
一种个性化(p,k)匿名隐私保护算法
2018-01-19 00:54,
计算机工程 2018年1期
,
(西北师范大学 计算机科学与工程学院,兰州 730070)
0 概述
在信息发达的当代,人类大量个人信息被政府部门、商业机构等存储、发布,这极大地激发了各部门从海量数据中挖掘有用信息的需求[1]。数据挖掘在用于公开分析大量的私人信息时,如在医疗记录、人口普查中,若公开某位病人的患病情况,或者公开个人的婚姻状况等这些敏感信息,将会对个人隐私构成威胁。因此,个体隐私信息的安全性问题在数据挖掘的研究中显得尤为重要。个体隐私信息的保护技术主要分为3类[2]:数据加密,数据失真,数据匿名化。其中,数据加密的安全性最高,对信息的有用性破坏较大,数据失真在给数据添加噪声的同时仍需保持数据基本性质不变,降低了可用信息的数量,因此,通常采用数据匿名技术实现隐私保护,既保证数据的有用性,同时又能兼顾数据的隐私性。
文献[3]建立了k匿名模型,要求发布数据中的每个元组至少有(k-1)个与其相同的元组。k匿名模型能有效地解决标志泄露问题,但对于敏感属性泄露问题并没有相应的保护机制[4],无法达到保护隐私的目的。之后文献[5-6]建立了p-sensitive k匿名模型,要求在满足k匿名的同时,在每个等价类中敏感属性至少有p个不同的值,这对敏感属性起到一定的保护作用。
然而在日常生活中,相同的敏感属性针对不同的个体敏感程度也不尽相同,需要针对个体的差异对敏感属性实施个性化保护[7]。文献[8]提出自顶向下个性化泛化回溯,动态构建泛化树,有效抵制了同质攻击和背景知识攻击。文献[9-10]皆是提出一种基于k匿名的个性化匿名算法,其中文献[9]算法增加匿名群记忆模块,以此加快匿名的速度,文献[10]根据个人隐私自治原则提出基于局部编码和敏感属性泛化的个性化k匿名算法。文献[11]建立基于(α,k)个性化匿名模型,通过设置等价类中敏感值出现的频率来实现个性化保护。由此可见,针对个体差异的个性化保护越来越受到关注和重视。通常敏感属性的保护方式分为2种:一种是对不同的敏感属性设置不同的阈值,敏感程度较高的阈值较小;另一种保护方式是对敏感属性泛化,用精度较低的敏感属性值取代原值。文献[12-13]运用前者提出敏感属性划分泛化的策略,对不同的敏感属性设置不同的级别。之后,文献[14-15]提出基于L多样性的个性化匿名模型,同样提到设置参数∂实现分级别保护。文献[16]方法在p-sensitive k匿名模型的基础下为敏感属性设置不同的阈值,实现个性化保护。
