
一种改进模糊kNN的云计算故障检测方法
2018-10-17 12:25刘诚诚
小型微型计算机系统 2018年10期
刘诚诚,姜 瑛
1(云南省计算机技术应用重点实验室,昆明 650500)
2(昆明理工大学 信息工程与自动化学院,昆明 650500)
1 引 言
故障检测主要研究如何对系统中出现的故障进行检测、分离和识别,即判断故障是否发生,定位故障发生的位置和种类,以确定故障的大小和发生的时间等[1],避免或减少系统失效所带来的损失,保障了系统性能和可靠性[2].
随着云计算的应用越来越广泛,大规模高动态性的云平台以及大量的恶意攻击和管理人员的不规范操作,引起部分甚至所有服务的失效,已经成为一种常态而非罕见事件[3].一旦云计算发生异常,产生故障,将会给社会、企业、个人造成难以估量的损失.例如2014年1月Gmail出现大范围的宕机,来自欧洲、美国、加拿大、印度和其他国家的报道显示,谷歌的电子邮件服务已经关闭1;2011年4月Amazon EC2的弹性块储存(EBS)出现故障,受影响的EBS影响了EBS API,并导致在整个美国东部地区EBS对API的调用出现高的错误率和延迟率2.目前,保证云计算系统可用性是云计算面临的一个重要的挑战[4].因此,有效的云计算故障检测成为保障云计算可用性的关键.
2 相关工作
故障数据检测实质上是一种模式识别问题,通过已有的故障数据建立故障检测模型,并以此对未知的故障数据进行识别[5].将机器学习方法应用于云计算故障检测,能使系统具有更强的适应性、自学习性和鲁棒性,是目前云计算故障检测的一个重要方向,国内外相续有众多学者提出一系列用于云计算故障检测的方法.为了提升故障检测的准确性,Song Fu等[6]提出了一种云环境下基于贝叶斯与决策树的主动云计算故障管理方法,首先利用贝叶斯模型预测出故障行为,系统管理员对其进行标记,然后利用标记的故障样本点作为训练样本构建决策树,最后对未标记的样本点进行故障预测.Chirag N.Modil等[7]将贝叶斯和Snort检测系统用于云计算故障检测,贝叶斯分类器通过观察先前存储的网络事件预测给定事件是否攻击,而Snort用于检测已知攻击.实验结果表明,此方法降低了误检率,降低了计算成本.Stehle E等[8]利用计算几何学方法来检测系统故障,分为训练和检测两个阶段,在训练阶段,搜集系统正常运行时多维度监测数据,建立几何闭包以表示系统的运行状态空间,在检测阶段,将不能包含在计算几何闭包内的监测数据判断为异常状态.
但是,上述基于监督学习的云计算故障检测方法存在两个主要问题:首先,未对训练样本做处理,忽略了训练样本中噪声数据对检测准确性的影响,由于云计算故障数据通常是监测系统采集或者人工标注,这种状况下,不可避免的会出现噪声数据,如果不对噪声数据进行处理,将会影响检测准确性;其次,训练样本得不到更新,没有识别未知类型故障的能力,由于云计算系统是动态多变的,训练集并不能完全的体现每个云计算故障类型的特点,这就需要不断的完善每个类别的训练样本,否则也会影响检测的准确性.
为了解决上述问题并提高故障检测速度,本文定义了云计算故障模型并提出一种改进模糊kNN的云计算故障检测方法.首先,该方法为了区别出初始云计算故障数据训练集中噪声数据,利用基于密度聚类的方法对训练集进行预处理,计算每条数据属于对应类别的模糊度量并给噪声数据更小的隶属度;其次,为了区分故障特征的重要程度,采用模糊熵与互信息相结合方法进行故障特征加权;然后,为了让模糊kNN更适用云计算故障检测且提高检测准确性和速度,采用云计算故障特征加权以及分层检测的方法改进模糊kNN,确定待检测云计算数据的近邻训练样本;最后利用基于最大隶属度的自学习确定待检测云计算数据检测结果,检测结果包括待检测云计算数据故障类型、未知类型故障数据、训练集的更新样本.
