
公共自行车系统的租赁点聚类与功能识别
2018-01-19 00:54,
计算机工程 2018年1期
,
(杭州电子科技大学 计算机应用技术研究所,杭州 310018)
0 概述
公共自行车系统(Public Bicycle System,PBS)具有便捷、可达性高、收费低廉、低碳环保等特征,是公共交通系统中的重要组成部分。随着公共自行车系统的普及和发展,现已积累了越来越多的使用数据。公共自行车系统的使用记录数据蕴含了丰富的人群移动信息,但这些数据具有规模庞大、多维度等特征,对其进行特征提取和知识获取非常困难。在系统中,租赁点所具有的功能和城市的区域功能具有相似性,都是用户为满足某个目的在空间和时间上进行聚集。
开展城市区域功能发现是一项繁重的任务,而公共自行车系统的使用用户只是城市中的小部分居民,通过这些数据进行城市功能区域发现准确率较低。为此,本文构建一种公共自行车系统的租赁点聚类模型,根据系统所积累的历史使用数据对租赁点进行功能聚类,识别租赁点的使用模式,以便于系统管理者进行车站平衡调度和新租赁点部署等操作。首先使用潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)模型对公共自行车系统进行租赁点功能特征挖掘,然后通过K-means算法进行特征聚类,最后采用兴趣点(Point of Interest,POI)数据和租赁点名称信息对结果进行验证。
1 相关工作
城市土地利用分析作为交通规划的重要组成部分,可以帮助交通规划者了解交通移动在使用空间上的影响[1],可用来定义城市中的居民对土地的使用,例如把城市分为住宅区、商业区和休闲区等。传统的城市区域功能发现方法是通过实地调查、问卷、检查建筑物数据的方式,这样不仅浪费时间和金钱,而且所得到的结果是粗粒度的[2-4]。
近年来,随着感知技术和计算环境的成熟,各种大数据在城市里悄然而生,如交通流、气象数据、道路网、兴趣点、移动轨迹和社交媒体等[5],越来越多的研究通过人群移动和活动模式实现城市区域功能发现:文献[6]采用地图分割算法把城市分割成若干区域,使用LDA算法分析城市中不同的功能区域以及每种功能的核心所在;文献[7]采用具有噪声的基于密度的聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)方法识别城市的功能区域。
随着公共自行车需求的日益增加,越来越多的研究从不同角度来提高公共自行车系统的性能:文献[8]和文献[9]分别从静态重分配和动态重分配2种调度类型出发进行系统自行车调度的最优化策略研究;文献[10]提出一种基于统计模型对公共自行车系统租赁点进行分析的方法;文献[11]对北爱尔兰的公共自行车系统进行分析,发现租赁点有工作日通勤模式和以休闲区域为中心的非工作日休闲旅行模式;文献[12]将出租车数据、天气信息和空间变量作为协变量,使用回归模型对公共自行车的使用量进行预测分析;文献[13]通过泊松分布模型、神经网络模型和马尔科夫链模型分别进行预测分析并比较结果。
2 华盛顿公共自行车租赁系统及数据