本文基于p-sensitive k匿名模型提出针对敏感属性的个性化隐私保护算法,通过建立敏感属性泛化树,根据个体间敏感程度的差异将敏感属性泛化到不同的层次,降低敏感属性的精度后再发布数据,以达到对敏感属性进行个性化隐私保护的目的。
1 相关概念
1.1 表属性划分
可将数据表的属性划分为3个部分:标识符属性A,准标识符属性QI和敏感属性S,其中:标识符属性是能唯一确定某个个体的属性,如身份证号;准标识符属性是指通过其与外部数据表某些属性进行链接以标识个体身份的属性,例如性别、年龄、邮编等;敏感属性是指包含个体隐私信息的属性,例如疾病、婚姻状况等。
表1为某医院电子病历,其中:“Name”为标识符属性,对表操作时应隐匿标识符属性避免严重的身份泄露[17];“Sex”“Age”“Zip code”是准标识符属性,对这些属性通过泛化可以得到匿名表;“Health condition”为敏感属性。

表1 原始数据
1.2 k匿名模型
k匿名算法[3]要求发布数据中每个等价类至少有k个不可区分的个体,使攻击者判别出所要攻击对象的概率为1/k,从而保护了个体隐私信息。k匿名算法可以有效防止链接攻击,但不能防止同质性攻击。
定义1(等价类) 对于数据表T{A1,A2,…,An}(n为属性的个数),一个等价类是指在子集{A1,A2,…,Aj}(j为子集属性的个数)上取值相同的元组的集合[17]。
定义2(k匿名) 给定数据表T{A1,A2,…,An},QI是T的准标识符,T[QI]为T在QI上的投影(元组可重复),当且仅当在T[QI]中出现的每组值至少要在T[QI]中出现k次,则T满足k匿名,记为T’[18]。
由此可知,一个数据表满足k匿名,当且仅当在准标识符上的任意一个等价类的大小至少为k。
表2为k=2时的匿名发布表,将表1中标识标识符属性姓名隐匿,避免个人身份泄露,对准标识符“Sex”“Age”“Zip code”通过泛化操作输出精度较低的值,令“Health condition”为敏感属性。