3 定义云计算故障模型
分层模型的基本思想是根据所述类别的不同对已知样本进行分层,并根据模型对未知样本进行分类.云计算系统内部可以看作是一组服务的集合,这些服务主要分为三层[9,10]:基础设施即服务层(Infrastructure as a Service,IaaS)、平台即服务层(Platform as a Service,PaaS)、软件即服务层(Software as a Service,IaaS),其中每层涉及的内容、包含的功能各不相同.本文根据分层模型的基本思想并结合云计算系统内部结构,按照云计算故障所属的层次,将云计算故障分为IaaS 层云计算故障、PaaS层云计算故障、SaaS层云计算故障,并根据各层的架构、组件对各层云计算故障次进一步划分.图1按照云计算故障所属层次对云计算故障进行分层,图中共分为三层.
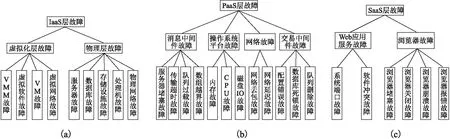
图1 云计算故障模型Fig.1 Cloud computing fault model
云计算故障模型的分层检测将从图1第一层开始判断,如果待检测云计算数据属于其中的一种或几种云计算故障,则只需沿着对应云计算故障类型的分支进行检测.而传统的方法需要对所有云计算故障类型进行比较,可以看出使用本文提出的云计算故障模型可以提升检测速度,并能对云计算故障进行定位.
由图1可以看出云计算故障数据存在数据量大、数据源多样的特点,且实际的云计算故障数据还具有数据更新速度快、类域交叉或重叠、数据存在噪声等特点[11,12].
4 基于改进模糊kNN的云计算故障检测方法
本节针对云计算故障数据的特点并结合基于监督学习的云计算故障检测方法的不足,提出一种改进模糊kNN的云计算故障检测方法,该方法分为云计算故障数据预处理、云计算故障特征加权、云计算故障检测三个部分,其中云计算故障检测包括确定待检测云计算数据的近邻训练样本和确定待检测云计算检测结果.检测的流程图如图2所示.

图2 云计算故障检测流程图
4.1 云计算故障数据预处理
云计算故障检测中,如何提高检测准确性是普遍关注的问题,而云计算故障数据训练集的质量是影响检测准确性的一个重要因素,云计算故障数据训练集类别越准确,内容越全面,检测的准确性就越高.噪声数据常常位于类边缘附近,影响了检测的准确性.
本节将针对云计算故障数据存在噪声数据问题进行预处理.通过基于密度聚类的方法,区别出噪声数据,并给每个训练样本属于对应云计算故障类型的隶属度,且对噪声数据赋予较小的隶属度.假设T={(xi,ci)|i=1,…,N}为包含一个云计算故障类型的初始云计算故障数据训练集,其中N为样本的个数,ci为xi对应的故障类型,每个训练样本xi都是一个p维的向量.首先,计算T每个样本的密度,得到一个密度为标准的集合G;然后,在G的基础上进行类中心的选取,并根据样本间的最大密度差确定噪声数据;最后,根据训练样本到类中心的距离计算每个训练样本的隶属度.具体的方法如下:
1)根据距离公式(1)计算T中训练样本xi的K个最近邻样本;
(1)
其中xil表示训练样本xi的第l个云计算故障特征,xj为T中的样本,j≠i,j=1,…,N.
2)根据(1)获得的xi的K个最近邻样本并结合公式(2)计算T中每个训练样本的分布密度,并对密度进行点排序,从而得到密度点的集合G;
(2)
其中,α为密度参数(α>1),pij为连接样本点xi和xj之间的所有路径,l为连接样本点xi和xj路径中训练样本的个数,d(xk,xk+1)为xk与xk+1之间的欧式距离公式.
3)选取密度最大的一个样本点xmax并通过欧式距离公式计算出与其最近的样本点xb;通过这两个点构造类中心a:
a=0.6×xmax+0.4×xb
(3)
4)根据公式(4)中确定的R值区别出噪声数据,当T中训练样本xi到类中心的距离d(a,xi)大于R,则该样本为噪声数据.
R=xj-a,xj满足max(density(xj)-density(xj+1))≤ε
(4)
其中,j≤N-1,density(xj)∈G,ε为调节阈值.
5)根据公式(5)计算T中训练样本的隶属度,并给噪声数据较小的隶属度.
(5)
通过对T的预处理得到云计算故障数据训练集D=(xi,ci,μ(xi))i=1,…,N,本节对噪声数据赋予较小的隶属度,能够有效地将噪声数据与有效训练样本区分开能,减少噪声数据对故障检测准确性的影响.
