里k的取值是通过lasso对训练样本稀疏选择得到的。另外W中第四行全为0,即出现整行稀疏性,这是l21-范数导致的结果,这意味着第四个训练样本与所有的测试样本都不相关,显然为噪声样本,在分类时予以去除。
目标函数(3)在重构过程中利用lasso稀疏学习出与每个测试样本相关的训练样本,即对每个测试样本用不同数目的训练样本进行分类,并且用l21-范数导致的整行稀疏性去除数据集中存在的噪声,有效解决了kNN算法中存在的k值固定问题和数据集中的噪声问题。
1.3SL-kNN算法
重构、lasso和l21-范数这三者被整合到一个函数里,成为了一个优化问题,即目标函数(3)。求解目标函数(3)可以从整体上得出一个最优解W,学习W的过程是由数据驱动的,因此能确保得到的关系最优,并且通过lasso使W具有稀疏性,从而使得每个测试样本需要的k值不同。l21-范数使W具有整行稀疏性,用来去除噪声样本,然后根据W的每一列取出与该测试样本相关的训练样本构造出分类器,最后对每个测试样本进行分类。上面的过程我们称为SL-kNN算法,下面我们给出具体的算法步骤,见算法1。
算法1SL-kNN算法。
输入:训练样本和测试样本;
输出:进行分类后的测试样本的类别;
1.将输入样本数据进行正规化;
2.根据算法2(下文给出)求解目标函数(3),得到最优解W;
3.根据W每列非零元素的个数得到每个测试样本的k值;
4.根据上面得到的k值,选出相应的这k个训练样本,并用这k个训练样本来对该测试样本进行分类;
5.根据这k个训练样本中的大多数属于同一个类别,则判定该测试样本也属于这个类别;
6.对所有的测试样本执行步骤4~5进行分类;
