
融合动态标签优化协同过滤推荐算法
2018-03-05 12:32金浙良胡桂明
机械设计与制造 2018年2期
金浙良,胡桂明
(1.浙江工业职业技术学院 电气电子工程学院,浙江 绍兴 312000;2.广西大学 电气工程学院,广西 南宁 530004)
1 引言
随着电子商务的快速发展和商品资源的日渐丰富,用户如何快速从海量信息中获取所需信息变得越来越紧迫,协同过滤推荐算法[1]通过分析用户购买和评分的历史记录来进行预测和推荐,是现今应用最为广泛的方法,但仍面临数据稀疏不均衡等问题,使系统难以有效的向新用户推荐商品[1]。为高效使用用户和商品的信息,并为用户推荐感兴趣的商品,信任关系被引入到推荐系统的算法中,提出基于用户信任关系的过滤推荐系统模型。文献[2]描述了基于用户信任关系的协同过滤算法原理,通过利用其信任用户的信息来向新用户推荐商品,取得较好的效果。然而,基于信任模型的推荐系统其信任值的合理计算对于提高算法性能至关重要,但现有方法存在以下不足:(1)覆盖率指标与推荐精度存在互斥问题,且二进制表示方式导致推荐精度下降;(2)用户信息不对称,不能充分利用信任用户提高算的性能。
为解决上述问题,提出一种融合用户动态标签的改进协同过滤推荐算法。算法首先通过构建用户集、标签集和物品集三者间的动态联系,建立用户动态偏好矩阵,接着构建基于用户社会网络信息的用户信任关系矩阵,最后提出融合用户动态标签和用户信任关系的矩阵概率分解模型优化协同过滤推荐算法。仿真实验结果表明,算法取得了较好的效果,提高了协同过滤推荐算法的性能。
2 计算偏好标签矩阵
用三元组的形式在标签集、用户集和项目集之间建立动态联系,用户在访问资源时,其对标签进行查找、新增和关注及与资源进行交互,充分表现出用户的实时偏好行为,可以计算这类行为的相关特征,以更好地向用户推荐资源。标签的质量可用Sigmoid函数[3]进行计算,假定项目i与对应标签t之间的权重值为ω(i,t)
式中:m—标签的质量,m=TF×IDF;TF—词条 t的出现次数;IDF—文档的逆频文件频率,指文档频率与词条t频率之间存在的反比关系。
采用项目资源评级(Item-Rating,IR)对用户与资源的交互进行用户偏好标签的预测。
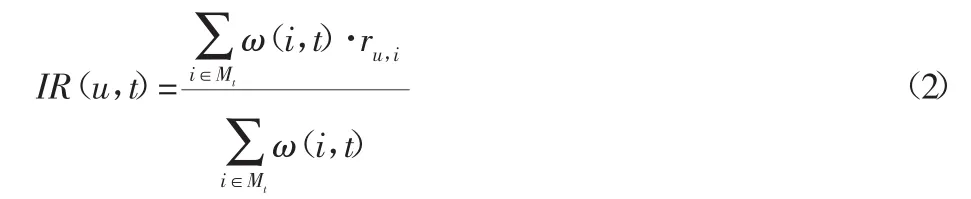
式中:ru,i—用户 u 对资源 i的评分;ω(i,t)—资源 i与标签 t之间的权重,变量Mt是包含标签t的所有资源。式(2)未考虑用户未评价但执行收藏等操作时的用户偏好,为了展示该类隐式标签的作用,采用式(3)对用户偏好进一步预测:

式中:NTP(u,t)—用户u对标签t的兴趣程度;Tt—包含隐式标签t的所有项目资源集。则用户与物品间的偏好标签矩阵为:

