
数据库系统中应用A*算法的程序模板研究
2017-03-28 01:55林峰郑爱媛
福建商学院学报 2017年1期
林峰,郑爱媛
(福建商学院 信息管理工程系,福建 福州,350012)
数据库系统中应用A*算法的程序模板研究
林峰,郑爱媛
(福建商学院 信息管理工程系,福建 福州,350012)
数据库系统已经获得了广泛的应用,借助它能处理现实生活中许多复杂的事务性的数据工作,A*算法也有许多成功的应用,但是,对结合利用数据库技术与A*算法来解决实际问题的探索做得还很不够。A*算法的搜索空间大,往往需要花费几十分钟甚至更长的时间才能搜索到问题的解,因此,采用A*算法的数据库系统可能由于等待执行结果的时间太长而不适合实际需要。针对这些不足,设计了一套在数据库系统中应用A*算法的程序模板,套用这个模板开发的自动排课系统能够在很短的时间内处理好一个典型的中学排课工作,满足实际需求。结果表明,该程序模板具有指导性价值。
A*算法;次级启发函数;数据库技术;自动排课
A*算法是人工智能领域中最重要的算法之一,它的经典应用是解决数码问题[1]。目前,A*算法主要用于解决路径规划问题[2],在电子游戏和无人机飞行控制等领域都有很多应用[3-4]。A*算法取得如此大的成功,使得研究利用A*算法来解决现实生活中其他问题的工作变得很有必要。A*算法是状态空间图中的启发式搜索方法,状态空间图中的节点就是状态。在计算机应用程序中,状态由数据构成。在数码问题或路径规划等问题中,构成状态的数据很简单,一般用二维或三维数组来表示。因此,在应用程序的运行期间,这些数据可以一直保持在内存中,应用程序的运行速度较快,等待输出结果的时间较短。现实生活中的其他问题需要处理的数据可能很复杂,数据量也很大,这些问题一般要借助于数据库系统来实现。数据库系统中对数据的访问和操作都要涉及到物理层面的读写过程,并且所有的数据不能同时保持在内存中,因此,利用A*算法的数据库系统的应用程序的运行速度很慢,需要花费很长时间来等待输出结果,限制了这类应用程序的推广和应用。
利用A*算法的数据库系统把状态保存在数据库表中,每一个状态都是由多条记录组成的。这样的系统在进行状态扩展时,以下两个环节影响了它的工作效率,造成等待运行结果的时间过长:(1)构造子状态的数据时,需要从父状态进行大量的数据拷贝,这需要进行大量的、重复的把数据插入到数据库表中的操作;(2)为了避免搜索过程陷入循环,如果扩展出来的新状态与任何已经存在的状态相同,那么必须抛弃这个新状态,这需要进行状态之间的比较,即把组成一个状态的多条记录与组成另一个状态的多条记录进行比较,会涉及到大量的、重复的对数据表的查询操作。
利用数据库技术与巧妙的设计,能够有效减少上述两个瓶颈环节造成的不利影响。针对第一个环节,本文提供了一个能在状态之间实现数据共享的设计方案,避免了数据拷贝过程。因为,父子状态之间绝大多的数据都是相同的,以8数码问题为例,不相同的数据只占全部数据的2/9。针对第二个环节,本文提供了一个利用状态特征值进行状态比较的设计方案,状态特征值是一个简短的字符串,它与状态一一对应,并且从状态中提取特征值的过程简单、容易实现。老状态的特征值存放在专门的数据库表中,把新状态的特征值作为SQL语言的select语句中的where子句的条件,就能够很容易实现新状态与老状态的比较。这两个设计方案具有普遍性,因此,可以作为程序模板来套用。
1.A*算法
