
基于会话时序相似性的矩阵分解数据填充
2018-10-16 03:12乔永卫张宇翔肖春景
计算机应用 2018年8期
乔永卫,张宇翔,肖春景,3
(1.中国民航大学 工程技术训练中心,天津 300300; 2.中国民航大学 计算机科学与技术学院,天津 300300;3.河北工业大学 电子信息工程学院,天津 300401)(*通信作者电子邮箱qiaoyongwei76@126.com)
0 引言
如何从混杂无序的信息中过滤出人们最关心的信息,成为“信息过载”背景下的重要任务。推荐系统通过挖掘用户交互历史分析用户的偏好和潜在兴趣,主动向用户推荐项目或服务。协同过滤 (Collaborative Filtering, CF)[ 1-2 ]是目前最流行的推荐技术,但由于数据稀疏使得它不能挖掘用户的真正的相似关系,推荐准确度降低。为了改善基本CF方法,研究人员在推荐过程中考虑用户兴趣漂移的问题,以提高精度。最流行的基于会话的协同过滤(Session-based CF)方法将用户的交互历史划分成不同阶段,利用隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)将其偏好表示成这些阶段的时序序列表示[3-6]。这些方法在一定程度上提高了推荐精度,但不仅没缓解数据稀疏性问题,反而由于将交互划分成不同阶段,导致某些阶段内很少甚至没有交互行为而加剧了数据稀疏。
目前,为了缓解数据稀疏主要有三类方法:1)通过设计更好的相似性度量来识别更相似的近邻,或利用更合理的集成策略去集成近邻用户项目评分[7-9]。2)通过机器学习方法,如贝叶斯网络[10]、奇异值分解[11]、潜在因素模型[12]、矩阵分解[13-14]等,训练一个预定义的模型,并用它来预测新项目的评分。3)近几年出现的数据填充方法[15],这些方法从评分矩阵中选择一些缺失值并在评分预测前填充这些缺失值[16-19]。Park等[16]利用综合特征工程进行了数据填充;Xue等[18]用机器学习方法平滑评分矩阵中所有的空值来提高推荐精度;Ma等[19]通过设置一个填充阈值来决定是否为用户和项目填充缺失值,如果阈值设置合适会得到较好的填充效果;文献[20]能自动识别带缺失值的项目关键集合,并利用基于用户的协同过滤进行自动填充;袁卫华等[21]利用非负矩阵分解重构矩阵来填充原始矩阵的缺失值,通过块模型划分用户-兴趣子集和物品-特征子集,最终完成TOP-N推荐;文献[22]中通过构建近邻的K层网络填充缺失值来提高预测精度;文献[23]中通过经典乘法更新规则填充评分以提高矩阵分解的性能;文献[24]中研究了如何降低在矩阵分解“软填充”中时间复杂度的问题。这些模型在一定程度上缓解了数据稀疏,但它们只考虑了评分信息,没有考虑捕获用户动态偏好的时间上下文。成韵姿等[25]提出了基于云填充和混合相似性的协同过滤推荐算法,它利用云模型填充评分矩阵,将用户间的时序影响融合到Jaccard系数相似性中;Hong等[8]提出了新的时间感知相似性挖掘间接近邻;李灿等[26]利用非精确增广拉格朗日乘子法对评分时间矩阵进行填充,并利用填充可信度和指数遗忘函数对填充评分进行加权修正。这些模型在填充或推荐过程中考虑了时序上下文,但它们只是将时间信息作为传统相似度的权值,没有考虑用户兴趣的漂移。文献[5]中提出了一个基于交叉领域CF的评分矩阵生成模型来填补现有和新用户的缺失评分,但相关领域共享知识往往隐蔽且不易获得。
为了缓解数据稀疏,本文提出基于时序相似性的矩阵分解数据填充(Data Imputation by Matrix Factorization, DIMF)方法。首先,提出基于会话的时序相似性来识别用户的近邻,它不仅考虑评分模式,而且还考虑了时间信息,以捕获用户间的实际相似关系;其次,自动抽取待填充的关键项目集合评分子矩阵并通过矩阵分解自动重构缺失值,更好地利用了影响用户和项目的潜在因素;接着,利用隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)和时间惩罚权值建立用户动态模型,并完成基于用户的协同过滤(User-based Collaborative Filtering, UCF)推荐。实验结果表明,与其他数据填充方法相比,本文方法降低了平均绝对误差(Mean Absolute Error, MAE),取得了更好性能。
1 问题定义及整体流程
1.1 问题定义