本文所研究的对象为华盛顿哥伦比亚特区的公共自行车租赁系统,所采用的数据均可以在华盛顿公共自行车网站上获取。
2.1 租赁点数据
华盛顿公共自行车租赁系统在美国迅速地发展,2008年有120辆公共自行车和10个租赁点,2014年达到3 171辆公共自行车和341个租赁点。租赁点的详细数据包含租赁点编号、经纬度、自行车容量、停车槽数。
2.2 使用记录数据
用户通过刷卡来使用公共自行车,卡片记录了用户的移动信息:借车站点,还车站点,使用时长,借车时刻,还车时刻,用户类型。经过数据清洗的历史使用数据信息如表1所示。
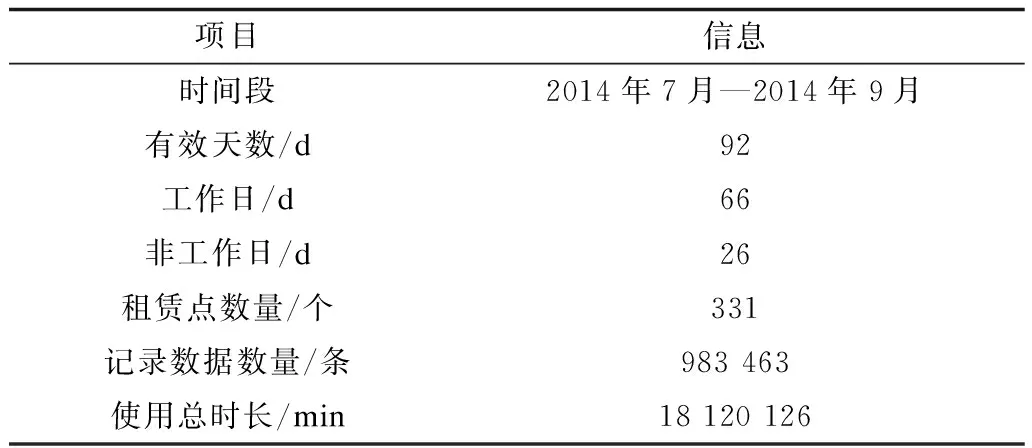
表1 历史使用数据信息
3 本文方法
本文首先利用车站位置信息,采用泰森多边形算法对城市进行区域划分,然后将公共自行车系统的使用历史记录转换为区域的组成“单词”,分别使用LDA算法[14]和K-means算法[15]对公共自行车系统进行租赁点聚类与功能识别,最后对每个聚类结果进行时空特征分析,采用POI数据和租赁点名称信息,通过TF-IDF(Term Frequency-Inverse Document Frequency)[16]方法进行结果验证。
3.1 数据定义
3.1.1 用户使用数据定义及处理
每个乘客的一次出行产生一条记录,这些记录构成了用户使用记录数据集,本文定义记录格式如式(1)所示。
U=(U.sO,U.tO,U.sD,U.tD)
(1)
其中:U.sO表示借车站点;U.tO表示借车时刻;U.sD表示还车站点;U.tD表示还车时刻。每条这样的OD(Origin-Destination)记录由空间属性和时间属性组成。
3.1.2 用户出行模式
由BSS的用户使用数据可以得出用户的出行模式,共有2种客流模式:租借模式和归还模式,本文分别定义为MO和MD。
MO=(U.sO,U.sD,U.tO)
(2)
MD=(U.sO,U.sD,U.tD)
(3)
3.1.3 租赁点使用模式
租赁点的使用模式不仅反映了用户在不同时间段内的使用规律,而且还反映了其和其他租赁点的移动关系。与用户出行模式类似,租赁点的使用模式也有2种,分别为租借模式和归还模式,本文分别定义为XSO和XSD:
XSO=(CO1,CO2,…,COs,…,COS)
(4)
XSD=(CD1,CD2,…,CDs,…,CDS)
(5)
其中,COs为在编号为s的租赁点发生租借行为的所有记录,它是一个S×T矩阵。
COs=‖{MO=(x,y,z)|x=s,y=i,z=k}‖
(6)
COs表示在时间点(1,2,…,k,…,T),从编号为s的租赁点借车,到编号为(1,2,…,i,…,S)的租赁点还车发生的记录统计量;同理,CDs为在编号为s的租赁点发生还车行为的所有记录,它是一个S×T矩阵。
CDs=‖{MD=(x,y,z)|x=s,y=i,z=k}‖
(7)
3.2 公共自行车系统在LDA模型中的类比
本文对公共自行车的使用记录数据和文档主题模型使用的文档数据做类比,如图1所示。具体而言:可以将每一个租赁点看作一个文档,租赁点对应的区域功能视作文档的主题,租赁点的使用模式相当于组成每篇文档的单词。如同每篇文档一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到,租赁点的用户出行模式也可以推导出租赁点所在区域的功能。
