
基于巨量轨迹数据的热点挖掘算法
2017-06-15 17:21张沛朋
绥化学院学报 2017年6期
张沛朋 魏 楠
(济源职业技术学院 河南济源 459000)
基于巨量轨迹数据的热点挖掘算法
张沛朋 魏 楠
(济源职业技术学院 河南济源 459000)
轨迹数据挖据算法目前主要集中于对有限维度属性轨迹数据的挖据。对于巨量多维度情况下的轨迹数据挖据算法的研究还处于起步阶段,较多研究结果均利用了常规性聚类算法,然而多维条件下的轨迹数据逐渐出现时空概念,常规的距离聚类已经不能有效地进行信息挖据。基于此背景,适时地提出了新的挖掘算法,是具有一定实际意义的。新算法加入时间维度,每个轨迹点的速度以及曲率属性,将整条轨迹划分为若干条子轨迹,再结合模糊C均值聚类,对子轨迹进行了聚类,与传统算法相比较,新算法在聚类质量以及运行时间上均有一定的提升,新算法更适合巨量轨迹数据的挖据。
巨量轨迹数据;挖据算法;子轨迹;模糊C均值聚类
随着工业4.0全自动化技术被日益提及,越来越多的学者开始关注传感器,射频识别技术以及定位系统的实时位置捕捉问题。但是这些实时位置点均镶嵌于空间、时间相关联的节点中,通常此类位置点也被称为空间点,而空间点所携带的数据就是现在被大量研究的时空数据,也被称为轨迹数据。如何挖掘轨迹数据中有效信息以及潜在的有用信息是当前数据挖掘的研究热点。[1]本文主要研究了巨量轨迹数据的处理方法以及子轨迹数据挖掘算法。
一、轨迹数据结构
轨迹是随着移动对象在时间领域中移动时被记录的一组记录序列。因此,轨迹可以通过节点与节点相连接,节点也是轨迹的捕捉点,其中,可以将节点根据轨迹的时间变化分为起点,锚点以及终点,如图1-1所示。

图1-1 轨迹结构示意图
