
一种改进过采样的不平衡数据集成分类算法
2018-10-17 12:25张菲菲王黎明柴玉梅
小型微型计算机系统 2018年10期
张菲菲,王黎明,柴玉梅
(郑州大学 信息工程学院,郑州 450001)
1 引 言
随着大数据的爆发,不平衡数据越来越多地出现在现实生活中:如肺癌病人诊断、信用卡欺骗检测、网络攻击识别以及银行破产预测等[1-4].从不平衡数据中挖掘出有价值的信息具有重要意义,且不平衡数据分类是数据挖掘和机器学习的重要环节.
如果数据集类别分布极不均匀,使得其中某个类别占支配地位,则称其为不平衡数据[5].占支配地位的数据称为多数类,而占很少一部分的称为少数类.针对不平衡数据分类,传统分类器往往对多数类的分类精度较高,而对少数类的分类精度较低.不平衡数据分类问题研究的重点是在数据分布不均衡的情况下,提高少数类的分类精度,提升分类器的性能.类分布不均衡和“困难样本”结合到一起会进一步恶化分类器的分类效果,并且主要影响少数类.因此,当处理具有“困难样本”的不平衡数据时,传统的分类器不能有效地表现数据的分布特征,分类器的性能下降[6].
针对不平衡数据分类,解决方法主要从三个层面:数据层面的方法、算法层面的方法和数据与算法层面相结合的方法.基于数据层面的方法包括过采样和降采样.现有过采样方法在过采样时充分地考虑类间数据的不平衡,而忽视类内数据的不平衡,导致合成样本的质量不高.本文提出改进过采样的不平衡数据集成分类算法,一方面对现有过采样方法进行改进,引入子簇的误分率、子簇的过采样权重和子簇的概率分布等概念,根据多数类样本把少数类样本划分为不同子簇,过采样时充分考虑类间和类内数据的不平衡,并对合成样本进行修正,提高合成样本的质量;另一方面提出改进过采样的不平衡数据集成分类模型,对不平衡数据处理分为三个阶段:噪声处理阶段、数据训练阶段和数据分类阶段,利用AdaBoost处理不平衡数据的优势,避免模型过拟合,提高分类的精度.
2 相关工作
数据采样包括数据过采样和降采样,通过采样技术可以改变原始数据分布.过采样通过添加少数类样本达到一定程度的平衡,而降采样通过删除多数类样本达到相同的目的.由于降采样删除部分多数类样本,可能删除含有重要信息的样本,容易引起信息丢失.最简单的过采样是随机过采样:从数据集中随机选取少数类样本进行复制,直到达到一定的平衡度.随机选取数据集中的样本进行复制,导致数据出现严重过拟合.
Chawla[7]在2002年提出了少数类样本合成技术,即SMOTE(Synthetic Minority Over-sampling Technique).此方法与随机过采样方法不同,它是通过在少数类样本与其k个最近邻居连线上合成新样本,合成公式如下:
Synthetic[i][attr]=instance[i][attr]+gap*dif
(1)
其中,dif为第i个少数类样本与其第j个近邻的全部属性值之差;gap∈[0,1].
传统分类器对不平衡数据中少数类的分类效果较差,当前众多研究者从过采样方面进行改进,文献[8]针对SMOTE方法盲目地对所有少数类样本进行过采样,提出了只对边界少数类样本进行过采样的方法;文献[9]根据少数类样本的分布,提出自适应合成样本的ADASYN采样方法;文献[10]提出了一种基于单边选择链和样本分布密度融合机制的过采样方法(OSLDD-SMOTE),有效避免过拟合瓶颈问题.文献[11]通过考虑多数类样本给“困难样本”分配权重的MWMOTE过采样方法.
现有过采样方法中,在一定程度上提高了少数类的分类精度,但存在以下方面的不足:1)覆盖现象较严重,合成样本的质量不高;2)少数类边界没有最大化;3)过采样时更多地考虑类间的不平衡而没有充分地考虑类内的不平衡,导致合成样本不能很好地模拟真实数据分布,分类效果不理想.
