
基于Kaldi的普米语语音识别
2018-01-19 00:54,,
计算机工程 2018年1期
,,
(云南民族大学 数学与计算机科学学院,昆明 650500)
0 概述
近年来语音识别技术得到飞速的发展,通过自然语言控制机器的梦想正在逐步实现。国内语音识别研究经过60年左右的积累,尤其是近20年来快速的发展,已取得显著成效。语音识别技术已由传统的隐马尔科夫模型(Hidden Markov Model,HMM)发展到了当今广泛使用的深度学习技术,并且取得较好的效果。但是这些研究都是针对英语、汉语等国际主流语言,对无文字濒危少数民族语言进行语音识别的研究目前还比较少见。
云南省有25个少数民族,大部分少数民族都有本民族的语言。由于民族语言众多且语言之间差别较大,导致各民族之间的交流比较困难。同时,像普米族、基诺族等人口较少的民族有20%的语言已经濒危[1]。因此,从少数民族语言保护和传承的角度看,进行少数民族语音识别研究就显得尤为重要。本团队的主要工作是针对普米语进行语音识别研究。普米族有本民族的语言,但没有文字。普米语属于汉藏语系藏缅语族羌语支,分为南北两个方言[2]。在此之前本团队的研究主要是基于HTK进行的,已取得了一些成果[3-7]。本文引入基于Kaldi的深度学习技术对普米语语音识别做进一步研究,这对普米语语音识别率的提高意义重大。
文献[8]提出深度学习的概念,激起了深度学习的研究热潮。自2009年以来,将深度学习技术应用到语音识别领域取得巨大成功。百度研发的新技术:深度语音识别(Deep Speech),通过使用一种叫做叠加的物理学原理,在干净的语音语料中加入各种不同的背景噪声来扩大语音语料量,用得到的语音语料进行深度语音识别实验,同时使用百度强大的新计算机系统的GPU进行加速支撑,运算效率得到重大提升,词错误率降低了10%[9]。微软公司人工智能研发团队受到机器学习集成技术的启发,系统性地结合使用了一系列的卷积神经网络模型、长短时间记忆单元的神经网络、全新的空间平滑方法和最大互信息训练方法,为所有声学模型架构的性能带来了显著的提升,最好的单个声学模型系统在NIST 2000 Switchboard数据集上的词错误率为6.9%,数个声学模型系统性地结合将词错误率降低到6.3%[10]。科大讯飞将深度神经网络(Deep Neural Network,DNN)模型首次成功应用到中文语音识别领域,语音识别率得到很大提升[11]。这些基于深度学习的语音识别研究主要是针对英语、汉语等国际主流语言的,在少数民族语言语音识别中使用深度学习技术的还比较少见,查阅到的文献主要集中在藏语、维吾尔语以及蒙古语。文献[12]在基于DNN模型的声学建模中,针对数据稀疏问题,提出了采用大语种数据训练好的DNN模型作为目标模型的初始网络进行模型优化的策略,实验用自然对话风格的藏语电话语音,共计10 327个句子,从中随机选择550个句子用于测试,其余的用于训练。实验结果表明,用1 000 h的汉语训练的DNN模型作为藏语DNN模型的初始网络,相对直接用藏语训练的DNN模型,语音识别率提升了6.37%[12]。