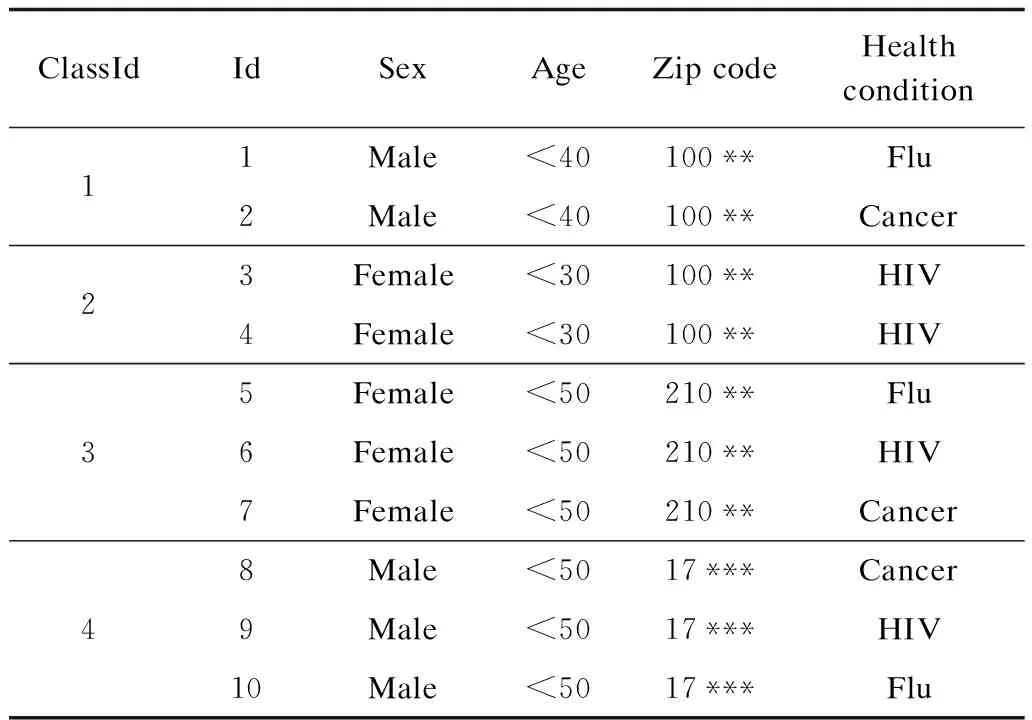
表2 2匿名数据
若攻击者事先已知Alice的年龄、邮编以及性别可推断出Alice在匿名表的第2个等价类中,攻击者可以确定Alice一定患有HIV,泄露了个人隐私。为解决该问题,使用p-sensitive k匿名算法,在该算法中要求每个等价类中至少有p个不同的敏感属性。
1.3 p-senstitive k匿名模型
定义3((p,k)匿名) 给定数据集T’满足k匿名,对于每个等价类中至少有p个不相同的敏感属性值且p≤k[16]。
运用(p,k)匿名算法(p=2,k=3)得到表3。其中,类标号相同的元组属于一个等价类,由此可知,前4条元组是一个等价类,第5条~第7条元组是一个等价类,第8条~第10条元组是一个等价类。在3个等价类中,任意一个等价类中的敏感属性取值至少为p=2。
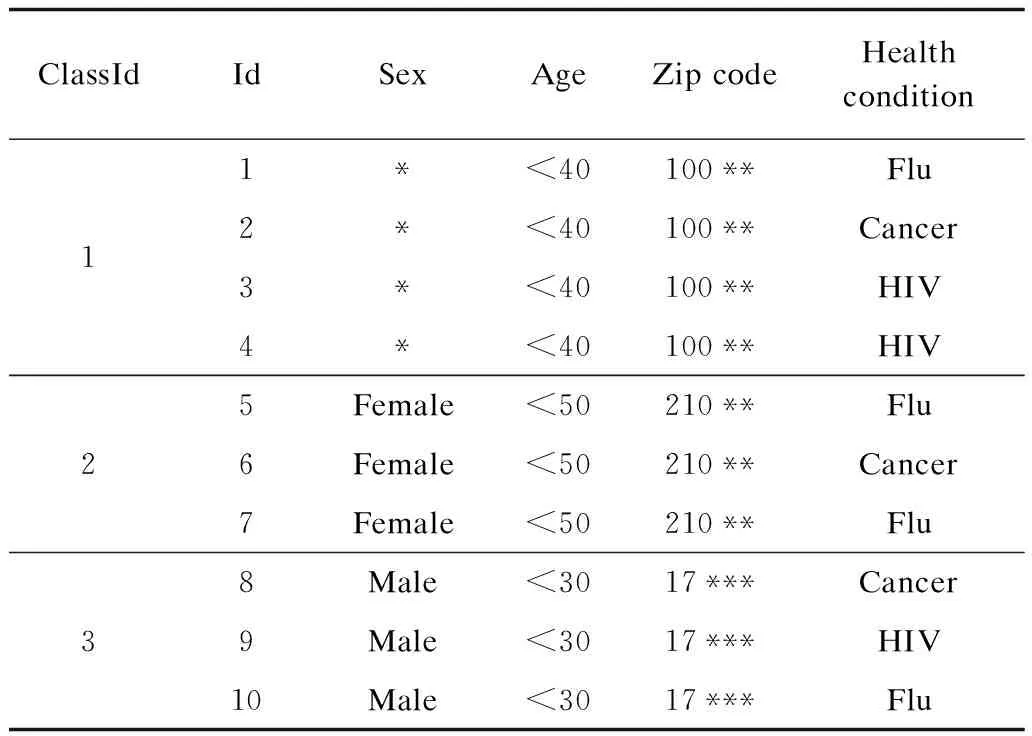
表3 (3,3)匿名数据
2 个性化p-sensitive k匿名相关定义
k匿名模型能有效防止链接攻击,但不能解决敏感属性的保护问题,p-sensitive k匿名要求在每个等价类中至少有p个不相同的敏感属性值,虽在一定程度上保护了敏感属性,但是未考虑敏感属性的敏感程度问题。表2中敏感属性取值为HIV,与Cancer与Flu相比,前两者更不想被他人知道,因此,对敏感属性个性化保护显得尤为重要,本文给出敏感属性泛化树的概念,实现对敏感属性的个性化保护。
2.1 敏感属性的敏感级别
本文提出用户评分机制划分敏感属性,保证敏感属性的划分更贴合实际个体的敏感信息,针对个体敏感信息的敏感程度实施分级保护。
定义4(敏感度评分) 设满分为Y,化为若干个分数区间Y{Y1,Y2,…,Yn},数据集为T,敏感属性集为S{S1,S2,…,Si,…,Sn},敏感属性取值个数为n。用户针对个人对敏感属性的敏感程度评分,分数较低的敏感属性,敏感度也较低。将评分对应于相应的分数区间Yi(1≤i≤n)中并用yi标记敏感属性的分数。
