
基于Hadoop的大数据解决方案的设计及应用
2017-06-22 14:41苏树鹏
河池学院学报 2017年2期
苏树鹏
(广西机电职业技术学院,广西 南宁 530007)
基于Hadoop的大数据解决方案的设计及应用
苏树鹏
(广西机电职业技术学院,广西 南宁 530007)
随着信息化技术和终端智能的迅猛发展,系统需要处理的数据呈现海量化,使得海量数据的存储、挖掘成为当前亟待解决的问题。使用云计算技术构建集群系统,可有效地解决海量数据的存储、共享和深度挖掘问题。首先,采用平台Hadoop构建主框架,并采用异构存储的方式将各部门的业务数据转储到集群系统各节点上存储,有效地解决了大数据的存储和备份问题。最后借鉴Hive和Hbase优点设计数据挖掘子系统,提高了集群系统对海量数据的分析能力。实时性分析实验结果表明此次采用的方法较之以往的方法再获得了30%的提升。
Hadoop;Hbase;Hive
0 引言
随着物联网和智能终端技术的广泛应用,数字世界产生了6ZB的数据,其中95%属于非结构化数据,且总量飞速增长。系统在处理大数据过程中面临真正的难题是大数据的存储、高速处理和系统及时响应。为了解决大数据带来的难题,柏林工业大学博士后Mikio L.Braun[1]提出了大数据解决方案:通过可动态伸缩并无限扩展对大数据进行可靠存储管理,运用知识计算等大数据分析技术挖掘大数据潜在价值的信息,但该方案还未解决实时大数据迁移等问题。本文在推进信息化智能化数字校园建设背景下,针对存在校园网平台中的各系统处理和存储的数据类型呈现多样化、异构性等问题,而导致无法实时存储和高效处理的大数据,利用大数据思想和云计算技术构建智能化数字校园平台。先对校园各个系统平台处理的信息生命周期分析,构建云计算架构的大数据解决方案,通过设计数据迁移子系统,解决实时将各个服务器中的数据迁移到集群系统中进行统一存储管理问题,实现校园海量数据共享。通过设计数据分析挖掘系统,解决数据深度挖掘、智能数据分析等问题,为处理大数据提供新的解决方案。
1 系统平台架构技术介绍
目前进行云计算研究与大数据处理的较为主流的平台有由Apache公司研发的Hadoop[2-3]系统,其把复杂的作业经过算法优化进行合理切分成若干子作业,然后将子作业分配到具有所需数据的若干节点进行并行MapReduce计算,节点间没有依赖性且可以根据运行状况进行调度,提高处理速度和效率。平台进行并行处理时,需要位于平台底层分布式存储系统中众多节点存储的数据和节点具体操作,众多节点中有唯一的主节点控制其他节点的协同操作和存储信息。HBase[4-6]是利用Hadoop系统另一核心HDFS作为存储基础,具备存储海量非关系数据库,作为众多节点进行并行计算任务的输入和输出。Hive[7]是采用类似SQL语言对数据进行管理的数据仓库工具,把经过解析和编译的HiveQL命令交给Hadoop平台中各个子节点的MapReduce并行执行。利用Hbase与Hive两者的API接口进行通信建立关联,对Hbase提供的用键值存储数据进行快速的索引查找。
2 基于Hadoop的大数据解决方案
2.1 方案系统需求分析
大数据解决方案系统主要分为两个子系统:数据迁移子系统和数据分析挖掘子系统。数据迁移子系统把各个在线业务平台服务器的数据实时迁移到海量数据库中,解决大数据的存储、备份和共享问题;数据分析挖掘子系统利用系统集群并行对大数据进行快速分析处理,生成有价值的报告。
2.2 系统架构设计
系统架构图如下图1所示。
本文设计的大数据解决方案系统基于Hadoop平台的集群,以面向列存储的HBase作为海量数据存储数据库。数据迁移子系统通过基于网络的存储虚拟化整合网络异构,规避和减少宕机,保证在线数据迁移时不需间断业务,迁移后由HBase对大数据进行高效管理。数据分析挖掘子系统则基于密集型离线数据分析,通过建立Hive和HBase无缝连接,Hive提供类似SQL查询,经过系统平台编译HQL,生成执行计划,交由MapReduce对HBase管理的数据进行高效地并行计算,把深度挖掘到有价值的结果反馈给用户。
(1)数据迁移子系统拓扑图如图2所示。
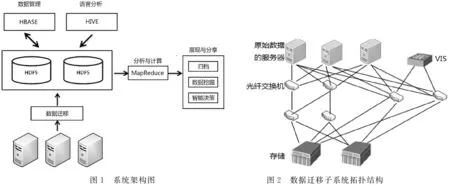
该拓扑图采用临时存储网络,解决在迁移过程中不需要中断业务,且可以控制业务的迁移速度问题,同时可以降低因网络环境问题对其他业务系统的影响。
(2)数据迁移子系统架构图图3所示

图3 数据迁移系统架构图
迁移功能的主要流程:
①各服务器原始数据:基于校园平台中的各系统在应用过程中产生种类繁多且海量化数据,如何将各个服务器上的海量数据安全、快速地迁移入分布式HDFS,集群系统中的IO性能起着决定性作用,通过实时分析IO读写速度和网络资源状况,把任务分配给IO负载较轻的节点,实现高效的从客户端将数据导入服务器的HDFS系统。
②系统Job:根据系统集群并行处理的需求,编写代码生产并行操作的Map/Reduce架包,当在运行Map和Reduce时生成一个作业Job实例,设计好Map方法读取数据的路径和格式。