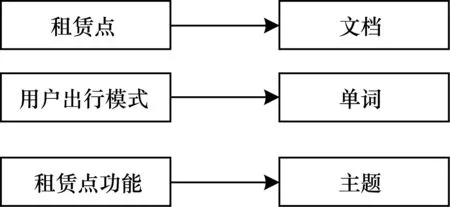
图1 租赁点区域-功能与文档-主题的类比图
公共自行车系统共有S个租赁点,因此,本文研究的文档个数也为S篇。根据租赁点的使用模式向量XSO和XSD,可以得出任意一个租赁点的组成内容为Cs=(WOs,WDs)。
以编号为i的租赁点为例来说明一篇文档的单词的计算过程:定义单词为WOi=COi和WDi=CDi。单词的生成示意图如图2所示。其中,横轴为时间,纵轴为租赁点编号。在时刻t(1,2,…,t,…,T)时,从编号为i的租赁点借车去到租赁点编号为s(1,2,…,s…,S)的租赁点还车的记录有M条,表示租赁点有M个这样的单词,同时“还车”类型单词也是相同计算方法。
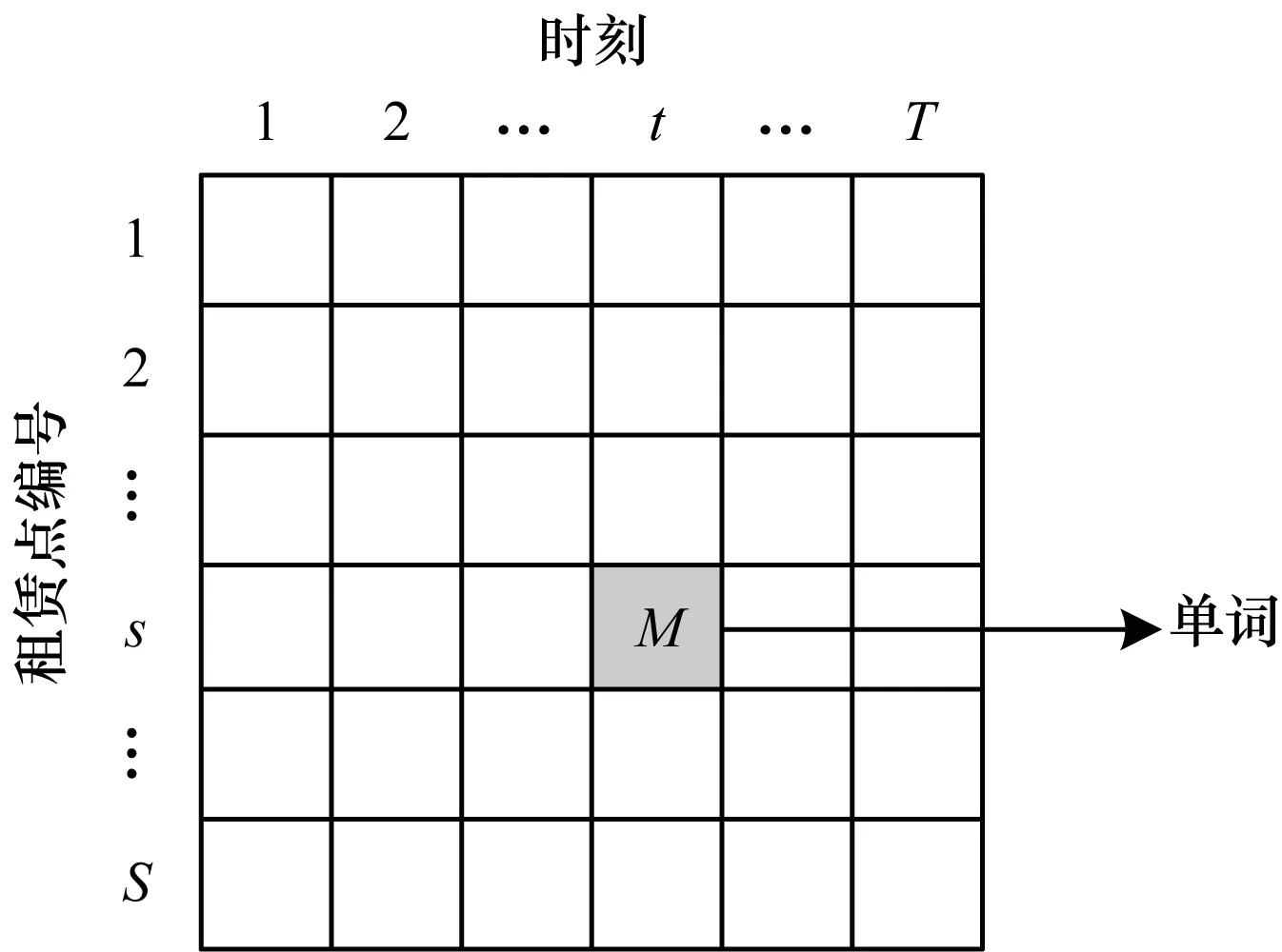
图2 用户出行模式转化为“单词”的过程
3.3 算法实现
本文使用LDA模型对租赁点所在区域进行功能挖掘,图3为得到的概率图模型,其中:α为每个租赁点的主题分布的先验分布Dirichlet分布的参数;β为每个主题的词分布的先验分布Dirichlet分布的参数;S为租赁点的总数;K为租赁点所具有的功能数;θs是一个s×k矩阵,代表第s个租赁点的主题分布;Ns表示租赁点s有Ns个单词;zs,n表示该单词(租赁点s第n个单词)被赋予的租赁点功能;φk是一个s×k矩阵,代表编号为k的主题上的词分布;w是通过人群移动转化的单词。
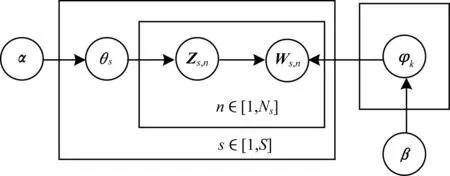
图3 主题模型概率图模型
LDA算法具体过程如下:
1)对于所有的功能数k∈[1,k]:生成φk,φk~Dir(β)。
2)对于所有的租赁点s∈[1,S]:生成租赁点-功能分布θs,θs~Dir(α);生成租赁点的长度Ns,Ns~poiss(ξ)。
3)对于任意一个租赁点的单词n∈[1,Ns]:生成单词所对应的功能Zs,n~Mult(θs);生成该功能对应的单词Ws,n~Mult(φZs,n)。
本文使用Java编写LDA算法,工程的核心文件为LdaModel.java和LdaGibbsSampling.java。算法运行结束后,将LDA主题模型得到的文档在每一主题上的概率分布作为文档的特征值,采用K-means聚类算法对不同的文档进行聚类。
4 聚类结果分析及验证
表2是主题发现产生的结果统计,图4则展示了所有租赁点在地图上的分布,其中,C1~C7区域表示公共自行车系统各租赁点的聚类结果。由表2和图4可以看出,C3、C4、C5每个租赁点的使用频次比较多,并且3个集群位于城市的中心地带,因此,这3个集群站点可能是将所有租赁点联系起来的核心租赁点,对于一个城市来说,商业区、住宅区、文化区构成了城市的必要组成部分,很有可能这3个聚类属于这几个功能;C1、C2则处于城市的边缘地带,同时根据表2得到平均每个租赁点的使用频次也相对较低;C6与C3和C4相邻,C6集群里面包含较多的站点,并且总共使用的频次较高。每个分为相同类的租赁点的地理位置也比较接近,这种现象也说明了公共自行车租赁点的使用受到空间影响。