4.2 云计算故障特征加权
得到云计算故障数据训练集D后,将对云计算故障数据特征进行加权.文献[13]根据模糊熵值越大不确定性越大的原则进行特征的选取,目的是为了保证分类的正确率的同时减小分类时间.文献[14]以特征的模糊熵值统一确定权值,并不能很好的体现每个类特征的特点,且忽略了特征与特征之间的关系.
本文为了更好的区别云计算故障数据特征的重要程度,首先,去除D中的噪声数据得到集合D*=(xi,ci,μ(xi))i=1,…,n;然后,提出模糊熵值和互信息[15,16]相结合的方法构造云计算故障特征的权值,其中互信息常用来度量2个特征相关程度的方法[17].利用模糊熵和互信息相结合的特征权值计算步骤如下:
1)对D*中训练样本归一化,找出能代表集合D*的理想向量idt,本节理想向量通过每个云计算故障类型中所有样本的均值确定;
2)计算D*中训练样本xi与该云计算故障类型理想向量idt每个特征的相似度:
(6)
其中,xil表示集合D*中第i个训练样本的第l个云计算故障特征,idtl表示训练样本xi对应类别的理想向量的第l个特征.该类样本得到一个n×p的相似度矩阵,记为S.
(7)
3)根据S计算出每个云计算故障特征的模糊熵值,将每个云计算故障特征对应的相似度作为隶属度带入式(8)中得到对应的模糊熵值;
(8)
其中l=1,…,p为训练样本的第l个云计算故障特征.
4)根据公式(9)计算D*中训练样本第l特征与其他特征之间的互信息和;

(9)
其中,r=1,2,…,p,I(l)表示D*中训练样本第l特征与其他特征之间的互信息之和,H(r)表示D*中训练样本第r个故障特征模糊熵值,H(l,r)表示训练样本第l个特征和第r个特征的联合模糊熵值.
(10)
5)根据公式(11)计算各个云计算故障特征的权值.
(11)
其中,wl表示D*中训练样本的第l特征的权值.
通过上述云计算故障特征加权方法,可以确定每个云计算故障类型的每个云计算故障特征的权值.
4.3 云计算故障检测
本节首先确定待检测云计算数据的近邻训练样本,然后确定待检测云计算数据的检测结果.
4.3.1 确定待检测云计算数据的近邻训练样本
由于kNN方法是靠近邻来确定数据所属类别,因此对于存在类域交叉或重叠的数据来说,kNN方法较其他方法更合适[18].本节使用模糊kNN判断待检测云计算数据的近邻训练样本,并根据云计算故障数据自身的特点以及模糊kNN的不足,对模糊kNN进行改进.
针对云计算故障数据自身的特点以及传统模糊kNN的不足,主要在以下方面进行改进:
1)采用加权距离判断待检测云计算数据的近邻训练样本.传统的欧氏距离并没有体现特征对于检测的贡献不同的规律,本文采用基于模糊熵和互信息相结合的特征赋权方法.
2)根据基于云计算故障模型的分层结构进行分层检测.针对云计算数据量大、数据源多样的特点,本文根据云计算故障模型构建树状分层结构,首先对高层进行检测,然后依据高层比较结果的不同,再依次对下一层次进行检测,相比直接对所有云计算故障类型中训练样本进行计算,提高了检测速度,并能对云计算故障进行定位.
具体的步骤如下:
(1)将云计算故障数据训练集D中的故障类型按照云计算故障模型进行分层,构建成m(m≤3)层树状模型.
(2)计算待检测云计算数据与前m层云计算故障类型类中心的加权距离(前m层处理方式相同,以下以第1层做具体说明):
1)根据第4.2节提到的方法计算第1层所有云计算故障类型的特征权值,对欧式距离进行加权,加权欧式距离公式为:
(12)
其中,xs表示待检测云计算数据,atl表示第1层上第t个云计算故障类型类中心at的第l个特征,wtl表示第1层上第t个云计算故障类型的第l个特征的权值.
2)根据加权距离,在第1层的云计算故障类型中选出与待检测云计算数据最近的k1(k1≤对应层云计算故障类型数)个近邻.