图1-1中示意的锚点是轨迹驻留时间相对其他节点较长的节点,表示移动对象到达此位置的频次。主要用来统计移动对象的时空规律以及预测移动对象的下一个实时位置。
二、基于巨量轨迹数据的挖掘算法
目前处理巨量的轨迹数据常用算法为聚类算法,通过聚类移动对象的相似轨迹,从而提取移动对象的运动特征,进一步预测移动对象的运动轨迹。[2]较成熟的轨迹聚类算法有欧式距离的轨迹聚类算法,豪斯多夫聚类算法以及最小外包矩形算法。但是此类聚类算法也有一些缺陷,例如,轨迹数据作为一种时空数据,欧式距离在时空领域逐渐失效。为此,本文提出了加入时间维度,将整个轨迹聚类划分为子轨迹聚类的算法。
(一)算法基本思想。基于巨量多维子轨迹聚类算法基本思想:
Step3:根据拐点的位置,将整段移动对象轨迹划分为n+1段子轨迹;
Step4:结合每段子轨迹的空间信息以及速度信息,度量子轨迹的距离;
Step5:采用模糊聚类算法的思想,对子轨迹进行聚类,挖掘轨迹数据中所包含的有效信息。
(二)算法概念解释。本文巨量轨迹数据的挖掘核心点在于对子轨迹数据的模糊聚类,目前较为完善的聚类算法为模糊C均值算法[3-5],因此本文的模糊聚类算法采用模糊C均值算法,其中的特定术语解释如下:
1.隶属度矩阵。设一个研究集合W中包含了m个元素wi(i=1,2,3…,m)。若将集合W划分为z个子集J1,J2,J3…,Jz。则隶属度矩阵D是由元素wi聚集到子集Jz的隶属度dik,该矩阵是一个z行m列的矩阵,且0dik1。聚类之后,可以通过隶属度划分每个元素的类别。
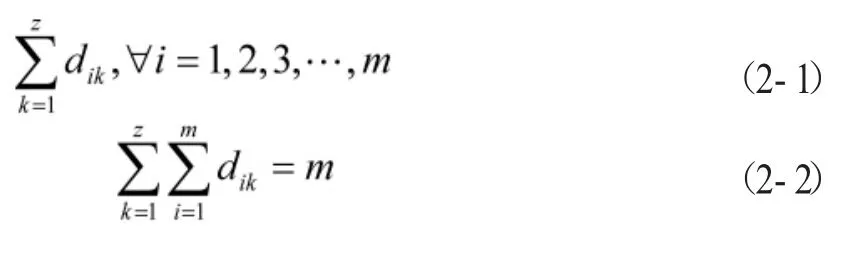
2.价值函数。聚类过程是否已经终止需要通过价值函数对其进行判断。模糊C均值算法中的价值函数为:
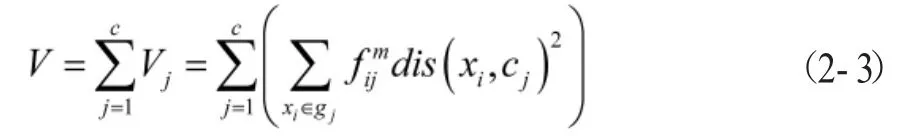