图1为某医院用户调查结果,横坐标为敏感属性疾病S的取值,分别用1~6表示Flu、Pneumonia、Fracture、Asthma、HIV、Cancer。纵坐标表示用户评分,评分系统满分为90分,划分为3个区间:[0,30]表示低敏感度;[30,60]表示中等敏感度;[60,90]表示高敏感度。根据用户评分情况,去除离群点,将6个敏感属性对应至相应的分数空间。
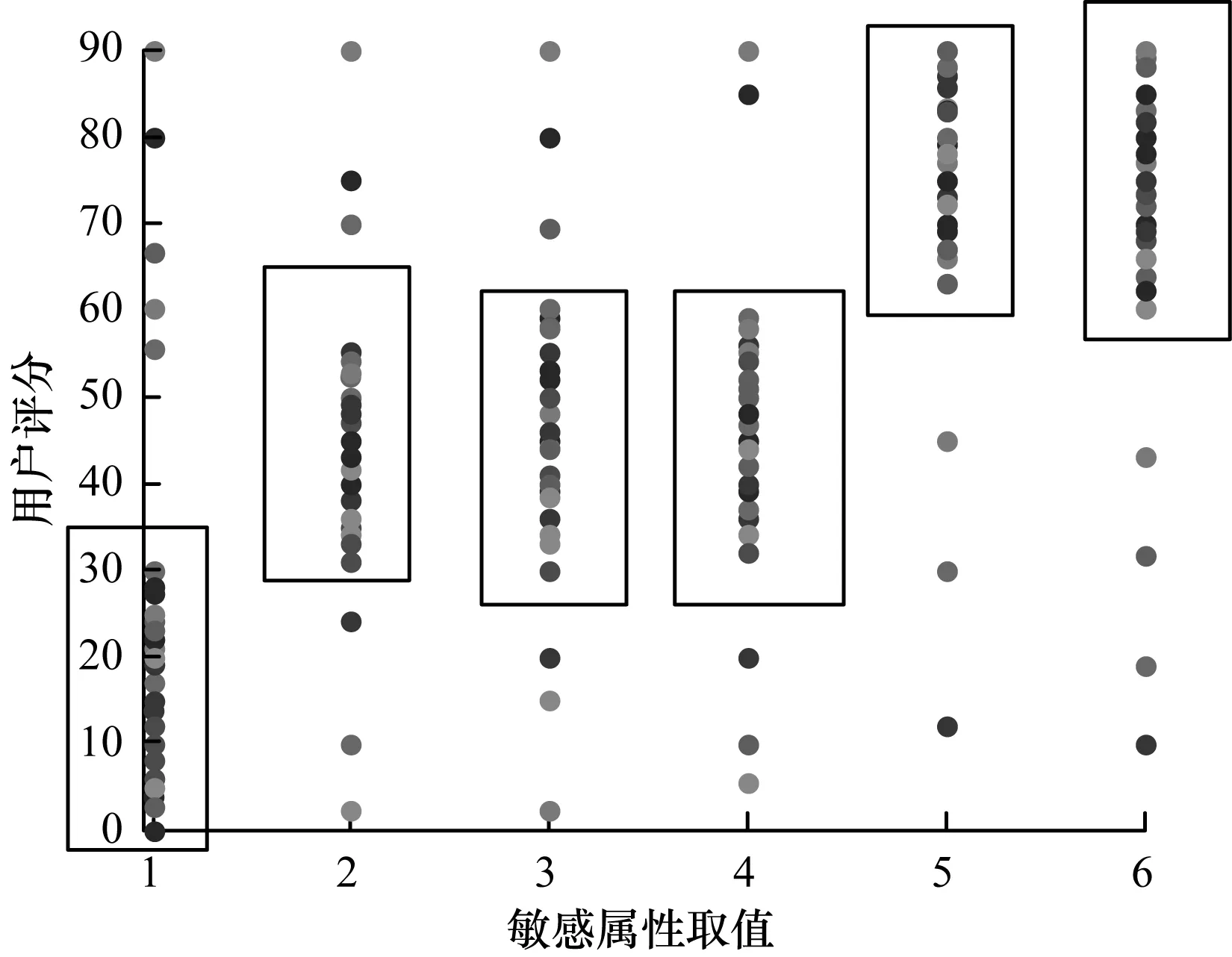
图1 敏感属性评分结果
根据图1的结果满分90分,根据用户评分结果将疾病敏感属性的敏感程度划分为3级,去掉个别离群点最终得到如表4所示的敏感属性登记表。

表4 用户评定敏感属性泛化数据表
2.2 敏感属性泛化树
根据用户评分将敏感属性划分为不同泛化,泛化较高的敏感属性,敏感信息具有较高隐私度,需要保护的程度也较高。构建一棵泛化树Q,Q的高度至少为敏感等级的个数,将敏感属性的所有取值存放在树的叶子结点中,按照敏感属性的敏感程度对敏感属性向上泛化。其中,规定最低敏感泛化的敏感属性不进行泛化,直接发布数据;其他敏感泛化的敏感属性按照其敏感度依次向上泛化,找到敏感属性的祖先结点,用祖先结点的值代替敏感属性值发布。如图2所示,敏感属性为疾病,取值为{感冒,哮喘,肺炎,骨折,烧伤}。若用户认为哮喘为中级敏感度,对敏感属性进行泛化,找到哮喘的父节点呼吸内科发布数据;若用户认为肺炎具有最高敏感度,发布数据时用根节点疾病代替肺炎。
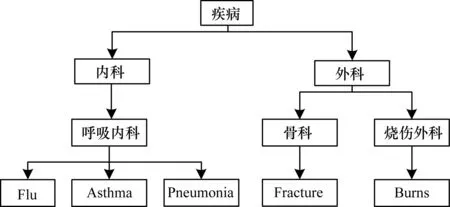
图2 敏感泛化树
2.3 精度度量
本文参考文献[19]的层次泛化的精度测量以及泛化区间的区间精度测量,无论是准标识符还是敏感属性通过泛化操作来实现匿名,必然存在信息损失,因此,给出以下相关定义。
定义5(分类型属性精度测量) 设任意不同类型的属性泛化有相同的信息损失量,若泛化树T所有的叶子节点记为M,某一个节点P所有的子树的个数记为MP,则某一属性泛化的信息损失量为:
(MP-1)/(M-1)
(1)
如图2所示,共有叶子节点5个,则M=5,由感冒泛化至呼吸内科,呼吸内科所有的子树个数为3,即MP=3,因此,由感冒泛化至呼吸内科的信息损失量为1/2。
定义6(数值型属性精度测量) 若某一数值被泛化至某一区间i中,则将这个区间的左端点标记为Li,右端点标记为Ui;该数值属性的所有区间中,最小左端点标记为L,最大右端点标记为U,则某一属性泛化至某一区间的信息损失量为:
