
基于深度学习的高维光谱分类识别研究
2019-05-22 02:45许婷婷张静敏杜利婷周卫红
云南民族大学学报(自然科学版) 2019年3期
许婷婷,张静敏,杜利婷,周卫红,2
(1.云南民族大学 数学与计算机科学学院,云南 昆明650500;2.中国科学院 天体结构与演化重点实验室,云南 昆明 650011)
大天区面积多目标光纤光谱天文望远镜LAMOST (large sky area multi-object fiber spectroscopic telescope)是一架视场为5°横卧于南北方向的中星仪式反射施密特望远镜,也称为郭守敬望远镜,是当今世界上光谱获取率最高的天文望远镜,最多可同时获得4 000个天体光谱.截止2017年12月31日,包含先导巡天及正式巡天5年的LAMOST DR5数据集正式发布,其中包括4 154个观测天区,共发布了901万条光谱,高质量光谱数(S/N>10)达到了777万条,恒星参数534万组,是世界上最大的、有传承价值的天体光谱数据库,为研究银河系的形成和演化提供了基础性数据.在这些已获得的光谱数据中,有很多是光谱型未知或者是现有分类可信度低的光谱数据,因此对这些光谱数据进行分析研究,从中获得有价值的信息,提高LAMOST望远镜的科学产出,这是非常有必要的一项工作.
1 研究进展及现状
鉴于LAMOST海量的光谱数据,引入计算机程序进行自动或者半自动的分析处理显得尤为重要.随着光谱观测在天文上的广泛开展,学者们对光谱分类的方法及在天文上的应用进行了大量研究.较早的有吴永东[1]应用空间选择性滤波、多尺度形态滤波等技术对类星体光谱进行识别.邱波[2]围绕着求红移和自动分类这2个中心问题进行,并基于粗集方法的光谱分类规则挖掘.覃冬梅、胡占义、赵永恒等[3-4]提出了2种快速的恒星光谱型分类方法,一种是基于主成分分析方法利用最近邻分类器构建分类树进行光谱分类;另一种方法是结合主成分分析方法提出一种新的基于支撑矢量机的非活动天体与活动天体的自动分类方法.罗阿理[5]采用支持向量机(SVM)方法对星系的分类问题进行了研究.赵瑞珍等[6]采用基于稀疏表示的方法进行谱线自动提取的研究.
与美国的SDSS巡天项目相比较,LAMOST没有配套的测光观测,只有光谱数据,在进行自动分类时不能借助色指数,对分类识别增加了难度,虽然LAMOST的pipeline对光谱进行了初步的分类[7],但由于多种原因一些恒星的分类识别结果还不是十分理想.此后,刘超等[8]对LAMOST光谱的进一步分类研究,发现由于巨星中B型以及早期的K型光谱与A型以及晚型的G型光谱非常相似导致分类困难,尚未解决的主要问题包括巨星中的OB,K, 亚巨星支的A,G的分类精度非常低,分类识别方法和结果仍然有待完善.由以上分析可知,LAMOST光谱中还存在一些不能确定的类型或者分类可信度低的光谱数据,针对这一问题,计划将人工智能的最新成果用于光谱数据的分类识别中,即采用深度学习的方法对天体光谱数据进行分类研究并结合天体物理理论进行描述.
深度学习概念起源于人工神经网络,作为机器学习中的一个新领域由Hinton等[9]于2006 年提出,通过对人脑机制的模仿来解释图像、文本和语音等数据,训练和学习类似于人脑的神经网络.由于深度学习的优势在于样本越大,分类精度越高,得益于LAMOST光谱数据的大样本优势,有理由相信将深度学习方法应用于LAMOST光谱数据的分类会取得较好结果.
2 数据预处理
从LAMOST 巡天项目发布的DR5数据库中随机选取30 000条恒星光谱,所选取的数据已被LAMOST Pipeline分为F、G、K 3种型星,每种型星样本均为10 000条光谱.首先,需要对原始光谱数据进行预处理,对于给定的光谱集合:
其中,Xi=(x1,x2,…,xd)∈Rd表示第i条光谱向量,xi是给定波长下的流量值;οi=(ο1,ο2,…,οm)∈Rm是每条光谱对应的标签向量.值得注意的是,在不同波长下,流量频谱变化很大,即原始数据不同维度的值差异很大.
为了降低其计算复杂度且不影响光谱分类精确率,需要对原始数据进行归一化处理,本文采用的归一化方法是:min-max标准化,也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0,1]之间.转换函数如下:
其中,xmax为每条光谱样本数据的最大值,xmin为每条光谱样本数据的最小值.