式中:使用α(0≤α≤1)调节因子来为物品显式标签与物品隐式标签设置权重。
3 用户信任关系矩阵
用户信任关系为用户偏好相似性和用户影响力,结合这两种因素的用户信任模型,如图1所示。图1中边缘代表节点间的信任关系,当请求用户U0的推荐信息时,只向其直接信任节点U1和U4发送信任查询信息,这些节点也同样向其受信任的节点发送信任查询关系,直到信任查询过程结束,然后选择信任值最高的用户,并反馈其所有产品的信任值,从而建立了基于用户信任关系图的反馈机制。通过信任反馈过程,就可以得到用户U0的受信任节点(包括直接和间接信任节点)所推荐项目的综合评分。
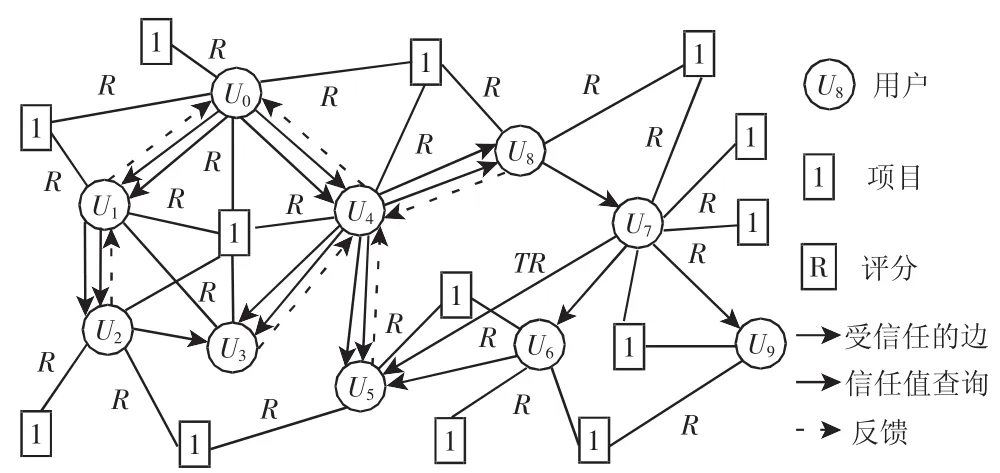
图1 用户信任关系模型Fig.1 User Trust Relation Model

信任关系具有转移性和方向性等非对称特性,可以有效缓解用户评分矩阵的数据稀疏问题。为测量用户间的影响力,使用Jaccard距离[4]来衡量用户的非对称关系。

用户之间的信任值主要由用户间相似度和用户间影响力组成,通过分配不同的权值计算用户间的信任值TRu,v。

4 改进协同过滤推荐算法
4.1 融合动态标签的改进概率矩阵分解模型
概率矩阵分解模型(Probability matrix factorization model,简写PMFM)是一类重要的协同过滤方式,文献[5]中将用户对项目的评价问题转换为概率问题,但是该模型未考虑到参与评分用户的信任级别以及用户与物品标签之间的动态联系。实际评分过程中过于均值化不利于体现重点用户的评分意见,同时用户对物品标签的偏好是动态的,需要获取实时交互行为,才能更好地向用户推荐商品。为此,融合信任关系和动态标签,设计了改进概率矩阵分解模型,如图2所示。
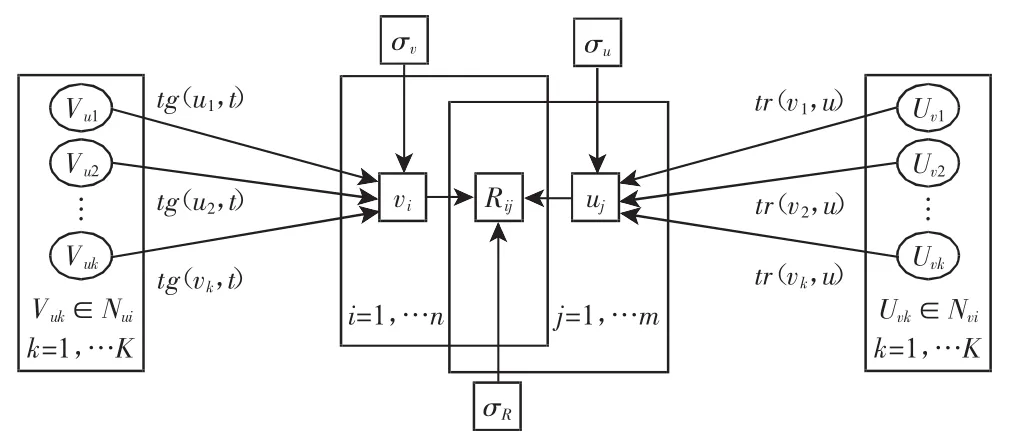
图2 改进PMFM模型Fig.2 Improved PFMF Model
改进模型中,评分矩阵为n行m列,第j行对应的潜在特征为uj,第i列对应的潜在特征为vi。Nui为具有相似偏好标签的用户集合,Nvi为用户u所信任的用户集合,tg(u1,t)为用户u1与物品标签t之间的关联程度,tr(v1,u)为用户v1与用户u之间的信任程度,tg(u1,t)与tr(v1,u)由用户偏好标签矩阵和用户信任关系矩阵计算得到。模型求解过程时,uj和vi均服从高斯特征分布N和),融合用户动态偏好标签和信任关系后联合概率分布为:
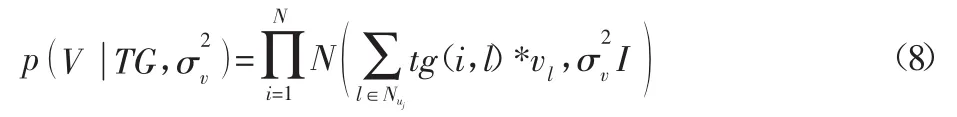
而用户信任关系矩阵与用户潜在特征的联合概率分布为:
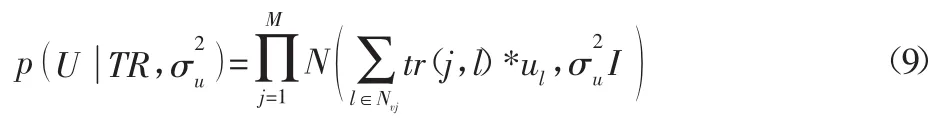
由于在改进模型中,U和V相互独立,则:
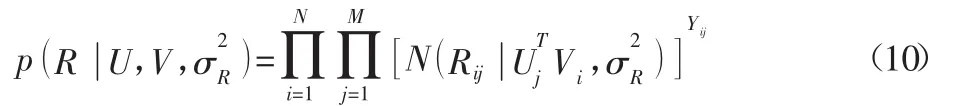
结合式(8)~式(10),通过贝叶斯推理可以得到,用户和物品潜在特征的后验概率分布为:

