
集中式蜂窝网架构下计算资源分配算法研究*
2019-02-26 00:59
广东通信技术 2019年1期
1 引言
随着移动通信技术的迅速发展,人们对移动数据的需求呈指数增长[1],现有移动通信系统中通常采用的大规模基站简单物理叠加的部署方式将不再适用。一方面,根据移动运营商的运营报告显示,移动运营商花费在基站运营维护的成本高达50%以上[2],如果继续部署大量的基站将会加剧维护成本。另一方面,传统基站的组网架构无法解决如“潮汐效应”这样的问题,造成资源浪费较为严重。因此,为了解决传统架构的上述问题,业界提出了集中式蜂窝接入网的概念和架构,如中国移动C-RAN[2],中科院计算技术研究所超级基站[3]架构。集中式蜂窝接入网中,通过集中式部署的计算资源池为移动用户业务提供计算资源需求,因此,如何对集中式的计算资源进行高效的动态分配是当前研究的重点。
目前,大规模集中式的处理资源的分配算法研究主要集中在计算机领域云计算环境下。在云计算领域中,大量的研究将处理资源的分配归纳为虚拟机的放置问题[4][5],并引入装箱问题的建模方式对其进行求解。由于并未结合通信接入网的特点如用户,业务等,因此不具有典型的参考意义。
针对上述问题,本文将结合移动通信接入网特性,对基于通用处理器的集中式蜂窝网架构下的计算资源分配算法进行研究。
在传统蜂窝网系统中,会为基带数据的处理提供专用的处理单元,如DSP,FPGA等专用芯片。而在未来基于通用平台集中式蜂窝网架构下,提倡将基带数据的处理转移到通用平台上,以提升架构的灵活性,在提供计算资源来处理峰值负载的同时,满足通信时延的要求。
在现有通用平台集中式蜂窝网架构下关于计算资源分配的研究中,通用处理器用于处理基带数据的计算资源需求并没有给出一个明确的定义。因此本文较为深入的分析了通用处理器处理基带数据的计算资源需求,并尝试给出需求模型,基于该模型研究了计算资源分配的算法,最后给出了算法的仿真结果。
2 系统模型与问题定义
已有研究结果显示,在通用平台下利用软基站处理基带数据的负载(负载定义为通用处理器处理LTE每子帧所用的时间,该时间满足LTE通信时延要求)很好的近似为调制编码阶数MCS和信道资源PRB的线性函数[6]。对于通用计算单元来说,计算单元的负载可以描述为该任务在该计算单元上的计算资源需求,通常为MIPS(Million Instructions Per Second)。
在无线通信系统中,基站的数据吞吐能力意味着基站承载移动无线业务的能力。因此着重分析基站的数据吞吐能力,尝试分析单位计算资源与其能够处理的基带数据量之间的关系,该分析将能够为集中式蜂窝网架构下计算资源的分配提供实际的指导意义。
通过分析无线通信相关知识,在一定的基站载波带宽和调制方式下,某个业务所需数据带宽(Mbps)由PRB和MCS所决定。
通过上述分析,可以将计算资源和业务带宽联系起来。因此,可以将对计算资源的需求转化为对带宽的需求。
假设如下情况:在理想的信道环境下,某个软基站内只有一个用户在做持续稳定的业务,每个LTE子帧内MCS和PRB均固定并稳定在较高的值,因此由于MCS和PRB一定,那么单位时间内的数据吞吐带宽即为一定的,假设为b(Mbps),并且计算单元处理此用户的业务数据所需的计算资源也一定,假设为c(MIPS),通过上述描述,可以描述出计算资源MIPS到数据带宽Mbps的映射关系。映射关系定义如下:

上式中µ即为当前平台下的计算资源MIPS到数据带宽Mbps之间的映射系数,单位为。通过该映射系数可以估算出当前平台下单一处理单元的极限数据带宽的处理能力。假设当前平台下计算单元能力为C(MIPS),并且计算单元配置的物理带宽足够大,如果不考虑开销,那么其所能处理的业务数据带宽极限为(Mbps)。
当多用户的任务分散在通用平台上更细粒度的调度单位,如CPU核或线程,那么就需要考虑到系统在多用户任务间进行上下文切换和控制上的计算开销。通过分析通用平台下实时操作系统常用任务调度算法,发现其复杂度为O(n2)[7][8],如果继续考虑到通信实时性较高的要求,那么多用户时任务调度的开销就不能忽略,假设任务调度的计算开销与复杂度成正比,则计算开销与用户数满足下式:

其中Ccost为与任务数相关的计算开销,单位为MIPS,那么定义为当前任务数下的“带宽损耗”Breduce:

