
一种面向医学文本数据的结构化信息抽取方法
2019-07-09 11:57聂铁铮申德荣
小型微型计算机系统 2019年7期
杨 兵,聂铁铮,申德荣,寇 月,于 戈
(东北大学 计算机科学与工程学院,沈阳 110819)
1 引 言
随着国内信息技术蓬勃发展,数字化建设步伐加快,各大医疗机构在很好地服务人们的同时也积累了大量的医学信息数据.然而,目前大部分的医疗文本都是以自然语言描述的非结构化数据,如医学影像报告、病理报告等.由于自然语言与机器语言之间存在巨大鸿沟,导致用计算机直接处理和分析非结构化文本的效率较低,也影响了分析结果的质量[1].因此,如何利用现有的技术方法从非结构化的医学文本数据中提取潜藏的、有价值的信息逐渐成为信息抽取[2,3]领域关注和研究的重点.
医学影像报告是医生根据X线片、CT、MR等影像学资料编写的一种电子文本记录,是一种典型的非结构化数据,其目的是反映疾病在某一阶段的病理变化和功能改变,是重要的临床诊断参考依据.然而,目前的医学影像报告主要是通过医务工作者在电子信息系统中手动编写的方法来产生.一方面,这种报告文本往往没有固定的书写格式,并且要求表述确切、内容全面,常常使用大量的医学术语进行描述;另一方面,为了方便临床医生的快速诊断,要求文字简明扼要、重点突出,因而常常使用短句描述,这就需要丰富的医学领域知识和一定的语言学功底.
针对以上问题,本文在分析医学影像报告数据特征的基础上,提出了一种高效的针对医学文本数据的结构化信息抽取方法.该方法首先构建VSM模型[4]对训练文本进行聚类,再从聚类后的文本集合中识别并提取医学描述语言常用的关键词,以生成医学领域的专业术语库,并将该医学术语库用于提高中文分词处理的效果,然后对文本中的描述短句进行语义依存分析并构建依存句法树,以实现对医学描述中的关键指标及其指标值的抽取,最终得到
2 相关工作
早期的结构化信息抽取主要面向英文文本,因为英文语法形式更为规范,并且已经构建了强大的语义知识库(WordNet[5]等),而国内针对中文文本的结构化抽取技术还相对不够成熟,这主要因为国内该领域的研究起步较晚,且中文语法复杂,常常需要进行中文分词[6,7]、实体识别[8]等处理,这使得针对中文的结构化数据抽取更为困难,并且现有的知识库(HowNet[9]等)并不支持特定领域内的词汇和语法.尤其是面向医学文本数据,由于书写自由、领域突出等特点,采用的方法大多依赖于通用的中文分词系统,如北京理工大学张华平博士团队的NLPIR[10]、复旦大学自然语言处理团队的FNLP[11]以及从开源项目Lucene发展而来的IKAnalyzer[12],此外还需要中文医学知识库的支持(如CMeSH[13]).
目前,对非结构化的医学文本进行信息抽取大多采用基于规则的方式,但由于医疗文本中不同组织器官所具有的属性不同,且描述不同病种所使用的指标词也不同,所以若想制定出一种适用所有医学报告形式的结构化规则十分困难[1].因此,研究人员从自然语言处理和机器学习两个方向做了很多尝试.
Socher R[14]等人提出了一种基于依赖关系树的DT-RNN模型,该模型与之前使用分区树的RNN模型不同,DT-RNN能更好地抽象出词序和句法的细节描述,并使用递归神经网络将句子映射到一个抽象空间,然后计算句子在依赖树中的向量表达,最终通过这种方法得到的句子向量所包含的语义信息.
Li[15]等人提出一种基于词语位置增益和知识库(HowSet)语义的计算模型——LaSE,考虑文本数据中的位置特征和语义特征,而位置特征具有可计算性和可操作性,语义特征具有可理解性和现实性,通过这种特征结合的方式来进行实体关系抽取.
Jonnalagadda S[16]等人使用语义划分来进行医学领域的概念抽取,该方法使用判别式分类器(CRF)来提取医疗事故、临床描述以及试验中的医学概念.通过语义划分的方式来构建索引,然后从未标注的语料数据中构建向量空间模型,进行分类任务,并从给定的句子分类结果中抽取出词汇模式.