(Ui-Li)/(U-L)
(2)
例如,属性年龄共分为3个区间,分别为[0,30]、[30,60]、[60,90],若某条记录的年龄属性为35,则泛化至第1个区间,由此可知:L2=30,U2=60,U=90,L=0,则该记录年龄属性泛化后信息损失为1/3。
3 个性化p-sensitive k匿名模型
个性化p-sensitive k匿名算法是针对敏感属性,在原有的p-sensitive k匿名的基础上,对敏感属性增加个性化保护的算法。首先用户针对个人的敏感属性对敏感度评分,用散列图表示所有用户评分结果,删除个别离群点,得到较可靠的敏感属性泛化划分结果。再根据敏感属性的泛化度构建对应的敏感属性泛化树。敏感度较高的属性值泛化的高度也较高,规定最低敏感度的敏感属性不进行泛化,直接发布数据。算法具体描述如下:
输入用户评分区间Y,待发布的(p,k)数据集T
输出个性化敏感属性匿名集T’
1.users choose merit internal
2.for data table T
3.use (p,k)anonymity
4.getT’;
5.Built a sensitive hierarchy tree A
6.for i to k{
7.If Si∈lowest sensitive degree
8.PublishT’;
9.Else Si∈other sensitive degree
10.According toA find ancestor node of Si
11.Then use ancestor node replace Si}
12.Publish T’
算法的第1步用户选择敏感属性的评分区间确定敏感属性的敏感泛化,第2步~第4步利用(p,k)匿名算法对数据集T匿名后,第5步~第11步利用敏感属性泛化树泛化每个等价类中的敏感属性,实现敏感属性个性化保护;最后发布匿名表T’,若泛化敏感属性后不满足(p,k)匿名要求,则重新划分等价类再泛化敏感属性发布。
4 实验结果与分析