(3)在前m层中,判断k1个近邻云计算故障类型中是否存在叶子节点且非全部叶子节点,如果存在,则保留该叶子节点,并和k1中非叶子节点对应的下一层故障类型一起作为待检测云计算数据的“训练样本”;如果不存在,则沿着k1个云计算故障类型对应的下一层故障类型进行检测,以此获得第m层的k1个近邻云计算故障类型;如果k1个近邻云计算故障类型全部是叶子节点,则从k1个云计算故障类型对应的训练样本中选取k2个近邻训练样本.
(4)根据第m层获得k1个近邻云计算故障类型,从k1个云计算故障类型对应的训练样本中选取k2个近邻训练样本.
通过改进模糊kNN方法可以获得待检测云计算数据的近邻训练样本.
4.3.2 确定待检测云计算数据检测结果
由于云计算数据具有更新速度快的特点,及时更新云计算故障数据训练集才能提升云计算故障检测准确性.本节根据得到的待检测云计算数据xs对应的k2个近邻训练样本,通过基于最大隶属度的自学习分析k2个近邻训练样本的隶属度来确定待检测云计算数据检测结果.
1)计算k2个云计算故障数据中最大的隶属度umax:
(13)
其中,i=1,2,…,k2表示待检测云计算数据的第i个近邻,μ(xi)表示近邻xi属于对应类别隶属度,wil表示近邻xi对应云计算故障类型的第l特征的权值.
2)根据umax大于阈值σ1且待检测云计算数据与umax对应训练样本所属云计算故障类型的理想向量的距离小于匹配阈值ρ来确定该待检测云计算数据的类别为umax对应云计算故障数据所属云计算故障类型,并将该待检测云计算数据及其类别信息加入去除噪声数据的初始云计算故障数据训练集T*;
3)根据umax小于阈值σ2来确定待检测云计算数据为未知类型故障,并将该待检测云计算数据和其类别信息加入去除噪声数据的初始云计算故障数据训练集T*;
4)跟据umax小于阈值σ1且umax大于阈值σ2来确定待检测云计算数据的类别为umax对应训练样本所属云计算故障类型.
根据云计算故障检测,可以获得待检测云计算数据的故障类型、云计算故障数据训练集的更新样本以及待检测云计算数据中属于未知类型故障的数据,并将T*作为新的初始云计算故障数据训练集.
5 实 验
5.1 实验环境
为了验证本文提出方法的有效性,本文应用eclipse4.3.0实现了相关方法,在win7系统下进行实验,并搭建基于Hadoop的云平台用以采集实验数据.其中搭建Hadoop集群包含3台主机,其中2台是从节点,1台式主节点.主机的配置如表1所示.

表1 主机配置情况Table 1 Host configuration
5.2 实验数据采集及分析
本文的云计算故障数据通过故障注入[19,20]产生,并使用基于Ganglia的性能数据采集工具收集云计算系统的性能数据,包括系统的CPU占用率、内存占用率、网络利用率、I/O占用率等属性,采集的时间间隔为5分钟.云计算故障数据采集主要是在系统运行时人为的注入故障(网络延迟故障、内存故障、CPU故障、磁盘IO故障).实验数据共用23888条数据,其中正常类别数据样本4917个,PaaS层故障样本18971个,PaaS层故障及其子故障类型、样本数如表2所示.

表2 PaaS层故障及其子故障类型、样本数
本次实验从表2和正常类别数据中随机选取1500个正常样本、1500个网络故障样本、4500个操作系统平台故障样本(包括1500个CPU故障样本、1500个内存故障样本、1500个磁盘IO故障样本)作为云计算故障训练样本,使用包含各个类别的16388个样本作为待检测云计算数据.本文实验相关参数设置为K=7,ε=0.013,σ1=0.93,σ2=0.27.
5.3 实验结果及分析
实验1.实验1就本文方法的检测准确性进行实验.检测准确性评估指标使用常用的真正率(True Positive Rate,TPR)、真负率(True Negative Rate,TNR)以及正确检测率(Correct Detection Rate,CDR).
(14)
(15)
(16)
其中,TPR刻画的是被检测为正常样本的正常样本数占所有正常样本的比例;TNR刻画的是被检测为故障样本的故障样本数占所有故障样本的比例;CDR为TPR与TNR和的均值;TP表示被检测为正常样本的正常样本数;TN表示被检测为故障样本的故障样本数;FN表示被检测为故障样本的正常样本数;FP表示被检测为正常样本的故障样本数.