图1是状态扩展的模型。算子表示动作,动作执行前后的环境称为状态。算子使状态发生变化,从执行前状态得到执行后状态,执行后状态称为执行前状态的子状态,这个过程称为状态扩展。特定的执行前状态可以通过不同的算子(参数)得到多个不同的执行后状态,所以,状态和子状态之间是1n的关系。连续多次的状态扩展,构成了一个有向图,即状态空间图,状态是图的节点,算子是图的边。

图1 状态扩展模型Fig.1 State-expansion model
A*算法是状态空间图中的启发式搜索方法。搜索的起始节点记为n0,搜索过程中的某个中间节点记为n,定义以下符号:
f (n) = g(n)+h(n):从n0经过n到达目标节点的最小路径的代价;
g(n):从n0到n的一个最小代价路径的代价;
h(n):n到目标节点最小代价路径的实际代价。
在n处,有多条可以选择的搜索路径,与之对应的有一系列 f (n),选择 f (n)值最小的路径进行搜索,就最有可能以最少的代价得到问题的解。这个搜索过程称为启发式搜索, f (n)称为启发函数。A*算法的具体步骤:
1)生成一个只包含开始节点n0的搜索图G,把n0放在一个叫OPEN的列表上;
2)生成一个列表CLOSED,它的初始值为空;
3)如果OPEN为空,则失败退出;
4)选择OPEN上的第一个节点,把它从OPEN中移入CLOSED,称该节点为n;
5)如果n是目标节点,顺着G中从n到n0的指针找到一条路径,获得解,成功退出;
6)扩展节点n,生成其后继节点集M。丢弃M中与G中任何一个节点值相同的成员,把M中其余的成员添加到G中,使它们成为n的后继;
7)把新加入G中的节点加入到OPEN中,对M的每一个已在OPEN中或CLOSED中的成员m,如果到目前为止到达m的最好路径通过n,就把它的指针指向n。对已在CLOSED中的M的每一个成员,重定向它在G中的每一个后继,以使它们顺着到目前为止发现的最好路径指向它们的祖先;
8)根据 f (n)值,以从小到大的顺序重新安排OPEN中节点的顺序;
9)返回第3步。
2.实现数据共享的程序模板
在状态之间实现数据共享的目的是:(1)子状态能最大限度地重用祖先状态的数据;(2)在扩展子状态时,通过采用尽量少的补偿操作使其他状态的数据不会发生改变。采用3个方法来实现这个目的。
(1)有效组织状态的数据。按照下列的公式对状态的数据进行有效的组织:
状态的数据=往祖先路径上每一个状态的重用数据+本状态的专用数据
所有状态的数据保存在名字为tblData数据库表中(根据具体情况,状态数据也可以保存在多个数据库表中),每一个状态由若干条记录组成。在tblData中添加名字为stateId和stateId0的两个字段,它们的数据类型都为整型,其中stateId用来标识记录所属的状态。利用stateId和stateId0字段值的组合(必有一个字段值为-1,另一个字段值为状态号n)把tblData表中记录的分为重用和专用两种:
·重用的记录:stateId=n并且stateId0=-1,这些记录可以被子孙状态共享;
·专用的记录:stateId=-1并且stateId0=n,这些记录只能被状态自身使用。
初始状态的所有记录都被初始化为stateId=0,stateId0=-1。
图2是一个状态空间图,图中的节点等同于状态。从初始状态S0依次扩展出子状态S1、S2、…、S10,从状态S1依次扩展出子状态S11、S12、…、S16,从状态S12依次扩展出子状态S20、S21、…、S28,等等。