式中:表示模糊C均值算法中的模糊程度。
利用拉格朗日乘子法构造模糊C均值算法的最小目标函数,表示为:
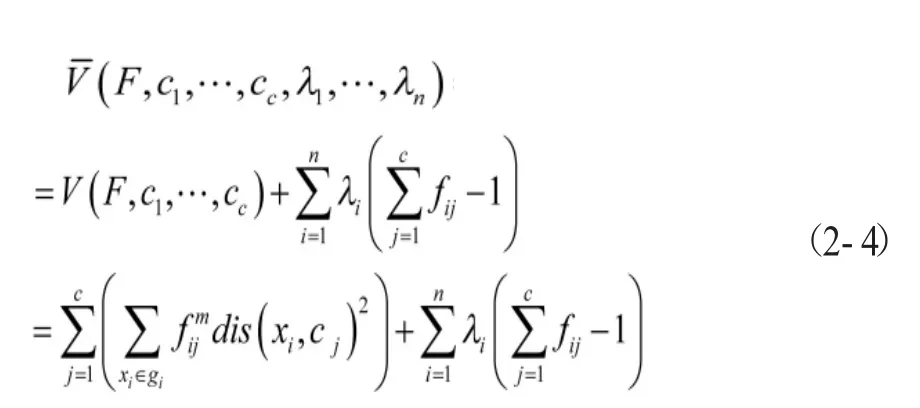
则可得到实现目标函数的条件为:
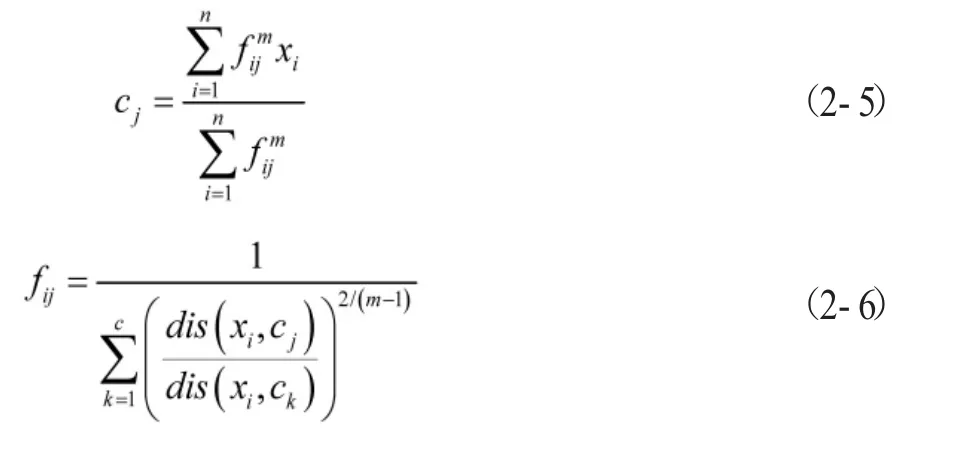
(三)轨迹划分。根据本文算法思想,将每一个移动对象轨迹数据录入到一个矩阵,并标记每一个移动轨迹数据为记录点,通过计算每个记录之间的曲率变化以及速度变化,寻找到轨迹数据的拐点。[6-8]算法如下:

(四)子轨迹距离度量。两条轨迹之间的距离需要通过三个子变量计算:位置距离,速度距离以及时间距离,除此之外还需轨迹数据的隶属度属性维度,则距离度量公式表示为:
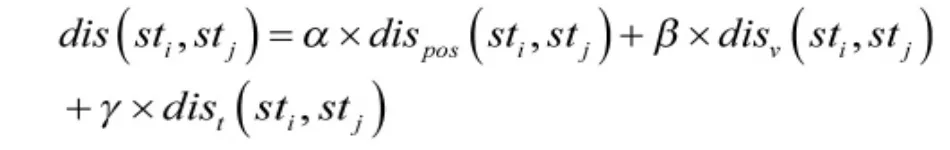
(五)子轨迹聚类。巨量轨迹数据一般均是重叠或者部分重叠于一起。[9]在模型中的具体表现是隶属度,且隶属度是一个0于1之间的数值。
算法步骤如下所示:

三、实验结果分析
(一)数据初始化。实验所使用的数据为真实数据集,来源于2015年10月由数据堂提供的背景出租车GPS记录的轨迹数据。该数据完整的记录了出租车在北京市的运行轨迹,原始数据包含属性维度较多,本文只是选择了:车辆ID,GPS时间,GPS经度,GPS纬度,GPS速度,GPS方向属性。数据初始化之后,如表3-1所示。
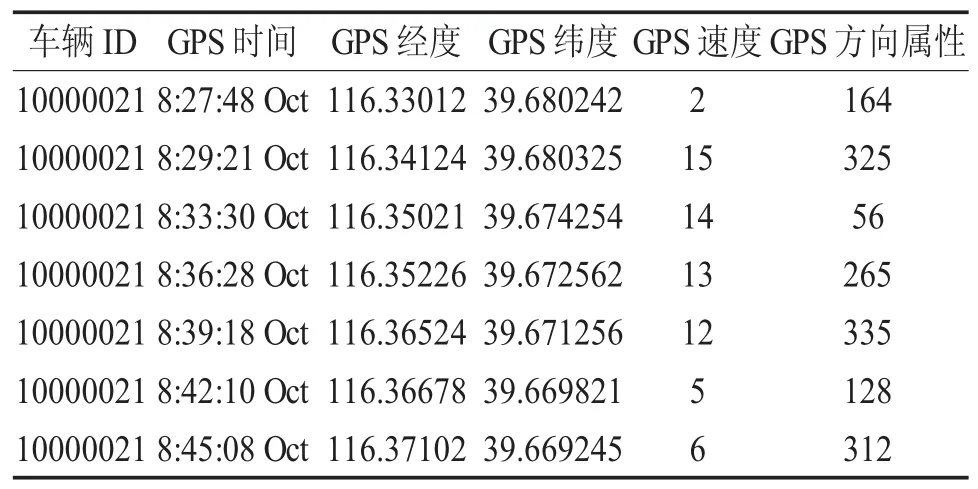
表3-1 数据初始化
(二)实验结果评价。对于聚类质量的评估需要综合评价,本文选择簇内方差评价,公式如下:
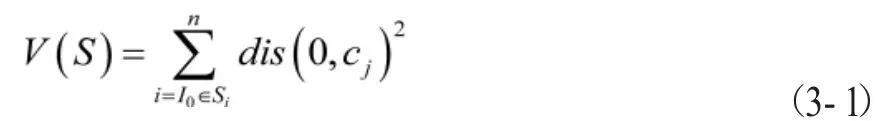
ci表示簇S的核心点
dis表示距离度量函数式