1.2 算法整体框架
基于矩阵分解的数据填充整体上分为三步:先对用户交互历史进行划分并计算用户间的基于会话的时序相似性;接着抽取用户关键项目集合并利用矩阵分解进行填充;最后利用LDA建立用户兴趣模型并完成基于用户的协同过滤推荐。具体的过程如算法1所示。
算法1 基于矩阵分解的数据填充方法。
输入 评分矩阵,时间窗大小,相似性参数,待填充评分子矩阵用户和项目数,近邻数;
输出 每个用户填充矩阵及评分预测矩阵。
1)
For 每个用户
2)
3)
End for
4)
For 每个用户
5)
计算用户间相似性,得到待填充关键项目集合,利用矩阵分解进行填充;
6)
利用LDA及时间惩罚函数得到用户兴趣漂移模型,预测用户下一阶段概率主题分布
7)
End for
8)
For 每个用户
9)
利用预测概率主题分布计算用户相似性,得到预测评分矩阵
10)
返回每个用户的填充的评分子矩阵和预测评分矩阵
11)
End for
2 基于会话的时序相似性
2.1 传统相似性缺陷分析
基于会话的CF方法通过建立用户偏好的漂移模型来提高推荐结果,但也加剧了数据稀疏,导致了由于相似性度量的失效而不能找到真正的近邻。
如图1所示,ij(rij)代表用户ui对项目ij评分rij,hl是用户交互历史用时间窗划分后的第l阶段,—表示这个阶段用户没有评分。假设u1是目标用户,u1与u2,u3的基于余弦或皮尔逊的相似性相同,因此i4将被推荐给u1。u1和u2的评分模式和随时间偏好的变化趋势是相似的,但是u1的偏好变化趋势则与u3正相反。因此传统的相似性能度量用户间评分模式的相似性,却不能度量偏好的变化趋势。
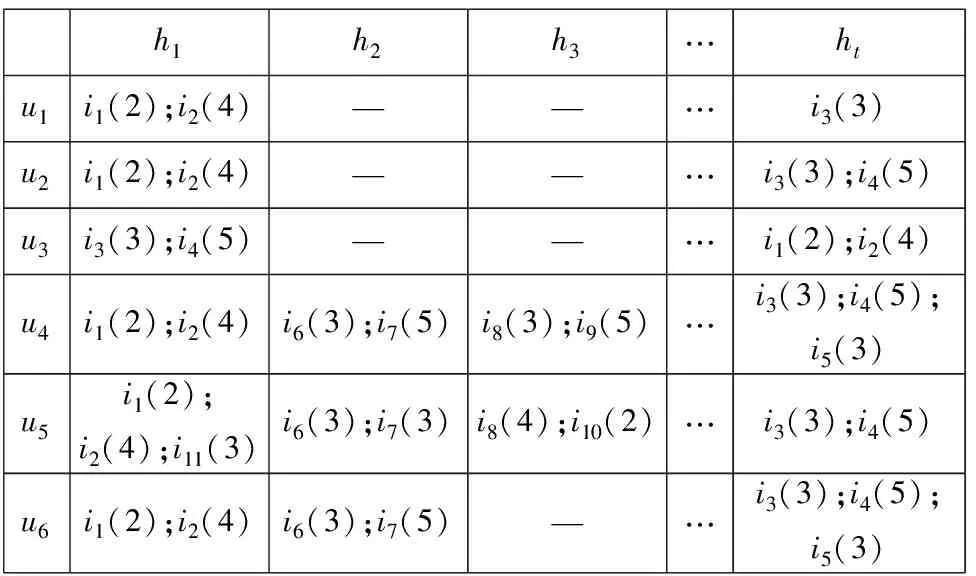
h1h2h3…htu1i1(2);i2(4)——…i3(3)u2i1(2);i2(4)——…i3(3);i4(5)u3i3(3);i4(5)——…i1(2);i2(4)u4i1(2);i2(4)i6(3);i7(5)i8(3);i9(5)…i3(3);i4(5);i5(3)u5i1(2);i2(4);i11(3)i6(3);i7(3)i8(4);i10(2)…i3(3);i4(5)u6i1(2);i2(4)i6(3);i7(5)—…i3(3);i4(5);i5(3)
图1 基于交互历史划分的用户-项目评分矩阵
Fig. 1 User-item rating matrix based on session
2.2 基于会话的时序相似性定义
针对传统相似性度量方法的不足,本文提出了一种基于会话的时序相似性度量方法,该方法不仅衡量用户间的评分模式的一致性,也反映了用户偏好随时间的漂移趋势。
定义1 时序相似性。它是每个阶段的评分模式和整个交互历史用户偏好变化趋势的综合度量,定义如式(1):
(1)