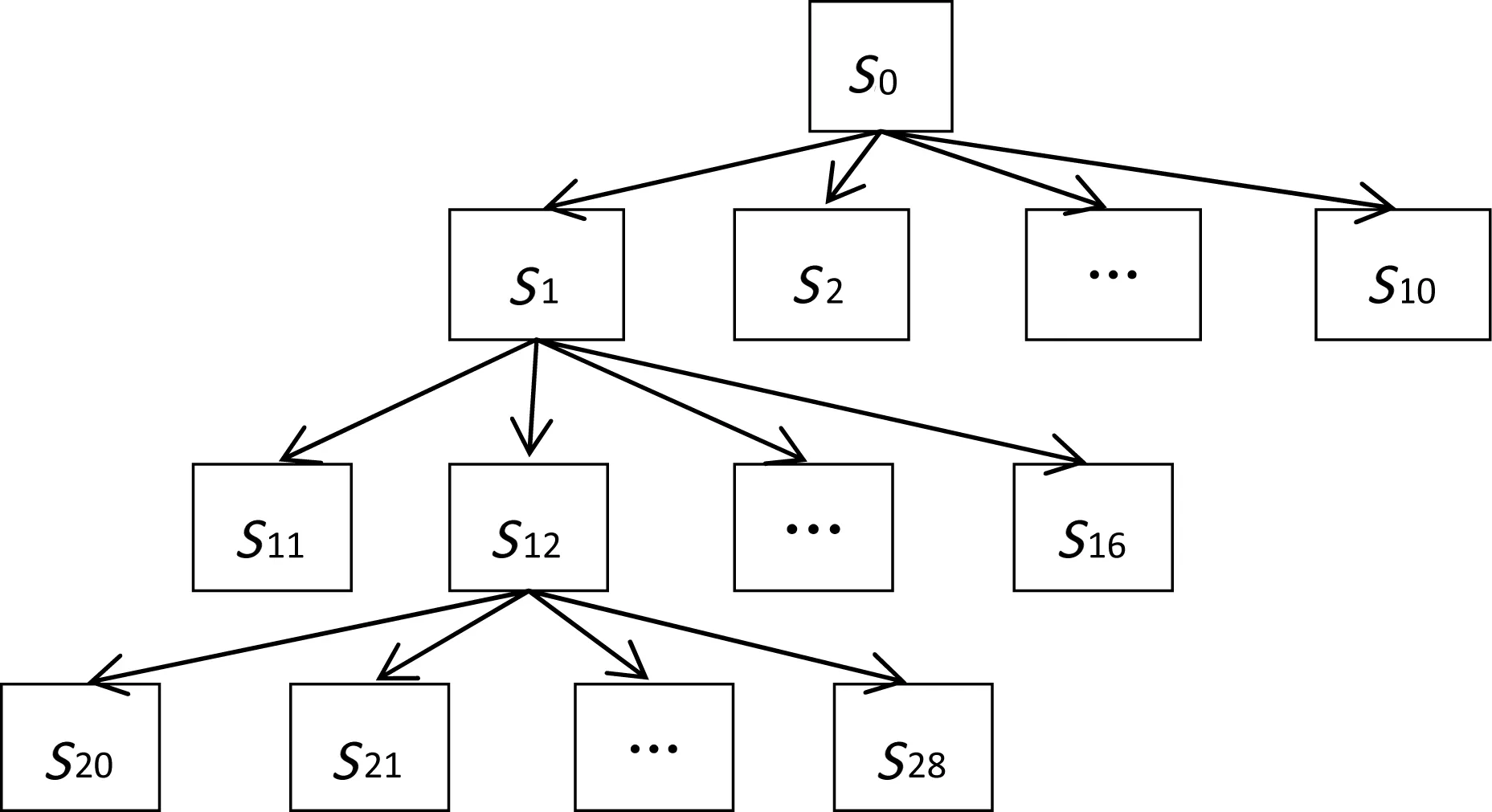
图2 状态空间图Fig.2 State-space graph
按照上述公式,读取任意状态数据的SQL语言的select语句(仅列出where子句):
S0:where (stateId=0 and stateId0=-1) or (stateId =-1 and stateId0=0)
S2:where(stateId=0 and stateId0=-1) or (stateId=2 and (stateId0=-1) or (stateId=-1 and stateId0=2)
S16:where (stateId=0 and stateId0=-1) or (stateId=1 and stateId0=-1) or (stateId=16 and stateId0=-1) or (stateId =-1 and stateId0=16)
(2)对受影响状态进行数据补偿。在扩展状态的过程中,祖先状态的数据可能会被改变,这会影响到包括该祖先状态在内的其他状态的数据。因此,采用delete取代update来改变祖先状态的数据,采用insert对受到影响的状态进行数据补偿。以S21为例,其祖先状态依次是S12、S1和S0。假设在扩展出S21时,删除了S0中的某条记录(stateId=0,stateId0=-1),那么必须按表1中列出的情况对受影响的状态进行补偿。

表1 补偿方法
需要补偿的状态分为一类状态和二类状态。一类状态是当前状态S21的祖先,对它们的补偿不能被当前状态S21重用。结合上述列出的SQL语句,可以看出,扩展S21前后,其他状态的数据都保持不变。
进行数据补偿的关键点是:(1)确定需要补偿的状态;(2)对它们进行分类。假设,新扩展出的状态为S_n,被改变数据的祖先状态为S_0。参考图2中的方位,S_n处于下方,S_0处于上方。程序模板的伪代码如下:
Being
按S_0到S_n的路径,提取节点,存放到list中;
For i=0 to n-2 Do
Begin
提取list[i]的直接孩子节点,存放到list_c中;
For each chlidNode in list_c Do
Begin
If chlidNode属于list Then
chlidNode是一类节点
else
chlidNode是二类节点;
End;
End;
End。
(3)重构初始状态。随着状态扩展的不断进行,一方面,状态空间图(实际上是一棵树)的层次不断增加,需要进行补偿的状态的数量会急剧增加,大量的补偿操作造成系统的运行速度变慢;另一方面,读取状态数据的SQL语言中的select语句的where子句中的or运算符的数量也会急剧增加,最终将会超过数据库系统的限制,造成系统异常。因此,必须在适当的情况下,选择某个比较好的状态(可以是最接近目标的状态)进行重构,即抛弃其他所有的状态,把选中的状态作为执行新一轮A*算法的初始状态。
3.利用特征值进行状态比较的程序模板
综合A*算法的其他要点,设计tblAStar数据库表,如表2所示。

表2 tbl AStar
程序模板的伪代码如下:
Begin
把tblAStar表清空;
扩展子状态,存放到list中;
For each子状态in list Do
Begin