基于上述几点的分析,结合集中式蜂窝网系统的特点,对基带池计算资源分配问题进行建模。
本章假设当前的集中式蜂窝网系统依托于前述通用平台下,基带数据均由实时性和可靠性经过优化得到保证的通用平台上运行的软基站来进行处理。在当前集中式架构中,对所有的计算资源是进行统一调度的,称之为计算资源管控。
假设一个接入网计算资源池内配置有N个计算单元实体PU。每个计算单元实体的软硬件配置相同,CPU核数为T,因此基带数据带宽处理上限也相同,均为B。某段时间内有M个用户进行移动业务,每个用户的业务需求的带宽为。计算资源的分配示意图如图1所示:
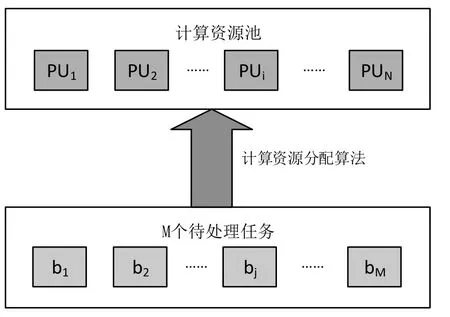
图1 计算资源分配示意图
本文考虑如何根据用户业务带宽需求,动态地分配计算资源,为此,进一步做如下假设:
①每个用户业务的处理需求被视为一个处理任务并且仅能在系统中某一个计算单元上获得;
②每个计算单元可以同时处理多个用户的业务处理需求,但是需要考虑多用户业务时计算开销带来的“带宽损耗“,其定义见公式(3);每个计算单元实体PUi上承载的用户业务带宽总和为Bi,可以表示为


每个计算单元上已承载的业务数为由于无线通信中通信时延和可靠性的要求,在某一个统一调度周期内,单一业务的处理需求需要独占一个CPU核以满足通信低时延高可靠的保证,假设PUi上的业务数为Si,可以表示为:

其中,xj如公式(5)所示。
根据上述系统模型,本文将重点研究如何根据系统中业务带宽负载需求,在保证不同用户业务带宽需求的情况下,通过动态分配计算资源,最小化系统实际开启计算单元数量。实际开启计算单元数量最小可以表示为目标函数:
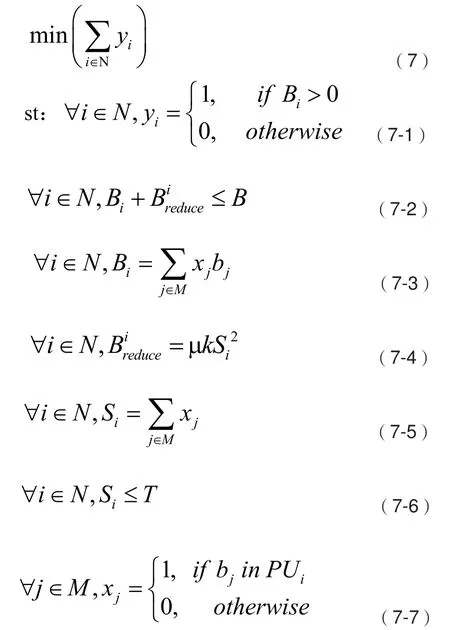
其中,(7-1)表示如果计算单元上承载了业务即表示该计算单元为开启状态,(7-2)表示每个计算单元实体PUi上承载的用户业务带宽总和Bi与多用户计算开销带来的“带宽损耗”之和不超过B,(7-3)表示计算单元实体PUi上承载的用户业务带宽总和Bi,(7-4)表示计算单元实体PUi上的“带宽损耗”(7-5)表示计算单元实体上承载的任务数,(7-6)表示每个计算单元上同时承载的业务数不超过计算单元核数,(7-7)表示任务bj是否在计算单元实体PUi,若是,则xj为1,否则为0。
通过分析问题(7)可以归结为带约束的一维装箱问题,约束在于装箱时需要考虑到箱子的容量会受到已装箱任务数量的“损耗”影响以及箱子中可装任务数量的上限,对于上述问题的最优解可通过遍历所有的资源分配组合来得到,但是遍历所有组合的方法的复杂度随着问题规模的增加而指数上升,无法在多项式时间内获得最优解,此即为NP-Hard问题[9]。针对此问题,通常通过采取相应的启发式算法来获得问题的近似最优解。
3 计算资源分配算法设计与实现
3.1 经典装箱算法分析
对于传统装箱问题会采用首次适应算法(First Fit)来求解,算法原理是根据当前目标大小从已开启箱子中选择满足目标大小的第一个箱子放入,若没有满足的箱子则新开启一个箱子放入。首次适应算法是在线算法(即随着装箱任务的到来立即进行装箱),相对于离线算法(即等到任务全部到来再统一进行装)会有性能上的损失,因此在适合离线算法的场景下通常会采用离线算法,如降序首次适应算法(FFD, First Fit Decreasing)。FFD算法首先将目标物按照降序进行重排列后再按照首次适应算法进行装箱。
FFD算法本质思想是将带宽需求较大的任务尽量优先分配,并且在算法分配的后半段,此阶段任务带宽需求相对较小,通过带宽需求较小的任务来逐渐填充前半段由于大带宽任务的聚集带来的计算单元上的碎片化空间。
上述两种算法是针对于传统无约束的一维装箱问题的近似最优解法,并且FFD的算法性能要优于FF。但是通过分析上述算法和模型,不难发现,FFD的算法性能是要低于FF算法的,主要原因是因为第二节所提到的约束问题,计算单元上的开销和任务上限的影响。FFD算法将任务排序后,前半段较大带宽任务占满计算单元容量,但是并未达到任务上限,后半段剩下大量较小带宽的任务只能开启新计算单元,此时任务上限达到而实际计算资源负载却很低,因此实际占用计算单元会更多。
由于任务数量和带宽容量受限的影响,FFD算法的离线排序优点反而在本应用场景下成了性能损失的缺点。
3.2 基于业务负载均衡(SLB,Service Load Balance)的分配算法
通过上述分析发现FFD算法的主要问题是由于任务分配不均匀导致的算法效率低下。虽然FF算法未排序,从一定程度上避免了FFD算法的问题,但是由于是在线算法,无法拥有业务负载感知的能力,因此对于一些混合应用场景下一段周期内大量大带宽任务连续出现的问题,FF算法还是会有比较明显的计算资源浪费问题,如在未来5G中以eMBB(增强型移动带宽)应用为主的混合应用场景中。
为了解决上述问题,受到负载均衡思想[10]的启发,本节提出了基于业务负载均衡的分配算法,该算法结合了交叉算法[11](简称CF算法)和FFD算法,算法思想主要是尽量将业务均匀分配到已开启的计算单元上并同时保持计算单元尽量被占满。
算法具体执行步骤如下:
①计算任务集合b中所有任务所需带宽总和Ball和任务数Sall;
(3)从集合Pα中选择前Ni个计算单元组成第i次分配集合Pβ,i,并将这些计算单元从未分配任务计算资源集合Pα中删除,对待分配任务集合b进行降序排列,并且将集合b分裂成个子集合,分别为b1,…,bt。
(4)对Pβ,i中E个计算单元Pβ,i,e执行如下步骤:
(5)对每一个子集合bx中剩余的任务,在计算资源集合Pβ,i中进行FFD算法的分配过程,直到Pβ,i中无计算单元能继续承载bx中任何一个剩余任务,将Pβ,i合并到已分配任务计算资源集合Pβ。
(6)对仍然剩余任务的子集合合并成待分配任务集合b,如果集合b中任务带宽总和,则对集合b在未分配任务计算资源集合Pα中进行降序首次适应算法的分配过程,直到所有任务的带宽需求得到满足;否则,对集合b执行步骤2到步骤6的迭代过程。
上述算法的分配过程实际是每次选取一个最大不饱和计算资源集合,然后通过CF算法将任务较为均匀的分配在该集合中每个计算单元上,避免将连续的大带宽任务或小带宽任务集中分配在同一个计算单元上,后续利用FFD算法对该计算资源集合进行填充,重复此过程直至所有任务被分配完毕。
4 实验仿真与结果分析
本节对第三节所提算法进行实验仿真,联合比较与分析,对算法性能进行了评估。
仿真参数设置见表1。