文献[13]提出了基于DNN模型的维吾尔语语音识别方法,以Kaldi语音识别工具包为实验平台,用4 466条维吾尔语语音训练了一个含有4隐层的DNN模型,用训练好的DNN模型对499条维吾尔语语音进行测试,测试结果显示,DNN模型相比传统的HMM词错误率下降了31.09%[13]。文献[14]基于Kaldi语音识别工具包,用DNN模型建立大词汇量连续语音识别系统,用78 h的蒙古语语音语料进行实验,实验结果表明,DNN-HMM模型比GMM-HMM模型语音识别率提高了约50%。因此,针对语音语料量和系统鲁棒性的问题,本文将深度学习引入普米语语音识别中,在Kaldi上进行普米语语音识别实验。
本文所使用的深度学习模型是深度神经网络-隐马尔科夫模型(DNN-HMM)的混合模型,以Kaldi语音识别工具包为实验平台,训练一个含有4隐层的深度学习模型,实现普米语语音识别。
1 Kaldi简介及使用流程
目前,常用的开源语音识别工具有Kaldi和HTK,Kaldi与HTK的比较如表1所示。

表1 Kaldi与HTK比较
从表1中可以看出,基于深度学习的语音识别实验在Kaldi上进行更合适。因此,本文选用Kaldi语音识别工具包作为实验平台。
1.1 Kaldi语音识别工具包
Kaldi语音识别工具包是由约翰·霍普金斯大学开发的开源的语音识别工具包,用C++编写并被Apache License v2.0授权许可[15-16]。Kaldi可以在Linux环境和Windows环境下编译,但是在Linux环境下进行编译比较稳定。因此,本文将在Linux环境下编译Kaldi。Kaldi语音识别工具包的框架结构如图1所示。
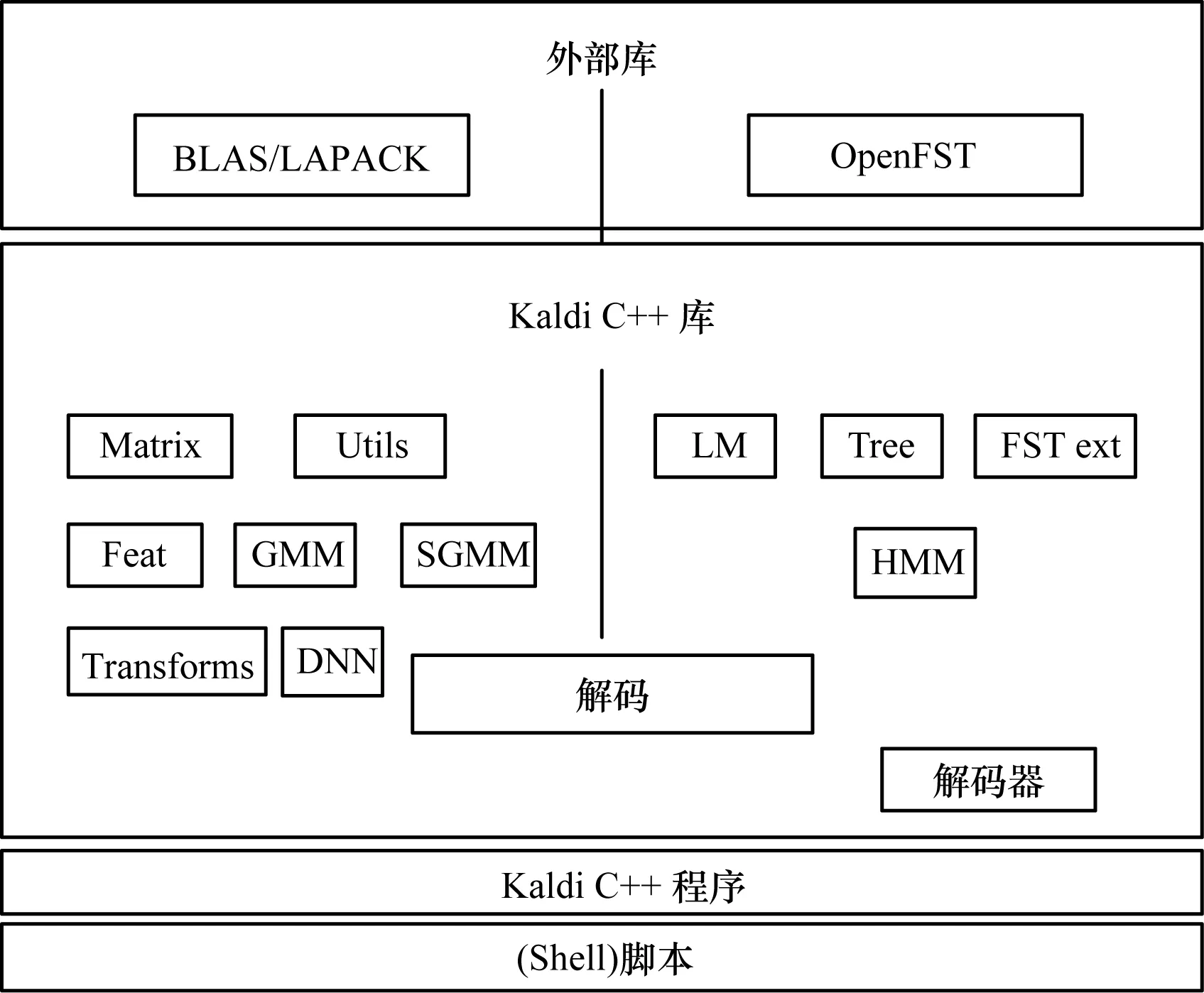
图1 Kaldi语音识别工具包结构
从图1中可以看出,Kaldi语音识别工具包主要依赖2个外部开源库: BLAS/LAPACK和OpenFST。同时,Kaldi本身也分为2个模块,分别依赖这2个外部开源库,这2个模块通过Decodable接口桥接。
BLAS是基本线性函数库,是许多数值计算软件库的核心,主要用于向量操作、矩阵-向量操作、矩阵-矩阵操作等基本运算。LAPACK是一个高性能的用于数值计算的函数集,以BLAS为基础,包含了丰富的工具函数,可用于常见的数值线性代数问题,例如求解线性方程、计算特征值和特征向量等问题。
OpenFST是一个开源的用于构造、合并、优化和搜索加权有限状态转换器(Weighted Finite State Transducer,WFST)的库。OpenFST在处理时间和空间规模很大的问题上时效果很好。WFST常被用于语音识别、模式匹配以及机器学习等任务中。在语音识别系统中,把数学模型转换为有限状态机模型,然后对有限状态机模型进行优化得到搜索空间,这样可以降低语音识别系统的复杂度。
1.2 基于Kaldi语音的识别实验过程
本文将Kaldi部署在Ubuntu14.04系统上,为了在DNN模型训练时使用GPU加速,还需要安装配置CUDA。