7.算法结束。
1.4 算法优化分析
目标函数(3)是凸的但非光滑的,本文通过设计一个新的加速近似梯度法来求解该函数,首先在目标函数(3)上进行近似梯度法,通过如下设置[12]:
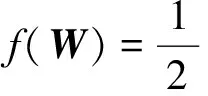
(4)
L(W)=f(W)+λ1‖W‖1+λ2‖W‖2,1,
(5)
注意到f(W)是凸且可微的,λ1‖W‖1和λ2‖W‖2,1是凸但非平滑的。使用近似梯度法优化W,通过下面的优化规则迭代地更新W:
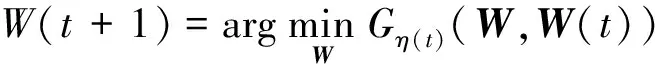
(6)
其中Gη(t)(W,W(t))=f(W(t))+〈‖‖W‖1+λ2‖W‖2,1,f(W(t))=XXTW(t)-XYT,η(t)和W(t)分别是调优参数和在第t次迭代获得的W值。
通过忽略公式(6)中独立的W,我们可以将其改写为:

(7)
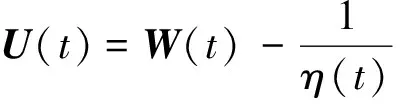
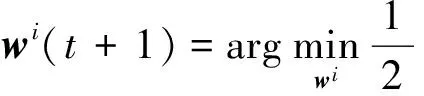
(8)
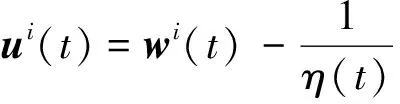
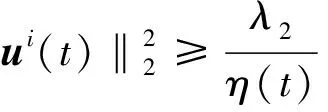
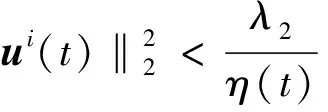
同时,为了加速公式(6)中的近似梯度法,本文进一步引进辅助变量V(t+1),即:
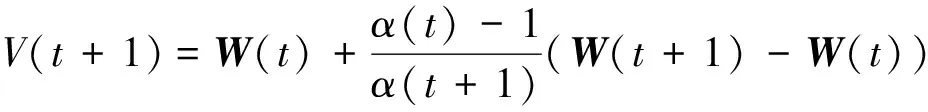
