
探测车占有率对宏观基本图估计精度的影响
2018-10-11 12:29江勇东卢守峰陶黎明谢耀漩
交通科学与工程 2018年3期
江勇东, 卢守峰, 陶黎明, 谢耀漩
(1.长沙理工大学 交通运输工程学院,湖南 长沙 410114; 2.苏州市运输管理处,江苏 苏州 215008)
宏观基本图是一种直观的城市交通流宏观模型。交通管理者通过宏观基本图可准确掌握交通状况,采取相应的交通控制策略来提高交通效率。学者们对宏观基本图的研究方法可归纳为解析法和实验法。Geroliminis[1]等人首次利用宏观基本图(macroscopic fundamental diagram,简称为MFD)的概念,定义了城市路网中的空间平均流量、密度和速度之间的关系。Buisson[2-4]等人分别用检测器数据、仿真数据及出租车GPS数据,验证了宏观基本图的存在。Daganzo[5-7]等人利用解析法,构造了宏观基本图。这类方法要求路网均质;否则,只能得到宏观基本图的上界。Leclercq[8]等人提出用实验法构建的宏观基本图更准确。
近年来,一些学者通过仿真手段研究了探测车占有率对宏观基本图和交通状态变量估计精度的影响。Gayah[9]等人提出一种利用探测车数据和宏观基本图间接估计路网密度的方法,研究结果表明:探测车数据占有率和取样时间间隔越高,密度的估计越准确。Nagle[10]等人对比分析了不同探测车占有率得到的各交通指标(平均流量、密度、速度及积累流量)的准确度。Du[11]等人对比了根据路段探测车占有率和OD间探测车占有率估计宏观基本图的精度,发现用OD间探测车占有率估计宏观基本图的精度更为准确。Bhaskar[12-13]等人提出一种准确估计车辆行程时间的模型,验证了该模型的有效性,并用该模型构建宏观基本图。这些研究大部分都是利用仿真数据或GPS数据检验宏观基本图和交通状态变量估计的准确度,而利用车牌识别的实测数据开展研究的鲜见。因此,作者拟基于城市卡口自动识别的车牌数据,建立宏观基本图。通过取样车牌数据量来控制探测车占有率,分析不同探测车占有率和交通状况对交通密度估计准确度的影响。
1 数据准备
随着城市智慧交通的建设和发展,出租车GPS、蓝牙、线圈感应器及自动识别车牌等数据源越来越丰富,为建立数据驱动的交通模型提供了重要支撑。出租车GPS是一种有效的探测车数据源,但空间分布不均匀,且出租车在时空分布上与社会车辆有所不同。而自动识别车牌数据包含了所有车辆的信息,为研究探测车占有率对交通指标估计的准确度提供了数据基础。