所有安装及配置都完成之后就可以在Kaldi上进行基于深度学习的普米语语音识别实验了。实验主要在/kaldi-trunk/egs/PrimiL/s5/下进行。具体过程如图2所示。
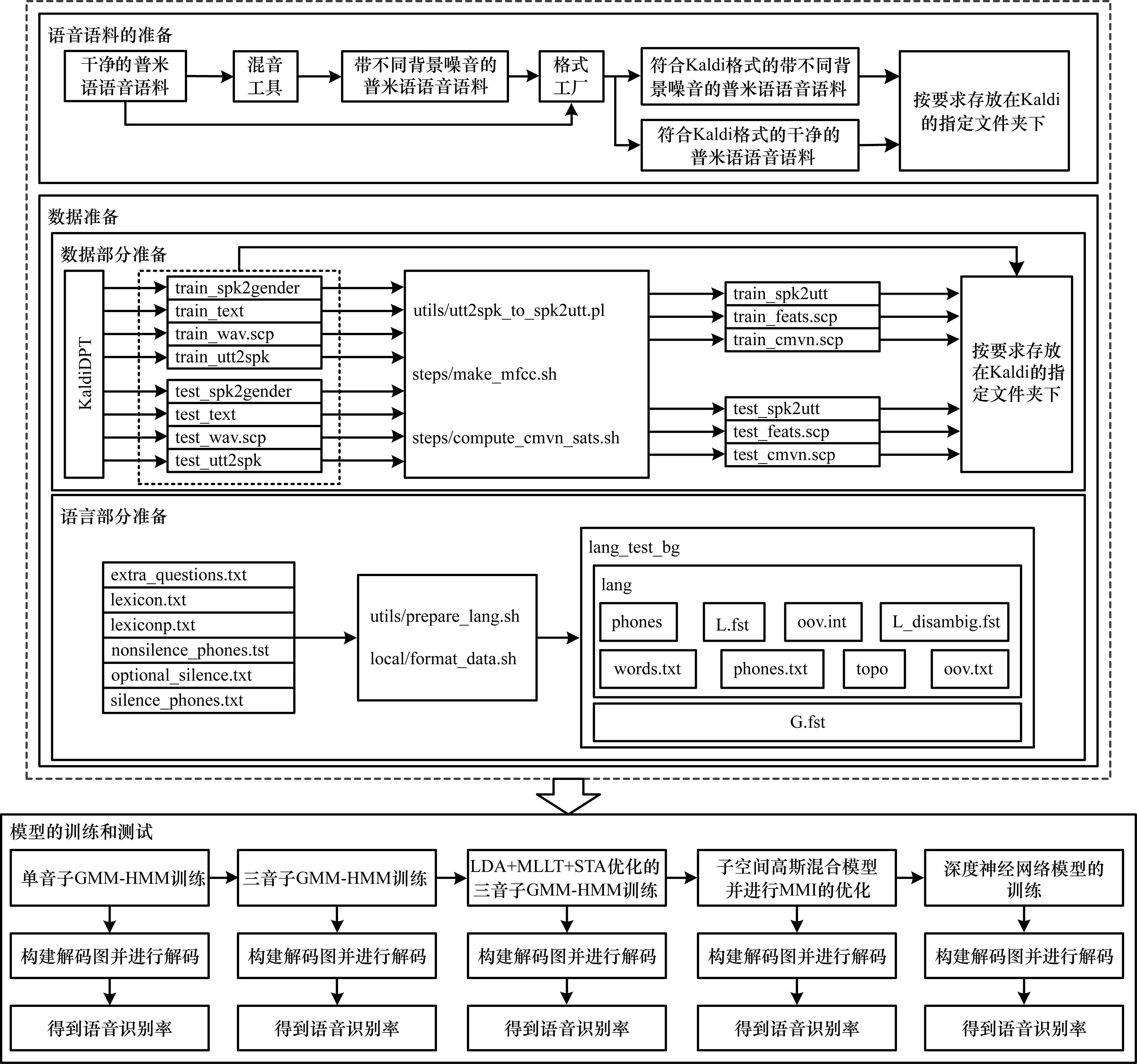
图2 基于Kaldi的普米语语音识别过程
从图2可以看出,基于Kaldi的普米语语音识别主要分为3步,具体过程描述如下:
1)普米语语音语料的准备。通过把录音棚下录制的干净的普米语语音语料通过混音工具得到带有背景噪音的普米语语音语料,用来扩大语音语料量。本文使用的混音工具是本团队成员开发的[7]。接着把带噪的语音语料和干净的语音语料都用格式工厂转换为Kaldi可用的格式。最后,将实验用到的语音语料按要求存放在指定文件夹中。
2)数据准备。数据准备又分为2个部分:第1部分是数据部分准备,先用KaldiDPT工具分别生成训练集和测试集下的spk2gender、text、wav.scp以及utt2spk,KaldiDPT工具是专门用Kaldi数据部分的准备工具[15]。再以这些文件作为输入,通过调用Kaldi中相应的工具,生成spk2utt、feats.scp以及cmvn.scp。其中,feats.scp中存储所有语音语料的特征文件存放的位置,cmvn.scp中存储所有语音语料的倒谱均值和方差归一化统计量存放的位置。第2部分是语言部分准备,语言部分的准备以发音字典为输入,依次调用prepare_lang.sh和format_data.sh工具,生成lang和lang_test_bg文件夹,这2个文件夹的差别在于lang_test_bg文件夹中多了G.fst文件,G.fst是语言模型的有限状态转换器格式的表示,用于解码。普米语发音字典已根据《普米语简志》准备好,且符合Kaldi的格式要求[15-16]。
3)模型的训练和测试。把前2步准备好的语音语料和文件用于模型的训练和测试。本文训练了5种不同的声学模型,分别是:单音子GMM-HMM,记为Monophone,该模型的训练过程要迭代39次,并且每迭代1次~3次要进行一次数据对齐;三音子GMM-HMM模型,记为Triphone1,该模型的训练是以训练好的Monophone模型为输入,训练过程要迭代34次,并且每迭代10次进行一次数据对齐;优化后的三音子GMM-HMM模型,记为Triphone2,该模型是对三音子GMM-HMM模型进行线性判别分析、最大似然线性变换和发音自适应训练的优化;优化后的子空间高斯混合模型,记为O-SGMM,该模型的训练以Triphone2模型为输入,训练子空间高斯混合模型(Subspace Gauss Mixture Model,SGMM)之前要用通用背景模型进行初始化,再训练SGMM,并进行最大互信息的区分性训练;深度神经网络模型,记为G-DNN,是基于O-SGMM模型训练的,G-DNN含有4层隐层,且使用GPU加速训练过程。每个模型训练完成后都会进行测试,得到基于该模型的普米语语音识别率。
2 实验及结果分析