(9)
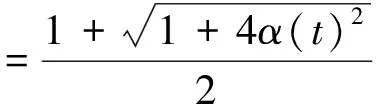
算法2中列出了优化算法的伪代码,并在定理1中说明了其收敛性。
算法2 解决公式(3)的伪代码。
输入:η(0),α(1)=1,γ;
输出:W
1 初始化t=1;
2 初始化W(1)为一个随机的对角矩阵;
3repeat
4whileL(W(t))>Gη(t-1)(πη(t-1)(W(t)),W(t))do
5Setη(t-1)=γη(t-1);
6end
7Setη(t)=η(t-1);
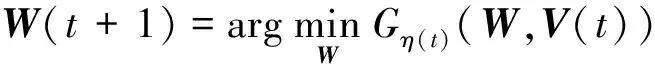
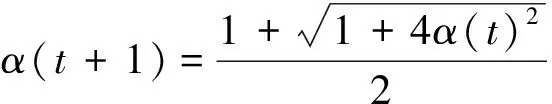
10 计算公式(9);
11until公式(3)收敛。
定理1 设{W(t)}是由算法2产生的序列,那么对于∀t≥1,式(10)成立:
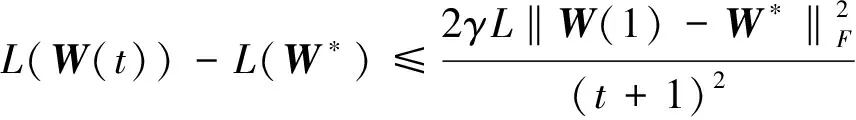
(10)
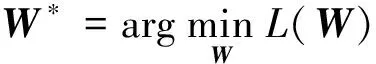
2 实验结果与分析
本文实验数据来自UCI机器学习库(http://archive.ics.uci.edu/~ml/),其中Fertility数据集、Blood Transfusion Service Center(简记BloodTrans)数据集、German Credit(简记German)数据集、Climate Model Simulation Crashes(简记Climate)数据集、Australian数据集和SPECTF Heart(简记SPECTF)数据集都是二类数据集,Seeds和Balance Scale(简记Balance)数据集为三类数据集,具体情况见表1。