
一种能耗优化的云内容分发网络
2018-10-17 12:25刘玉洁陆佃杰张桂娟
小型微型计算机系统 2018年10期
刘玉洁,陆佃杰,张桂娟
1(山东师范大学 信息科学与工程学院,济南 250014)
2(山东省分布式计算机软件新技术重点实验室,济南 250014)
1 引 言
随着互联网的不断发展,互联网用户规模的快速增长,有限的网络资源与日益增长的用户需求之间的矛盾日益突出.CDN是解决这类问题的一个主要途径.不同于其他的网络,(如无线传感网络[1]),CDN通过在用户与源服务器之间部署一层边缘服务器,使用户可以从距离较近的边缘服务器获得所需内容,缓解了网络拥塞情况,同时减少了用户的访问延迟.但是,对于中小规模的内容提供商来说,部署大型服务器来提供内容分发服务在经济上是不可行的.新兴云储存供应商,如亚马逊S3,能够实现低成本的基于云的内容分发网络,使中小型内容提供商部署内容分发网络成为可能.
当CCDN中某一服务器节点有新内容发布或者有内容更新的时候,该源节点需要发起一个复制请求,把新内容发布到其他节点上.对于这种CCDN内容副本放置问题,要在保证用户QoS的同时最大程度的降低系统的能耗开销被证明是NP难的.对于内容副本放置问题,如果源节点与每个其他节点建立一个单播连接,能耗开销较大且扩展性不好.目前大多数内容分发都采用多播树型结构,多播树型结构具有良好的扩展性且有利于降低能耗开销.Bauguion Pierre等[2]提出适用于传统内容分发问题的树型网络构建算法,并设计出一套根据副本热度部分更新的内容替换策略,该方法具有良好的扩展性.SPIDER[3]假设Internet核心网络中有专门的高带宽转发节点,然后利用这些额外的节点来构建多个树参与复制.但是实际Internet中,部署这些专门转发节点的代价是很高的.Zaman和Pallis[4,5]等人针对拓扑结构提出启发式算法,提出用户找到最近副本服务器的一种构想,通过实验证明了这一算法的可行性.叶双[6]等人介绍一种应用于视频监控系统的混合内容分发网络,该网络既克服了树状拓扑结构中节点动态性带来的数据传输延迟大的缺点,又较随机拓扑结构减少了控制开销.Gong[7]等人提出一种基于斯坦纳树问题的多播树构建方法,使用一种简单的分发模式来构建多播树,实现了低成本、低能耗.然而,已有的通过构建树型结构向给定目的节点发送内容的方式不能很好的解决云内容分发网络的内容副本放置优化问题.云内容分发网络往往拥有大量的的代理云站点,如何在众多站点中找到一个能耗优化的内容放置方案同时满足整个网络中终端用户的服务质量是亟待解决的问题.
本文提出一种基于能耗优化的云内容分发模型,首先通过关键节点选取,使副本分发尽可能覆盖整个网络.然后通过最小化分发代价的副本放置多播路由选择算法构建连接所有关键节点的分发树,以此来减少数据分发的路径长度.当用户请求数据内容时,可以就近选择存储有该内容的代理云站点为自己提供服务,而不需向源服务器发送数据请求,从而从整体上减少了内容分发的路径长度,降低了能耗.
下面介绍本文的组织结构:第二节主要描述了相关工作;第三节介绍了传统的CDN模型与CCDN模型,并提出了一种能耗优化分发模型;第四节展示了关键节点选取以及分发树构建算法;第五节进行了性能分析;第六节对本文进行总结.
2 相关工作
为了有效部署CDN中的副本,许多学者已经做了大量的研究,Sahoo[8]以及Kolisch[9]等针对CDN网络中的内容部署问题提出了最佳解决方案,使检索成本最小化.意大利都灵理工大学的Chiaraviglio[10]提出一种通过动态提供CDN服务器和网络元素的方案,能够优化内容供应商和互联网服务提供商的能耗.Aram[11]等人研究了城市内容分发网络中最优副本服务器部署和内容放置问题,提出了一种优化设计,使服务器部署成本最小化.Wendell[12]等人提出了一种可以有效平衡边缘服务器之间的负载的分布式服务器选择机制.胡海洋[13]等人通过分析面向内容分发完成时间的两种优化策略,制定了优化的内容分发机制.Alzoubi[14]等人通过提出负载感知IP任播CDN架构,重新评估CDN的IP任播,该架构利用路由控制机制来考虑服务器和网络负载,实现负载感知任播.然而以上方法都要求部署大量的边缘服务器,成本较高,扩展性差,很难推广应用.