1.1 自动识别车牌数据
在20世纪90年代,一些学者就开始对车牌识别进行研究,至今车牌识别技术(automatic number plate recognition,简称为ANPR)已日渐成熟,且中国车牌格式统一,自动识别车牌的准确率达95%以上。中国大中城市的主要道路交叉口都设有卡口监控系统,该系统具有全天候自动记录并识别的特点。
卡口监控系统在各交叉口进口道上方均设置了视频检测器,可记录经过车辆的车牌、日期、时间、车道、进口道方向、视频检测设备编号、车牌颜色及车牌种类等信息,自动识别车牌数据是由Oracle数据库储存的。利用PL/SQL Developer,对该数据进行了筛选,只选取与本研究相关的数据,见表1。
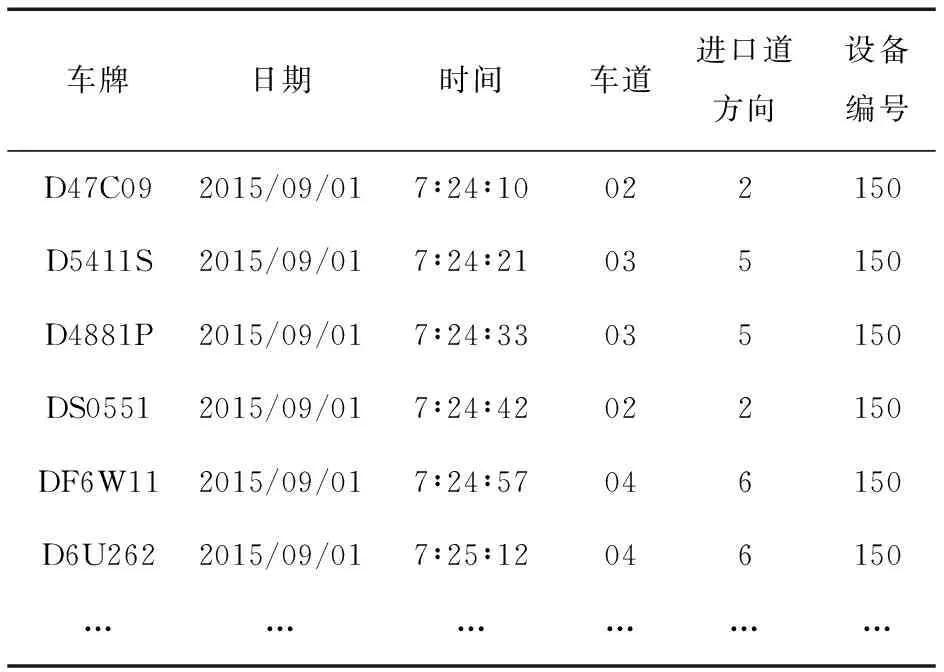
表1 自动识别车牌数据Table 1 Automatic number plate recognition data
车辆的运行轨迹如图1所示。在图1中,li是路段长度,T是研究时间间隔。如果上、下游都提取到该车牌,则该车辆(线a)完整地经过该路段。若仅上游提取到车牌,则该车辆驶向路段吸引源;若仅下游提取到车牌,则该车辆由路段发生源驶出。

图1 车辆轨迹的时间距离窗Fig. 1 Time-space window of vehicle trajectories
1.2 研究范围
自动识别车牌数据的检测时间为2015年9月1日7∶00∶00-22∶00∶00,研究时间间隔取10 min。本试验研究路网为中国某二线城市城区道路,路网范围约5 km×4.5 km,如图2所示。其中,有66%的路段为双向4车道,30%的路段为双向2车道,4%的路段为双向6车道,路网呈方格网状,路网条件较均质,如图2所示。在图2中,交叉口标有的数字表示该交叉口装有卡口,可以获取车牌数据。通过对所有道路的车牌数据进行比对,发现湖西路各路段上、下游车牌匹配率最高,因此,对湖西路进行了研究。湖西路为双向4车道的南北向道路,长约2.6 km。
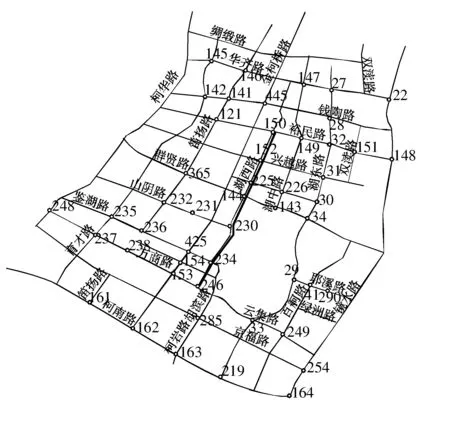
图2 研究路网Fig. 2 Road network
