
MMSEG算法与统计方法结合的中文分词模型研究
2017-07-02 03:52
岭南学术研究 2017年1期
(东莞理工学院城市学院,广东 东莞 523419)
在信息检索和数据分析等领域存在大量的中文文本数据,而使用计算机对这些数据进行处理之前都必须进行分词的处理。分词需要高效、准确的算法。目前常见的分词模型有基于机械式的字符串匹配、基于字符串的统计频率、基于自然语言语法语义的理解等。其中基于规则的分词方法如最大匹配法(MM)及其各种变体,因为规则覆盖率不高和规则的主观性较强,准确率有所不足[1]。常见的基于统计的模型如N-gram、隐马尔可夫模型(HMM)、最大熵马尔可夫模型(MEMM)和条件随机场(CRF)等分词方法过于依赖训练语料库,分词效率较低,同时在分词过程中忽视了汉语的句法、语法等信息[2]。结合规则与统计的方法是中文分词领域研究的热点。本文结合规则和统计分词算法提出一种改进的分词模型,该模型将最大匹配算法的一个变体——MMSEG算法[3-4]与统计方法相结合,根据中文分词中所遇到的问题,对模型进行逐步优化,最终实现分词方法的时间复杂度降低,以及分词的召回率(recall)和F-measure指标的提高。
一、分词算法及其实现
(一)MMSEG分词算法
MMSEG包含简单最大匹配法和复杂最大匹配法,本文选取其中的复杂最大匹配法与统计方法进行结合。MMSEG的复杂最大匹配法首先识别出从当前读取位置开始所有的块(chunk),块是包含三个词的组合。对于句子 由多个字符构成,则
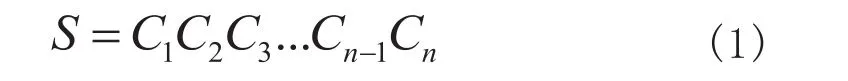
当前分词位置为 时则其所有块组成的集合表达式为
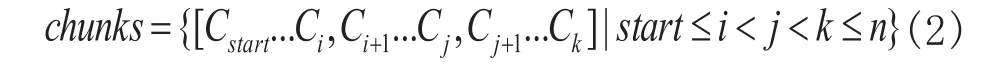
例如有字典dict=[研究,生命,研究生],对句子“研究生命”进行分词则能分出所有的块:[研究,生命],[研究,生,命],[研究生,命],[研,究,生命],[研,究,生]。如果元素个数等于1,则选择唯一的块中的第一个词作为分词结果返回,如果元素多于1个,则依次应用规则1到4进行过滤。
规则1:最大总词长
取总词长度最长的块中的第一个词作为分词结果返回。
假设的元素个数为中的元素的有效词数(即不为空的词的个数)为为词w的长度,为中的词,则i的总词长计算公式为
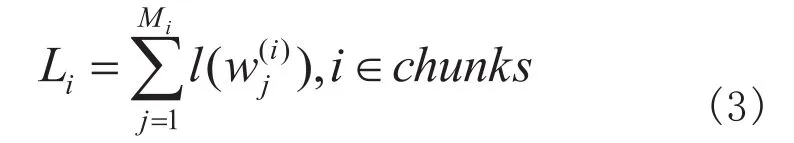
取得最大词长的块的公式为