最优的簇内聚类是簇的期望值尽可能等于0。
为了进一步反应新算法在聚类中的优势,本文考虑了在不同维度下,变化时间和维度后新算法与以往聚类算法在巨量数据下的误差比较。
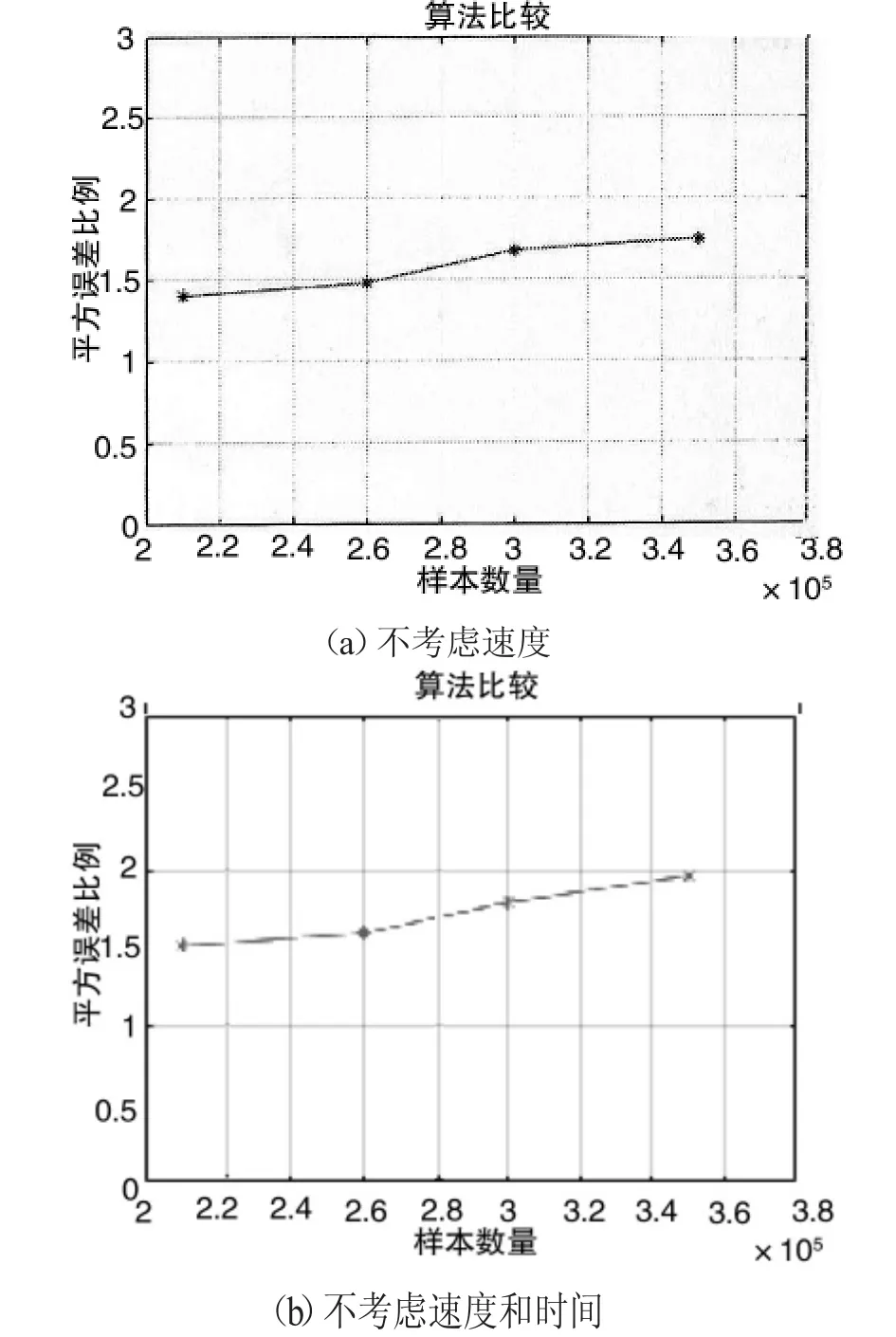
图3-1 聚类结果效果比较
图3-1表示轨迹数据在不同维度下聚类结果的质量。其中,图3-1(a)表示了不考虑速度维度时的算法质量比较结果,图3-1(b)表示了不考虑速度和时间维度的算法质量比较结果。
新算法与之前算法的运行时间比较结果如图3-2所示。该实验环境是,增加初始状态的簇数量,则结果如下:
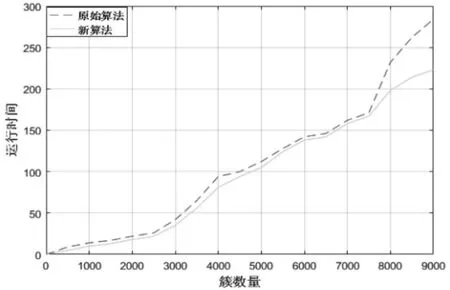
图3-2 新旧算法运行时间比较
由图3-2可以清楚的看出,新算法的运行时间相比较旧算法在不断增加簇数量的情况下有所降低,但是从图3-1可以看出算法质量并没用降低。因此新算法对于巨量轨迹数据的挖掘有一定的效率以及质量优势。
四、结语
对于多维巨量轨迹数据的挖掘算法来说,主要是集中于对子轨迹的划分以及最后对子轨迹的聚类。本文在前人的基础上,通过轨迹的速度以及曲率变化标记了轨迹的拐点,然后由拐点将轨迹划分成若干子轨迹,最终使用改进的模糊C聚类算法对子轨迹进行了聚类。并评价了新算法的挖掘效果,最终得出新算法更适用于轨迹数据挖掘的结论。
[1]Y.F.Li,J.W.Han,J.Yang.Clustering Moving Objects[M].In Proceedingsofthe10thACMSIGKDDInternationalConferenceon Knowledge Discovery and Data Mining,Seattle,WA,USA,2004, 617-622.