随着云计算的快速发展,云存储提供商提供了快速读写能力以及低成本的可扩展性、可以帮助内容提供商应对突然的网络带宽拥挤以及可预期的增长需求.从使用成本与性能方面考虑,以现有的“云存储”结构进行CDN 服务与将大量投资花在建立自己拥有的内容分发平台或者租用类似Akamai这样的现有CDN相比是十分划算的.文献[15]提出了一种基于云的优化的视频分发服务部署方案,并深入研究了运营开销以及用户体验之间权衡问题.Salahuddin等[16]和Lin等[17],设计并实施了基于云存储的内容分发框架来协助副本放置,以便在多样化需求下实现云上的最佳内容分发.Zeng等[18]提出了一种基于QoS的贪婪启发式算法使云存储内容分发网络的副本放置最优化.但是到目前为止,云存储内容分发网络仍然没有找到很好的方法使副本放置路径最优且能够优化系统的整体能耗.本文在云分发网络的基础上建立基于多播的能耗优化分发模型,通过减少分发路径长度实现能耗优化.
3 网络模型
传统的CDN网络架构由用户、源服务器和边缘服务器组成.如图1所示,源服务器将数据副本发送给边缘服务器,当用户访问数据内容时,离用户近的边缘服务器优先为用户提供数据内容.但部署代理服务器费用高,当大量用户同时访问服务器时容易产生网络拥塞,并且可扩展性差.相反,租用云资源,建立云存储站点,经济费用低,可实现站点动态部署,并且可以定期的更新资源.

图1 传统CDN网络架构Fig.1 Traditional CDN network architecture
3.1 CCDN的组成框架
CCDN网络架构由CCDN源服务器站点以及代理云站点组成.其中,源服务器站点存储原始数据,而代理云站点可以根据用户需求动态灵活地部署.本文将代理云站点分为关键云站点和其他云站点.关键云站点即分发的目的站点,接收源站点发来的数据;其他云站点是指代理云站点中除关键云站点以外的其他站点,由于其他云站点可作为中继站点参加到副本分发的过程中,因此也称为中继云站点.如图2所示,CCDN内容运营商将内容放置到源服务器站点,源服务站点负责将数据副本发送到关键云站点,而从源服务器站点到关键云站点的副本放置过程中,我们允许中继云站点的加入以使分发路径最优从而获得较低的能耗开销.

图2 CCDN网络架构Fig.2 CCDN network architecture
3.2 能耗优化分发模型
本文将网络中的云存储站点看成节点,用R(R1,R2,…,Rn)表示包含网络中的所有节点的集合.在能耗优化分发模型中,文章首先通过K-Canopy算法确定最优关键节点个数k,然后通过K-Means聚类算法将整个网络分成k个簇,对于每个簇选出一个节点作为代表这个簇的关键节点,用集合M(M0,M1,M2,…,Mk)表示所有的关键节点.其中M0为源服务器节点,M1到Mk为每个簇中选出的关键节点.
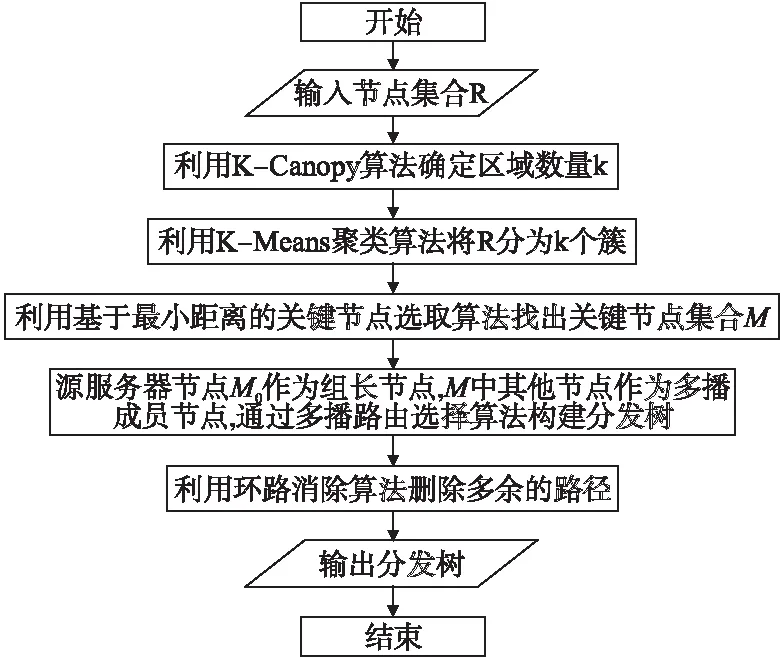
图3 能耗优化分发模型整体流程图Fig.3 Overall flow chart of energy efficient delivery model
确定好关键节点之后,本文根据最小化分发代价的副本放置多播路由选择算法建立一棵连接所有关键节点的分发树.此过程中,M0为该分发树的组长节点,M中每个簇的关键节点作为多播成员节点,通过为每一个成员节点建立一条连接到其最近邻居成员节点的方式,建立一棵连接所有多播组成员节点并且允许中继节点加入的分发树.在实际副本分发过程中,我们只需将原始数据副本上传至多播组组长节点,由组长节点沿着已经构造好的分发树向网络中的所有关键节点发送数据.整个模型的整体流程图如图3所示.