实验中设置参数k1=2、k2=1~20,并将本文方法与经典的模糊kNN方法、本文方法1(加入更新训练样本)、文献[6]中决策树方法进行检测准确性对比,其中,文献[6]提出的方法是以提升检测准确性为目的;更新训练样本为本文方法运行产生的云计算故障数据训练集的更新样本,包含正常样本29个、内存故障样本33、CPU故障样本26个、未知类型故障样本6个.本文方法与模糊kNN、本文方法1、文献[6]决策树方法的实验结果如图3到图6所示.


图3 本文方法与模糊kNN、本文方法1的真正率 Fig.3 TPR of this paper's method,fuzzy kNN and this paper 's method 1图4 本文方法与模糊kNN、本文方法1的真负率Fig.4 TNR of this paper's method,fuzzy kNN and this paper's method 1图5 本文方法与模糊kNN、本文方法1的正确检测率Fig.5 CDR of this paper's method,fuzzy kNN and this paper's method 1图6 文献[6]决策树方法的TPR、TNR、CDRFig.6 TPR,TNR and CDR of the decision tree method in literature [6]
从图3到图6可以看出,本文方法的检测准确性明显高于模糊kNN方法、文献[6]决策树方法,本文方法1的检测准确性略高于本文方法.

表3 四种方法的检测结果
如图6所示,文献[6]决策树方法实验结果的横坐标表示的值为随机选取训练样本的百分比,与图3-图5其他三种方法实验结果的横坐标表示的值不一致,因此未将文献[6]决策树方法的实验结果放在图3-图5中比较.四种方法的最高真正率(TPRmax)、最高真负率(TNRmax)、最高正确检测率(CDRmax)如表3所示.
从表3可以看出,本文方法相对于模糊kNN,最高CDR提升了2.99%,相对文献[6]决策树方法,最高CDR提升了2.14%,本文方法1相对本文方法的最高CDR提升0.13%.说明本文方法的检测准确性要好于模糊kNN方法、文献[6]决策树方法,且本文的基于最大隶属度的自学习是有效的.

表4 识别未知类型故障的实验结果Table 4 Fault,sub fault type and sample number of PaaS layer
实验2.实验2就本文方法识别未知类型故障的效果进行实验.在云计算故障训练样本中任意删除所构成云计算故障模型叶子节点上的一个云计算故障类型,并在待检测云计算数据中保留该云计算故障类型的1000个样本作为未知类型故障故障,其中参数k1为2.记录本文方法识别未知类型故障的情况,实验结果如表4所示.
由表4可以看出,当未知类型故障为内存故障时,识别率最高达到90.3%,对未知类型故障的平均识别率为87.82%,说明本文的方法具有识别未知类型故障的能力.
实验3.实验3就本文方法的检测速度进行实验.本次试验分别使用本文方法与本文方法2(不包含基于云计算故障模型的分层检测的本文方法)、模糊kNN方法对待检测云计算数据进行检测,记录其检测用时并进行比较,分别运行N(N=5)次求平均时间,实验结果如表4所示.

表5 故障检测时间比较Table 5 Comparison of fault detection time
由表5可以看出,本文方法在时间上比传统的模糊kNN方法时间缩短了28.68%,本文方法用时比本文方法2提升了43.01%,且本文方法2比模糊kNN方法用时多出871ms,分析原因,是由于本文方法对训练集进行了预处理以及对特征进行了加权.综上可以看出,本文的方法是一种对云计算故障检测效果较好且速度较快的检测方法.
6 总 结
本文提出了一种改进模糊kNN的云计算故障检测方法.首先采用基于密度聚类方法来对云计算故障数据训练集进行预处理,给噪声数据赋予更小的隶属度,减小噪声数据对检测效果的影响.其次对模糊kNN进行改进,使其更适合云计算的云计算故障检测.最后根据基于最大隶属度的自学习方法,不断的更新云计算故障训练样本集,识别未知云计算故障.实验表明本文方法在云计算故障检测方面是有效的.但是本文方法还有不足的地方,没有充分考虑云计算故障转移,今后将针对这个问题进行持续研究.
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
科技创新与应用(2020年6期)2020-02-29
劳动保护(2019年3期)2019-05-16
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
客车技术与研究(2014年6期)2014-02-28
西南学林(2011年0期)2011-11-12
现代电子技术(2009年13期)2009-08-31