val_stateStr = 子状态特征值;
执行select count(*) from tblAStar where state Str = val_stateStr;
If 返回值为0 Then
把val_stateStr插入talAStar中
Else
抛弃子状态;
End;
End。
每一个状态都是由数量相同的记录的数据集组成,对两个状态进行比较涉及这两组数据集的比较运算,并且需要依次读取每一个被比较的状态的数据,这非常耗费计算机系统的资源。按照这个程序模板来开发程序,完全避免了上述缺点,取而代之的是简单的提取状态特征值的运算和一个高效的SQL语句的执行运算,大大提高了应用程序的工作效率。新扩展出来的有效的状态也被不断地添加到tblAStar表中,为随后的扩展所需要进行的状态比较操作准备好了数据。
4.程序模板的应用实例——中小学排课系统
由于约束条件非常苛刻,全部合理地安排好学校的课程表是一个非常困难并且耗时的工作。目前,在排课工作中,计算机排课软件一般只起辅助作用,大部分工作都由人工完成。开发能够完全自动排课的应用软件很有必要。自动排课应用软件属于数据库系统软件。以下介绍套用这两个程序模板开发自动排课系统的几个技术要点。
(1)排课工作的切入点和数据前处理。中小学的课程表是一种二维表,由星期一到星期五组成课程表的列,由第1节到第8节组成课程表的行。用wd表示行,用ln表示列,用wlCell表示课程表中的某一节课。表3是某个老师课程表的一个样例。
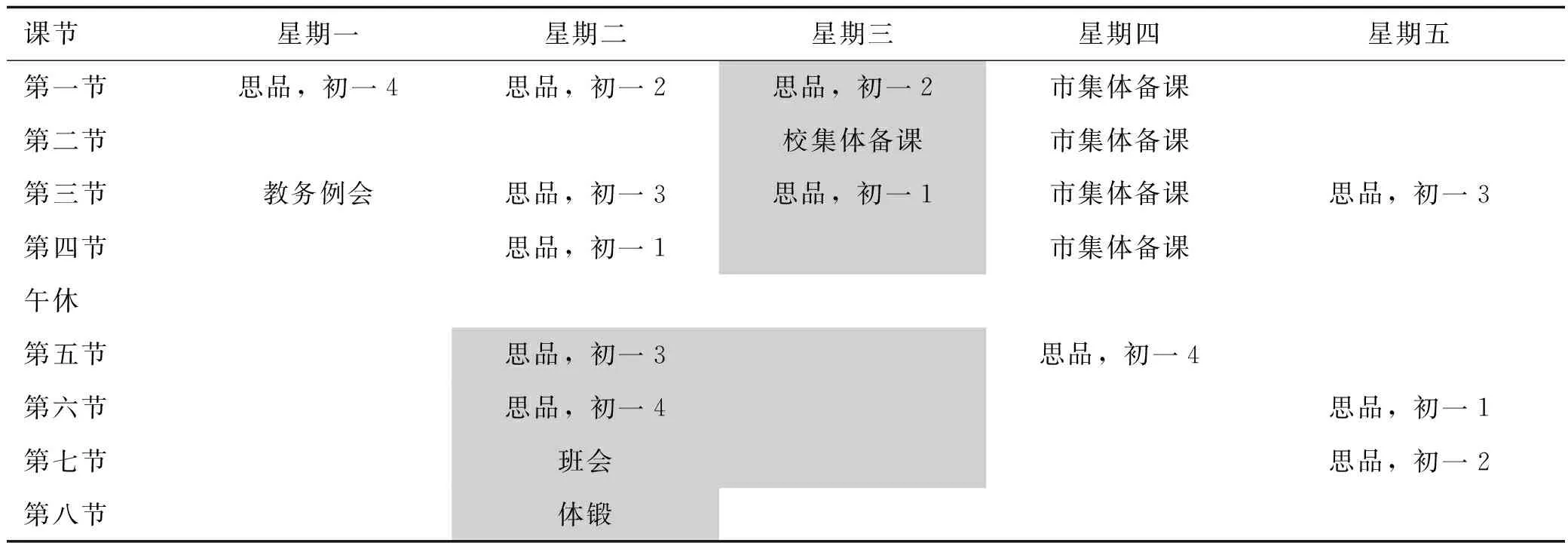
表3 某个老师的课程表
中小学的特点是:学生固定在班级中上课;每一节课占用的时间段是固定的;每一节课在特定的教室上课;班级的每一门课程由固定的老师任课;每一个任课老师可以负责多个班级。综合上述因素,得出结论:首先,中小学的课程表问题是由学生、任课老师和教室这三个资源共同约束的同时段任务安排问题;其次,任课老师、课程、班级(学生)和教室的组合数据是排课工作的切入点。为了保证教学进程同步,必须按照轮次安排任课老师的课程,即合理地平摊每个轮次的wlCell空间,把任课老师每个轮次所有班级的课程都安排在这个空间之中。把任课老师、课程、班级和排课轮次绑定在一起的数据称为teacher-topic-class-classroom-turnNo数据,简称ttcct。一个ttcct代表一节待安排的课。合理地分派ttcct的wlCell空间是实现同步教学的保证。图3是为ttcct分派wlCell空间的一种方案,其中turnNo表示排课轮次,与ttcct相关的课程每周上3次课[5]。

图3 分派ttcct的wlCell空间的一种方案Fig.3 An example of assigning wlCell to ttcct
如果wlCell被教师的其他活动(“教务例会”“市集体备课”“校集体备课”等)占用,或者被班级的固定课(“班会”“体锻”等)占用,或者处于限制排课的范围之内(例如,某些课不能排在上午的第1节,等等),那么根据排课的资源约束条件,该wlCell是不可排课的。因此,ttcct的wlCell空间分为可排课和不可排课两部分,可排课的wlCell数量与全体的wlCell数量的比值称为排课容易度,记为ISRatio,它的取值范围是0%~100%,值越大,越容易安排。如果ISRatio等于0,意味着ttcct没有地方安排,排课失败。ttcct是静态数据,可以预先处理好,需要时查表获取。
