
基于One Class SVM的电信用户流失情况研究
2017-11-22 07:28简宋全李青海黄心蕊秦于钦
现代计算机 2017年29期
简宋全,李青海,黄心蕊,秦于钦
(广东精点数据科技股份有限公司,广州510630)
基于One Class SVM的电信用户流失情况研究
简宋全,李青海,黄心蕊,秦于钦
(广东精点数据科技股份有限公司,广州510630)
在对数据进行分类的过程中,如何用机器学习的方法使数据分类更加准确一直是研究的重点。在对电信用户流失情况的研究中,通常可以比较容易对流失用户进行标记,但是还未流失用户并不代表用户不会流失,所以并不能作为准确的2分类负样本,用One Class SVM提取未知样本中密度较高的部分作为真负样本,将源数据分为正样本,负样本与未知样本三部分,方便以后研究。
0 引言
用户是企业获取利润的直接来源,因此对用户进行分析,可以使企业在市场中更具竞争力,生产出更符合市场要求的产品。在对电信的用户群进行分析时,通过对流失的用户群进行分析,可以使企业做出的决策更符合市场规律。在对用户群进行分类时,往往是将用户群分为已流失的和未流失的两种,然而在实际的用户群分类中,通常可以确定已流失的用户群,可是未流失的部分并不代表未来不会流失,因此很难直接确定用户群是否流失,为了解决这个问题,在分类中,我们采用One Class SVM对数据进行预处理,重新构建分类特征,从未确定特征中提取出真负样本,构建模型,最终找出可能流失的用户群。
1 One Class SVM算法解析
One Class SVM是SVM算法中的一个分支,在机器学习领域,支持向量SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别,分类,以及回归分析。
SVM的主要思想主要是:在线性可分情况下直接进行分箱,在线性不可分的情况,通过非线性映射把输入空间的低维线性不可分的样本转化为输出空间的高维特征空间使其线性可分,再对高维特征空间采用线性算法对样本的非线性特征进行线性分析。SVM是基于结构风险最小化理论之上在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并在整个样本空间的期望风险以某个概率满足一定上界。
在SVM中,我们通过核函数将一组数据分为两类,由于核函数的确定只与特征空间中的向量的点积有关(所有这些向量间的距离),因此,不需要对空间进行显式投影,只需要用核函数K来分类,这就是运用核函数展开定理的技巧,它使SVM可以分析非线性可分离数据的强大功能。特征空间F可以是无限维度的,因此,分离数据的超平面可能非常复杂,在我们的计算中,运用核函数的展开定理,则可以避免这种复杂性。
在一般情况下,核函数可以是线性的,多项式的,S形的,高斯型的,在本文中使用的核函数是RBF One Class SVM算法是用来检测新的数据是否属于原始数据的一种算法,通过提供常规的训练数据,创建一个(具有代表性的)数据模型。形象地说,它就是构造一个高维超球,把数据包起来,尽可能收紧,又尽可能不受外界影响。如果新遇到的数据与训练数据区别较大,在这个模型中就将他定义为类别外的数据。当出现一个分类问题时,只有一种类型的样本,或有两种类型样本,但其中一类型样本数目远少于另一类样本数目时,此时采用二分类器,由于正负样本不均衡,可能造成分类器过雨偏向数目多的样本类别,因此可以考虑使用One Class SVM进行分类。
2 实验过程及结果
(1)在对电信用户群进行分析的过程中,将用户群分为两类,正样本数据是已经流失的用户群,负样本数据是未确定是否流失的用户群,该样本中的一部分可能在下个时段变成正样本。
(2)用one class SVM的方式对负样本进行训练,得出负样本特征较为密集的部分,定义这些部分的负样本为真负样本,再以同样的思路对正样本进行训练,对正样本的训练的目的在于去除正样本中的一些离群噪声点,从而得到真正的正样本。
(3)通过计算可以从结果中可以发现,正样本中总共1502个目标,计算后后出现了362个离群点,负样本中17048个目标,计算后出现5670个离群点,且两个计算后的高密度群互不相交,可以从此处看出其二维分布应该如下图所示:
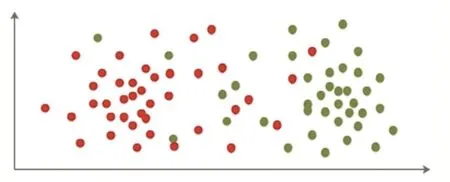
图1
其具体根据算法计算后的分类边界应该如下图所示:

图2
故利用该分类边界将原始数据重新划分为3类,真正类,未知类,真负类:

图3
(4)利用该方式将得到的真正样本与真负样本进行一般分类器的训练,就可以提取未知样本中的真正样本与真负样本,对未知样本部分进行分类。
3 结果评估
该方式可以较好的解决负样本不确定的问题,利用密度较高的样本的情况来判断其离群点情况,得到结果后,只采用特征较为明显的正负样本进行分类器的训练,防止了离群点和不明确点对模型的影响。
但是该方法存在一定的缺点,由于使用该方法得出的正负样本由于特征较为明确,也就是说在二维图中两种样本距离较为分散,因此可能有多种分类方式都能将样本进行分类,使得分类器的泛化能力减弱如概念图所示:

图4
所以采用该方式进行特征工程后的数据建议采用泛化能力较为强的模型,例如随机森林等;同样也可以采用三分类器进行分类,将离群点作为第三分类进行训练。
[1]刘文,吴陈.一种新的中文文本分类算法——One Class SVM-KNN算法[J].计算机技术与发展,2012(05)
[2]张彬.基于One-class SVM的人脸识别研究[J].江南大学,2016(02)
[3]黄谦,王震,韦韬,陈昱.基于One-class SVM的实时入侵检测系统[J].计算机工程,2006(08)
简宋全(1971-),男,广东广州人,硕士研究生,工程师,研究方向为机器学习算法
李青海(1980-),男,广东广州人,硕士研究生,工程师,研究方向为机器学习算法
黄心蕊(1994-),女,福建三明人,本科,助理工程师,研究方向为机器学习算法
秦于钦(1993-),男,广东广州人,本科,助理工程师,研究方向为机器学习算法
2017-07-27
2017-09-25
Machine Learning;One Class SVM
Research on Telecom User Churn Based on One Class SVM
JIAN Song-quan,LI Qing-hai,HUANG Xin-rui,QIN Yu-qin
(Guangdong Fine Point Data Polytron Technologies Inc,Guangzhou 510630)
It's an emphasis to make data classification more accurate in classifying data,when we do research in the loss of telecom users.It's easier to mark the loss of users,but the users not yet lost don't mean that the user does not leak,when studying telecom user loss.So it's not an ac⁃curate classification of 2 negative samples,uses One Class SVM to extract the unknown sample density higher part as a true negative sam⁃ple,the source data is divided into positive samples and negative samples with unknown samples of three parts,for the future study.
机器学习;One Class SVM
天河区科技计划项目(No.201502YH019)
1007-1423(2017)29-0032-03
10.3969/j.issn.1007-1423.2017.29.008
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
电子产品世界(2022年4期)2022-04-21
消费电子(2021年6期)2021-07-17
计算机系统应用(2021年2期)2021-02-23
求知导刊(2019年17期)2019-10-18
小型微型计算机系统(2018年8期)2018-09-07
环球市场信息导报(2017年36期)2017-12-24
电子技术与软件工程(2017年14期)2017-09-08
阅读(中年级)(2016年4期)2016-11-19
科技视界(2015年24期)2015-08-22