1995年Freund和Schapire提出的AdaBoost[12],是Boosting族中最著名的代表.与单一弱分类器相比,AdaBoost具有更高的分类精度及更好的泛化能力,能够避免模型过拟合.
近年来,随着AdaBoost技术的不断发展,如何将AdaBoost与其它算法相结合成为一个新的研究热点.文献[13]将SMOTE方法和AdaBoost.M2算法相结合,在每次迭代中引入合成样本,提出SMOTEBoost分类算法;文献[14]提出了联合随机降采样与Boosting的RUSBoost算法,是SMOTEBoost的变形.文献[5]提出一种新的不平衡数据学习算法PCBoost,每次迭代初始,考虑属性特征,合成新的少数类样本,平衡训练信息;文献[15]提出基于RSBoost的不平衡数据分类方法,该方法采取SMOTE过采样和随机降采样,再将其与Boosting算法相结合对数据进行分类.
上述研究中,各种改进过采样方法实现了类间数据的平衡,在一定程度上提高了少数类的分类精度.虽然有不少基于过采样与AdaBoost相结合的方法,但对于过采样方法还需进一步关注和研究.本文在过采样时充分地考虑类间和类内的不平衡,使少数类边界最大化,更好地模拟真实数据分布,提高合成样本质量,提出基于子簇划分和概率分布的过采样方法与改进AdaBoost相结合,提出基于过采样的不平衡数据集成分类算法(SDPDBoost,Sub-clusters Division and Probability Distribution-SMOTE and AdaBoost),不但能提升分类的性能,而且能从根本上提高不平衡数据分类的精度.
3 一种改进过采样的不平衡数据集成分类算法
3.1 改进的过采样方法
为了获得更加有效的样本信息,对不平衡数据集中的样本进行采样.文献[9,10]提出的过采样方法,过采样时更多地考虑类间数据的不平衡,即少数类与多数类之间的不平衡,但是没有充分考虑少数类样本分布不均导致的不平衡,即类内数据的不平衡.因此,本文在过采样时充分地考虑类间和类内数据的不平衡,采取分层聚类[16]划分多数类样本为不同多数类子簇,再根据多数类样本划分少数类样本为不同少数类子簇.
本文引入误分率和过采样权重这两个概念,误分率用来表示分类器对子簇中误分的样本个数占整个子簇中总样本个数的比值,记作Err(Cmint),则有:
(2)
其中kt表示少数类子簇Cmint中误分样本个数,mt表示少数类子簇Cmint中总样本个数.
过采样权重为子簇的误分率比重、多数类样本与少数类样本数目的差值与过采样率的乘积,记作W(Cmint),则有:
(3)
其中,Nmaj表示原始数据集中多数类样本数目,Nmin表示原始数据集中少数类样本数目,β∈[0,1]表示过采样率.
对少数类样本进行子簇划分后,根据子簇的不同误分率为其分配不同的过采样权重.由公式(3)可知,少数类子簇中误分样本数目越多,则W(Cmint)越大,即所需的过采样权重越大.根据子簇的误分率给子簇分配过采样权重,实现类间数据的平衡.
再引入少数类子簇的概率分布.在少数类子簇Cminj中,对∀x∈Cminj,x被选为“种子样本”的概率构成子簇Cminj的概率分布,记为PD,则有:
(4)
其中,yt是x的第t个多数类样本近邻,1≤t≤k.dxyi表示少数类样本x与多数类样本yi之间的欧式距离,n表示少数类子簇中样本个数,k为近邻样本个数.
根据概率分布采取轮盘赌选取“种子样本”,然后从近邻少数类样本中随机选择一个进行过采样.因为采取随机选择的方法,保证合成样本具有随机性,能更好地模拟原始数据分布.