3 深度信念网络模型设计
3.1 深度信念网络结构
深度信念网络(deep belief networks, DBN)是由受限玻尔兹曼机(restricted boltzmann machine, RBM)结构堆叠而成的深度学习模型.由于受限玻尔兹曼机只具有2层结构,所以从严格意义上说并不是一种真正的深度学习模型,然而它可用来作为基本模块构造自编码器、深层信念网络、深层玻尔兹曼机等许多其他深层模型[10].深度信念网络是一种深度学习的生成模型,又译为深层信念网络,由Geoffrey Hinton 及其合作者在 2006 年提出,其结构示意图如图1所示.DBN的神经元可以分为显性神经元和隐性神经元,显性神经元用于数据的输入,隐性神经元用于数据特征的提取.
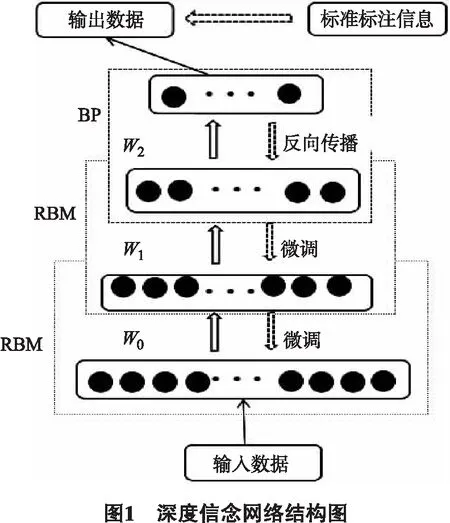
在用传统方法构造光谱分类器时,光谱特征的提取和选择是非常重要的一项工作.可通过测量特征谱线的参量,例如谱线的线心深度、等值宽度、特征谱线最大相对强度、特征谱线的特征波长、特征谱线的辐射强度度量等作为特征,以降低光谱数据的维度.深度信念网络(DBN)因其本身构造的特殊性,能够对数据的特征进行分层学习,也就是结构本身就具有良好的降维功能,使得大数据中的有效特征能够直接通过模型本身进行提取.而本文所采用的是维度较高的光谱数据,只需要设计深度信念网络中各层网络的选取与构造,从而获取更好的特征学习能力.
3.2 深度信念网络的算法过程
1) DBN的预训练过程:分别对每一层受限玻尔兹曼机(RBM)网络进行单独无监督地训练,使其数据的特征在不同空间的映射过程中,都尽量保留光谱数据的特征信息.
2) DBN的反向微调过程:在DBN的结构中,前面的每一层RBM网络都只能使得自身层内的权值对该层特征向量映射达到最优,并不是对整个DBN的特征向量映射达到最优.因此需要设置最后一层BP网络层,将错误的信息自顶向下传播至每一层RBM层,再全局微调整个DBN网络.这样的训练过程使DBN克服了BP网络因随机初始化权值参数而容易陷入局部最优和时间复杂度高的问题.
3.3 深度信念网络模型的参数选择
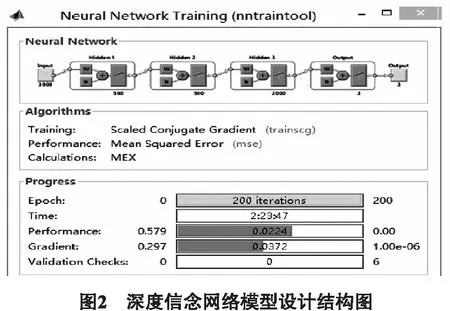
深度信念网络中RBM的层数越多对应的学习次数也越多,得到的光谱数据特征也更具有代表意义.在本实验中,经过反复尝试,当RBM层数为3层时,光谱数据的有效特征已经能够被有效提取,因此DBN中的受限玻尔兹曼机层数为3层.DBN模型节点数分别为3 909-500-500-2 000-3.其中,3 909个输入单元表示输入的光谱数据维度,受限玻尔兹曼机层的神经元个数分别为500,500,2 000,3个输出节点表示光谱输出光谱类别数目.训练中为了避免过拟合和欠拟合的情况经实验调参将迭代次数设为200次,学习率为默认值0.1,其分类模型结构如图2所示:
4 分类实验与结果分析
4.1 实验1
1) 实验环境在Intel i5处理器下进行,实验平台为Matlab 2014b.
2) 实验样本数据样本来源于刘超、崔文元[8]等采用27种线指数特征基于支持向量机方法对LAMOST光谱数据进行自动分类研究的文章,本文从参考文献[8]中选取F、G、K样本共计1 667条光谱数据(光谱信噪比大于20),其中F型光谱309条,G型光谱1 121条,K型光谱237条,分别标记为1、2、3.在本实验中将该样本分为训练集和测试集,其中训练集1 200条光谱,测试集467条光谱.