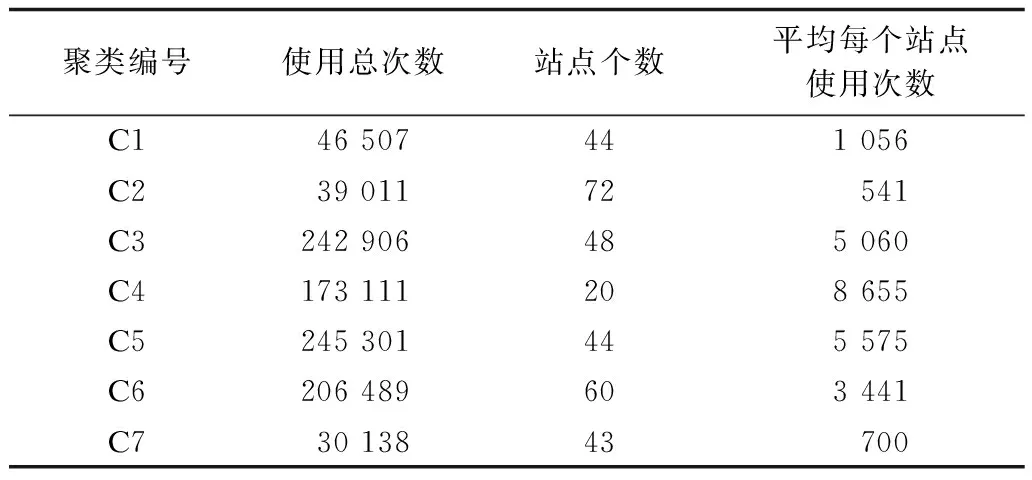
表2 聚类站点信息
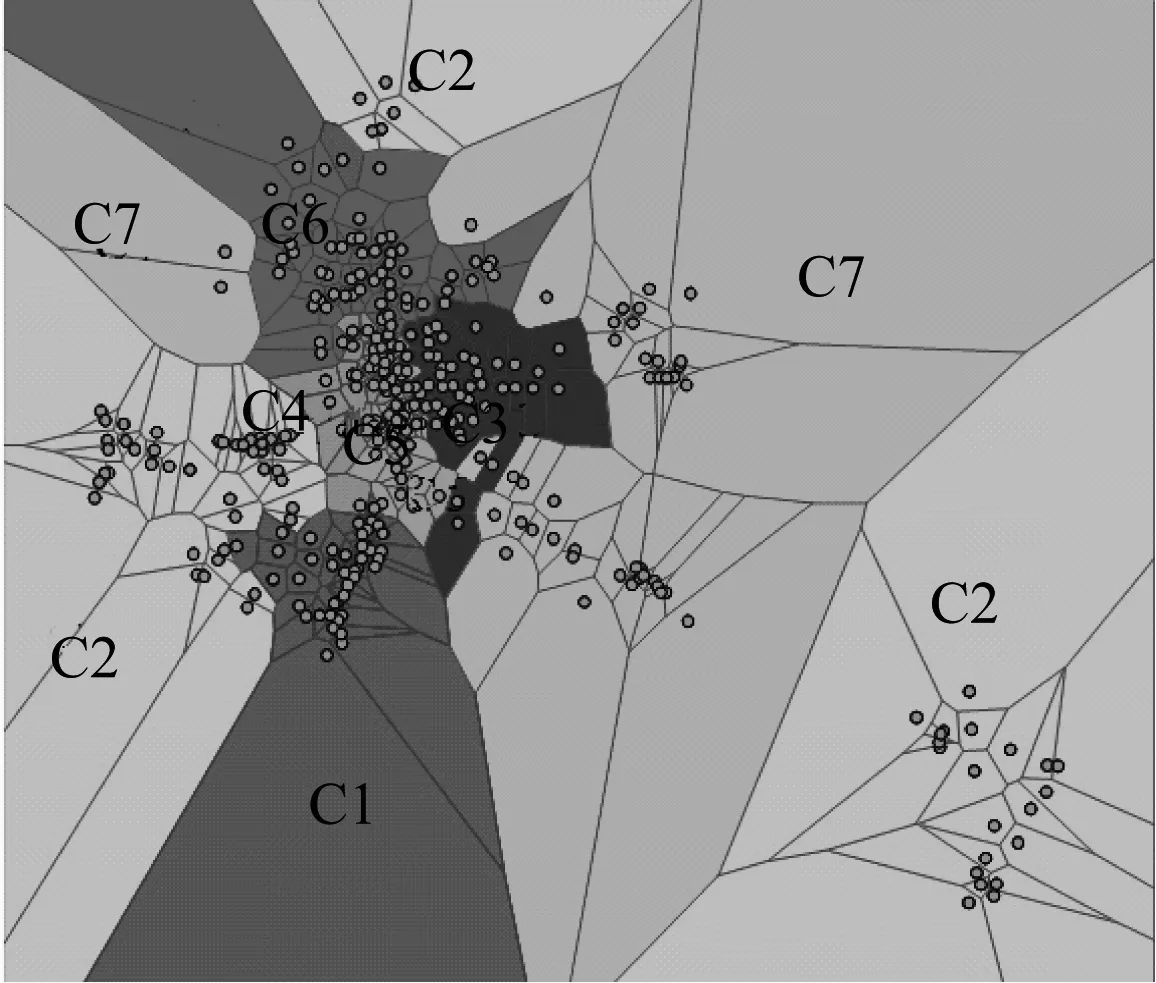
图4 聚类结果分布
4.1 整体聚类特点分析
图5为不同聚类集群中的移动频次统计图,横轴为借车聚类编号(C1~C7),纵轴为还车聚类编号(C1~C7)。从图5可以得出每个聚类集群的客流主要来自于其本身集群,这是因为公共自行车系统是公共交通系统中的毛细血管,它提供“门到门”服务,有效满足短距离出行的需求,所以在自身集群中发生的使用频次较多;C1、C2、C7仅在本区域中的用户移动频率较明显,而其余几个聚类集群则相互频繁流通。本文根据各个聚类在不同用户和不同时刻的使用特征对7类聚类进行命名,如表3所示。

图5 不同聚类集群中的移动频次
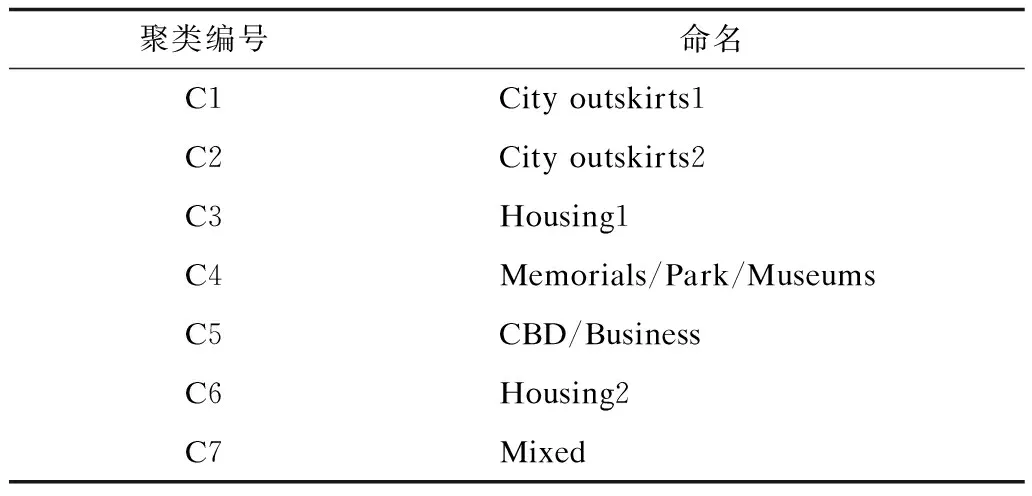
聚类编号命名C1Cityoutskirts1C2Cityoutskirts2C3Housing1C4Memorials/Park/MuseumsC5CBD/BusinessC6Housing2C7Mixed
4.2 不同集群特点分析
将C4命名为Memorials/Park/Museums,是因为本文对其1 d客流模式进行分析,由图6所示的C4不同时段借车客流模式图,发现其呈现出“单峰”状态,并且非工作日的使用量要多于工作日的使用量,这说明C4租赁点所在区域呈现的功能是景区。
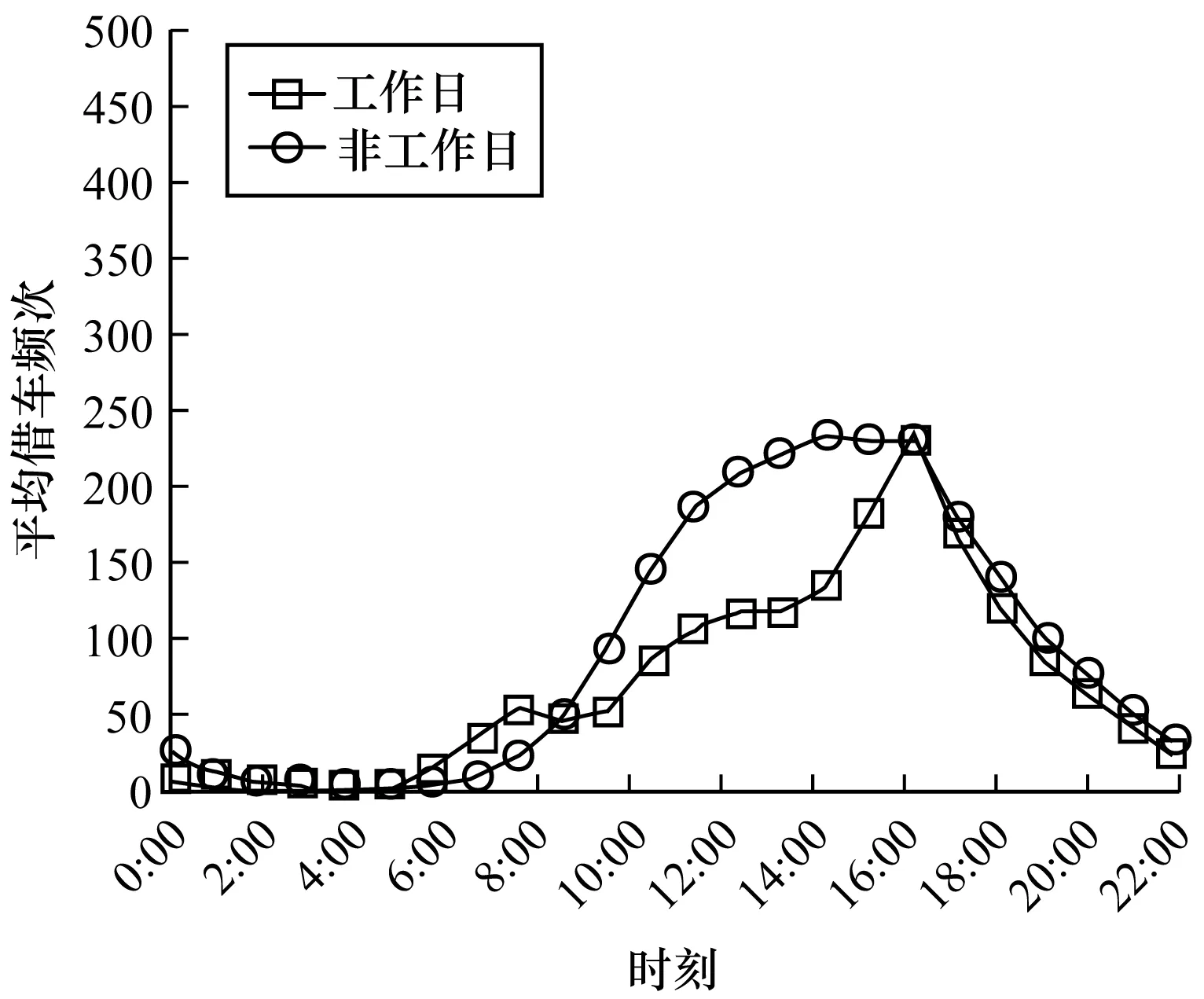
图6 C4不同时段借车客流模式图
本文同时分析C4车站的不同用户类型在92 d内的使用特征,如图7所示,可以发现该集群内的非注册用户的使用量要大于注册用户的使用量,这也进一步说明C4中的租赁点所呈现的功能是风景区。通过图5所示的流动图,可以得出C4在本身区域发生的租借行为较多,这是因为公共自行车在景区有着很大的便利性,大多数用户借到自行车之后,在各个景点之间进行骑行,这样不仅可以节省时间和体力,也能更好地进行游玩,同时C4、C5、C6联系比较紧密。
对C3 1 d客流模式进行分析,结果如图8所示。其中工作日呈现出明显的“双峰”现象,借车和还车的客流模式则呈现相反现象,这种现象非常符合人们的日常行为:早上从生活区到工作区上班,晚上则从工作区返回生活区;而在非工作日时,则没有这样的客流模式,并且可以看出,在非工作日用户的夜间活动明显增加。
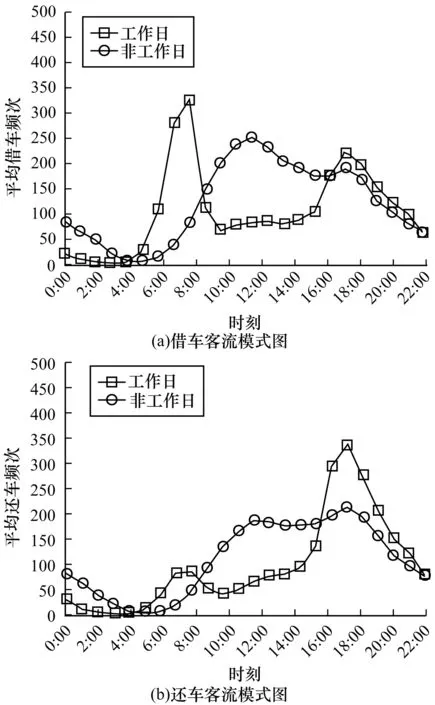
图8 C3不同时段客流模式图
C6的借还特征和C3很相似,但又有所不同,如图5所示,由于C6其他几个集群的的联系性比较大,因此,笔者猜测C6可能是居住和商业混合区。图9所示为C6不同时段客流模式图(图9(a)为借车模式,图9(b)为还车模式),其中工作日呈现出和C3相似的特性,不同之处在于早晚高峰C3还车频次和借车频次差距比C6较大。