路段上、下游车流的关系如图3所示。经过上游车道号为9,7和5的车辆驶入路段i,经过下游车道号为6,7和8的车辆是由路段i驶出。对于路段i,上游和下游的累计车辆数可分别由经过对应车道的车辆数统计所得。
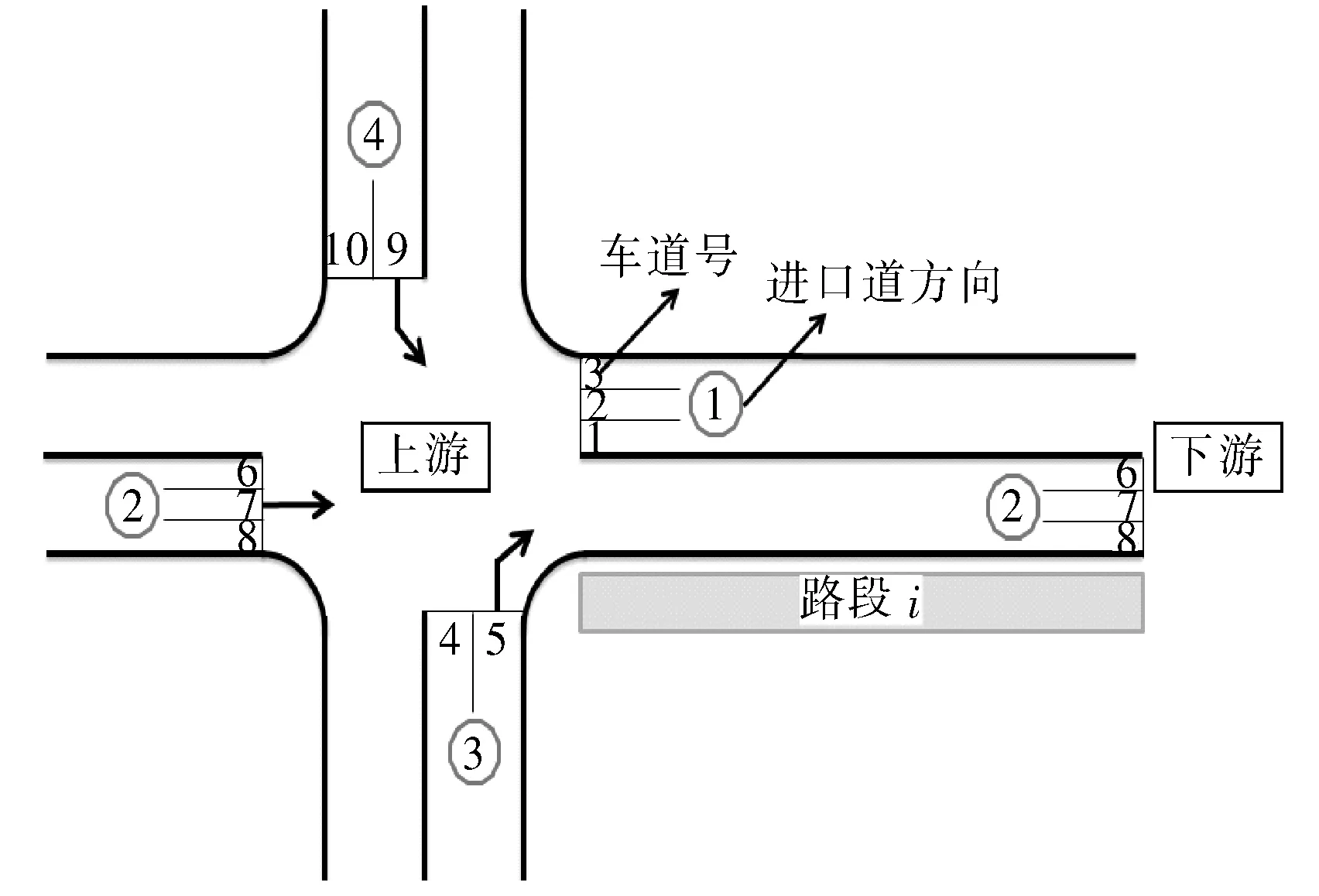
图3 路段上、下游车流的关系Fig. 3 The relationship between the upstream and the downstream traffic
2 宏观基本图的构造
对于任意路段的任意时间段,如果所有车辆都完整经过该路段,每辆车的出行时间和出行距离均可得到,可根据Edie定义[8]构建宏观基本图。但是,实际路网中存在路段的发生源和吸引源,且这部分车辆的轨迹信息难以获取。因此,本研究基于自动识别车牌数据,利用CUPRITE模型[12]进行宏观基本图的构建。完整经过路段的车辆可视为CUPRITE模型中的探测车,CUPRITE模型的建立步骤如图4所示。该模型的优势在于可根据固定检测器数据和少量的探测车数据,估计较精确的宏观基本图,且对于宏观基本图密度的估计非常精确,但宏观基本图流量的估计存在着一定的误差。
1) 在研究时间间隔T内,分别画路段的上游累计曲线U(t)和下游累计曲线D(t)。
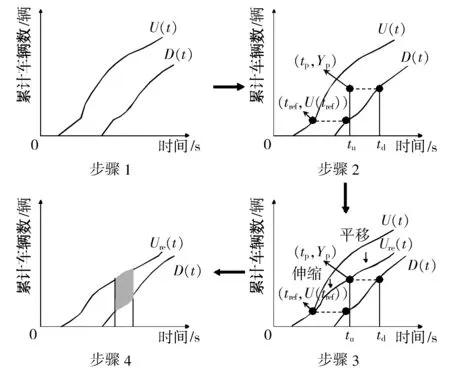
图4 CUPRITE模型步骤Fig. 4 The steps of the CUPRITE model
2) 对于任意一辆探测车,其行驶时间为td-tu。其中:tu为该探测车经过上游进口道时间;td为该探测车经过下游进口道时间。固定下游累计曲线D(t),根据探测车的行程时间,可得到上游曲线应该经过的点(tp,Yp)。
3) 已知控制点(tref,U(tref))和应该经过的点(tp,Yp),将上游累计曲线U(t)伸缩和平移可以得到修正后的上游累计曲线Ure(t),使得原始上游累计曲线的点U(t)全部落在Ure(t)上。设纵坐标平移量为correction,纵坐标伸缩比例为scale,其表达式为:
Ure(t)=U(t)+correction。
(1)
correction=
(2)
(3)
4) 对于每个时间间隔,修正后的上游累计曲线Ure(t)和下游累计曲线D(t)间的面积即为路段i的车辆数。将积分所得面积之差除以时间间隔T、路段长度li及车道数ni,得到路段密度Ki。路段流量Qi可由下游交叉口进口道累计车牌数量得到。