③数据解析转换:运行在MapReduce架构中的Job,读取指定路径中的HDFS中的文件,并在Map方法中将数据生成指定的格式。
④通过ZooKeeper在META.表查找存储大数据的RegionServer,通过运行系统jar生成Put对象,使用该对象的add()方法将客户端的数据映射到数据库中对应的列,最后将数据通过Write方法迁移入指定的HBase数据表。
(3)数据分析挖掘子系统架构如图4所示。

图4 挖掘子系统架构图
数据分析模块的主要流程:
①Hive与HBase集成:Hive和Hbase两个框架通过HBaseStorageHandler架包实现无缝接口整合,在Hive建立的表自动获取与其建立通信的Hbase中的对应的表名、列簇和输入输出格式等信息。
②数据表映射:运行HQL命令创建Hive的外表,该外表和Hbase的表映射,通过配置信息映射由HBase到Hive,确保HBase和Hive两者之间列和数据类型的一致性。
③HBase表切分:根据数据表对应的HRegion,将Region作为InputSplit单位,根据拆分数量交给等量的Map操作。
④查询分析统计:用户在系统平台中使用Hive提供的组件,根据业务需求进行编译、提交HQL命令,然后编译器对HiveQL命令进行解析,优化,最后系统生成Hadoop的MapReduce任务,通过构建Scanner对HBase表数据进行扫描,对条件进行过滤、排序、去重,最后通过next()获取数据,并且把数据生产表格、图表等形式交付给用户。
3 系统负载均衡
集群系统吞吐量和数据处理能力需要负载均衡,在集群各设备中合理分配业务量,确保集群中设备协同完成作业,步骤如下图5:

图5 负载均衡步骤
①集群系统状态初始化:存储系统中的各个Region服务器在规定的时间间隔内把自身的负载状况向master汇报,并通过master获取集群的分配情况且存入数据表Map中,存储方式采用键值对,设置好Region服务器的负载度以及Memstore内存大小等等。
②计算系统是否平衡:先计算系统集群中负载平均值:float average=region数/server数;再求集群负载最小值floor和最大值ceil,通过遍历Map中的Value,如果Value的最小值大于floor,并且最大值小于ceil,则不需要进行负载均衡,反之则需要。
③计算开销:当需要平衡时,首先根据集群分配表生成一个虚拟的集群clusterP,其中clusterState是表的状态,loads是整个集群的状态:Cluster clusterP=new Cluster(clusterState,loads,regionFinder);通过对集群中各服务器计算cost的加权平均和计算实现开销重心,然后循环MaxSteps次,用选号器从集群当中随机选出
④数据移动:根据平衡方案List
4 系统运行效果分析
为了测试大数据解决方案的数据分析挖掘子系统性能,实验中采用了5组不同的数据进行测试。本次实验的重点在于负载均衡方案下评估系统集群协同处理作业的耗时测试,集群的每个节点的配置一样且没有失效问题。实验环境:系统集群由1台做NameNode,JobTracker,另外5台做DataNode,Task-Tracker。服务器运行用centos操作系统,并安装hadoop-1.0.3,hive-0.9.0,hbase-0.94.2,zookeeper-3.3.5。
实验内容:在实验中的数据都来自存储在具有唯一主键的HBase数据库中,集群通过系统负载均衡方案优化,再根据优化结果向各节点发送数据,然后在各节点中并发处理数据,最后统计发送和处理数据总耗时,为了表明本文所提系统集成之后经过系统均衡方案算法的有效性,如表1所示。

表1 数据耗时对比
通过表1的实验数据可以看出,本文所提出在Hadoop平台上集成Hive和HBase,通过本文设计的系统均衡方案,处理相同容量的数据性能平均提高了30%,表明本文算法的可行性,所以在以Hadoop为平台的集群中,Hive+Hbase数据处理时,通过优化Hbase能发挥其海量处理的优势,且随着处理数据量的增大优势更明显。本方案与Hadoop+Hive架构方案最大的不同包含以下两方面:
一是数据存储方式不同。两种方案都是采用Master/slaves架构,Hadoop+Hive架构方案中的HDFS会把大文件分割成很多小文件来存储,保证大数据存储完整性和安全性,并且Hadoop记录每一个数据块在存储架构中的位置,在Map/Reduce处理作业时,通过就近原则进行任务分配,从执行任务的Task机器上读取最近的数据块,减少了数据传输和读取的时间开销。本方案的数据由HBase管理,为了解决HBase会随机分配数据无法存储在本地机器的难题,在少重启系统的条件下,每台机器都装Hadoop和HBase,确保每个RegionServer都有DataNode,这样RegionServer具备了从本地机器读取数据的条件,且在测试系统过程中发现数据的存储地点更稳定。