本文基于Kaldi的普米语语音识别实验分为3个部分。第1部分:不同的声学模型对普米语语音识别率的影响;第2部分:普米语语音语料的规模对普米语语音识别率的影响;第3部分:普米语语音识别系统的鲁棒性。
本文实验使用的语音语料:4位普米语发音人在录音棚环境录制的包含1 650个普米词汇的干净的普米语语音语料,在录音棚录制普米语语音语料时,每个普米词汇每个发音人说8遍。再通过混音工具对所有干净的语音语料分别混入4种不同的背景噪音,每种随机混音8次,每2次混音得到的带噪的普米语语音语料记为一组,共有4组,分别记为第1组~第4组。因此,干净的语音语料有:1 650个词×8遍×4位发音人=52 800条,带噪的语音语料有:1 650个词×8遍×4种背景噪声×8次混音×4位发音人=1 689 600条,共计1 742 400条语音语料。
2.1 声学模型实验
不同的声学模型对语音识别率的影响较大,因此本实验验证不同的声学模型对普米语语音识别率的影响。同时,为了避免语音语料量不足及测试集和训练集设置的问题导致识别结果出现偶然性,进行交叉验证实验。
本实验用所有干净的普米语语音语料和第1组带噪的普米语语音语料。为了便于交叉验证实验的进行,将本节所用的所有实验数据平均分为4组,分别记为第1组~第4组。使用留一交叉验证的方法,其中3组用于训练,余下的1组用于测试,每组数据都有且仅有一次作为测试集出现在实验中。用测试集的序号标记实验组的序号,例如以第4组为测试集,则记为第4组实验。
通过实验得到不同声学模型的语音识别率,如表2所示。
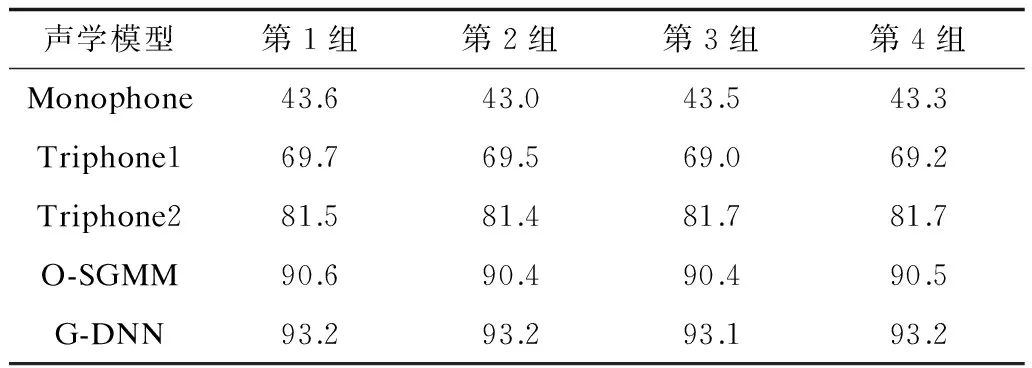
表2 不同声学模型的语音识别率 %
为了更直观地表示在不同声学模型中,普米语语音识别率的变化情况,由表2中的数据绘制折线图,得到图3、图4。
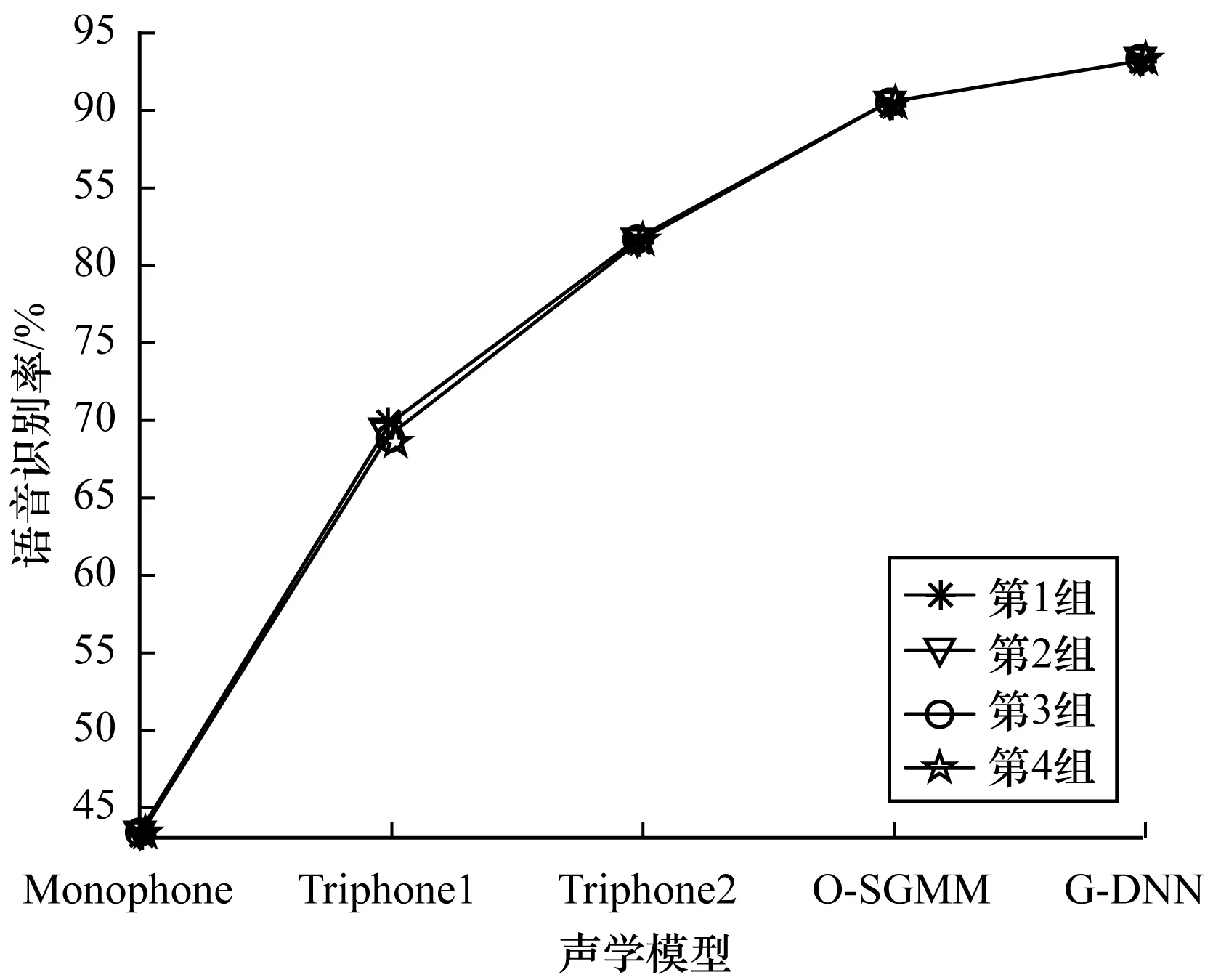
图3 不同声学模型的语音识别率1
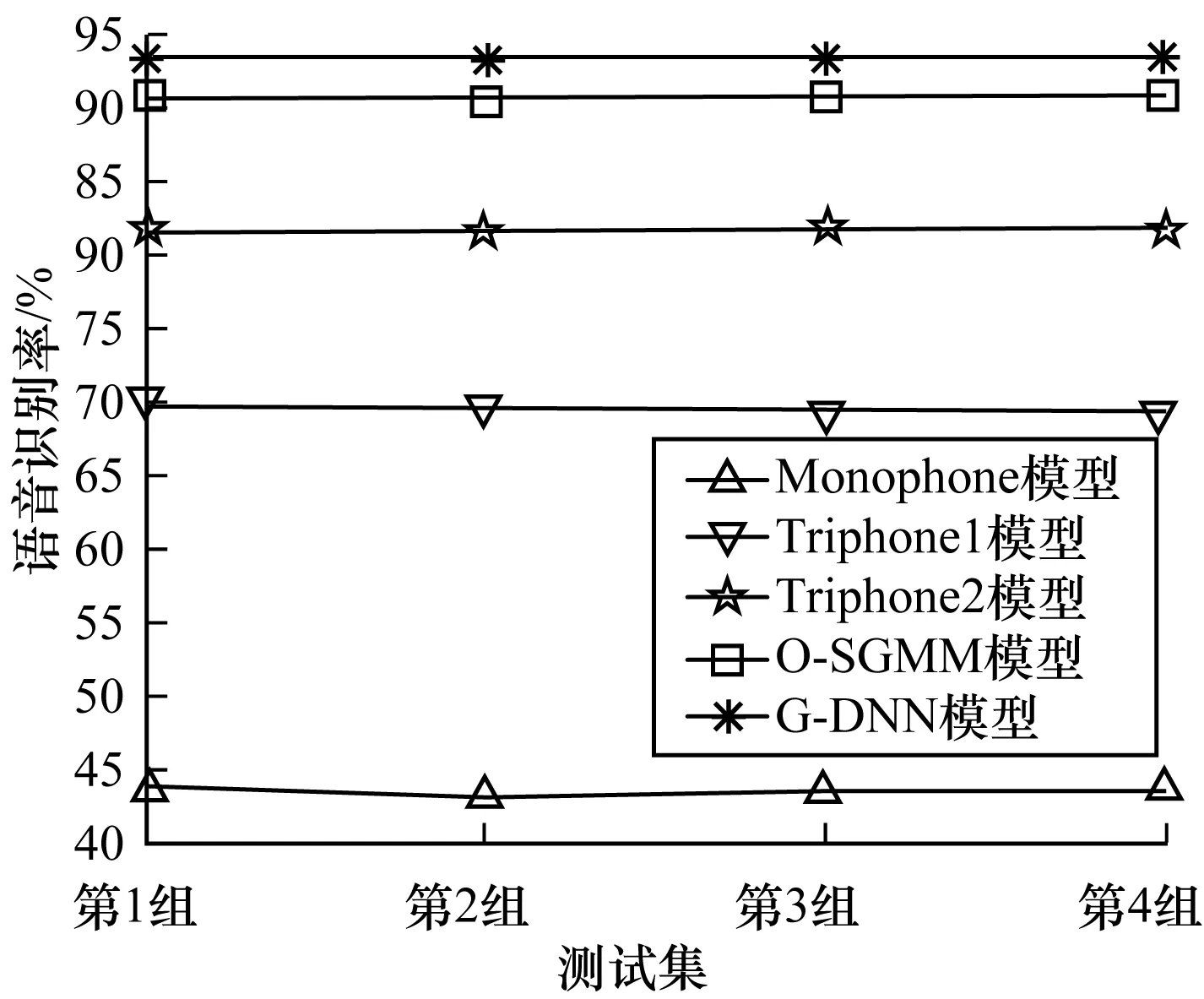
图4 不同声学模型的语音识别率2
从表2中可以看出,4组实验的语音识别率不完全相同,在图3中,4条折线几乎重合,说明4组实验中语音识别率的波动很小。由此可以得出,测试集和训练集的设置没有影响普米语语音识别率。从图4可以看出,4组实验中G-DNN模型的语音识别率最高,接着是O-SGMM模型、Triphone2模型、Triphone1模型、Monophone模型依次降低,而Monophone模型的语音识别率最低。以第1组为测试集的普米语语音识别实验为例,通过对表2中的数据比较得到,G-DNN模型比O-SGMM模型语音识别率提升了2.6%,G-DNN模型比Triphone2模型语音识别率提升了11.7%,G-DNN模型比Triphone1模型语音识别率提升了23.5%,G-DNN模型比Monophone模型语音识别率提升了49.6%。由此可知,G-DNN模型有效地提升了普米语语音识别率。