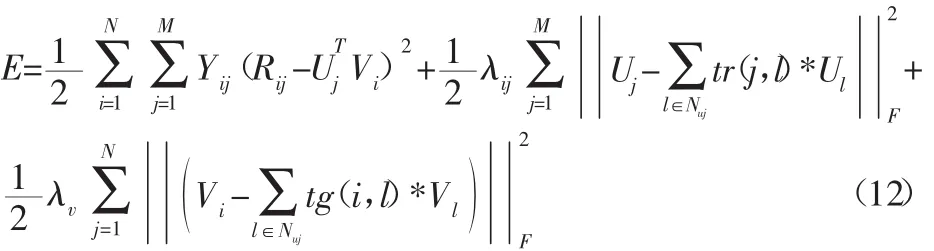
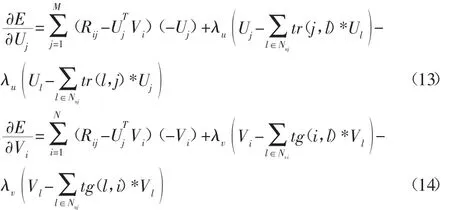
4.2 改进PMFM计算过程
改进PMFM模型的求解过程为:(a)根据数据集和式(4)、式(5)计算用户-项目评分矩阵、用户-项目的动态偏好标签矩阵及目标用户与其他用户之间的信任关系。(b)利用K-NN算法[6]获得目标用户u的K个用户-项目偏好标签集合以及K个与目标用户信任值极高的近邻用户集合。(c)设置迭代初始步数i=1,利用K-NN算法将步骤(b)得到的集合带入式(12)。(d)根据梯度下降法原理利用K-NN算法计算目标函数的下降可行方向d(i),并依据式(12)中的约束条件来计算下降方向的步长[0,λmax]。(e)根据获得的下降方向以及步长范围,利用0.618法[7]计算最优步长λi。(f)获得式(13)、式(14)的最优解,最终得到目标用户 u所有参数,并进行矢量相乘,最终获得目标用户对待评物品的预测值。
5 实验结果及分析
5.1 实验数据
为验证文中算法的有效性,在Jester-Data和MovieLens两个数据集上进行实验验证。Jester-Data数据集随机选取1743组用户,对121组新闻进行了评价,包含18924组用户标签评分信息。MovieLens测试集共有943组用户,1682组电影,100000条标签评分信息。这两个数据集的相关属性,如表1所示。不失一般性,采用5-fold交叉验证方法,将数据集分为测试集和训练集,比例为1:4,且这两个集合互斥,涵盖整个数据集。

表1 数据集相关属性Tab.1 The Relevant Attributes of the Data Set
5.2 评价指标
5.2.1 平均绝对误差指标
式中:pi—用户的预测评分;ri—用户的实际评分;N—评分条数。
5.2.2 平均准确率指标Precision
式中:Ru—模型根据训练集用户的行为给用户做出的Top-N推荐集;Tu—用户对测试集所做出的正面评分集;N—测试用户的数目。该值越大说明所预测的项目占所有项目的比例越高,从而表明推荐算法的性能越佳
5.3 实验结果分析
5.3.1 阈值设置对算法性能的影响
在Jester-Data测试集和MovieLens测试集上设置不同的阈值,并设定用户近邻参数值为8,测试其平均绝对误差,实验结果,如图3所示。