实验环境为Windows XP系统环境,实现算法的软件为Matlab7.11.0。
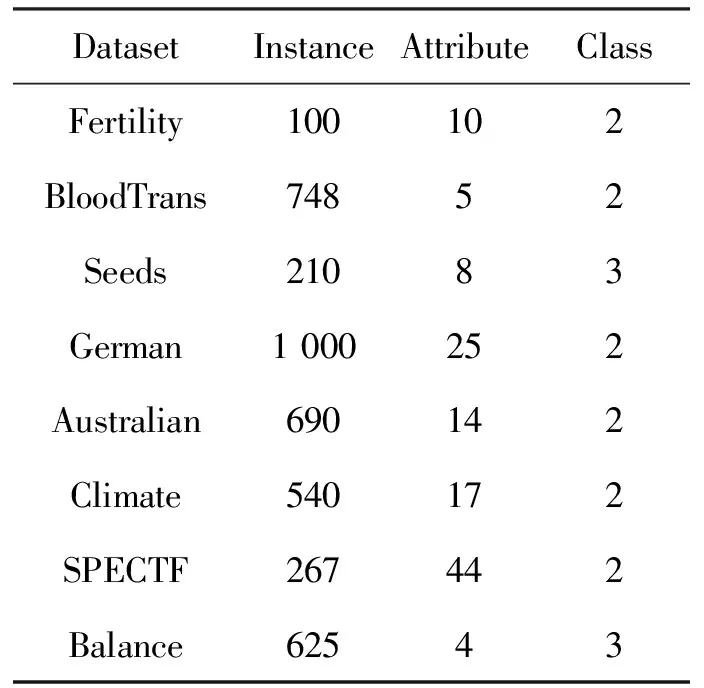
表1 UCI数据集基本情况
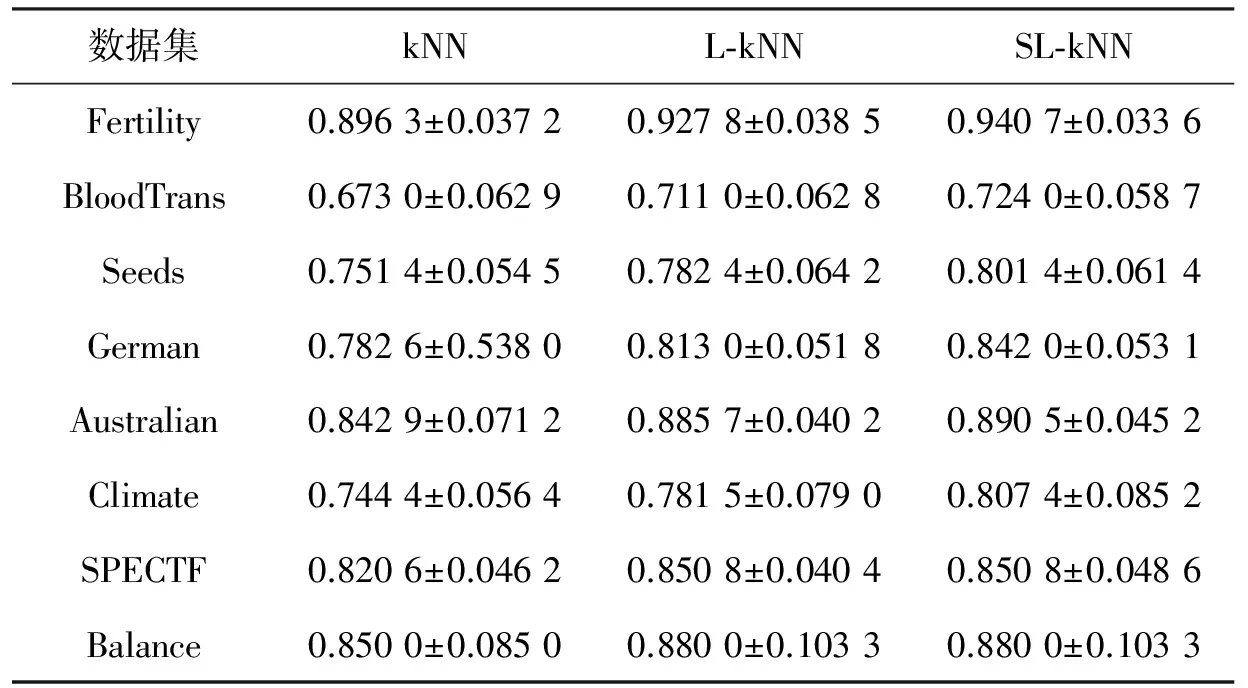
表2 两种算法在UCI数据集上的分类准确性(均值±方差)
在每个数据集上用十折交叉验证法[14]做10次实验看算法效果,主要的对比算法是kNN算法和L-kNN算法,其中kNN算法是一种经典的数据挖掘分类算法,而L-kNN算法是只考虑稀疏性(即只使用l1-范数)而没有考虑去除噪声样本的算法,即相比目标函数(3)没有考虑l21-范数正则化项。为了保证公平性,kNN算法、L-kNN算法和SL-kNN算法在每一次实验中选用相同的训练集和测试集,记录这两种算法10次实验取得的分类准确率。一般准确率越高,分类的准确性越好,否则,分类的准确性越低。kNN算法、L-kNN算法和SL-kNN算法在8个数据集上进行实验的分类准确性(Accuracy)结果的均值和方差如表2所示。
两种算法在数据集上10次实验的分类准确率结果如图2~9所示。
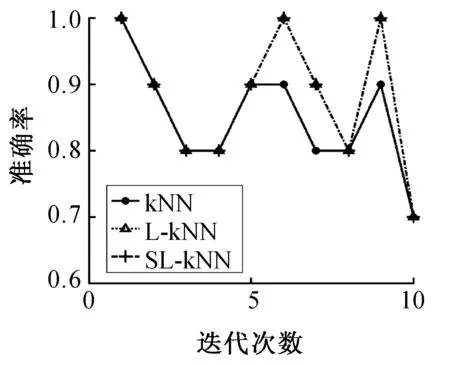
图2 FertilityFig.2 Fertility
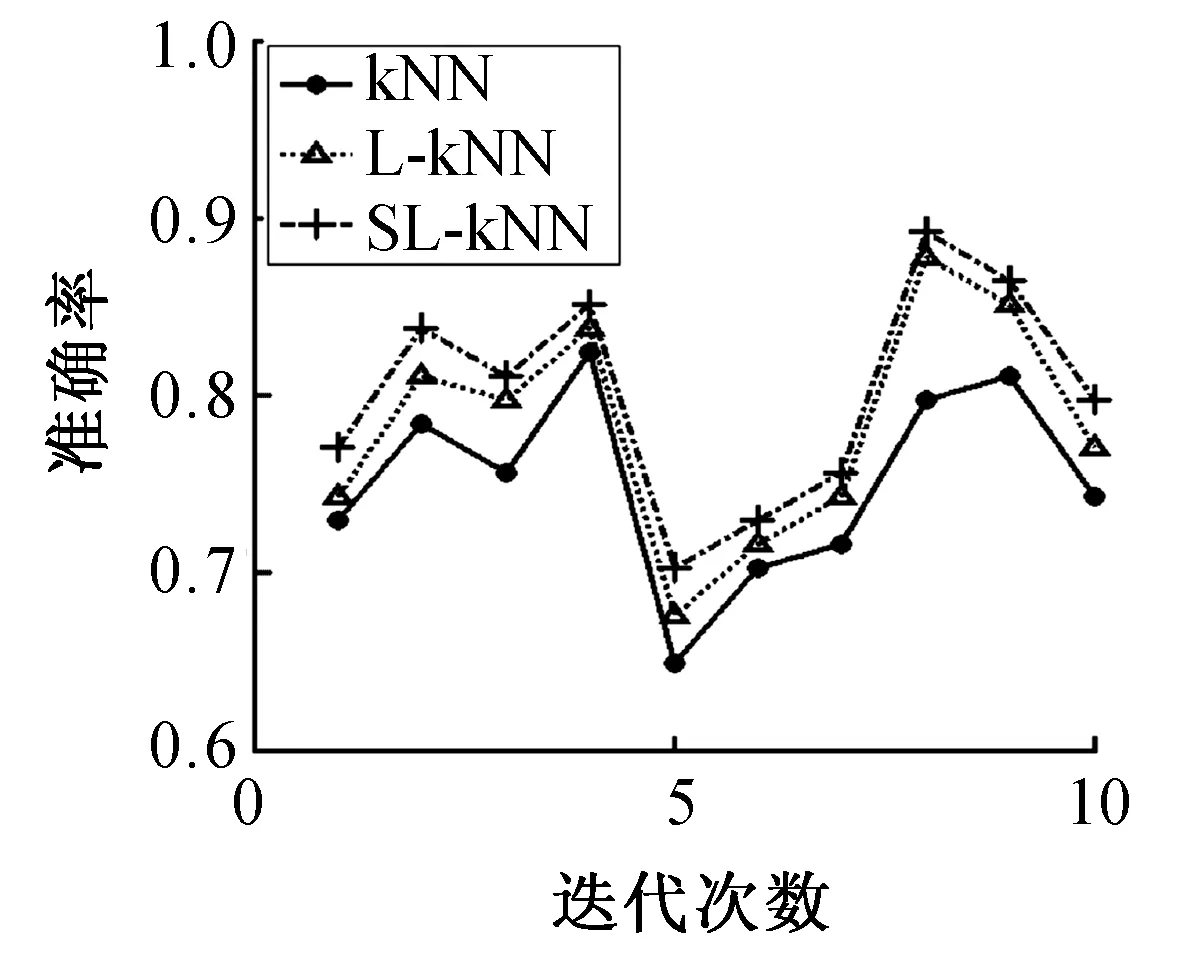