为避免过采样某些子簇导致分类器对这些子簇的偏置,本文采取对所有少数类子簇都分配权重进行过采样,实现类内数据的平衡.在同一少数类子簇中选取“种子样本”和它的近邻样本,既可以避免选取的近邻样本离“种子样本”太远,又可以减少合成样本导致的过覆盖现象,如图1所示.
数据过采样包含3个过程:第1个过程用来划分少数类样本形成不同少数类子簇;第2个过程依据子簇的误分率和子簇的过采样权重,公式(2)、(3)是该过采样过程的核心;第3个过程根据公式(4)计算出每个少数类子簇的概率分布,根据概率分布与过采样权重,选取“种子样本”和近邻少数类样本进行过采样,采用公式(1)方法合成新的少数类样本.利用过程(2)的结果,在过程(3)中重复执行,直到迭代次数达到过采样权重,结束循环.

图1 同一子簇样本合成方法Fig.1 Same sub-cluster over-sample technique
少数类子簇划分步骤:1)初始化每个少数类样本为单独的少数类子簇;2)如果距离最近的两个少数类子簇之间没有多数类样本存在,则合并这两个少数类子簇;3)重复步骤1)、2),直到子簇之间的距离小于预先设置的阈值CThresh,结束循环.
3.2 改进过采样的不平衡数据集成分类算法
基于过采样的不平衡数据集成分类模型分为三部分:噪声处理阶段、数据训练阶段和数据分类阶段.分类模型如图2所示.

图2 基于过采样的不平衡数据集成分类模型Fig.2 Imbalanced data ensemble classification model based on over-sampling
3.2.1 噪声处理阶段
实际情况下噪声数据的存在是不可避免的,并且一定程度上影响分类器的性能.少数类样本的抗噪能力较弱,噪声数据对少数类的影响很大.
通过过采样方法合成样本,使数据集各类之间达到一定程度的平衡.如果少数类的近邻是噪声数据,则不但不会生成更多有益的样本,反而会误导分类器,进而降低其分类精度.因此,采用过采样方法之前必须对数据进行噪声处理.当基分类器均认为该样本为可疑样本时,该样本被判断为可疑样本.文献[16,17]处理可疑样本的方法是直接将可疑样本删除.由于少数类样本稀少的特征,本文采取最近邻决策机制处理可疑样本.
算法1.NoiseRemover
输入:原始数据集OriginalData;近邻数K
输出:ClearData
1.[WholeDataInst,WholeDataLabel]=splite(OriginalData);
//找到原始数据集中的所有可疑样本
2.fort=1:size(WholeDataInst)
3. model1=fitcknn();
4. label1=predict(model1,WholeDataInst [t])
5. model2=fitcsvm();
6. label2=predict(model2,WholeDataInst [t])
7. model3=fitctree();
8. label3=predict(model3,WholeDataInst [t])
9.If(label1!=Who leDataLabel [t] &&label2!=WholeDataLabel [t] &&label3!=WholeDataLabel [t])
10. SusData=[SusData;WholeDataInst[t]];
11. SusLabel=[SusLabl;WholeDataLabel [t]];
12.endif
13.endfor
//对所有可疑样本进行处理
14.InsKnn=knnsearch(WholeDataInst,SusData,’k’,K);
15.fori=1:size(SusData)
16.forj=2:K
17.ifWholeDataLabel(InsKnn(i ,j),1)==SusLabel(i,1)
18. SafeLevel(1,i)=SafeLevel(1,i)+1;
19.endif
20.endfor
21.endfor
22.if(SafeLevel==0)!=null
23.ifWholeDataLabel(ToMarkSus(:,1))==-1
24. ClearLabel(ToMarkSus(:,1))=1;
25.elseClearLabel(:,1)=-1;
26.endif
27.endif
28.if(SafeLevel==1)!=null
29. ClearData(ToRemoveSus,:)=[ ];
30. ClearLabel(ToRemoveSus,:)=[ ];
31.endif
32.OutputClearData;
噪声处理算法(NoiseRemover)如算法1所示:
1)把原始数据集OriginalData划分为样本属性集WholeDataInst,样本标签集WholeDataLabel(第1行).