4 算 法
本章将详细介绍关键节点个数k确定算法K-Canopy、基于最小距离的关键节点选择算法、多播路由选择算法以及环路消除算法.如图4所示,是一棵连接所有多播组成员节点并且有中继节点加入的分发树.其中S标记的点代表源服务器节点M0,数据内容最初只存放在源服务器节点中;较大的点代表多播组成员节点,数据内容需要分发给所有的多播组成员节点;其他较小的点代表网路中的其他代理节点,分发过程中可作为中继节点;图中实线代表内容分发路径;虚线代表多余的分发路径,如图5所示,本文通过删除该路径来消除环路.

图4 有环路的分发树Fig.4 Distribution tree with a loop

图5 取消环路后的分发树Fig.5 Distribution tree without loop
4.1 关键节点选取算法
为了使所选取的节点能够尽可能的覆盖整个网络,避免关键节点分布不均,从而使得当有用户发送数据请求时,可以就近的选择合适的存储有该用户所需数据的云站点为用户提供服务,我们需要计算出网络的最优区域划分数量,并为每个区域找出一个关键节点构建关键节点集合M.算法1为关键节点个数k确定算法,算法1设置了两个阈值T1、T2(T1>T2),每次从R中随机选择一个节点作为一个类的中心,并将该点从R中移除,计算R中剩余点到该中心的距离,将距离小于T1的点归到该类中,将距离小于T2的点从R中移除.如此循环,直到R为空,这样就找到了整个网络最合适的区域划分个数k.
算法1.关键节点个数k确定算法 K-Canopy
输入:CCDN网络中所有节点的地理坐标集合R
输出:关键节点个数k
BEGIN
1T2←R中所有点的平均距离,T1←2×T2
2 k←0
3 WHILER不为空
4 k←k+1
5 从R中随机选取一个点r0作为中心,并将r0从R中移除
6 FOR ALL r INR
7 d←r到r0的距离
8 IF d 9 将 r归到以r0为中心的类中,并将r从R中移除 10 ELSE IF d 11 将r归到以r0为中心的类中 12 END IF 13 END FOR 14 END WHILE END 接下来通过K-Means聚类算法,将网络分成k个簇,通过算法2为每一个簇选取一个关键节点,并储存在集合M(M1,M2,…,Mk)中,选取出的关键节点作为下一步的多播组成员节点,参与数据的分发. 算法2中,Ri表示第i个簇的节点集合,(x0,y0)表示集合Ri中所有节点坐标的平均值,rj表示集合Ri中的第j个元素,|Ri|表示集合Ri的元素个数.算法2选择离(x0,y0)欧氏距离最近的节点作为每个簇的关键节点. 算法2.基于最小距离的关键节点选择算法 输入:CCDN网络中所有节点的地理坐标集合R,关键节点个数k 输出:网络的关键节点集合M BEGIN 1 对于R中的节点,用嵌入的聚类算法将其划分成k个簇Ri(1≤i≤k) 2 FOREACHRi 3 (x0,y0)←Ri中所有节点坐标的均值 4d0←∞ 5 FOREACHrj(1≤j≤|Ri|) inRi 6dj←rj到(x0,y0)的距离 7 IFdj 8d0←dj 9Mi←rj 10 END IF 11 END FOREACH 参照《国土资源环境承载力评价技术要求(试行)》,计算基础评价系统中各项指标及指数值(表2)。根据相关技术规定,当D1>0时,建设开发压力大,为超载;当D1=0时,建设开发状态为临界;当D1<0时,建设开发压力小,为可载。耕地开发压力状态指数D2>0时,耕地开发利用为可载;D2=0时,耕地开发利用为临界;D2<0时,耕地开发利用为超载。 12 END FOREACH END 开始时,副本只存放在组长节点M0中,该节点携带其他节点的位置信息.组长节点发送广播消息激活多播组中其他的成员节点.接收到该消息的节点如果是成员节点,则更新自己的多播路由表,将组地址设置为该多播组的组地址,将多播组组长地址设置为该多播组的组长地址.如果不是成员节点,则继续转发该报文,直到所有多播组成员节点都被激活.接下来,连接组长节点以及所有的多播组成员节点. 