(4)
将各路段的密度Ki和流量Qi进行加权,得到湖西路的密度K和流量Q,如图5所示。

图5 湖西路宏观基本图Fig. 5 MFD of the Huxi Road
(5)
(6)
3 宏观基本图密度估计的精度分析
3.1 不同探测车占有率的宏观基本图密度估计的精度
探测车占有率定义为上、下游匹配的车牌数量与下游检测的车牌总数量的比值。通过取样上、下游匹配的车牌数量来调整探测车占有率ρ;根据全部车牌数据,绘制累计曲线;通过CUPRITE模型得到的各时间间隔的路段密度Ki是最准确的,如:式(4);再利用式(6),得到准确的宏观基本图密度K,如图6所示。在图6中,实心点表示探测车辆。对于任意路段,图6(a)为下游累计经过的20辆车,只利用第5辆车和第17辆车的出行时间对上游累计曲线进行修正,则探测车占有率为10%。图6(b)为上游累计经过的20辆车,利用第5辆车、第12辆车和第17辆车的出行时间对上游累计曲线进行修正,则探测车占有率为15%。对道路中的每一段路段均按该方法调整探测车占有率,则整条道路的探测车占有率也得到相应控制。

图6 不同探测车占有率的修正上游累计曲线Fig. 6 The redefined upstream cumulative plots with different probe penetration rates

100%。
(7)
对湖西路的不同探测车占有率下的宏观基本图密度估计进行了分析,如图7所示。当探测车占有率只有5%时,宏观基本图密度估计精度达到91.3%。表明:利用少量探测车数据来估计所有车辆的交通状态是一种有效的方法。当探测车占有率达到10%时,宏观基本图密度估计精度为95.9%,探测车占有率持续增加时,宏观基本图密度估计精度的增长幅度不大。考虑到城市中探测车数据的采集成本,以10%的探测车占有率可以满足精度的要求。
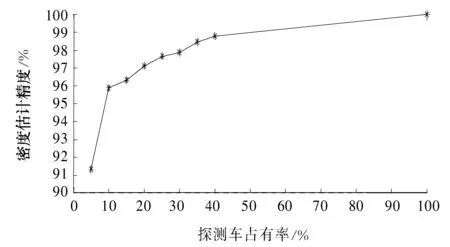
图7 不同探测车占有率的宏观基本图密度估计精度Fig. 7 The accuracy of the density estimation with different probe penetration rates
3.2 高峰期和平峰期宏观基本图密度估计精度的对比