图3 不同阈值下的平均绝对误差Fig.3 The Mean Absolute Error at Different Thresholds
从图3可以看出,随着阈值不断增大,MovieLens测试集的平均绝对误差呈先迅速下降后趋于平稳的趋势。而Jester-data测试集则先缓慢下降,再逐渐增加,最后趋于平稳。其差异的主要原因是,Jester-data数据集其测试集的规模要小于其本身的规模,当阈值过大时,无法计算Jester-data测试集的用户相似性,导致协同过滤推荐算法的推荐精度下降。而MovieLens测试集由于规模较大,用户信任关系错综复杂,无法计算用户相似性,当增加的取值时,会过滤掉一些重要程度不高的用户,有利于提高协同过滤推荐算法的精度。
5.3.2 算法性能分析
为验证所提算法的性能,选取FTCF[8]、IBCF[9]以及SemPMF[10]三种经典的协同过滤算法,在不同的环境下进行实验结果,如图4所示。算法由于在推荐过程中融合了用户的动态偏好标签和信任关系,使得推荐模型能迅速感知用户的喜好并基于用户的社会化属性选择近邻用户,向当前用户准确地推荐商品。从图6(a)和图6(b)的实验结果可以看出,与FTCF、IBCF以及SemPMF算法相比,算法在不同近邻参数k的环境下,均获得了良好的性能。
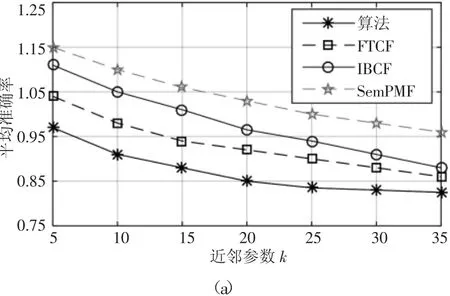

图4 不同近邻参数k的实验结果Fig.4 Experimental Results Corresponding to Different Values of Neighbor Parameter k
6 结语
针对社交网络推荐算法因信任值存在互斥导致的推荐精度下降的问题,提出了一种融合用户动态标签和用户信任关系的矩阵概率分解模型对推荐算法进行优化改进。改进算法在一定程度上缓解了传统的协同过滤算法存在的数据稀疏、用户评分不均等问题,提高了协同过滤推荐算法的性能,实验结果验证了算法的有效性。
[1]陈婷,朱青,周梦溪.社交网络环境下基于信任的推荐算法[J].软件学报,2017,28(3):721-731.(Chen Ting,Zhu Qing,Zhou Meng-xi.Trust-based recommendation algorithm in social network[J].Journal of software,2017,28(3):721-731.)
[2]Akulwar P,Pardeshi S.Bayesian Probabilistic Matrix Factorization-A dive towards recommendation[C].International Conference on Inventive Computation Technologies,IEEE,2017.
[3]Zhao Hai-yan,Wang Sheng-sheng,Chen Qing-kui.Probabilistic matrix factorization based on similarity propagation and trust propagation for recommendation[C].Conference on Collaboration and Internet Computing,IEEE,2016:90-98.
[4]高发展,黄梦醒,张婷婷.综合用户特征及专家信任的协作过滤推荐算法[J].计算机科学,2017,44(2):103-106.(Gao Fa-zhan,Huang Meng-xing,Zhang Ting-ting.Collaborative filtering recommendation algorithm based on user characteristics and expert opinions[J].Computer Science,2017,44(2):103-106.)
[5]Li Gai.Pairwise probabilistic matrix factorization for implicit feedback collaborative filtering[C].International Conference on Security,Pattern Analysis,and Cybernetics,IEEE,2014:17-25.
[6]张金萍,白广彬.基于主元分析与KNN算法的旋转机械故障识别方法[J].机械设计与制造,2017(6):23-25.(Zhang Jin-ping,Bai Guang-bin.Fault recognition method of rotating machinery based on principal component analysis and KNN algorithm[J].Machinery Design&manufacture,2017(6):23-25.)
[7]陆坤,谢玲,李明楚.一种融合隐式信任的协同过滤推荐算法[J].小型微型计算机系统,2016,37(2):241-245.(Chen Kun,Xie Ling,Li Ming-chu.Research on Implied-trust Aware Collaborative Filtering Recommendation Algorithm[J].Journal of Chinese Computer Systems,2016,37(2):241-245.)
[8]Liu Jun-tao,Wu Cai-hua,Xiong Yi.List-wise probabilistic matrix factorization for recommendation[J].Information Sciences,2014,278(10):434-447.
[9]Bokde D,Girase S,Mukhopadhyay D.Matrix factorization model in collaborative filtering algorithms:a survey[J].Procedia Computer Science,2015,49(1):136-146.
[10]Liu Zi-qi,Wang Yu-xiang,Smola Alexander.Fast differentially private matrix factorization[C].Proceedings of the 9th ACM Conference on Recommender Systems,ACM,2015:171-178.
猜你喜欢
卫星应用(2022年7期)2022-09-05
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
环球慈善(2019年6期)2019-09-25
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
桃之夭夭B(2017年2期)2017-02-24
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
高中生·青春励志(2014年11期)2014-11-25