由于GMM-HMM在考虑三音子后,模型的参数迅速增加,模型参数无法充分地训练,影响语音识别率。而深度学习模型是一种多隐层的网络结构,每一层都单独训练,使得模型参数能够充分地训练,所以基于深度学习的声学模型相比其余4个声学模型,语音识别率有了明显提升。因此,使用不同的声学模型对普米语语音识别率的影响较大,其中,由G-DNN模型训练得到的普米语语音识别系统的语音识别率最高,由Monophone模型训练得到的普米语语音识别系统的语音识别率最低。由此可以得出,深度学习模型能够有效地提升普米语语音识别率。
2.2 不同语料量实验
不同语料量的实验指的是单个普米语词汇语音语料的数量不同的实验。基于深度学习的语音识别实验,语音语料量的大小对语音识别率有很大的影响,本节将研究普米语语音语料量的大小对普米语语音识别率的影响。
本实验使用所有干净的普米语语音语料和第1组~第4组带噪的普米语语音语料,共进行了4组实验。
第1组实验:用所有干净的语音语料和第1组带噪的语音语料,分别取干净的和带噪的语音语料的6/8用于训练,余下的用于测试。
第2组实验:用所有干净的语音语料加上第1组、第2组带噪的语音语料,分别取干净的和带噪的语音语料的6/8用于训练,余下的用于测试。
第3组实验:用所有干净的语音语料加上第1组、第2组、第3组带噪的语音语料,分别取干净的和带噪的语音语料的6/8用于训练,余下的用于测试。
第4组实验:用所有干净的语音语料加上第1组~第4组带噪的语音语料,分别取干净的和带噪的语音语料的6/8用于训练,余下的用于测试。
通过实验得到不同语料量的普米语语音识别率,如表3所示。
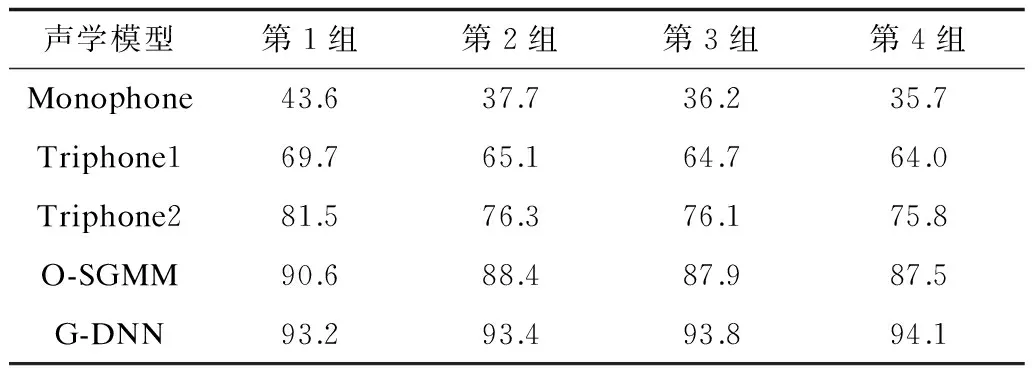
表3 不同语料量实验的语音识别率 %
为了更直观地表示当普米语语音语料量不同时,语音识别率的变化情况,由表3中的数据绘制折线图,如图5、图6所示。
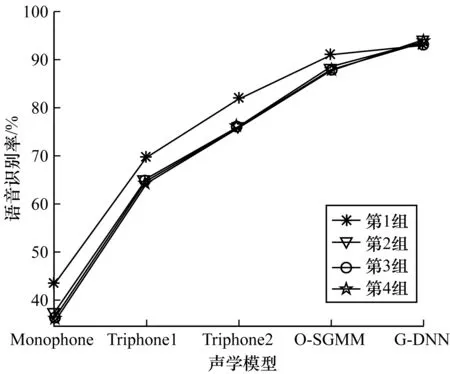
图5 不同语料量实验的语音识别率1
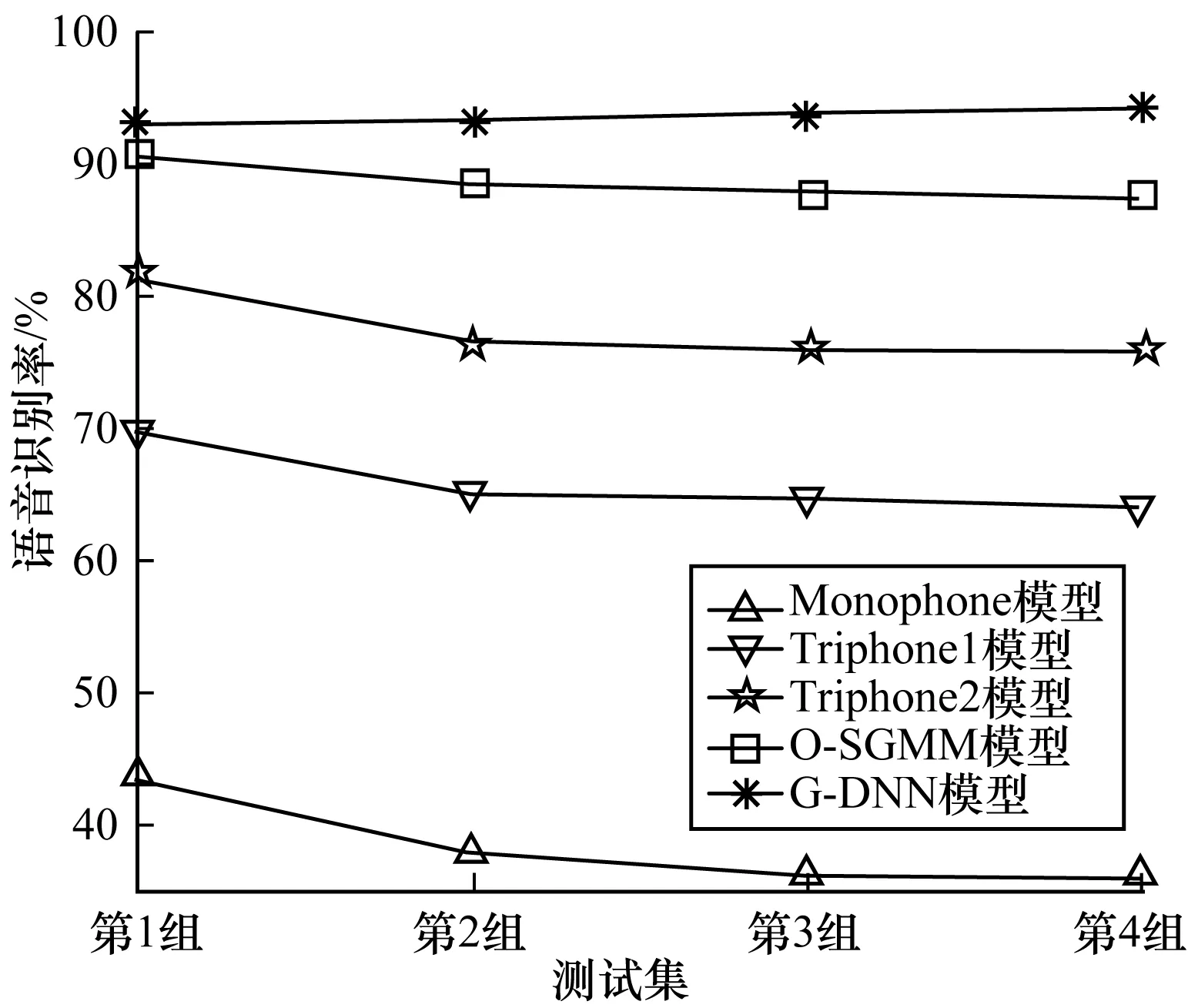
图6 不同语料量实验的语音识别率2
由图5可以看出,不论语料量的多少,每条折线均是从左往右呈上升趋势,即每组实验中均是由Monophone模型到Triphone1模型、Triphone2模型、O-SGMM模型、G-DNN模型语音识别率依次升高。由图6可以看出,随着普米语语音语料量的增加,Monophone模型、Triphone1模型、Triphone2模型以及O-SGMM模型的语音识别率都有所下降,只有G-DNN模型的语音识别率逐渐升高。当语料量从干净的语音语料加1组加噪的语音语料增加到干净的语音语料加4组加噪的语音语料时,基于G-DNN模型的普米语语音识别率提升了0.9%。实验结果表明,增加普米语语音语料量可以促进基于深度学习的普米语语音识别率的提升。
2.3 鲁棒性实验
本实验的目的在于验证不同的声学模型对普米语语音识别系统鲁棒性的影响以及相同的声学模型用不同的训练集对普米语语音识别系统的鲁棒性的影响。