例如对于以上例子有

表1 各块的总词长
如果过滤后得到的候选块个数等于1,则选择该块中的第一个词作为分词结果返回,如果多于1则应用规则2进行过滤。例子中根据规则1排除第5种方案,接着对剩下的4种应用规则2。
规则2:最大平均词长
取平均词长度最大的块中的第一个词作为分词结果返回。
计算平均词长的公式为
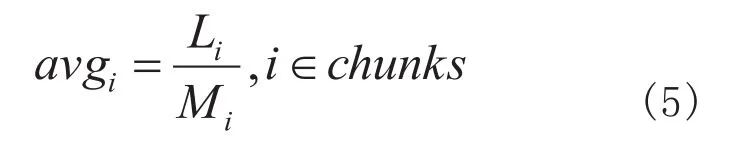
选择最大平均词长的块的公式为
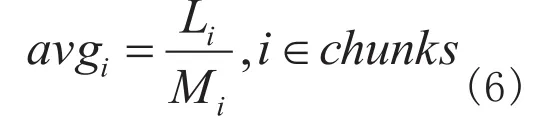
上文例子的平均词长为
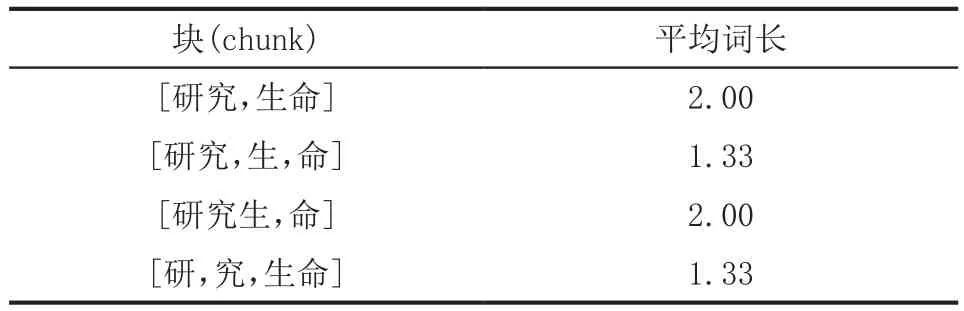
表2 各块的平均词长
如果过滤后得到的候选块个数等于1,则选择该块中的第一个词作为分词结果返回,如果多于1则应用规则3进行过滤。例子中排除两种方案,剩下两种继续应用规则3。
规则3:最小词长方差
取词长方差最小的块中的第一个词作为分词结果返回。
词长方差的计算公式为

得到最小方差的块的公式为
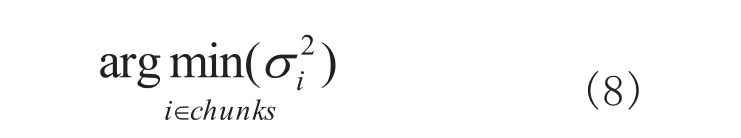
例子中计算得到

表3 各块的词长方差
如果过滤后得到的候选块个数等于1,则选择该块中的第一个词作为分词结果返回,如果多于1则应用规则4进行过滤。例子中选出了正确的分词方案,即返回[研究,生命]中的“研究”一词作为此次分词的结果。
规则4:最大单字语素自由度之和
取单字语素自由度之和最大的块中的第一个词作为分词结果返回。
假设有多重集(multiset)为中单字词的集合,则有
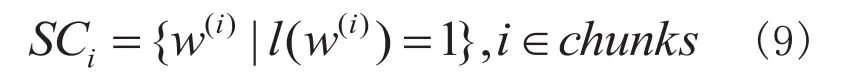
以各个单字词的出现频数作为函数的真数并相加得到最大语素自由度之和,其计算公式为
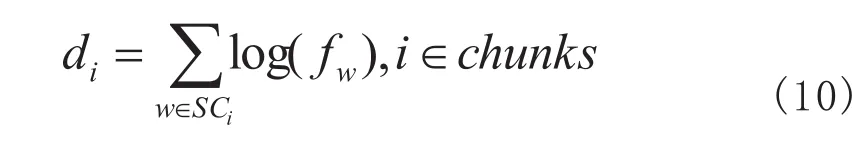
取得最大语素自由度之和的块的公式为

依靠以上规则可以解决大部分的分词歧义问题,但也有相当的一部分句子无法进行正确分词,对于应用规则4后候选块个数仍然多于1个的情况,MMSEG则无法处理,所以本文加入了下文的统计分词算法。
(二)统计分词算法
1.基本思想
本文使用的统计分词算法类似中文分词中的最大概率法,最大概率分词是认为一个句子可能有多种分词结果,而把概率最大的那种分词结果作为正确的结果[5]。不完全和最大概率分词方法相同的是本文的统计算法是计算得到概率最大的块,选择其第一个词作为正确分词结果返回,同时因为基于这样的假设:每个词的出现概率独立。N-gram时间复杂度为v在这里表示一种语言词典的词汇量[6]33,而HMM使用的Viterbi算法复杂度为其中N为节点数,为网络宽度[6]232,而本文统计方法的时间复杂度仅为其中表示分词数,相对于N-gram和HMM等模型大大减少了计算量和降低了模型复杂度,提高了分词的速度,在精度和效率间取得了一个平衡。
根据大数定律,可以知道只要语料库足够大,一个词出现的频率就等于其概率[6]30,在这里直接使用词在训练语料库中出现的频率代表其概率。设语料库词汇量为#,w出现次数为频率为概率为有
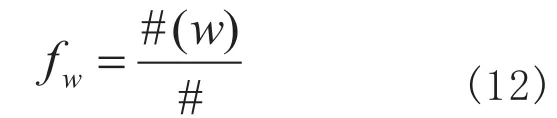
由大数定律得