3) 方法分析与比较文献[8]中,选取27种Lick线指数来描述光谱特征,在对高维数据进行降维时能够较完整地保留光谱信息,并基于支持向量机进行分类研究,结果显示对G型光谱能够很好的分类,但对于F和K光谱分类效果并不十分理想.而深度信念网络模型最大的优势在于对光谱数据特征的分层学习,本身就具备降维功能,能够很好的提取光谱数据的显示特征,从而更好地进行特征学习和分类实验.基于以上样本和本文分类模型进行分类实验,并将分类结果与刘超、崔文元等的文章结果进行对比分析,结果见表1.

表1 分类结果比较 %
4.2 实验2
1)实验环境在Intel i5处理器下进行,实验平台为Matlab 2014b.
2)样本数据考虑到实验1中样本数据较少,为了体现深度神经网络大样本的优势,本实验选取的样本总数为30 000条光谱,维度为3 909,分别为F、G、K型.仅对数据进行了归一化处理,未限制光谱的信噪比值,样本标签分别为1、2、3,且在实验中将样本分为训练集和测试集,其中训练集27 000条光谱,测试集3 000条光谱.
3)方法分析与比较 王可等[11]采用深度神经网络对F、G、K 3种型星的分类结果进行比较,样本为50 000条.文章采用深度神经网络分类模型,节点设计为721-400-800-1 200-2 000-3,即有4个隐含层的分类器模型.本实验同样采用深度学习模型,但与其不同的是深度信念网络结构由受限玻尔兹曼机堆叠而成,不需要对光谱进行降维,应用该模型对高维光谱数据的特征分层学习能力,尽可能保留有效特征以提升分类精确度.
基于以上模型和数据进行分类实验,需要说明的是:虽然参考文献的数据集与本实验的数据集不完全一样,但均来自于LAMOST DR5,且样本都是在不限制信噪比的前提下随机选取.将结果与参考文献[11]进行比较,结果见表2(注:PILDNN是指基于伪逆学习算法的深度神经网络).
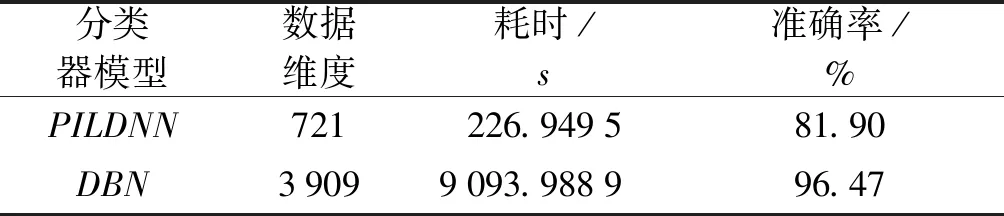
表2 分类结果比较
本文基于LAMOST巡天项目发布的海量数据的优势,将深度学习中的模型用于恒星F、G、K光谱数据中,由以上2个对比实验可以看出.
1)深度信念网络模型充分体现了大样本的优势.实验1的样本数据量少,尤其F和K型光谱,因此分类效果明显低于实验2的大样本数据的分类结果.
2)深度信念网络分类模型与其他算法相比较,该模型通过受限玻尔兹曼机层学习、训练各个参数的权值,并根据目标函数值经误差反馈对参数数值进行微调,使得对于天体光谱的总体分类精确率有明显提升;
3)深度信念网络模型具有较强的学习能力,可以从高维的原始数据中提取差别较大的低维特征,不需要对数据进行降维就可直接开始训练分类模型,不仅能够更全面的考虑到光谱信息量,而且能够较为准确的对光谱数据进行分类识别.
5 结语
针对分类可信度较低的F、G和K3种型星,采用深度信念网络进行大样本分类实验,结果表明该方法通过分层提取光谱数据特征的方法,具有很好的鲁棒性,且分类效果优于其他分类模型.深度学习方法虽然在大样本数据分类识别时具有较大优势,但是该方法计算量巨大,对计算资源具有较高要求,因此,还需要优化算法以解决计算复杂度高的问题.在接下来的工作中,我们会继续选取分类精度低或光谱型未知的光谱作为分类搜寻的候选体,进行自动分类和数据挖掘研究,进一步完备各型巨星样本,研究成果可以为银河系结构和动力学研究提供更好的支持.

猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
黑龙江大学自然科学学报(2022年1期)2022-03-29
黄河之声(2021年9期)2021-07-21
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
雪豆月读·低年级(2020年7期)2020-09-10
音乐天地(音乐创作版)(2020年2期)2020-04-18
领导决策信息(2018年16期)2018-09-27
学苑创造·A版(2017年11期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
食品工业科技(2014年23期)2014-03-11