实验环境:Intel Pentium 2.00 GHz CPU,2.0 GB RAM,Windows 7 旗舰版操作系统,MATLAB 7.1。编程语言为Java和MATLAB混合编程。实验所选用的数据集是Adult标准数据集,此数据集共有48 842条数据其中包括部分美国人口普查数据,去除空值后的数据有45 220条可用数据。本文选取Age、Salary、Education、Relationship、Education-num、Race、Native-country、Workclass作为准标识符,选取Marital-status作为敏感属性,取值分别为{Never-married,Married-CIV-spouse,Divorced,Married-spouse-absent,Separated,Widowed,Married-AF-spouse}。实验数据分组如表5所示,具体描述如表6所示。重复进行实验10次,取相应实验结果的平均值作为对比分析数据。
表5 实验数据分组
表6 Adult 数据集描述
实验使用以下模型进行比较:
1)k匿名模型:通过泛化构造匿名表,敏感属性不做处理;
2)个性化(α,k)匿名模型:通过设置阈值α实现对敏感属性的个性化匿名保护;
3)个性化(p,k)匿名模型:利用敏感属性泛化树实现对敏感属性的个性化匿名保护。
实验从执行时间和信息损失2个角度分析个性化(p,k)匿名模型、k匿名和个性化(α,k)匿名模型的性能。
4.1 执行时间分析
图3为准标识符个数为8个,数据集的大小为45 220,k分别取2、4、6和8时3种匿名模型的执行时间比较。由图3可知:3种模型都随着k值的增长,执行时间逐渐增大,由于个性化(α,k)匿名采用自底向上的聚类策略,当k逐渐增加时,聚类次数也逐渐变多,因此耗时比k匿名模型要多,而个性化(p,k)匿名算法则首先有用户输入评分区间,之后对敏感属性泛化实现个性化匿名,因此执行时间比较长,随着k的增长,p越容易达到,则斜率越平缓。
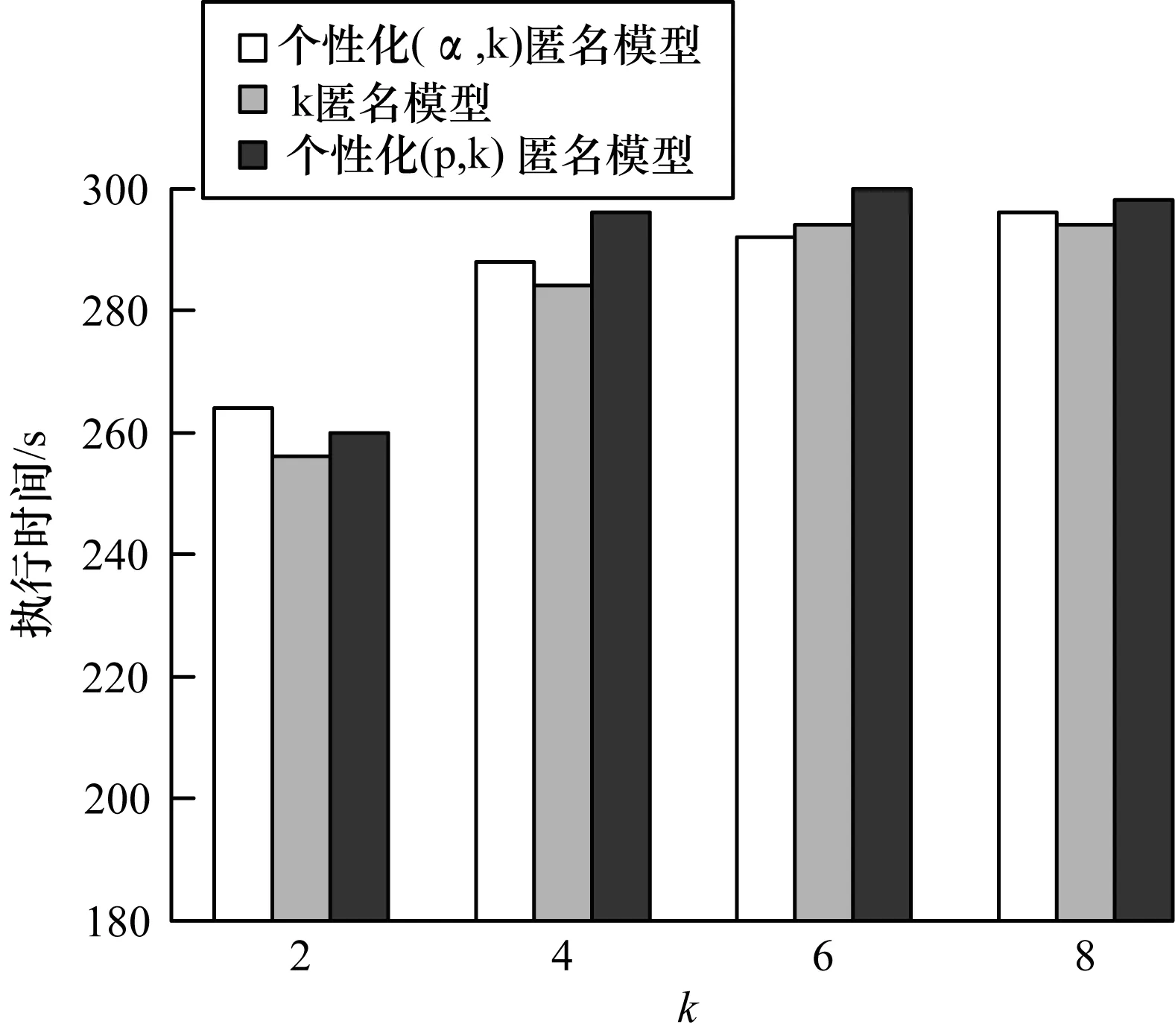
图3 执行时间对比1
图4是k取6时,改变元组个数实现3种匿名模型的执行时间对比。由图4可知:3种模型都随着添加元组个数的增加执行时间变大,因为随着数据增多,需要匿名的元组也增多,因此执行时间增大。由于添加元组数增多,个性化(p,k)匿名的k、p值并不改变,因此随着元组增多,越容易满足p值的限制,因此与个性化(p,k)匿名有相似的执行时间,个性化(p,k)匿名会得到更好的隐私保护效果。