求出最大概率的块,选取其中的第一个词作为分词结果返回

例如例子“和平和未来”在经过MMSEG处理后仍然无法判定唯一的分词方案,见表4

表4 各块的语素自由度和
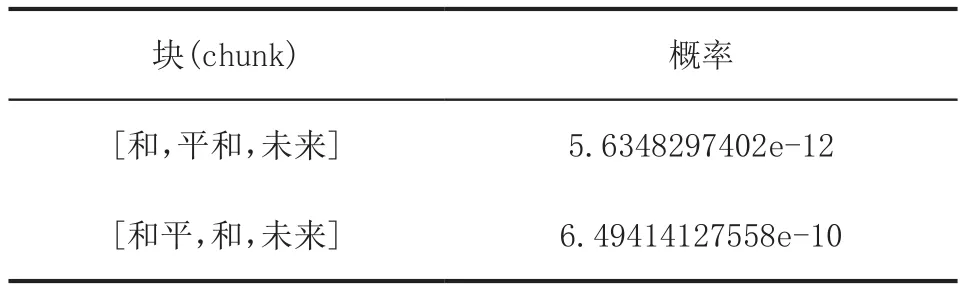
表5 各块的概率
例子中得到了正确的分词结果“和平”。
2.异常处理
对于经过统计方法处理后仍然无法得到唯一分词结果的情况,本文采用将该句子的第一个字作为切分结果返回,然后继续往下切分。而对于未登陆词,为了避免导致分词总体概率为0,考虑到未登陆词在应用场景中很可能属于小概率词,以及出于简便的目的,将未登陆词的出现次数设置为1,对应其概率则为1/#。
3.统计模块伪代码

二、实验结果
(一)分词结果
运行本文所实现的分词程序,部分分词结果如下图所示

图1 部分分词效果
(二)实验结果
为了方便且客观地对比分词的效果,本文所使用的训练语料,测试语料以及评测答案均来自由北京大学为SIGHAN举办的的第二届Bakeoff大赛提供的数据集,评测程序同样采用该次比赛的评测程序。此数据集及数据说明可在SIGHAN官网提供的下载页面[7]中找到,该届比赛的比赛结果可在SIGHAN所提供的比赛结果公布页面中找到。从公布的结果来看,在作为主要评测指标的F-measure上,本文算法优于部分公布的参赛算法。因为语料的差异会严重影响分词的最终结果,为了保证对算法本身的评测客观,本文仅采用封闭测试进行实验和对比,对比算法为未加入统计方法的MMSEG方法,评测指标主要采用F-measure,运行该测试集提供的评测程序score程序,主要输出信息如下

通过实验数据分析,本文提出的规则和统计结合的算法在保持和MMSEG分词算法一样的精确率的情况下提升了召回率,从而使得F-measure也有了小幅改善,在MMSEG上加入简单的统计方法后分词效果得到了小幅的提升。
三、结束语
本文提出的规则和统计相结合的分词算法,能有效改善MMSEG的分词效果,但还存在以下一些尚待改进的地方:词出现概率独立假设这一假设和过于简化,未能全面,准确地反映现实情况。虽然简化了计算过程,降低了计算量,但也同时丢失了词间的上下文信息。未登录词的频率替代问题。本文使用的替代档案是用1代替,使得该词对于所求概率影响无效化。当有大量未登陆词时,会严重降低分词效果,所以需要更为有效的平滑方法处理这种情况。
[1] 赵伟,戴新宇,尹存燕等.一种规则与统计相结合的汉语分词方法[J].计算机工应用研究,2004(3):23-25.
[2] 奉国和,郑伟.国内中文自动分词技术研究综述[J].图书情报工作,2011,55(2):41-45.
[3] Tsai C H.MMSEG: A Word Identification System for Mandarin Chinese Text Based on Two Variants of the Maximum Matching Algorithm [EB/OL]. http://technology.chtsai.org/mmseg/,2000.
[4] 张中耀,葛万成,汪亮友等.基于MMSEG算法的中文分词技术的研究与设计[J].信息技术,2006(6):17-20.
[5] 丁浩.基于最大概率分词算法的中文分词方法研究[J].科技信息,2010,(21):587.
[6] 吴军.数学之美[M].第2版.北京:人民邮电出版社,2014:30.
[7] SIGHAN.SIGHAN官网[EB/OL]. http://sighan.cs.uchicago.edu/bakeoff2005/,2006.
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
小学生学习指导(低年级)(2021年9期)2021-10-14
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
校园英语·月末(2021年13期)2021-03-15
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