图3 BloodTransFig.3 BloodTrans
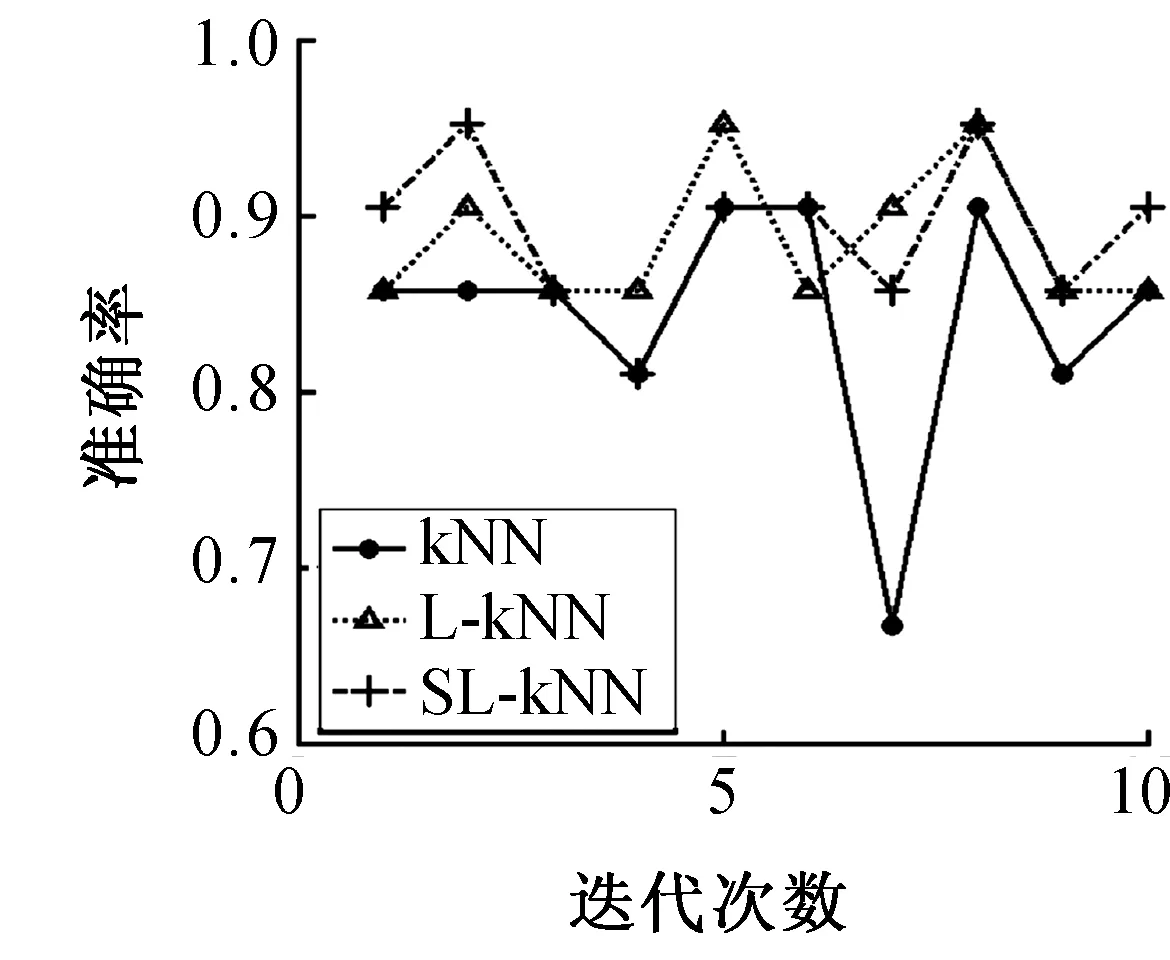
图4 SeedsFig.4 Seeds
分析表2可知,通过和kNN方法、L-kNN方法比较,本文提出的改进方法SL-kNN获得了最好的分类准确率。例如,SL-kNN算法的分类准确率在8个数据集上平均比kNN算法和L-kNN算法分别提高了4.69%和1.13%。另外,根据图2~9,我们也发现SL-kNN算法几乎在每一次实验中都有较高的分类准确率。
SL-kNN算法比L-kNN算法准确率高是因为使用了l21-范数消除噪声样本,例如,在Australian和Climate数据集上,该算法的分类准确率比L-kNN方法分别提高了2.9%和1.29%。这意味着Australian和Climate数据集可能含有噪声样本,进一步来说,Australian数据集可能有更多的噪声样本。综合来看,相比于kNN算法和L-kNN算法,SL-kNN算法具有更好的分类效果,对噪声的鲁棒性也更强。

图5 GermanFig.5 German
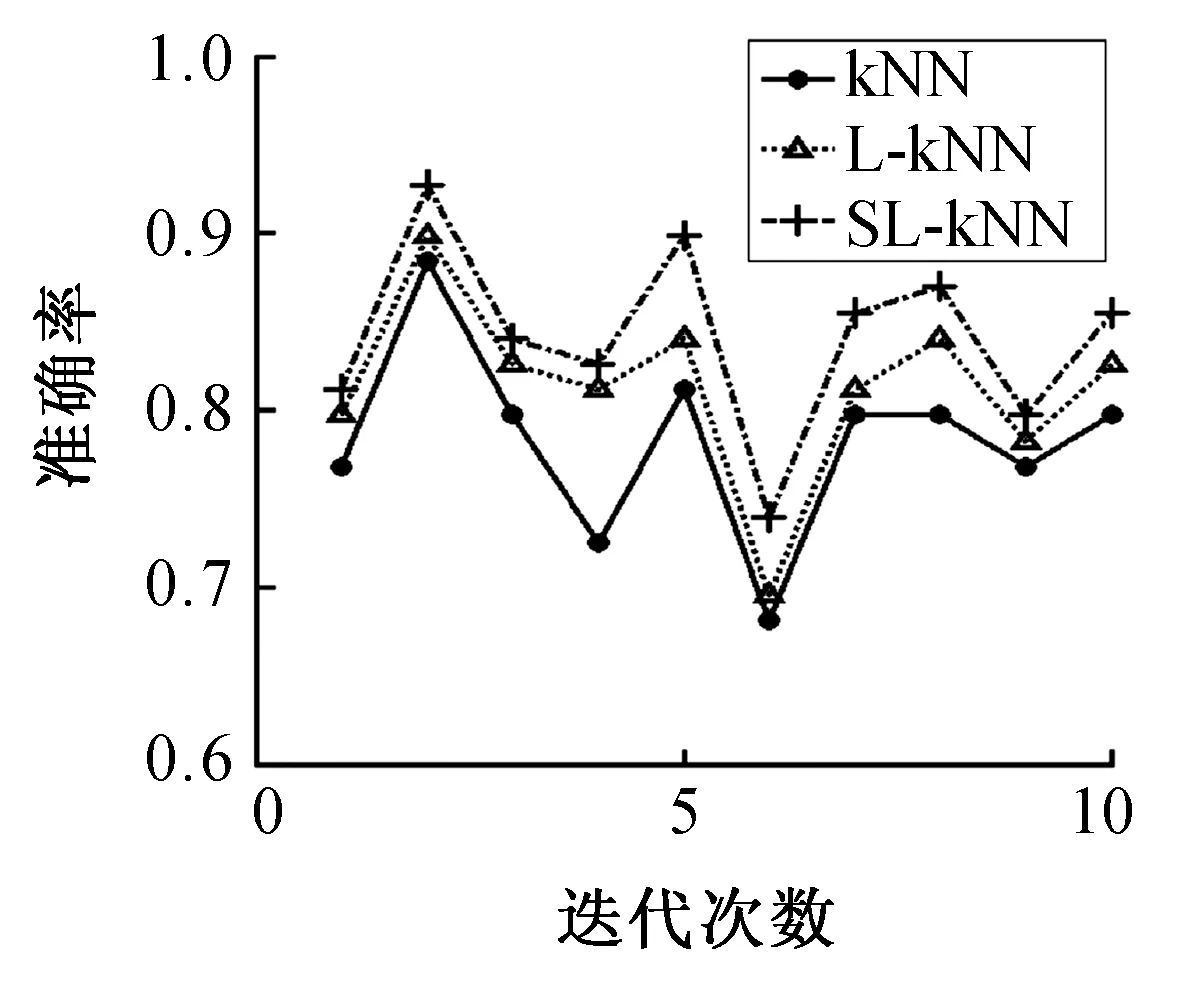
图6 AustralianFig.6 Australian
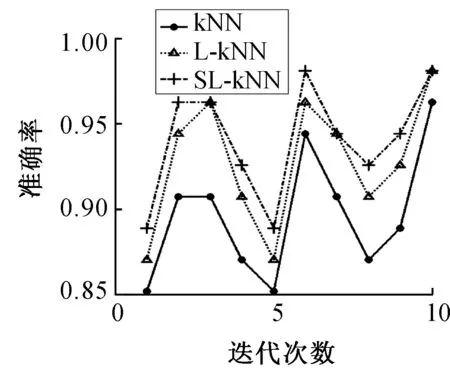
图7 ClimateFig.7 Climate
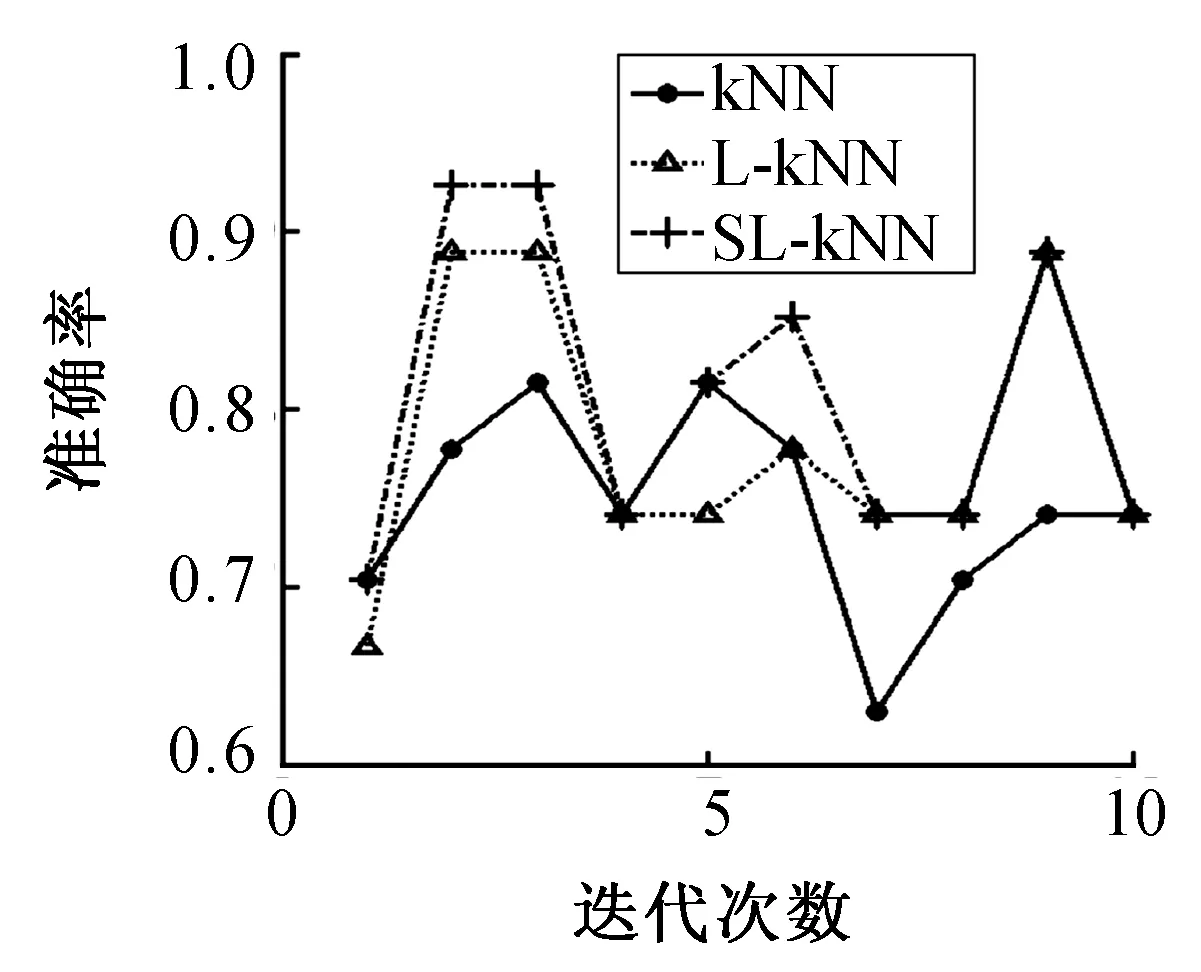
图8 SPECTFFig.8 SPECTF

图9 BalanceFig.9 Balance
3 结束语