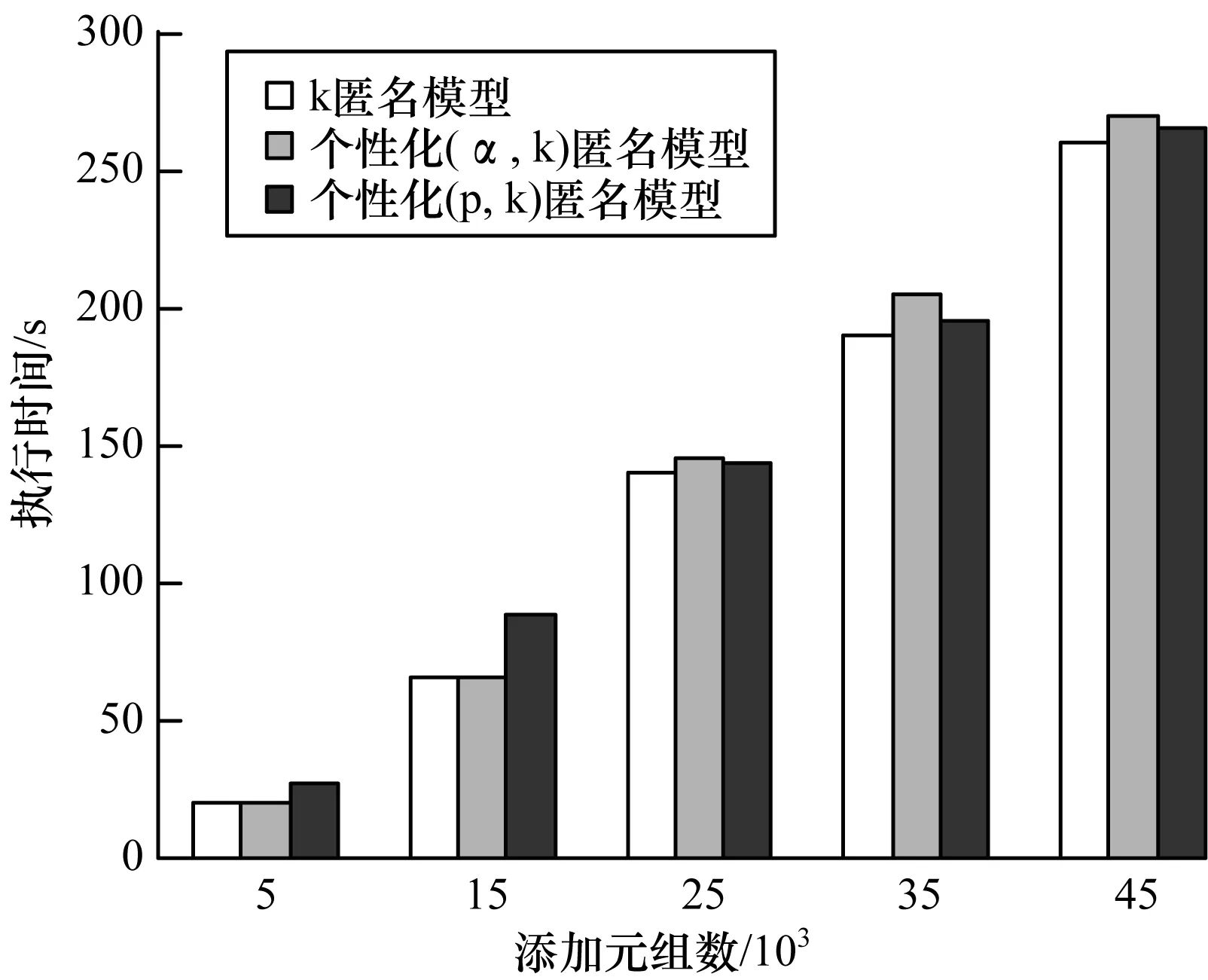
图4 执行时间对比2
4.2 精度对比
信息损失量用式(1)、式(2)来计算,图5为准标识符为6个,元组数为45 200,k取6时,3种匿名模型得到的信息损失量比较。由图5可知:3种匿名算法的精度都会随着准标识符个数的增加而降低。因为随着准标识符个数的增加,对元组匿名操作就会越复杂,损失的信息量也就越多。k匿名算法的信息损失量最少是因为它仅需要对准标识符操作,不考虑敏感属性,而个性化(α,k)匿名模型比个性化(p,k)匿名模型的信息损失量多是因为在控制敏感属性个性化时采用的方式不同。个性化(α,k)匿名模型采用设置阈值α,而个性化(p,k)匿名算法采用对敏感属性泛化的方法,因此精度损失比个性化(α,k)匿名模型多。
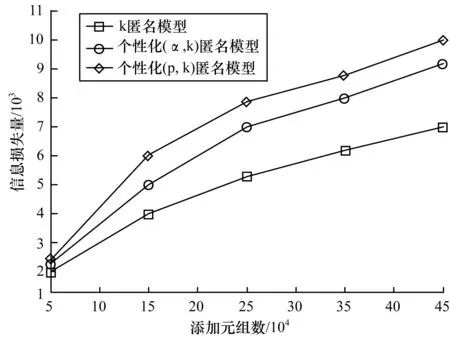
图5 信息损失量对比1
图6是在k取不同值时的精度比较,可以看出3种模型都随着k值的增加,精度损失增加,等价类中的元组个数增加,泛化准标识符个数增加,而个性化(p,k)匿名模型取固定的p值,在元组个数较少时曲线斜率较陡,随着k值的增加,曲线逐渐变得平缓。
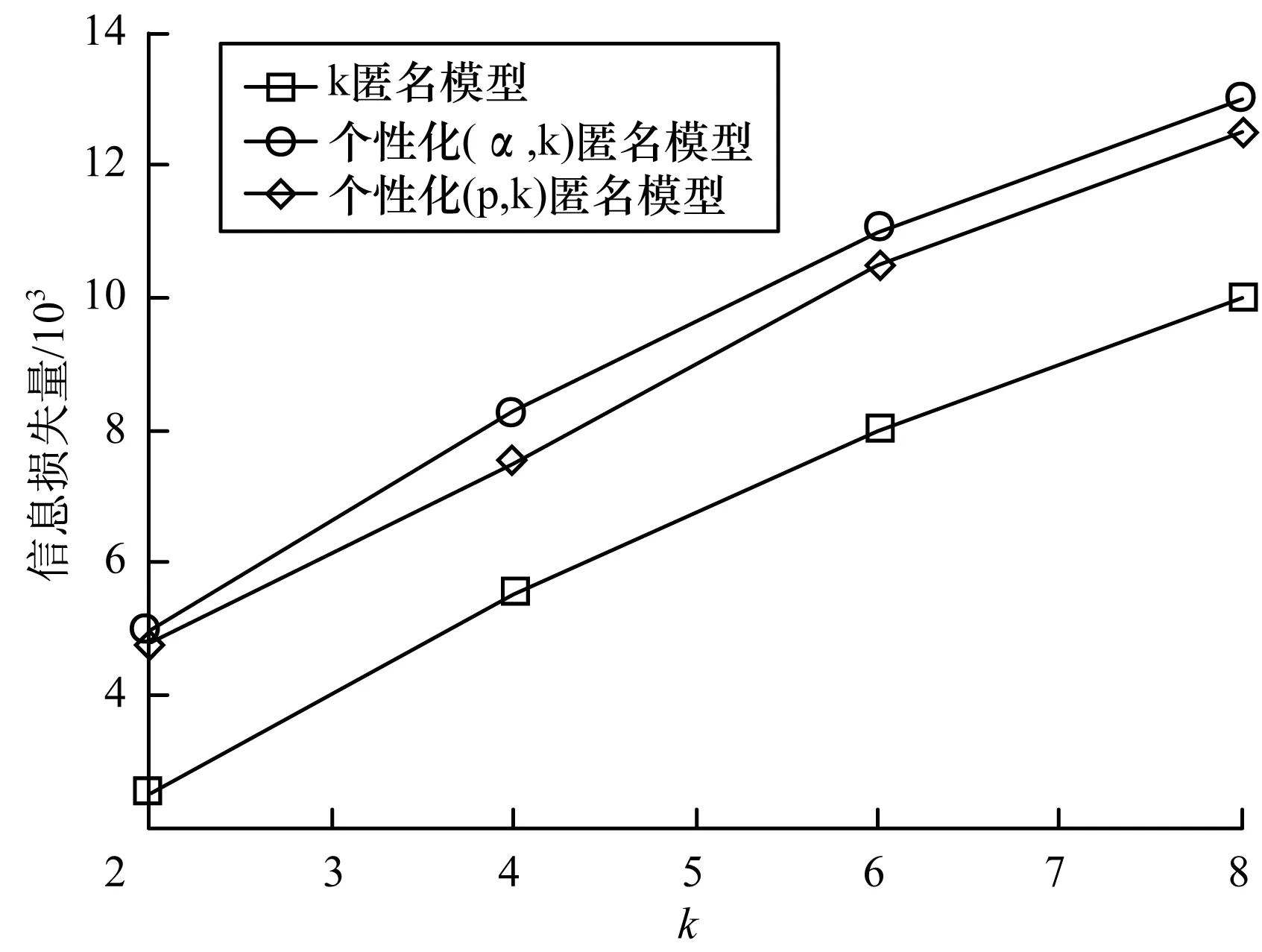
图6 信息损失量对比2
5 结束语
本文提出一种基于(p,k)匿名模型的敏感属性个性化匿名算法。根据多数用户针对敏感属性的评分结果建立敏感属性等级,将少数与大众评分结果存在差异的用户视为离群点遗弃,之后利用敏感属性泛化树泛化敏感属性,对不满足(p,k)匿名条件的元组重新划分等价类。实验结果表明,通过损失部分敏感属性的精度实现个性化保护的方法有效。后续工作将主要针对个性化匿名模型进行更合理的设计,并考虑将本文算法与实际问题相结合。
[1] AGGARWAL C C,YU P S.Privacy-preserving Data Mining:Models and Algorithms[J].Advances in Database Systems,2008,35:11-52.