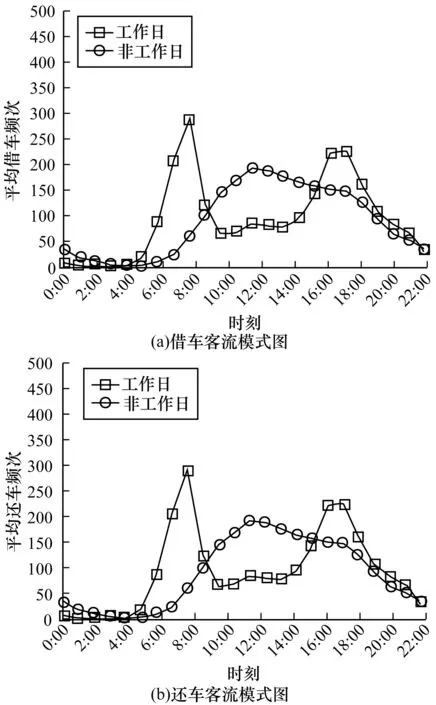
图9 C6不同时段客流模式图
从图10不同时段客流模式图可以得出C5在工作日呈现“双峰”,并且C5的客流模式与C3和C6呈现相反的特征:早高峰借车数较少而晚高峰借车数较高。从图5同样可得出C5除了与自身区域发生的借还频次较多外,与C3、C4、C6的关系也很紧密:在工作日的晚高峰时,多数用户从C5借车还车到C3和C6,而在早高峰,多数用户从C3和C6借车,还到C5。可以利用工作区和居住区这种相反使用特征去指导公共自行车系统的自行车重分配策略,使得公共自行车系统的使用率达到平衡,减少公共自行车系统出现“无车可借”“无桩可还”的情况。
从地图上可以看出C1和C2分布在城市的外围,将其命名为和City outskirts2,同样对其进行不同时刻的使用特征分析。图11(a)和图11(b)分别为C1和C2不同时间借车的客流模式图,从图中可以得出这两类的站点使用在工作日都呈现“双峰”特性,非工作日则为“单峰”特性。
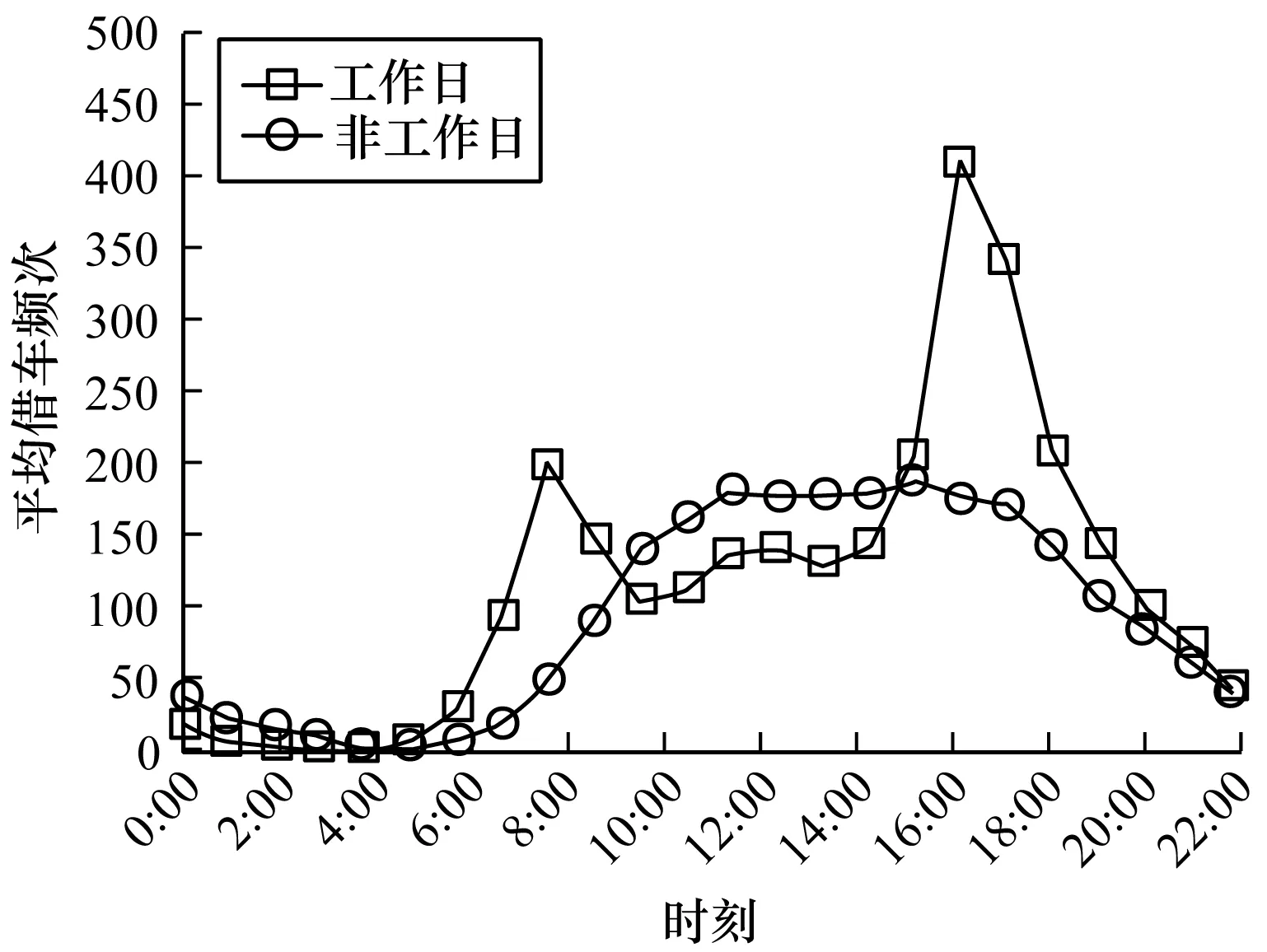
图10 C5不同时段借车客流模式图
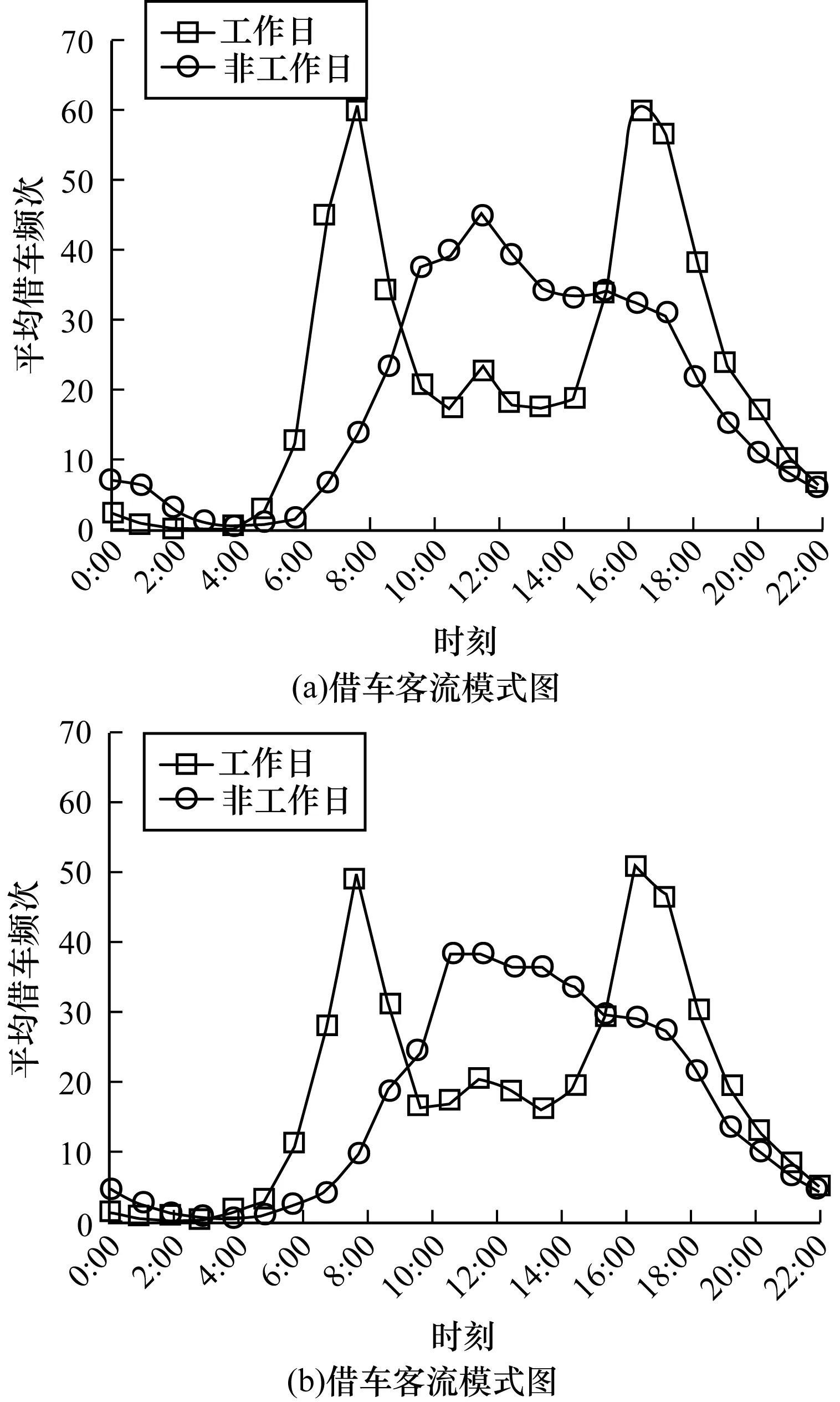
图11 C1和C2不同时段借车客流模式图
最后对C7进行分析,类似地做出其不同时段客流模式图和不同集群之间的客流模式图(分别为图12和图13)。图12表明,属于C7的租赁点工作日和非工作日呈现出不同的特性,并且通过观察图13可以得出:C7和C3、C5之间关系较紧密,它们之间发生借还频次较高的时间段为一天之中的早高峰和晚高峰,据此,判断C7为一个混合区域,也就是说该区域为工业、商业、住宅混合在一起,下文会进一步对结果进行证明。
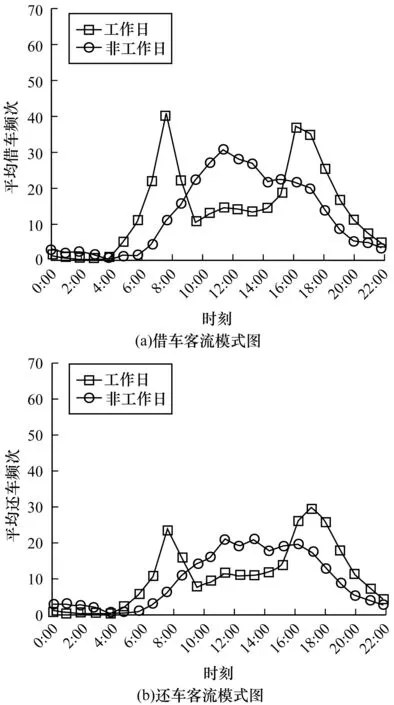
图12 C7不同时段的客流模式图
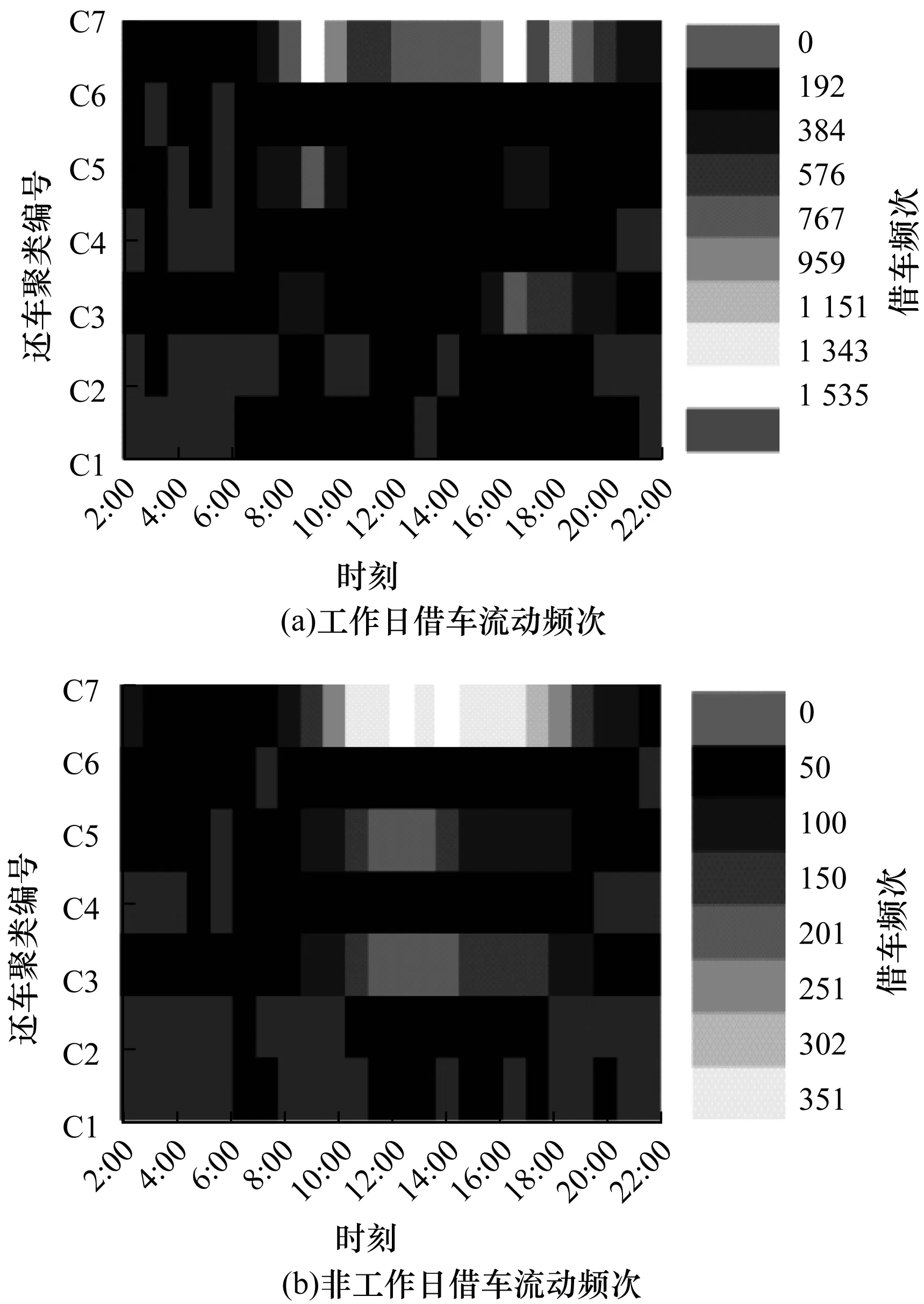
图13 C7借车流动频次
4.3 POI数据和租赁点名称数据验证
POI数据的分布在一定程度上可以反映某类地物的分布,因此,可以通过对POI数据的分析挖掘某类地物的分布规律和特点,为本文的聚类验证进一步研究提供依据。本文共获取51种POI数据,为了验证方便,把这51种POI又划分为6类。对于任意租赁点Si,都可以求出向量POI-Si(P1,P2,…,Pp,…,Pn),Pp为租赁点i的第p类POI的TF-IDF值:
(8)
其中,np为租赁点i的第p类POI的数量,Ni为租赁点i拥有的POI的数量,S为所有的租赁点总个数,‖Si|thep-thPOI∈Si‖为第p类POI出现在不同租赁点的数量。
进一步可求得集群的POI分布POI-Cc(P1,P2,…,Pp,…Pn),求解公式如下:
(9)