定义2 时序相异度。它是目标用户没有交互的每个阶段的差异度和整个交互历史中用户偏好差异的综合衡量,定义如式(2):
(2)
在图1中,u1和u2、u4、u5、u6在h1,h|H|有极大相似,因此u1和u2、u4、u5、u6是时序相似的。但如果近邻与目标用户行为太一致,需要为目标用户填充数据的会话里近邻也没有交互行为,例如u2,因此应选取与目标用户有交互行为的会话保持一致,而与目标用户没有交互行为的会话保持相异性的那些用户作为近邻能更好地完成数据填充,如u4和u5。
结合时序相似性和时序相异性,定义基于会话的时序相似性如式(3)所示:
Sim(ui,uk)=γSim_T(ui,uk)+(1-γ)DSim_T(ui,uk)
(3)
其中γ∈[0,1] 用于调整时序相似性和相异性比率。 如果γ=0,目标用户与近邻时序相似性差别最大,但目标用户交互行为会话可参考填充数据是最丰富的;如果γ=1,目标用户与近邻时序相似性最一致,但数据填充是困难的。因此选取合适的γ值对发现近邻去填充缺失值至关重要。
3 基于矩阵分解的数据填充
3.1 利用矩阵分解填充关键项目集合评分子矩阵

(4)
(5)
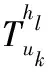
(6)

(7)