实验使用所有干净的普米语语音语料和第1组带噪的普米语语音语料,共进行4组实验。
第1组实验:用所有干净的普米语语音语料,取6/8用于训练,余下的用于测试。
第2组实验:用第1组实验训练好的模型,把第1组用于测试的干净的普米语语音语料用混音工具随机混音1次得到的带噪普米语语音语料作为该组实验的测试集。
第3组实验:将第1组实验的训练集加上第1组带噪普米语语音语料的6/8用于该组实验的训练,第1组实验的测试集作为该组实验的测试集。
第4组实验:用第3组实验训练好的模型,用第2组实验的测试集进行该组实验的测试。
通过实验得普米语语音识别系统鲁棒性实验的语音识别率,如表4所示。
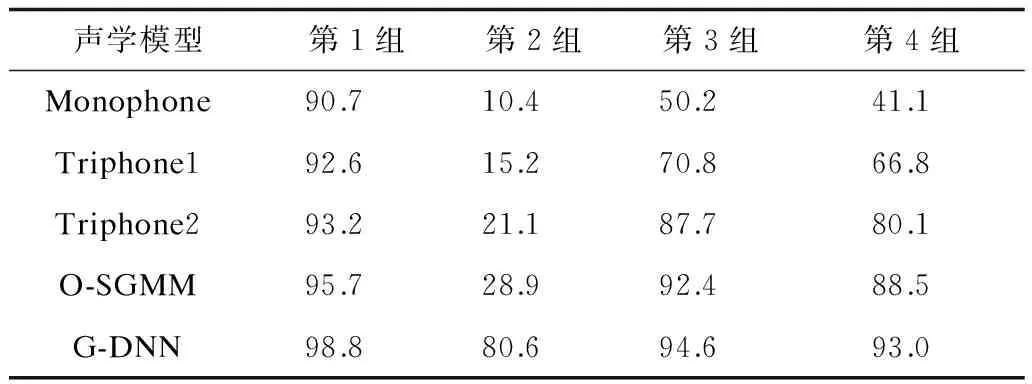
表4 鲁棒性实验的语音识别率 %
为了更直观地表示鲁棒性实验普米语语音识别率的变化规律,由表4中的数据绘制折线图,如图7、图8所示。
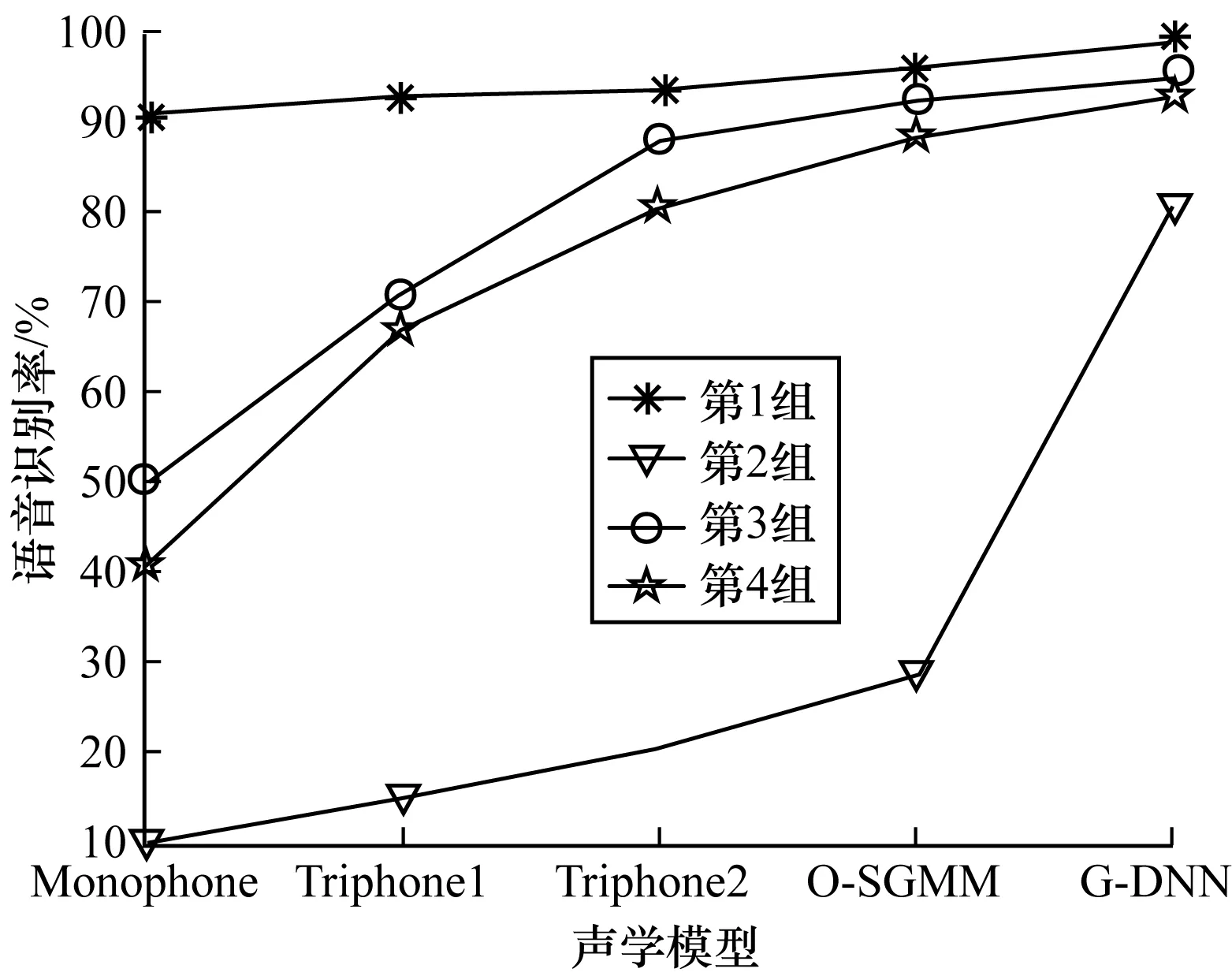
图7 鲁棒性实验的语音识别率1
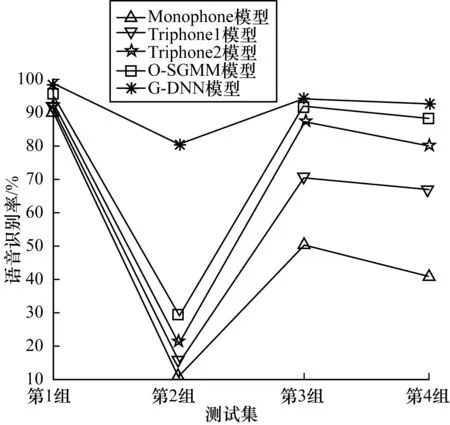
图8 鲁棒性实验的语音识别率2
对第1组实验与第2组实验进行比较,第1组、第2组实验的训练集相同,都是干净的语音语料,测试集分别为干净的和带噪的语音语料。从图7中可以看出,第1组实验的语音识别率较高,第2组实验的语音识别率较低,且2组实验的语音识别率变化较大。由此可以得出,用干净的语音语料训练出来的模型只有用干净的语音语料去测试才能得到较高的语音识别率,若是使用带噪的语音语料去测试则语音识别率很低,说明仅使用干净的语音语料训练的语音识别系统,系统的鲁棒性较差。对第3组实验与第4组实验进行比较,第3组、第4组实验的训练集也相同,都是干净的语音语料加上带噪的语音语料,测试集分别为干净的和带噪的语音语料。从图7可以看出,第3组实验的语音识别率更高,第4组实验的语音识别率更低,但是2组实验的语音识别率变化不大。由此可以得出,在训练集中加入带噪的语音语料时,即使用带噪的语音语料进行测试,语音识别率也不会大幅度地降低,说明同时使用干净的和带噪的语音语料进行训练的语音识别系统,系统的鲁棒性较好。实验结果表明,在训练集中加入带噪的语音语料能够有效地提高普米语语音识别系统的鲁棒性。
从图8可以看出,无论是在哪种方案的实验中,G-DNN模型的语音识别率均比其余4个模型的语音识别率高。当测试集与训练集的设定不同时,Monophone模型、Triphone1模型、Triphone2模型以及O-SGMM模型的语音识别率波动较大,而G-DNN模型的语音识别率波动较小。例如将第1组实验与第2组实验进行比较,如表5所示,当测试集由干净的普米语语音语料换为带噪的普米语语音语料时,Monophone模型的语音识别率下降了80.3%;Triphone1模型的语音识别率下降了77.4%;Triphone2模型的语音识别率下降了72.1%;O-SGMM模型的语音识别率下降了66.8%;G-DNN模型的语音识别率下降了18.2%。为了更直观地表示不同声学模型语音识别率的变化情况,绘制柱状图,如图9所示。可以看出,G-DNN模型的语音识别率的减少量最小。由此可知,G-DNN模型的语音识别率降低得最少。实验结果表明,G-DNN模型的鲁棒性比其余4个声学模型的鲁棒性更好。