计算的结果如表4所示。C4区域内的文化类(包含景点、公园、博物馆等)POI值较之其他集群为最大,说明C4集群内的车站大多数位于娱乐休闲中心和景点周边。例如美国著名的景点:“白宫”“杰弗逊纪念堂”“肯尼迪中心”等;住宅区是城市最大、最基础的功能区,其他功能区的布局多是围绕其分布或延伸开来的,有成品住宅楼及配套的服务设备,与企业相邻或成片规划建设,从表4中可以看出C3和C6的住宅、商业、购物的值和其他集群比较而言,值较高而且分布均匀。C3和C6主要的区别在于:C3为比较成熟的住宅区;C6为住宅区与商业区的混合;C5的商业、停车场、出租屋、酒店以及通勤类型的POI较多;C1和C2的POI分布最多的为公寓,其次为车站和地铁。城市混合功能区是指:在这个区域内,工业、商业、住宅混合在一起,是多用途功能区,在这个区域里面,既有办公楼群,也有住宅、餐馆、购物中心和文化设施等。观察其POI分布,可以发现区域内分布较靠前的为房屋出租、公寓、商业、公司类型的POI,在C7里分布的居民房和停车场也比较多。
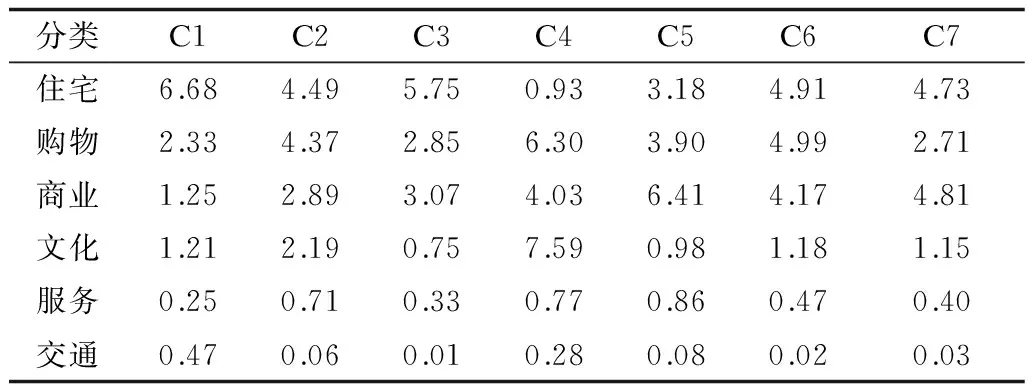
表4 POI分布
车站的记录信息不仅包含车站的具体位置信息(经、纬度),还包含其名字,这个名字类似于上文所使用的POI名称信息,所以,一个车站的名字也在某种程度上可以反映这个车站所具有的功能,例如,处于C4里面的租赁点名称为Lincoln Memorial,它的使用频次在所有租赁点为首位,其位于林肯纪念馆附近,用户使用该租赁点的目的很明显,是为了更好地去欣赏风景和游玩。所以,采用相似的办法对车站名称进行处理分析,经过处理分析可以得出以下结果:C4中车站名字词项频次比重排名靠前的为Jefferson、Construction、Memorial、Lincoln;C3和C6中车站名字词项频次比重排名靠前的为Columbia、Station、Capitol、Market;C5中车站名字词项频次比重排名靠前的为DuPont、Pennsylvania、Georgetown;C1和C2中车站名字词项频次比重排名靠前的为Wilson、Metro、Memorial;C7中车站名字词项频次比重排名靠前的为Connecticut、Zoo、Metro,上述结果在一定程度上证明了本文结论。
5 结束语
本文以公共自行车的OD记录数据为研究对象,使用LDA模型和K-means聚类算法对公共自行车系统进行租赁点聚类分析和功能识别,并将华盛顿哥伦比亚特区公共自行车系统作为实例进行实验分析。基于集群模式特征分析、POI数据和租赁点名字数据的验证结果表明,该模型可以实现城市公共自行车系统租赁点的功能识别。下一步将利用实验结果对公共自行车系统进行自行车需求预测,同时解决聚类区域间的自行车调度问题。
[1] 王静远,李 超,熊 璋,等.以数据为中心的智慧城市研究综述[J].计算机研究与发展,2015,51(2):239-259.
[2] PUISSANT A,HIRSCH J,WEBER C.The Utility of Texture Analysis to Improve Per-pixel Classification for High to Very High Spatial Resolution Imagery[J].International Journal of Remote Sensing,2005,26(4):733-745.
