
基于决策树C5.0算法的员工职称晋级评估研究
2018-06-07 15:55涂波,张炜,胡文,张健伟,冯媛媛
中国管理信息化 2018年8期
涂波,张炜,胡文,张健伟,冯媛媛

[摘 要]本文在某企业人力资源管理系统数据库的基础上,利用数据挖掘技术对企业职工的人事档案信息进行深度挖掘。基于决策树的C5.0算法,构建企业员工职业晋升的评判模型,生成职业晋升评判规则集,从而实现对企业员工职业晋升的自动评判,并针对不同员工进行定向信息推送,帮助人事部门有效提高管理效率,为企业实现人力资源的优化配置提供助力。
[关键词]人事档案;数字化;人力资源管理;决策树
doi:10.3969/j.issn.1673 - 0194.2018.08.029
[中图分类号]TP311.13 [文献标识码]A [文章编号]1673-0194(2018)08-00-02
0 引 言
企业的人事档案管理信息系统已保存了大量的员工档案信息。如何在海量的信息中快速、准确地获取、分析信息,进而提供更加个性、精准的服务是摆在企业人力资源管理部门面前的一个重要问题。其中,如何通过对系统中庞大的人事档案数据进行数据挖掘分析,尝试找出数据之间隐含的关联关系,构建员工的多维能力模型,进而据此实现职称升级推荐功能,为企业优化人力资源管理提供科学依据,丰富完善人事档案管理信息系统的智能应用是企业探寻人力资源数据挖掘的核心应用点。
1 算法的选择
在进行数据挖掘时,可以通过构建分类模型实现对数据的全面刻画以及对新数据的分类预测。数据分类一般包括两个阶段,学习阶段通过对历史数据的深度学习构建分类模型,分类阶段则利用模型对给定数据进行分类预测。决策树是用于分类和预测的主要技术之一,通过将大量数据有目的地分类,从中找到一些有价值的信息供决策者作出正确判断。
1.1 决策树算法及特点
决策树学习是以实例为基础的归纳学习算法,着眼于从一组无次序、无规则的事例中推理出决策树表示形式的分类规则。它采用自上而下的递推方式,在决策树的内部节点进行属性值的比较,并根据不同属性判断从该节点向下的分支,然后进行剪枝,最后在决策树的叶节点得到结论。决策树的每个节点都有一定量的样本,从根节点开始往下各节点样本量逐级减少,决策树算法挖掘其实是对数据进行不断分组的一个过程。决策树的类型有两种,使用哪种类型的树取决于输出变量的类型,输出变量为分类型变量,则选用分类树;输出变量为连续型变量,则使用回归树。
1.2 常用的决策树算法
基于决策树的分类有很多实现算法,比较常用的主要有ID3算法、C4.5算法、C5.0算法、CART算法等。
1.2.1 ID3算法
ID3算法是较早提出并被普遍使用的决策树算法。在信息论中,期望信息越小,那么信息增益就越大,从而纯度就越高。ID3算法的核心思想就是以信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行分裂。
1.2.2 C4.5和C5.0算法
C4.5算法是对ID3算法的一种改进和扩充,克服了ID3算法应用信息增益选择属性时偏向选择取值多的属性的不足,并且在树的构造过程中就可以进行剪枝,且能够完成对连续属性的离散化处理。C5.0是C4.5应用于大数据集上的分类算法,核心算法与C4.5保持一致,主要在执行效率和内存使用方面进行了改进。相比C4.5,C5.0在处理数据遗漏和输入字段较多的问题时更加稳健,可以提供更强大的技术来提升分类的精度。
1.2.3 CART算法
CART算法是一种二分递归分割技术,把当前样本划分为两个子样本,使生成的每个非叶子结点都有两个分支,因此CART算法生成的决策树是结构简洁的二叉树。CART算法的特点是只能生成二叉树,即每个父节点只能生成两个子节点,在确定分组变量时主要根据Gini系数来进行选择。
ID3、C4.5、C5.0、CART算法都有各自的特点和适用范围。ID3算法选择最佳分组变量使用的标准是信息增益值,存在选择属性时会偏向于选择值多的缺陷。C4.5算法虽然修正了ID3算法的不足,但其算法本身只能处理留驻在内存中的数据集,并不适用于大数据集的处理,数据量的大小会直接影响运算的效率。CART算法只能生成二叉树,属性所受局限较大。C5.0算法是用信息增益率来确定最佳分组变量和最佳分割点,相较C4.5算法拥有更强大的数据处理技术,耗用内存更小,分类精度更高,适用于处理数据量较大且不在内存中存储的数据集。