本文针对kNN算法在分类问题中遇到的两个问题,即k值固定不变问题和如何去除噪声样本问题,提出了一种新的基于稀疏学习的kNN分类算法(SL-kNN),用重构获得测试样本与训练样本之间的相关性,用lasso产生样本间相关系数的稀疏性,用l21-范数去除训练数据集中的噪声。在UCI数据集上进行的实验结果表明,SL-kNN算法比kNN算法取得更高的分类准确率,对噪声的鲁棒性更优。
[1] QIN Yongsong, ZHANG Shichao, ZHU Xiaofeng, et al. Semi-parametric optimization for missing data imputation[J]. Applied Intelligence, 2007,27(1):79-88. DOI: 10.1007/s10489-006-0032-0.
[2] ZHU Xiaofeng,HUANG Zi,CHENG Hong,et al.Sparse hashing for fast multimedia search[J].ACM Transactions on Information Systems,2013,31(2):9. DOI: 10.1145/2457465.2457469.
[3] ZHU Xiaofeng, LI Xuelong, ZHANG Shichao. Block-row sparse multiview multilabel learning for image classification [J].IEEE Transactions on Cybernetics, 2016, 46(2):450-461. DOI:10.1109/TCYB.2015.2403356.
[4] ZHU Xiaofeng, ZHANG Lei, HUANG Zi. A sparse embedding and least variance encoding approach to hashing [J].IEEE Transactions on Image Processing, 2014, 23(9):3737-3750. DOI:10.1109/TIP.2014.2332764.
[5] LIU Huawen,ZHANG Shichao.Noisy data elimination using mutual k-nearest neighbor for classification mining[J].Journal of Systems and Software,2012,85(5):1067-1074. DOI:10.1016/j.jss.2011.12.019.
[6] ZHU Xiaofeng,HUANG Zi,SHEN Hengtao,et al.Linear cross-modal hashing for efficient multimedia search[C]//Proceedings of the 21st ACM International Conference on Multimedia. New York: ACM Press, 2013: 143-152. DOI:10.1145/2502081.2502107.