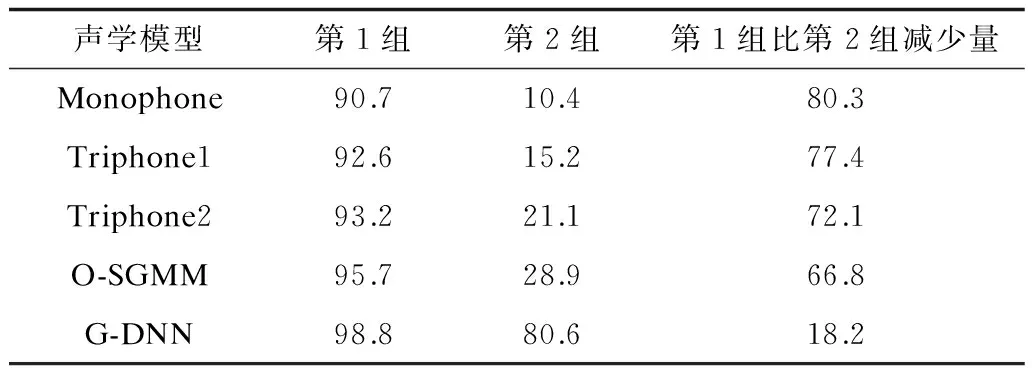
表5 第1组实验与第2组实验语音识别率比较 %
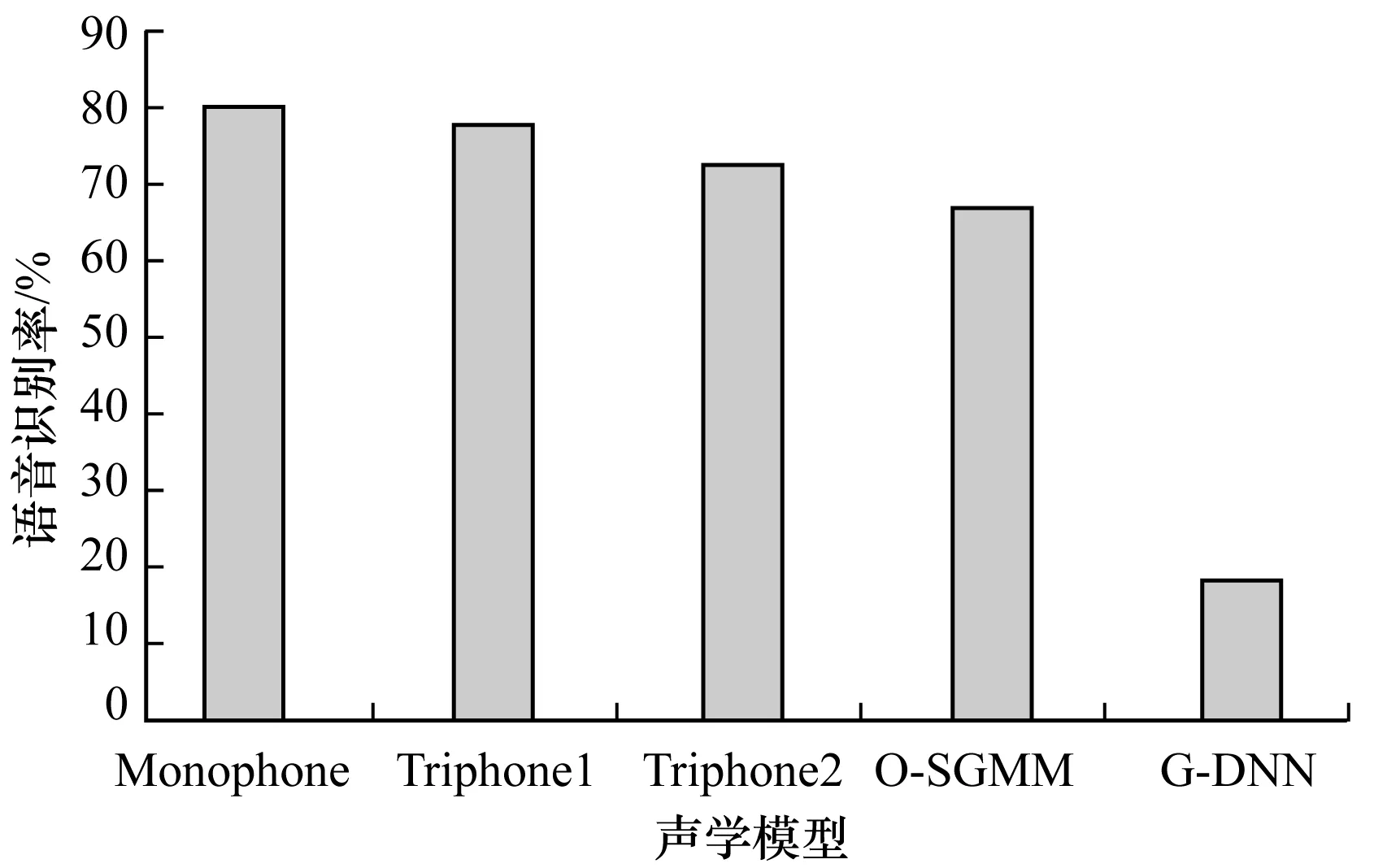
图9 第2组比第1组语音识别率减少量
通过对实验结果的详细分析,得到仅用干净的语音语料训练的语音识别系统中,只有用干净的语音语料进行测试才能得到较高的语音识别率。如果用带噪的语音语料进行测试,则语音识别率会变得很低,说明仅使用干净的普米语语音语料训练的普米语语音识别系统的鲁棒性较差。而同时使用干净的和带噪的语音语料进行训练时,不论是用干净的语音语料进行测试,还是用带噪的语音语料进行测试,语音识别率波动较小,说明在训练集中加入带噪的语音语料能够提高普米语语音识别系统的鲁棒性。同时,在4组实验中,基于G-DNN模型的普米语语音识别系统的语音识别率波动最小,其余4个声学模型的语音识别率波动较大。综上所述,相比于Monophone模型、Triphone1模型、Triphone2模型和O-SGMM模型,G-DNN模型具有更好的鲁棒性,即用深度学习技术能够提高普米语语音识别系统的鲁棒性。
3 结束语
本文在Kaldi上进行基于深度学习的普米语语音识别实验,为加速模型的训练,配置安装了CUDA,有效地解决了深度学习模型训练效率的问题。在Kaldi上进行了3类实验:通过对不同声学模型实验结果的比较发现,深度学习模型的语音识别率明显高于其余的4个声学模型,G-DNN模型比Monophone模型的语音识别率平均提升了49.8%;通过不同语音语料量的实验发现,在训练集中增加语音语料量,可以提高基于深度学习的普米语语音识别率;通过鲁棒性的实验发现,在训练集中加入带噪的语音语料可以提高普米语语音识别系统的鲁棒性,并且基于深度学习的普米语语音识别系统的鲁棒性比其余4个声学模型的普米语语音识别系统的鲁棒性更强。
[1] 陆惠云.云南省七个“特少”民族语言使用状况调查[J].玉溪师范学院学报,2014,30(1):45-59.
[2] 解鲁云.国内普米族研究综述[J].云南民族学院学报(哲学社会科学版),2003,20(1):75-78.
[3] 李余芳,苏 洁,胡文君,等.基于HTK的普米语孤立词的语音识别[J].云南民族大学学报(自然科学版),2015,24(5):426-430.
[4] 苏 洁.基于HTK的普米语孤立词识别研究[D].昆明:云南民族大学,2016.
[5] 郭 琳,苏 洁,李余芳,等.一种人机交互语音切分系统[J].云南民族大学学报(自然科学版).2016,25(1):87-91.
[6] 苏 洁,李余芳,郭 琳,等.HTK参数对普米语孤立词识别率的影响[J].云南民族大学学报(自然科学版),2015,24(6):510-513.