[2]Q.Zhang,X.Lin.Clustering Moving Objects for Spatiotemporal Selectivity Estimation[J].In Proceedings of the 15th Australasian Database Conference,Dunedin,New Zealand,2004:123-130.
[3]P.Kalnis,N.Mamoulis,S.Bakiras.On Discovering Moving Clusters in Spatio-temporal Data[J].In Proceedings of the 9th International Symposium on Spatial and Temporal Databases, AngradosReis,Brazil,2005:364-381.
[4]J.Chen,C.Lai,X.Meng,J.Xu,H.Hu.ClusteringMovingObjectsinSpatialNetworks[J].Inproceedingsofthe12thInternational Conference on Database Systems for Advanced Applications (DASFAA2007),Bangkok,Thailand,2007.
[5]J.Lee,J.Han,X.Li,H.Gonzalez.TraClass:TrajectoryClassification Using Hierarchical Region-Based and Trajectory-Based Clustering[J].InProc.VLDB2008:140-149.
[6]潘纲,李心坚,齐观德,等.移动轨迹数据分析与智慧城市[J].中国计算机学会通讯,2012(5).
[7]刘大有,陈慧灵,齐红,等.时空数据挖掘研究进展[J].计算机研究与进展,2013,50(2):225-239.
[8]D.Chudova,S.Gaffney,E.Mjolsness,and P.Smyth.Translation-invariantmixture modelsforcurveclustering[J].In Proceedings of the 9th International Conference on Knowledge Discovery and Data Mining(KDD’03).ACM,New York,2003:79-88.
[9]T.Tzouramanis,M.Vassilakopoulos,and Y.Manolopoulos. Overlapping Linear Q uadtrees:A Spatio-Temporal Access Method[J].In Proc.of the ACM workshop on Adv.in Geographic Info.Sys.,ACMGIS,Nov.1998:1-7.
[责任编辑 郑丽娟]
A Hotspot Mining Algorithm Based on Large Amount of Trajectory Data
Zhang Peipeng1Wei Nan2
(1.Department of Art and Design,Jiyuan Vocational and Technical College;2.Undergraduate Teaching Office, Jiyuan Vocational and Technical College,Jiyuan,Henan 459000)
The trajectory data mining algorithm is mainly focused on the mining of finite-dimensional attribute trajectory data.In this paper,we use the conventional clustering algorithm,but the trajectory data under the multi-dimensional condition gradually appear the concept of time and space,and the conventional distance clustering Has been unable to effectively carry out information digging.Based on this background,it is of practical significance to put forward a new mining algorithm in time.The new algorithm adds the time dimension,the velocity of each track point and the curvature attribute,divides the whole trajectory into several sub-trajectories,and then combines the fuzzy C-means clustering to cluster the sub-trajectories.Compared with the traditional algorithm,The clustering quality and the running time have some improvement,the new algorithm is more suitable for the huge amount of trajectory data.
huge amount of trajectory data;digging algorithm;sub-trajectory;fuzzy C-means clustering
TP393
A
2095-0438(2017)06-0150-04
2017-03-05
张沛朋(1983-),男,河南开封人,济源职业技术学院讲师,硕士,研究方向:计算机应用;魏楠(1983-),女,河南济源人,济源职业技术学院讲师,硕士,研究方向:计算机应用。
2015年度河南省高等学校青年骨干教师资助计划(编号:2015GGJS-282)。
猜你喜欢
中州建设(2020年5期)2020-12-02
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
今日农业(2019年10期)2019-06-26
人大建设(2018年9期)2018-11-13
现代装饰(2018年5期)2018-05-26
电子测试(2017年15期)2017-12-18
中国三峡(2017年2期)2017-06-09
雷达学报(2017年6期)2017-03-26
人大建设(2017年12期)2017-03-20