经过对以上几种方法的综合比较,本文选择用C5.0算法生成决策树来对企业员工的职业晋升进行评判分析。
2 基于C5.0算法的职业晋升评判分析
在已有系统用户信息数据库的基础上,可以借助数据挖掘技术对企业职工的人事档案信息进行深度挖掘。基于决策树的基本思想及C5.0算法,构建企业员工职业晋升评判模型,生成职业晋升评判规则集,根据企业员工的实际工作情况判断其是否能够晋升,并针对不同员工进行定向信息推送,如图1所示。
在构造决策树模型时,需要从多方面对企业员工的人事档案信息进行综合考量。本文以员工年龄、学历、工龄、工资和是否晋升等基础信息为例,基于C5.0算法构造决策树模型,如表1所示。根据员工的基础信息,选择年龄、学历、工龄、工资作为决策属性集,以“是否晋升”作为类别标识属性。C5.0算法的核心是通过信息增益率来判定决策属性,选择信息增益率最大的属性作为决策属性。
将员工基础信息数据表示为训练样本数据集D,其中决策属性年龄、学历、工龄、工资分别用A1、A2、A3、A4來表示。训练样本数据集D中总共有15个元组,分类属性将这15个元组分成两个子集,每个子集中对应的元组个数分别为8和7。由此可以计算得到集合D关于分类的期望信息量。
(1)
假设将训练元组D按决策属性A进行划分,则A对D划分的期望信息如下。
(2)
决策属性的信息增益分别如下。
(3)
属性A的信息增益率如下。
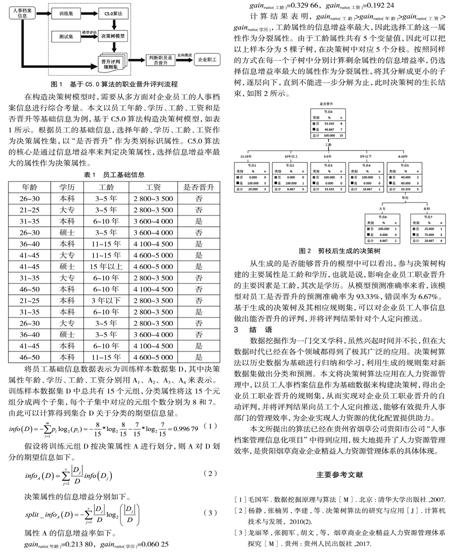
gainratio(年龄)=0.213 80,gainratio(学历)=0.060 25
gainratio(工龄)=0.329 66,gainratio(工资)=0.192 24
计算结果表明,gainratio(工龄)>gainratio(年龄)>gainratio(工资)>
gainratio(学历),工龄属性的信息增益率最大,因此选择工龄这一属性作为分裂属性。由于工龄属性共有5个变量值,因此可以把以上样本分为5棵子树,在决策树中对应5个分枝。按照同样的方式在每一个子树中分别计算剩余属性的信息增益率,仍选择信息增益率最大的属性作为分裂属性,将其分解成更小的子树,逐层向下,直到不能进一步分解为止,此时决策树的生长结束,如图2所示。
从生成的是否能够晋升的模型中可以看出,参与决策树构建的主要属性是工龄和学历,也就是说,影响企业员工职业晋升的主要因素是工龄,其次是学历。从模型预测准确率来看,该模型对员工是否晋升的预测准确率为93.33%,错误率为6.67%。基于生成的决策树及其相应规则集,可以对企业员工人事信息做出能否晋升的评判,并将评判结果针对个人定向推送。
3 结 语
数据挖掘作为一门交叉学科,虽然兴起时间并不长,但在大数据时代已经在各个领域都得到了极其广泛的应用。决策树算法以历史数据为基础进行归纳和学习,利用生成的规则集对新数据集做出分类和预测。本文将决策树算法应用在人力资源管理中,以员工人事档案信息作为基础数据来构建决策树,得出企业员工职业晋升的规则集,从而实现对企业员工职业晋升的自动评判,并将评判结果向员工个人定向推送,能够有效提升人事部门的管理效率,为企业实现人力资源的优化配置提供助力。
本文所提出的算法已经在贵州省烟草公司贵阳市公司“人事檔案管理信息化项目”中得到应用,极大地提升了人力资源管理效率,是贵阳烟草商业企业精益人力资源管理体系的具体体现。
主要参考文献
[1]毛国军.数据挖掘原理与算法[M].北京:清华大学出版社,2007.
[2]杨静,张楠男,李建,等.决策树算法的研究与应用[J].计算机技术与发展,2010(2).
[3]龙丽琴,张拥军,胡文,等,烟草商业企业精益人力资源管理体系探究[M].贵州:贵州人民出版社,2017.
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
知音励志·社科版(2016年9期)2016-11-09
企业导报(2016年20期)2016-11-05
中国市场(2016年35期)2016-10-19
中国市场(2016年35期)2016-10-19
商(2016年27期)2016-10-17
商(2016年27期)2016-10-17
大众理财顾问(2016年8期)2016-09-28
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