从软件设计的角度,把排课的任务归结为以下3个步骤:
1)构造全校的每一节课对应的ttcct;
2)按照保证教学进程同步的要求,确定每个ttcct的可排课的wlCell空间;
3)利用A*算法,解决排课资源冲突,把ttcct安排到某个可以排课的wlCell中。
(2)状态与扩展。全校的ttcct可以分为已经排入课程表和未排入课程表两个部分。已经排入课程表的记为ttcctwl,未安排入课程表中的还是记为ttcct。把它们分别放在名为tblData_ttcctwl和tblData_ttcct的两个数据库表中。因此,每一个状态的数据同时存放在tblData_ttcctwl表和tblData_ttcct表中。初始状态是,tblData_ttcctwl表中的记录数为0,所有的ttcct都在tblData_ttcct表中;目标状态是,tblData_ttcct表中的记录数为0,所有的ttcct都在tblData_ttcctwl表中。
自动排课系统的基本动作是,从tblData_ttcct表中提取一个ttcct,依次与ttcct的每一个可排课的wlCell结合成ttcctwl,并把它放入tblData_ttcctwl表中。实现这个过程的前提是必须满足排课资源约束条件。所以,执行基本动作之前,必须根据具体情况,执行以下3个辅助动作:
·如果ttcct对应的班级在wlCell已经排课,那么,要预先将ttcctwl_c从tblData_ttcctwl表中删除,将ttcctwl_c对应的ttcct加入到tblData_ttcct表中;
·如果ttcct对应的老师在wlCell已经排课,那么,要预先将ttcctwl_t从tblData_ttcctwl表中删除,将ttcctwl_t对应的ttcct加入到tblData_ttcct表中;
·如果ttcct对应的教室在wlCell已经排课,那么,要预先将ttcctwl_cr从tblData_ttcctwl表中删除,将ttcctwl_cr对应的ttcct加入到tblData_ttcct中。
基本动作导致tblData_ttcct表中的记录数减1,辅助动作导致tblData_ttcct表中的记录数加1。但是辅助动作的执行是有条件的,所以一系列动作执行的结果可能导致tblData_ttcct表中的记录数趋向0,从而达到目标。
上述动作将产生新的状态,并且可能删除某个祖先状态的数据,因此,可以套用数据共享的程序模板进行补偿。要注意,因为状态数据保存在两个数据库表中,所以要同时对这两个数据库表进行补偿。
(3)启发函数和次级启发函数。启发函数f(n)=g(n)+h(n)。排课系统不关心过程,只关心最后结果,所以可以把启发函数简化为f(n)=h(n),把状态n在tblData_ttcct表中的记录的数量作为h(n)的值,因为它能够衡量状态n与目标状态之间的距离。应该选取h(n)最小的状态n进行扩展。但是,此时,tblData_ttcct表中还有h(n)条记录,即还有h(n)个ttcct,还需要在它们之间选择一个最优的ttcct进行扩展。对于数据库系统而言,需要进行第二次选择的环节具有普遍性,因此,引入次级启发的概念,相应地定义次级启发函数:
f’(i) =h’(i)
i表示构成状态的数据集中的某个元素,h’(i)表示与这个元素有关的数据。