[3] YANG X,LO C P.Using a Time Series of Satellite Imagery to Detect Land Use and Land Cover Changes in the Atlanta,Georgia Metropolitan Area[J].International Journal of Remote Sensing,2002,23(9):1775-1798.
[4] CARLEER A P,WOLFF E.Urban Land Cover Multi-level Region-based Classification of VHR Data by Selecting Relevant Features[J].International Journal of Remote Sensing,2006,27(6):1035-1051.
[5] 郑 宇.城市计算概述[J].武汉大学学报(信息科学版),2015,40(1):1-13.
[6] YUAN J,ZHENG Y,XIE X.Discovering Regions of Different Functions in a City Using Human Mobility and POIs[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2012:186-194.
[7] PAN G,QI G,WU Z,et al.Land-use Classification Using Taxi GPS Traces[J].IEEE Transactions on Intelligent Transportation Systems,2013,14(1):113-123.
[8] RAVIV T,TZUR M,FORMA I A.Static Repositioning in a Bike-sharing System:Models and Solution App-roaches[J].EURO Journal on Transportation and Logistics,2013,2(3):187-229.
[9] CAGGIANI L,OTTOMANELLI M.A Dynamic Simulation Based Model for Optimal Fleet Repositioning in Bike-sharing Systems[J].Procedia-Social and Behavioral Sciences,2013,87:203-210.
[10] COME E,OUKHELLOU L.Model-based Count Series Clustering for Bike Sharing System Usage Mining:A Case Study with the Velib’System of Paris[J].ACM Transactions on Intelligent Systems and Technology,2014,5(3):1-28.