二是读取数据效率不同。Hadoop+Hive架构方案读取数据提交给HiveQL,并通过编译交给Map/Reduce同时对HDFS存储的数据进行处理。本方案设计系统负载均衡算法,使MasterServer分配Region更合理,确保每个Region被分配给拥有最多RegionBlock的RegionServer。HBase是低延迟,所以通过Hive集成HBase,使MapReduce执行效率得到最优化。
5 总结
基于Hadoop平台系统集群通过协同作业是解决大数据方案之一,系统集群中存在备份数据困难、负载不均衡导致JobTracker的负载过大,系统集群性能遇到瓶颈。本文提出了基于Hadoop大数据解决方案,通过设计数据迁子系统,实现了实时数据迁移功能,解决了海量数据备份问题;利用Hadoop平台构建系统集群,使用HBase实现实时存储数据和高效检索,通过负载均衡方案,使得系统集群中的每个JobTracker实现高效处理海量数据,大大提高了处理海量数据速度和挖掘效率。
[1]朱珠.基于Hadoop的海量数据处理模型研究和应用[J].北京邮电大学学报,2008,11(2):100-102.
[2]周霞.基于云计算的太阳风大数据挖掘分类算法的研究[J].成都理工大学学报,2014,10(5):50-52.
[3]刘士佳.基于MapReduce框架的频繁项集挖掘算法研究[J].哈尔滨理工大学学报,2015,12(2):70-73.
[4]曾大耽,周傲英.Hadoop权威指南[M].北京:清华大学出版社,2010:12-15.
[5]范建华.TCP/IP协议详解[M].北京:机械工业出版社,2012.
[6]刘鹏.实战Hadoop开启通向云计算的捷径[M].北京:电子工业出版社,2011.
[7]易见.Hadoop开发者[M].北京:清华大学出版社,2010.
[责任编辑 韦志巧]
The Design and Application of Big Data Solution Based on Hadoop
SU Shupeng
(Guangxi Technologial College of Machinery and Electricity,Nanning, Guangxi 530007, China)
With the rapid development of information and intelligent terminal technology, the data needed to be processed has grown enormously.How to store and mine the massive data become more essential at present.This article solves the problem of massive data storing,sharing and mining by building cluster system on thebasis of cloud computing technology.First of all,this paper construct a framework with Hadoop platform.then transfer business data to nodes of cluster system in heterogeneous storage mode,finally,with reference to the advantage of Hive and Hbase. a data mining subsystem is designed,that enhance the massive data analytical ability of cluster system.The result of real-time analysis shows that the solution of this article raise 30% in efficiency,which has high practical and reference value
Hadoop; Hbase; Hive
TP31
A
1672-9021(2017)02-0089-05
苏树鹏(1980-),男,广西南宁人,广西机电职业技术学院讲师,硕士,主要研究方向:云计算和软件设计。
2016年度广西高校中青年教师基础能力提升项目“基于云计算和物联网的智能校园的研究与设计”(KY2016YB650)。
2016-12-25
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
北京航空航天大学学报(2022年8期)2022-08-31
铁道通信信号(2020年3期)2020-09-21
军事运筹与系统工程(2019年4期)2019-09-11
当代陕西(2019年14期)2019-08-26
铁道通信信号(2018年8期)2018-11-10
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
中学数学杂志(初中版)(2016年5期)2016-11-01