ttcct的ISRatio值越小,排课难度越大,越应该优先被安排,对安排全部的ttcct越有利。所以,把ISRatio作为h’(i)的值,在h(n)个的ttcct中,选择h’(i)最小的ttcct,利用它进行状态扩展。
(4)状态特征值。状态特征值是一个字符串,对它的要求是提取速度快,字符串短。排课系统的状态特征值浓缩了某个状态的全校课程表信息。状态特征值应该只包含课程表中最基本的信息,所以可以从班级课程表来提取状态特征值。用字符串stateStr表示状态特征值,从全校班级课程表中提取状态特征值的伪代码如下:
Begin
初始化stateStr为空;
按既定顺序提取班级课程表,存放到list中;
For each班级课程表 in list Do
Begin
For ln=1 to 8 Do
Begin
For wd=1 to 5 Do
Begin
str=wlCell[ln,wd]课程名称的第一个字符;
stateStr += str;
End;
End;
End;
End。
如果某个wlCell还没有安排课程,那么课程名称可以用空格或下划线等代替。一般情况下,每个班级课程表中有40节课(每周5天,每天8节),如果所有的课程名称的第一个汉字都不相同,可以只提取第一个汉字加入到状态特征值的字符串中。以全校12个班级计,状态特征值的字符串长度是40*12*2=960。如果用一个英文字母来表示课程的名称,状态特征值的字符串长度就会减半,为480个字符。
5.结论与后续工作
套用本文提供的这两个程序模板开发的自动排课软件已经在福州市第36中学使用。这是一所典型的初级中学,有3个年段,12个班级,每个班级每周40节课。设置好基本数据之后,自动排课软件能够在8分钟左右的时间内自动安排好整个学校的课程表,完全满足学校的要求。后续的工作是研究如何选择最好的状态进行重构,以便更快地搜索到目标。另外,状态特征值的字符串长度可能会很长,超过数据库系统中基本表的字符型字段的长度限制,目前的做法是把状态特征值拆分为若干个子字符串以适应数据库系统的要求,这会造成tblAStar的表结构不统一,不利于应用程序的通用性的要求。所以,有必要对状态特征值进行深入研究。
[1]NILSSON N J. 人工智能[M].北京:机械工业出版社, 2000 .
[2]VAN M D. A museum visitors guide with the A~*pathfinding algorithm[C].上海:2011 IEEE International Conference on Computer Science and Automation Engineering(CSAE 2011),2001.
[3]张程,肖大薇,张盈谦.基于区域搜索的A*算法在游戏寻径中的应用研究[J].电子设计工程,2014(13):15-17.
[4]肖自兵,袁冬莉,屈耀红.基于A~*定长搜索算法的多无人机协同航迹规划[J].飞行力学, 2012(01):92-96.
[5]林峰.模板比对法实现中小学自动排课[J].福建电脑,2008,24(12):183-185.
(责任编辑:杨成平)
The Application of A*Algorithm Program Template for Database System
LIN Feng, ZHENG Ai-yuan