[11] DAVIS A W,LEE J H,GOULIAS K G.Analyzing Bay Area Bikeshare Usage in Space and Time[C]//Proceedings of the 94th Annual Meeting of Transportation Research Board.Santa Barbara,USA:[s.n.],2015:1-19.
[12] SINGHVI D,SINGHVI S,FRAZIER P I,et al.Predicting Bike Usage for New York City’s Bike Sharing System[C]//Proceedings of the 29th AAAI Conference on Artificial Intelligence.[S.l.]:AAAI,2015:1-5.
[13] LEE C,WANG D,WONG A.Forecasting Utilization in City Bike-Share Program[EB/OL].[2016-10-30].http://cs229.stanford.edu/proj2014/Christina Lee,David Wang,Adeline Wong,Forecasting Utilization in City Bike-Share Program.pdf.
[14] BLEI D M,NG A Y,JORDAN M I.Latent Dirichlet Allocation[J].The Journal of Machine Learning Research,2003,3:993-1022.
[15] HARTIGAN J A,WONG M A.Algorithm AS 136:A k-means Clustering Algorithm[J].Journal of the Royal Statistical Society,Series C(Applied Statistics),1979,28(1):100-108.
[16] SALTON G,McGILL M J.Introduction to Modern Information Retrieval[M].New York,USA:McGraw-Hill,Inc.,1986.
猜你喜欢
环球时报(2022-12-12)2022-12-12
科学家(2021年24期)2021-04-25
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
汽车与驾驶维修(汽车版)(2017年1期)2017-10-30
中国公共安全(2017年5期)2017-09-04
中国交通信息化(2017年3期)2017-06-08
汽车与驾驶维修(汽车版)(2017年1期)2017-02-22
知识就是力量(2017年2期)2017-01-21
棋艺(2016年6期)2016-11-14