(8)
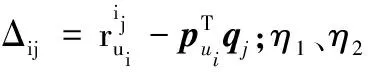
3.2 评分冲突解决
(9)
4 用户漂移模型的建立和项目推荐
4.1 利用LDA建立用户动态漂移模型
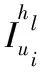
用户目前偏好更依赖于它最近喜好,也就是说在预测用户当前偏好时,用户越久远的喜好贡献越小[7]。因此,用户ui的偏好模型可表示为:
(10)
其中f(·)为指数衰减函数(范围从1到0),定义如下:
(11)
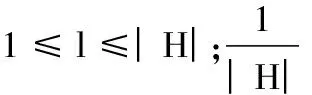
4.2 项目推荐
使用余弦相似度通过预测的概率主题分布计算所有用户间的相似性并选择用户ui的n个近邻。利用式(12)基于用户CF的集成近邻的评分完成预测。
(12)
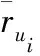
5 实验与分析
5.1 数据集
实验使用的数据集是推荐系统流行的MovieLens数据集(https://grouplens.org/datasets/movielens/),包含从2008年9月7日到2009年1月5日间共1 200位用户对3 526部电影以0.5为步长的157 961个评分(分值为1~5)。其中每个用户至少评过30部电影,每个项目至少被10个用户评分过,用户项矩阵的数据稀疏性为96.27%。实验中建立了几种不同的形式来评估算法,分别选择300、600、900位用户作为训练集,命名为M300、M600和M900,其余300位用户作为测试集,为每个用户选取项目评分数分别为10、20、30,即Given10,Given20和Given30。
5.2 评估度量
为了与其他工作一致,使用平均绝对误差作为度量标准,定义如下:
(13)
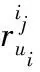
5.3 参数训练
5.3.1 时间窗口T
时间窗T的大小对邻居选择和推荐精度至关重要。T值如果太小,用户在阶段内稳定偏好不能形成;如果太大,某一阶段内的偏好可能已经迁移。为了观察时间窗T的大小对推荐精度的影响,T值从20变化到60在不同的训练集的性能如图2所示,该图表示在训练集为M300、M600、M900,评分分别为10, 20, 30时T如何影响MAE。由于数据的极度稀疏,在不同训练集下Given10的推荐结果都差于Given20和Given30。随着T的增加,MAE先下降后增加,因此需要选择适当的T值平衡用户偏好的稳定和迁移得到较好的推荐性能。在M300Given10、M300Given20和M300Given30中分别选择60、50、40,而在M600和M900中分别选60、50、50和40、60、60。
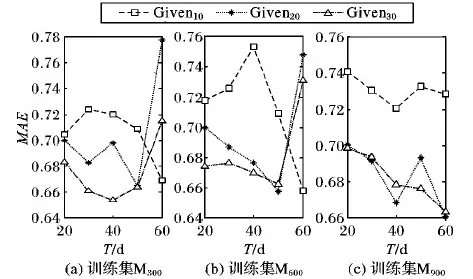
图2 时间窗口T对MAE的影响
5.3.2 相似性度量参数α,β,γ
对基于会话时序相似性中三个参数α、β、γ进行了几个实验来确定它们对最终结果影响。具体来说,α、β、γ以0.1步长从0.1变化到0.9,结果分别如图3~5所示。

图3 α对MAE的影响

图4 β对MAE的影响
图3和图4表明时序相似性和时序相异性阶段数目对评分模型同等重要,因为当α和β为最大值和最小值时MAE没有明显变化,并且在不同训练集上的趋势是相同的。随着训练用户和评分数的增加,相比会话数,每个会话内评分模式更能显著提高性能,并且α比β更明显。例如图3的M900训练集,在α=0.1时算法性能好于α=0.9性能,但是在M300和M600训练集上差别不大。它说明当数据稀疏时,时序相似性/相异性会话数目对寻找近邻是重要的,也表明基于会话时序相似性更适用于稀疏数据。
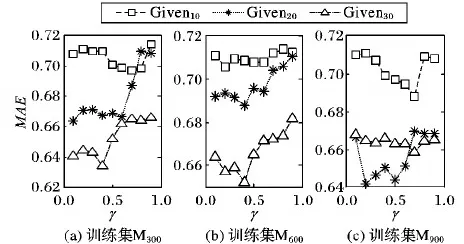
图5 γ对MAE的影响
从图5可知,M300Given10、M600Given10和M900所有三种情况在γ最大值和最小值时的MAE没有明显变化,因此时序相异性和时序相似性同等重要。但是其他训练集在γ=0.1的性能明显优于γ=0.9时的性能,这表明时序相异性在较小的训练集对发现近邻完成数据填充至关重要。
5.3.3 待填充项目集合评分子矩阵用户和项目数s,d
在数据填充过程中,s和d起着非常重要的作用,它们直接决定着选择多少近邻和多少缺失数据被填充。s和d如果太大,每个目标用户会有太多近邻和待填充数据,导致计算不准确、计算开销增大;如果太小,又会导致可利用的信息仍然很少。当它们的值从10增长到100时,MAE先降低后增长,如图6和图7所示。

图6 待填充矩阵最大用户数对MAE的影响
从图6可知,随着训练集用户和评分数的增加,近邻的最佳数目降低。例如在M300训练集,在Given10、Given20和Given30最佳性能时近邻分别为90、40、40。 相似地,在图7中随着训练用户和评分的增加,最佳的填充项目数也在减少。这主要是因为随着越来越多可用信息,可选择较少近邻和项目进行数据填充。
5.3.4 近邻数n
基于近邻的推荐算法,近邻数目n是关键。n从10变化到100的预测性能如图8所示。