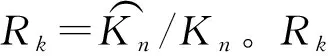
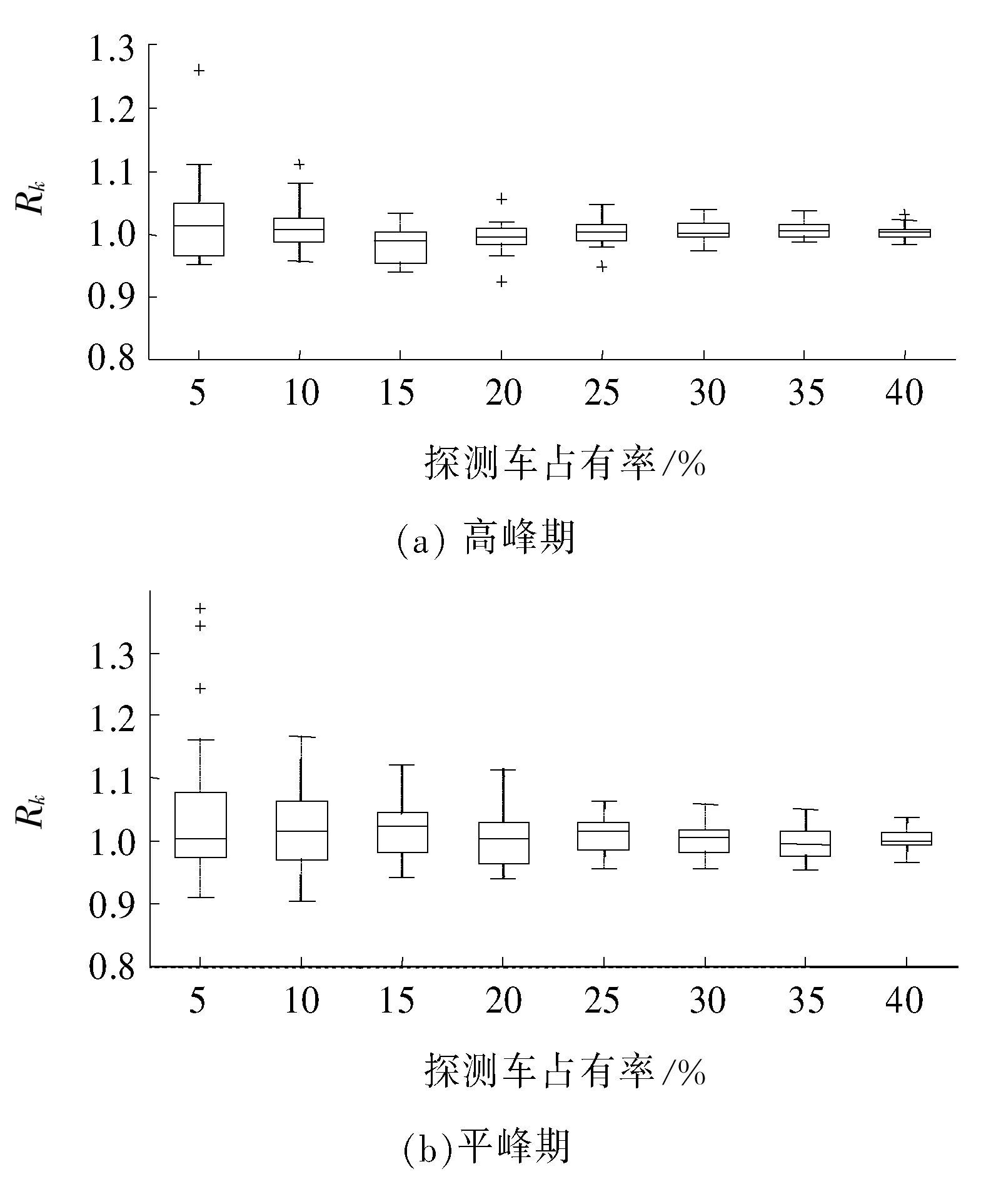
图8 通过Rk作盒图Fig. 8 Rk for box plots
在图8中,“+”的点代表异常值,最顶端和最低端的横线分别代表观测值的最大值和最小值,盒子中间的线代表中位数,盒子上、下2条线分别代表上四分位数和下四分位数。从图8中可以看出,无论探测车占有率ρ取何值,高峰期Rk的观测值区间均比平峰期Rk的观测值区间小,离散度低,表明高峰期的宏观基本图密度估计比平峰期的宏观基本图密度估计精度更准确。从图8中可以看出,当探测车占有率取10%时,高峰期的Rk的观测值为0.96~1.08,平峰期的Rk的观测值为0.90~1.17。
4 结论
利用CUPRITE模型,处理自动识别车牌数据,构建了城市道路的宏观基本图。通过取样探测车的数量,从而调整探测车占有率,并对探测车占有率取5%,10%,15%,20%,25%,30%,35%和40%时的宏观基本图密度估计精度分别进行了计算。研究结果表明:探测车占有率越高,宏观基本图密度估计越精确。当探测车占有率达到10%时,宏观基本图的估计精度达到95.9%,可替代理想的宏观基本图。因此,考虑到实际路网中数据采集、传输及处理的成本,以10%作为探测车占有率的最小参考值。对高峰期和平峰期的宏观基本图密度估计比值Rk构建了盒图。探测车占有率取10%时,高峰期Rk的观测值为0.96~1.08,平峰期Rk的观测值为0.90~1.17。表明:相同探测车占有率下,高峰期MFD密度估计观测值的离散度更小,估计精度更高。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
科技视界(2021年4期)2021-04-13
现代信息科技(2021年17期)2021-04-05
农业机械学报(2021年1期)2021-02-01
现代家电(2019年21期)2019-12-28
电子制作(2019年12期)2019-07-16
小猕猴智力画刊(2017年5期)2017-05-25
电子技术与软件工程(2017年4期)2017-03-27
电子制作(2017年22期)2017-02-02
少年体育训练(2015年7期)2015-12-05