第一步,每个多播组成员节点作为发送节点广播RREQ_JOIN请求报文.RREQ_JOIN报文格式为 第二步,收到RREQ_JOIN报文的节点按照RREQ_JOIN报文所携带的反向路由信息向发送节点发送RREP_J报文.RREP_J报文格式为 择优处理过程完成后进入下一步,由于第二步中发送节点通过择优处理选定了到达多播组的路径.第三步发送节点则按逆向路由向离自己最近的多播成员节点发送MACT_Confirm消息,收到消息的多播成员节点发送MACT路由激活信息激活一条从该成员节点到发送节点的路径.收到MACT信息的邻居节点在单播路由表内添加一栏信息 算法3.多播路由选择算法 BEGIN 2 将自己加入到node sequence 3 HopCount←HopCount+1 4 Dist←当前节点到上一跳节点的距离 5 Path length←Path length+Dist 6 继续转发RREEQ_JOIN消息 7 IF 是多播组成员节点 8 NodeSourceDist←当前节点到源节点距离 9 SenderSourceDist←发送节点到源节点距离 10 IF SenderSourceDist < NodeSourceDist 11 IF u收到过该发送节点发送来的信息 12 选择HopCount最小,Path length最短的一条路径 发送RREP_J 13 ELSE 14 沿该消息的反向路由信息向发送节点发送RREP_J 15 END IF 16 END IF 17 END IF END 在构建分发树过程中,由于有其他中继节点的加入,可能导致有环路产生.如一个中继节点被不同的成员节点对共享,这个中继节点则有可能收到多余的消息,也就意味着有环产生.这一阶段检查是否存在这样的环,并取消环路. 算法4描述了如何消除环路.如果中继节点u是k组接收节点对的中继,这些节点对表示为(M11,M12),(M21,M22),…,(Mk1,Mk2).假设Mi1是比Mi2(1≤i≤k)离源节点更近的多播组成员节点,中继节点记录了从Mi1到Mi2的路径中它的上一跳和下一跳,分别用PHi和NHi表示,算法4随机选择一组接收节点对(Mj1,Mj2),并保持其信息(Mj1,Mj2,PHj,NHj)不变,对于其他的节点对(Mi1,Mi2),当Mi1≠Mj1,中继节点将信息修改为(Mj1,Mi2,PHj,NHi).最后发送MACT_Eliminate消息 本文通过仿真实验,对提出的EEDM模型进行性能分析.首先比较了不同聚类算法对树长的影响,其次将本文提出的EEDM模型构造的分发树树长与斯坦纳树树长进行比较,最后比较了使用EEDM模型与使用广播以及使用基于邻居信息广播算法(Neighbor Knowledge-Based Broadcast,NKB)[20]进行副本分发的能耗消耗. 算法4.环路消除算法 BEGIN 1 FOR ALL u(u被k对成员节点共享) 2 选择一对成员节点(Mj1,Mj2)(1≤j≤k) 3 FOR ALL i(1≤i≤k且i≠j) 4 发送MACT_Eliminate消息 5 END FOR 6 END FOR 7 FOR ALL w(收到MACT_Eliminate消息的节点) 8 IF w是PHi 9 IF w不是多播成员节点 10PHi←Mi1到Mi2路径中w的上一跳 11 发送MACT_Eliminate消息给上一跳 12 删除单播路由表中该节点的路由信息 13 END IF 14 END IF 15 END FOR END 为了验证EEDM模型是否具有良好的鲁棒性,本文比较了两种聚类算法K-Means以及基于距离的层次聚类(Hierarchical clustering)对树长的影响.本文中用n表示网络大小即网络中节点的数目.文章改变网络大小使之从100-800变化,通过算法1计算得到的关键节点个数为:12,13,15,13,12,12,13,14.如图6所示,分别使用K-Means以及基于距离的层次聚类算法,从图中可以看出,两种聚类算法得到的结果很接近,但K-Means聚类算法得到的树长比基于距离的层次聚类稍短一些. 图6 聚类算法对树长的影响Fig.6 Influence of clustering algorithm on tree length 最小生成树是在给定的点集和边中寻求最短网络使所有点连通.