图7 待填充项目数对MAE的影响
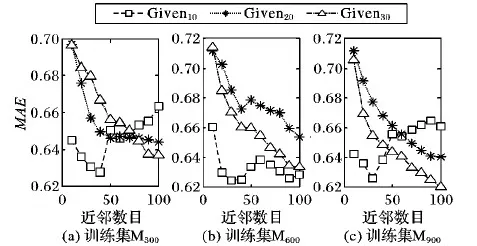
图8 近邻数n对MAE的影响
从图8可知,不同训练集上给定20和30评分时,由于随着n增加,可用信息越来越丰富,因此MAE降低。但是在Given10时,由于需要填充更多缺失值,MAE先降低后升高。在M300和M600训练集上,Given10的最佳性能优于Given20和 Given30的最佳性能。这表明本文方法更适合稀疏数据,可以更好地处理数据稀疏问题。
5.4 与其他方法的比较
为了验证方法的有效性,将本文矩阵分解数据填充方法 (DIMF)与其他数据填充方法进行了比较:
1)自适应填充 (Auto-Adaptive Imputation, AutAI)[20]:自动识别缺失数据关键集合并利用用户的交互历史进行数据填充的方法。
2)非负矩阵分解及子集划分协同过滤 (Non-negative Matrix Completion and Subgroups Partitioning, NMCSP)[21]:利用非负矩阵分解填充原始评分矩阵空缺值,并用块模型划分用户-兴趣和项目-特征子集,完成TOP-N推荐。
3)基于云填充与混合相似性的协同过滤 (Cloud model Filling and Hybrid Similarity, CFHS)[25]:利用云模型进行数据填充,并利用时序信息改进了传统协同过滤的相似性计算。
4)时间依赖的网络服务推荐 (Time-aware Web Service Recommendation, TWSRec)[11]:结合时间信息进行相似性计算和服务质量预测,并采用随机游走处理数据稀疏的方法。
5)层次近邻网络 (Hierarchy K-Nearest Neighbor, HKNN)[22]:建立多层的近邻网络填充数据的方法。
实验过程中对比方法的参数都采用最佳值,本文方法的参数都采用5.3节的最优参数,结果如表1所示。显然,即使由于用户交互历史被划分成不同会话阶段加剧了数据稀疏,本文方法仍然能够提高推荐精度,并优于对比方法。这是因为,在利用矩阵分解填充空缺值时,本文方法在计算用户间相似性时,不仅考虑了评分模式,也考虑到时间上下文,而其他方法只考虑两种情况之一;此外,本文方法在用基于近邻的协同过滤项目推荐前在填充后的评分矩阵上建立了用户偏好的漂移模型,而其他方法都是在数据填充后直接进行项目推荐。训练用户从300增加到900时,MAE降低说明所有基于填充的方法在可用信息丰富时都能产生较好性能。Given10的性能不低于Given20和Given30表明所有方法都能处理数据稀疏,但本文方法改善效果最明显,这也是因为矩阵分解重构低秩矩阵的数据填充能挖掘潜在影响因素,而其他方法仅直接利用了评分。

表1 本文方法与其他方法在MAE上的比较
6 结语
本文提出了基于会话的时序相似性度量的矩阵分解数据填充方法。该方法首先定义了基于会话时序相似性度量,它结合时间信息到评分模式捕获用户间的真实相似关系;采用矩阵分解重构基于近邻用户自动抽取项目关键集合的评分子矩阵来填充缺失值缓解了数据稀疏,挖掘了用户和项目的潜在影响因素;利用LDA和时间惩罚函数建立了用户兴趣漂移模型,捕获了用户兴趣动态。实验结果表明,本文方法的预测精度优于对比的几种填充方法。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
长江丛刊(2020年17期)2020-11-19
河北画报(2020年8期)2020-10-27
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
考试周刊(2016年82期)2016-11-01
俄罗斯问题研究(2013年1期)2013-03-11