[7] ZHU Xiaofeng,HUANG Zi,SHEN Hengtao,et al.Dimensionality reduction by mixed kernel canonical correlation analysis [J]. Pattern Recognition,2012, 45(8):3003-3016. DOI:10.1016/j.patcog.2012.02.007.
[8] HASTIE T,TIBSHIRANI R,FRIEDMAN J.统计学习基础:数据挖掘、推理与预测[M].范明,柴玉梅,咎红英,译.北京:电子工业出版社,2003:7-8.
[9] ZHU Xiaofeng,SUK H,SHEN D G.Matrix-similarity based loss function and feature selection for Alzheimer’s disease diagnosis[C]//Proceeding of IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos, CA:IEEE Computer Society,2014:3089-3096. DOI:10.1109/CVPR.2014.395.
[10] ZHU Xiaofeng,HUANG Zi,YANG Yang,et al.Self-taught dimensionality reduction on the high-dimensional small-sized data[J]. Pattern Recognition,2013,46(1):215-229. DOI:10.1016/j.patcog.2012.07.018.
[11] ZHU Xiaofeng, ZHANG Shichao, JIN Zhi,et al. Missing value estimation for mixed-attribute data sets[J]. IEEE Transactions on Knowledge and Data Engineering,2011, 23(1):110-121. DOI:10.1109/TKDE.2010.99.
[12] ZHU Xiaofeng,HUANG Zi,CUI Jiangtao,et al. Video-to-shot tag propagation by graph sparse group lasso[J]. IEEE Transactions on Multimedia,2013,15(3):633-646. DOI:10.1109/TMM.2012.2233723.
[13] NESTEROV Y.Introductory lectures on convex optimization: A basic course[M]. Berlin: Springer, 2004.
[14] ZHU Xiaofeng, LI Xuelong, ZHANG Shichao,et al.Robust joint graph sparse coding for unsupervised spectral feature selection [J].IEEE Transactions on neural networks and learning systems, 2016, PP(99):1-13. DOI:10.1109/TNNLS. 2016.2521602.
(责任编辑 黄 勇)
kNN Classification Based on Sparse Learning
ZONG Ming1,2,GONG Yonghong3,WEN Guoqiu1,CHENG Debo1,2,ZHU Yonghua4
(1.College of Computer Science and Information Technology,Guangxi Normal University,Guilin Guangxi 541004,China; 2.Guangxi Collaborative Innovation Center of Multi-source Information Integration and Intelligent Processing, Guigang Guangxi 537000,China;3.Department of Information Engineering,Guilin University of Aerospace Technology, Guilin Guangxi 541004,China; 4.School of Computer,Electronics and Information, Guangxi University, Nanning Guangxi 530004,China)
The value ofkis usually fixed in the issue ofkNearest Neighbors (kNN) classification. In addition, there may be noise in train samples which affect the results of classification. To solve these two problems, a sparse-basedkNearest Neighbors (kNN) classification method is proposed in this paper. Specifically, the proposed method reconstructs each test sample by the training data. During the reconstruction process,l1-norm is used to generate the sparsity and differentkvalues are used for different test samples, which solves the issue of fixed value ofk. Andl21-norm is used to generate row sparsity which can remove noisy training samples. The experimental results on UCI datasets show that the proposed method outperforms the existing kNN classification method in terms of classification performance.
sparse learning;reconstruction;l1-norm;l21-norm;noise sample
10.16088/j.issn.1001-6600.2016.03.006
2015-09-09
国家自然科学基金资助项目(61450001,61263035,61573270);国家973计划项目(2013CB329404);中国博士后科学基金资助项目(2015M570837);广西自然科学基金资助项目(2012GXNSFGA060004,2015GXNSFCB139011,2015GXNSFAA139306)
文国秋(1987—),女,广西桂林人,广西师范大学讲师。E-mail:wenguoqiu2008@163.com;龚永红(1970—),女,广西永福人,桂林航天工业学院副教授。E-mail:zysjd2015@163.com
TP181
A
1001-6600(2016)03-0039-07
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
安阳工学院学报(2020年4期)2020-09-11
科技创新与应用(2020年6期)2020-02-29
知识经济·中国直销(2018年12期)2018-12-29
中国校外教育(下旬)(2017年8期)2017-10-30
商周刊(2017年6期)2017-08-22
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
自动化学报(2016年3期)2016-08-23