[2] PATEL B H,SHAH A N.Overview of Privacy Preserving Techniques and Data Accuracy[J].International Journal of Advance Research in Computer Science and Management Studies,2015,3(1):135-140.
[3] LATANYA S.k-Anonymity:A Model for Protecting Privacy[J].International Journal of Uncertainty,Fuzziness and Knowledge-based Systems,2002,10(5):557-570.
[4] JOSHI P,WADE S A,WADKAR C G,et al.The k-Anonymity Approach for Privacy Preservation Against Aggregate Knowledge Attacks[J].The International Journal of Science and Technoledge,2015,3(1):50.
[5] TRUTA T M,VINAY B.Privacy Protection:p-Sensitive k-Anonymity Property[C]//Proceedings of the 22nd International Conference on Data Engineering Workshops.Washington D.C.,USA:IEEE Press,2006:94.
[6] YUAN Yongbin,YANG Jing,LAN Sheng,et al.p-Sensitive k-Anonymity Based on Nearest Neighborhood Search in Privacy Presering[J].Journal of Information and Computational Science,2012,9(5):1385-1393.
[7] 康海燕,杨孔雨,陈建明.基于K-匿名的个性化隐私保护方法研究[J].山东大学学报(理学版),2014,49(9):142-149.
[8] 戢渼钧.关于个性化信息服务的隐私保护[J].图书情报工作,2006,50(2):49-51.
[9] 何 康,吴 蒙.一种个性化的k-匿名位置隐私保护算法[J].南京邮电大学学报(自然科学版),2012,32(6):69-73.
[10] 刘 明,叶晓俊.个性化K-匿名模型[J].计算机工程与设计,2008,29(2):282-286.
[11] 韩建民,于 娟,虞慧群,等.面向敏感值的个性化隐私保护[J].电子学报,2010,38(7):1723-1728.
[12] LIU Yinghua,YANG Bingru,LI Guangyuan.A Personalized Privacy Preserving Parallel (alpha,k)-anonymity Model[J].International Journal of Advancements in Computing Technology,2012,4(5):265-271.
[13] HUANG Xuezhen,LIU Jiqiang,HAN Zhen,et al.Privacy Beyond Sensitive Values[J].Science China Information Sciences,2015,58(7):1-15.
[14] 王 波,杨 静.一种基于逆聚类的个性化隐私匿名方法[J].电子学报,2012,40(5):883-890.
[15] 傅鹤岗,曾 凯.多维敏感k-匿名隐私保护模型[J].计算机工程,2012,38(3):145-147.
[16] 王 茜,曾子平.(p,a)-sensitive k-匿名隐私保护模型[J].计算机应用研究,2009,26(6):2177-2179.
[17] TONG Yunhai,TAO Youdong,TANG Shiwei,et al.Identity-reserved Anonymity in Privacy Preserving Data Publishing[J].Journal of Software,2010,21(4):771-781.
[18] 夏赞珠,韩建民,于 娟,等.用于实现(k,e)-匿名模型的MDAV算法[J].计算机工程,2010,36(15):159-161.
[19] IYENGAR V S.Transforming Data to Satisfy Privacy Constraints[C]//Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery.New York,USA:ACM Press,2002:279-288.
猜你喜欢
计算机应用(2022年8期)2022-08-24
新高考·高三数学(2022年3期)2022-04-28
电脑报(2021年14期)2021-06-28
计算机系统应用(2020年8期)2020-03-22
软件学报(2019年11期)2019-12-11
计算机与生活(2019年5期)2019-07-18
吉林大学学报(理学版)(2018年2期)2018-03-29
中文信息(2017年12期)2018-01-27
图书馆建设(2015年11期)2015-08-24
中央民族大学学报(自然科学版)(2015年2期)2015-06-09