而最小斯坦纳树允许在给定点外增加额外的点,使生成的最短网络开销最小.然而,与最小生成树相比,斯坦纳树可以仅仅通过一个常量比率来最优化树长.本文得到的分发树长度和斯坦纳树的长度同序,他们之间的近似比不大于10. 图7 树长比较Fig.7 Tree length comparison 图7描述了当网络中节点服从正态分布,聚类算法采用K-Means时,斯坦纳树的长度以及EEDM模型构造的分发树的长度随着网络中关键节点个数变化而变化的曲线图,从图中可以看出,本文构造的分发树树长与斯坦纳树树长非常接近. 云存储内容分发网络中,能源消耗是需要考虑的重要问题,能耗是减少网络拥堵,提高网络性能,保障用户的QoS的关键,而减少节点间交换消息的数量能够减少消息复杂度,从而降低能源消耗. 云存储内容分发网络中数据分发的能耗主要由分发树树长以及构建分发树时交换消息的数量决定,且能耗花费与分发树树长、交换消息数量成正比.本文建立CCDN数据分发的能耗公式,表示为: P=T×(La+mb) (1) 其中P代表分发单位数据所产生的总能耗,单位是J;T是发送的数据包个数;L是构建的分发树的总长;m是数据分发过程中交换信息的总数量;a和b是功耗参数,分别代表发送单位长度数据和交换一条信息所需能耗.本文假设节点分布在100×100的平方区域内,设置当前分发任务为T=103个数据包,每个数据包大小为20k,并设置a=b=50nJ/bit[19]. 本文将EEDM模型副本分发时的能耗分别与使用广播以及使用NKB算法进行副本分发的能耗比较.在NKB算法中,如果节点ni的未覆盖邻居比率较大,说明ni需要更大的概率来转发消息,相反,如果未覆盖邻居比率较小那么要适当降低转发概率以减少冗余消息.然而当一个节点的未覆盖邻居比率较小,但是未覆盖邻居绝对数量较大时,也需要较大的概率来转发消息.同时当节点处在密度大的区域则需要较小的转发概率,相反稀疏区域需要较大的转发概率.因此NKB算法是基于未覆盖邻居比、绝对数量的未覆盖邻居因子以及密度因子等邻居信息来动态调整转发概率的[20]. 使用广播以及NKB算法进行副本分发时,我们已知源节点以及目的节点,源节点发送广播消息,将数据发送到所有的目的节点.使用广播以及NKB算法进行数据分发的分发树长为从源节点到达所有目的节点时所经历的路径长度,交换消息数量为从源节点到达所有目的节点时所有节点广播消息的数量. 图8 能耗比较Fig.8 Comparison of energy consumption 图8为当节点服从正态分布,聚类算法采用K-Means时,EEDM模型进行副本分发时的能耗花费与使用广播和使用NKB算法进行副本分发能耗花费的比较,从图中可以看出,EEDM模型的能耗花费要远远低于使用其他两种方式进行副本分发的能耗. 本文针对云存储内容分发网络高能耗问题,提出了一种基于云存储内容分发网络的能耗优化分发模型.主要工作有一下几个方面:首先提出了在云存储内容分发网络中能耗优化分发模型,然后介绍了该模型用到的主要算法,包括确定关键节点个数,通过聚类找出关键节点,然后根据最小化分发代价的副本放置多播路由选择算法构建包含所有接收节点的分发树,最后进行仿真实验. 实验结果表明,本文构建的分发树与斯坦纳树近似,且具有较低的能量消耗,验证了本文提出的能耗优化分发模型能够有效的节约能耗.下一步的工作是研究在用户随机到达的条件下,如何满足每个用户响应时间和服务成本QoS需求的CCDN能耗优化方法.4.2 副本放置多播路由选择算法
5 实验分析
5.1 聚类算法对树长的影响

5.2 树长分析

5.3 能耗分析

6 总 结
猜你喜欢
昆钢科技(2022年2期)2022-07-08当代水产(2021年10期)2022-01-12建材发展导向(2021年23期)2021-03-08网络安全和信息化(2019年8期)2019-08-28电子制作(2019年14期)2019-08-20计算机系统应用(2019年2期)2019-04-10华人时刊(2018年15期)2018-11-10小型微型计算机系统(2018年3期)2018-03-27党的生活·党员电教与远程教育(2017年9期)2017-10-17故事会(2016年21期)2016-11-10