(Department of Information Management & Engineering,Fujian Commercial College, Fuzhou 350012, China)
Database system has been widely applied, dealing with many complex data processing in real life. A*algorithm also has many successful applications, but there is a lot of room for development in using database technology and A*algorithm to tackle practical problems. A*algorithm search space is large and often takes tens of minutes or even longer time to search for the solution. Therefore, a database system using A*algorithm is impractical because it requires considerable time to wait for executive results. Therefore, a set of program template which applies A*algorithm to database is proposed to solve above mentioned problems. An automatic course timetabling system based on program template is designed to solve a typical high school course scheduling problem. The results show that program template demonstrates practical value of proposed method.
A*algorithm; secondary heuristic function; database technology; automatic course timetabling
2017-01-22
2016年福建省中青年教师教育科研项目(科技类)“利用状态空间的启发式搜索法实现自动排课系统”(JAT160578)。
林峰(1966-),男,福建福州人,讲师,硕士。研究方向:计算机软件编程。
TP311.138
A
2096-3300(2017)01-0094-06
猜你喜欢
数学物理学报(2021年5期)2021-11-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
童话世界(2019年17期)2019-07-04
数学物理学报(2018年3期)2018-07-17
小学生优秀作文(趣味阅读)(2017年9期)2017-08-07
制造技术与机床(2017年4期)2017-06-22
中国交通信息化(2017年11期)2017-06-06
电信科学(2016年10期)2016-11-23
金色年华(2016年8期)2016-02-28
核科学与工程(2016年3期)2016-01-03