表1 仿真参数设置
仿真结果如下。
从图2中可以看出,在均匀随机分布的任务到来顺序下,FF算法和SLB算法性能几乎相同,而FFD算法性能较差,如图中所示,符合前述结论。
由于FF算法是在线算法,无法控制业务到来的顺序,因此在任务顺序满足均匀随机分布时拥有接近最优的性能表现,但是当
任务到来的顺序在某一分配算法周期内有序阶段较多时,其性能下降较为明显。如图3中所示,在某一周期内有序任务越来越多时其算法结果表现越来越差,最差时为该周期内任务全局升序有序,即该算法的性能下界。由于SLB算法具有业务负载感知能力,因此与任务到来顺序无关,对于同一任务序列,不管其中任务到来顺序如何,其总能获得近似最优性能表现。
5 结束语

图2 不同算法开启计算单元数对比

图3 FF算法与SLB算法性能比较
本文对集中式蜂窝网架构下计算资源的分配问题展开研究,首先给出了计算资源到通信业务带宽的一种映射关系,并基于此提出了集中式蜂窝网架构下计算资源的分配模型及基于业务负载均衡的计算资源分配算法。系统仿真表明,本文提出的算法在多种任务场景下均能取得近似最优解。
猜你喜欢
包装工程(2022年3期)2022-02-22
科学技术创新(2021年18期)2021-06-23
微型电脑应用(2019年10期)2019-10-23
能源(2018年8期)2018-09-21
计算机测量与控制(2017年12期)2018-01-05
计算机技术与发展(2017年12期)2017-12-20
电子与封装(2016年10期)2016-11-15
电脑知识与技术(2016年19期)2016-08-18
电气化铁道(2016年5期)2016-04-16
工业设计(2016年10期)2016-04-16