2)分别采用K近邻,支持向量机和决策树分类模型对样本属性集中的样本进行预测,把分类模型都预测错误的样本集标记为可疑样本集SusData和可疑样本标签集SusLabel(第2行至13行).
3)根据步骤(2)得到的可疑样本集,求得可疑样本的K近邻样本InsKnn,根据近邻样本的标签得到可疑样本的安全水平SafeLevel(第14行至21行).
4)若样本与其近邻样本的标签都不一样,即样本的安全水平为0,则需重新标记样本的标签;若样本与其近邻样本存在一个相同的标签,即样本的安全水平为1,则需删除样本(第22行至31行).
5)输出ClearData(第32行).
3.2.2 数据训练阶段
经过噪声处理阶段后,进入数据训练阶段.在数据训练阶段的每次迭代过程中有两次权值更新:1)样本过采样之后;2)子分类器形成之后.

(5)
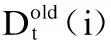

证明:采用数学归纳法证明

因此可证,当t=0时,定理1成立
2)当t=k时,假设定理1成立.即

3)当t=k+1时,

即定理1成立
证毕
第t次迭代训练结束时,得到子分类器ht:x→y,子分类器ht形成后的权值更新记为Dt+1(i),则有:
(6)
其中,SDt为第t次迭代过采样后的训练样本集,Zt为规范因子.
第t次迭代所得子分类器的训练误差记为εt,则有:
(7)
根据公式(8)中训练误差εt,得到子分类器参数记为βt,则有:
(8)
定理2.本文SDPDBoost算法的误差的界为

|{xi:xi∈ClearData∩H(xi)≠yi}|
证毕
数据训练模型包含3个过程,第1个过程初始化训练集中样本权值;第2个过程对训练集进行过采样,根据公式(5)更新样本权值;第3个过程使用临时训练集训练基本分类器,形成子分类器,根据公式(6)权值更新过程使得下一次迭代时误分的“困难样本”能够得到更多地关注.重复执行过程(2)、(3),直到迭代次数为T,得到最终分类模型.
算法2:SDPDBoost
输入:原始数据集OriginalData;迭代次数T;基本分类器h
输出:H(X)
1.ClearData=Noise_Remover( OriginalData);
2.[TrainData,TestData]=splite(ClearData);
3. Initialize the weight vector D0(i)=1/n for i=1,…,n.;
4.fort=1:T
5. [majority,minority]=splite(Data)
6. Cmaj = Orig_agg_cluster(majority,CThresh);
7.whilepp_min 8. point_dist=pdist(Cmin); 9. [pp_min,p1,p2]=min_pp(p_dist); 10.ifpp_min 11. merge(point1,point2); 12.endif 13.endwhile 14. Err_rate=computererrorate(errorCluster_min); 15. W_min=Err_rate*(Nmaj-Nmin)*β; 16.fori=1:size(Cmin) 17. PD[i]=CPD(Cmin[i]); 18.whilej 19. S2=sample(Cmin[i],PD[i],1); 20. nearsamp=nearestneighbour(S2,5,Cmin[i]); 21. snew = S2 + rand(1)*(nearsamp - S2); 22. label=predict(model,snew); 23.iflabel=-1 24. TData =[temporarydata;snew]; 25. j=j+1; 26.endif 27.endwhile 28.endfor 29.endfor 30. Update TData weights using the equation (5); 31. Train a Base Classifier ht:x y,using TData; 32.Calculate the error of the