[7] 李余芳.基于HTK的带噪普米语音识别系统的鲁棒性研究[D].昆明:云南民族大学,2016.
[8] HINTON G E,OSINDERO S,TEH Y W.A Fast Learning Algorithm for Deep Belief Nets[J].Neural Computation,2006,18(7):1527-1554.
[9] AWNI H,CARL C,JARED C,et al.Deep Speech:Scaling up End-to-End Speech Recognition[EB/OL].(2014-10-19).https://arxiv.org/pdf/1412.5567v2.pdf.
[10] XIONG W,DROPPO J,HUANG Xuedong,et al.Achieving Human Parity in Conversational Speech Recognition[EB/OL].(2016-10-17).https://arxiv.org/abs/1610.05256.
[11] 科大讯飞.探索语音识别技术的前世今生[J].科技导报,2016,36(9):76-77.
[12] 袁胜龙,郭 武,戴礼荣.基于深层神经网络的藏语识别[J].模式识别与人工智能,2015,28(3):209-213.
[13] 其米克·巴特西,黄 浩,王羡慧.基于深度神经网络的维吾尔语语音识别[J].计算机工程与设计,2015(8):2239-2244.
[14] ZHANG Hui,BAO Feilong,GAO Guanglai.Mongolian Speech Recognition Based on Deep Neural Networks[M]// SUN Maosong,LIU Zhiyuan,ZHANG Min.Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data.Berlin,Germany:Springer,2015.
[15] HU Wenjun,FU Meijun,PAN Wenlin.Primi Speech Recognition Based on Deep Neural Network[C]//Proceedings of IEEE International Conference on Intelligent Systems.Washington D.C.,USA:IEEE Press,2016:667-671.
[16] 陆绍尊.普米语简志[M].北京:民族出版社,1983.
猜你喜欢
科技研究·理论版(2021年22期)2021-04-18
家庭影院技术(2020年6期)2020-07-27
农业机械学报(2020年2期)2020-03-09
中华建设(2019年7期)2019-08-27
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
中国交通信息化(2018年3期)2018-06-13