sub-classifier:εt,using the equation (7); 33.Calculate parameterβtusing the equation(8); 34. Update TData weights using the equation (6) again; 35.endfor 36.OutputH(x); 数据分类算法(SDPDBoost)如算法2所示. 1)首先对原始数据集OriginalData进行噪声处理,得到数据集ClearData;把数据集ClearData划分为训练集TrainData和测试集TestData,同时初始化训练样本权值(第1行至第3行). 2)将数据集TrainData分成多数类样本集和少数类样本集,采用分层聚类把多数类样本集划分为多数类子簇.根据得到的多数类子簇,划分少数类样本为不同的少数类子簇(第5行至第13行). 3)通过计算步骤2)得到的少数类子簇的误分率,为所有的少数类子簇都分配过采样权重.同时,通过计算每个少数类子簇中样本的概率分布,对每个子簇中样本进行过采样,同时对合成样本进行修正,把预测正确的合成样本添加到数据集temporarydata中,得到最终过采样后的数据集TData(第14行至第28行). 4)采用步骤3)得到的数据集TData作为临时训练集,根据公式5)更新样本权值,并对基本分类器进行训练得到子分类器,计算子分类器的误差,并更新训练样本的的权重(第30行至第24行). 5)重复执行步骤2)、3)和4),直到迭代次数为T,结束循环. 3.2.3 数据分类阶段 经过数据训练阶段,得到基于过采样的不平衡数据集成分类模型H(X).然后使用分类模型对测试集TestData进行分类.本文使用决策树分类器作为基本分类器,改进AdaBoost作为分类的核心.AdaBoost[12]算法思想如下:初始化时,对所有训练样本设置相同的初始权值,通过T次迭代训练若干个基本分类器为最终分类模型.该分类模型更多地关注容易误分的“困难样本”,提高分类精度,提升分类性能. 为验证本文方法的有效性,实验采用7组UCI数据集.实验采取十次十交叉验证求得平均值,作为对分类算法精度的估计.配置如下:CPU为Intel 3.4GHz ,内存为8.0GB,本文算法均用MATLAB实现. 实验设计思路:首先选择UCI中的类别不平衡数据,同目前处理不平衡的过采样方法进行比较,来验证本文提出的过采样算法的有效性.同时对不同过采样率下的各数据集的TPR值进行比较;然后对本文提出的集成分类模型与其它集成模型进行比较,验证本文方法在处理不平衡数据上能够得到更好的分类效果,更具有优势. F-measure值:用于综合反映整体的指标,计算公式如公式(9)所示. (9) 其中,P表示准确率,R表示召回率. G-mean值:用于度量在两个类上的平均性能,计算如公式(10)所示. (10) 其中,TPR表示真实正类率,TNR表示真实负类率. AUC值:用于衡量分类器性能的指标,计算如公式(11)所示. (11) 其中,FP表示实际负类误分为正类的数目,FN表示实际正类误分为负类的数目,N和M分别表示数据集中正类样本数目,负类样本数目. 本文采用F-measure、G-mean和AUC作为评价指标. 实验采用具有不同实际应用背景的7组UCI数据集.这些UCI数据集被国内外大量研究者引用.实验前去掉丢失部分信息的样本;同时,对于含有多类别的数据集划分为二类别的.实验中所需要的数据信息包含少数类样本数目(MIN),多数类样本数目(MAN)和数据集的不平衡度(IBR)等,如表1所示. 表1 本文所用UCI数据集Table1 UCI datasets in this paper 本文过采样方法与SMOTE、S-SMOTE、ADASYN和OSLDD-SMOTE在不同数据集Car、Glass、Sat、Vehicle和Prima上对F-measure、G-mean和AUC等三个评价指标进行了比较.对原始数据集经过采样后,实验中均采用MATLAB自带的C4.5分类器,本文过采样方法中的过采样率β值设置为1,实验结果如表2所示. 由表2实验数据可以看出本文过采样方法在数据集Glass、Sat和Vehicle上的评价指标均优于其它的算法;在Car中,本文算法的G-mean和F-measure优于其它算法,而AUC略低;在数据集Car上AUC略低的原因,主要是随着合成样本的增加,实际正类被预测为负类的比例略高于实际负类被预测为正类的比例;在Prima中,本文算法的F-measure和AUC优于其它算法,而G-mean略低;在Prima数据集上G-mean略低的原因是TNR降低程度高于TPR增大程度. 不同过采样率β决定所要合成的样本数目,而合成样本后形成的训练数据集对最终分类模型会产生重要影响.为验证过采样率β对本文过采样方法性能的影响,在不同过采样率下测试各数据集TPR的变化,如图3所示.其中过采样率β由0每隔0.2取一次直到1. 由图3可明显看出随着参数β逐渐增大,各数据集上的TPR逐渐上升.当β取1时,得到最优的TPR.因此,本文实验中过采样率β均设置为1. 本文算法SDPDBoost与C4.5、AdaBoost.M1、SMOTEBoost和PCBoost在5个不同数据集上的F-measure和G-mean比较结果,如表3所示. 由表3实验数据可以发现,本文算法在数据集Glass、Ve-hicle、Sat和Abalone上的评价指标均优于其它的算法;在数据集Segment中,本文算法的G-mean均优于其它算法,而F-measure略低于PCBoost算法.因此,验证本文算法并不是通过牺牲多数类的分类精度来提高少数类的分类精度. 表2 本文过采样算法与其它算法的比较(%)Table 2 Sample algorithm in this paper comparison with other algorithms (%) 图3 各数据集TPR值随着β的变化Fig.3 TPR of datasets as β variation 通过对实验结果分析可知,本文算法在不平衡度较高的数据集Sat、Abalone上的三个评价指标均优于其它算法,而在不平衡度较低的数据集Prima上的两个评价指标优于其它算法,另外一个略低于某个算法.从而验证了造成不平衡数据难以分类的主要因素并不是不平衡度的大小,而是数据集中难以识别的“困难样本”.与其它分类算法相比,基于过采样的不平衡数据集成分类算法能够较好地处理具有“困难样本”的不平衡数据,有效“拓展”少数类边界,提高分类的准确率. 表3 SDPDBoost与其它算法的比较(%)Table 3 SDPDBoost comparison with other algorithms (%) 现有过采样方法更多地考虑类间数据的不平衡,而忽视类内数据的不平衡,导致合成样本的质量不高,实际应用中对少数类样本的分类准确率偏低.本文总结了现有过采样方法的不足,提出一种基于子簇划分和概率分布的过采样方法;同时结合AdaBoost优势,提出基于改进过采样的不平衡数据集成分类算法.在标准的UCI数据集上与其它方法进行了比较,实验表明该分类模型可以明显提高少数类的分类精度,进而提升分类器的性能. 鉴于本文提出的一种改进过采样的不平衡数据集成分类算法没有针对多类别进行分类,例如,生活中所遇到的真实数据集大部分是多类别的.未来研究考虑针对多类别的基于过采样的分类算法,提高分类的精度;同时,期望本文分类模型可以解决更多领域中的不平衡的分类问题.本文提出的分类模型能否应用到多类别数据上,分类精度能否提高,是下一步研究的重点.
4 实验结果与分析
4.1 评价指标
4.2 实验数据

4.3 本文过采样方法与其它过采样方法的比较
4.4 本文分类模型SDPDBoost与其它算法的比较



5 总结与展望
猜你喜欢
电子产品世界(2022年4期)2022-04-21一重技术(2021年5期)2022-01-18计算机系统应用(2021年2期)2021-02-23领导决策信息(2018年16期)2018-09-27电子制作(2018年11期)2018-08-04电子技术与软件工程(2017年14期)2017-09-08数学学习与研究(2017年3期)2017-03-09华人时刊(2016年16期)2016-04-05科技视界(2015年24期)2015-08-22西南学林(2011年0期)2011-11-12