Denecke K[17]等人使用统一医学语言系统(UMLS)来进行语义结构化和信息提取,并提出了一种从自然语言文本数据中自动生成知识表示的方法——SeReMeD,然后结合现有的语言工程方法和语义转换规则,将语义信息映射为语义表示,并通过这种方式将医学文献的内容转换为结构化的语义信息.
上述方法都主要从模型和方法角度来进行研究,而忽略了数据本身的特征,即没有充分考虑医学文本数据(如医学影像报告)所独有的词汇特征和语法特征.本文在总结各种模型和方法的同时,深入分析了实验数据本身的特殊性以及与其他文本数据的差异性,针对医学领域的专业词汇和医学报告的语法习惯分别构建医学术语库和依存关系库,并进行多次迭代计算,以实现高鲁棒性和可扩展性.
3 问题描述
医学文本是医务工作者在电子信息系统中采用自然语言编写的一种记录报告.以医学影像报告为例,医生通过观察医学影像设备(如胃镜、支气管镜、CT、彩超等)的图像显示,给出病灶在某一阶段的病理变化和功能改变的描述,数据样例如表1所示.
表1 医学影像报告数据样例
Table 1 Data sample of medical imaging reports

检查项目主要病症人工描述支气管镜肺恶性肿瘤气管环清晰,粘膜正常,隆突锐利,血管纹理清晰,左上叶管口可见新生物,管腔完全阻塞,取病理,左肺二级隆突粘膜充血,肥厚,左下叶管口粘膜充血,肥厚,左下叶B6管口局部粘膜充血,左肺余支气管开口正常,未见新生物,右肺各支气管开口正常,未见新生物.
因此,医学影像报告是医生编写的一种病情描述,由表1可知,其用词上大量使用医学术语,如“气管环”、“隆突”、“管腔”等;语法上主要采用短句结构,并为了语言精简而大量省略动词,同时常常伴有文言句式的表达形式,如“取病理”、“可见……”、“未见……”等.为了减少人工阅读量,需要从这些文本数据中抽取结构化信息,但前提是必须准确识别这种自然语言描述中的关键指标及其相对应的指标值.下面给出本文所涉及到的几个定义.
定义1.病灶.机体上发生病变的部分,包括人体中任何组织器官的病变.
定义2.关键指标.对人体指定部位检查所涉及到的组织名和器官名等名词.
定义3.指标值.一种与关键指标名相对应的描述信息.
以表1中的数据为例,在人工描述中包含“气管环”、“粘膜”、“血管纹理”等人体肺部的组织器官名,即为关键指标名,而对于这些指标名的描述即为对应的指标值.因此,可以大致得到表1中人工描述信息进行抽取后的结果,如表2所示.
表2 结构化抽取结果示例
Table 2 Example of structured extraction
4 医学文本结构化抽取方法
4.1 处理框架
本文提出的方法主要是对医学报告文本中的结构化信息进行抽取,如图1所示,系统分为两个处理模块:
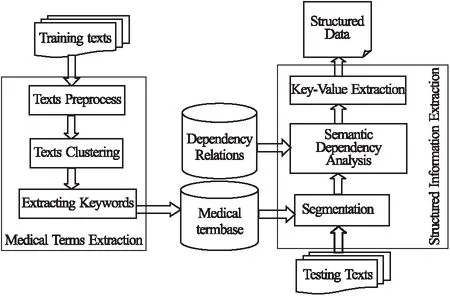
图1 医学文本数据结构化抽取过程Fig.1 Processing of structured extraction for medical text data
1)在医学术语提取模块,对预处理后的训练文本进行聚类,然后在每个文本类簇中进行关键词抽取,以获取具有丰富领域知识的医学术语库.
2)在结构化信息抽取模块,利用生成的医学术语库提高测试文本的分词质量,再利用现有的依存关系库进行语义依存分析,构建依存句法树的结构,然后依据语法规则抽取关键指标及其对应的指标值,最终得到结构化的输出结果.
4.2 医学术语提取
该模块包含文本预处理、文本聚类和关键词抽取三个操作,主要处理的是训练文本,目的是为了获取具有领域知识的医学术语库.在预处理阶段,主要是分词和数据清洗,包括去除停用词和过滤句子结束符等.关于文本聚类和关键词提取两个阶段,本文将分别在4.2.1节和4.2.2节中详细介绍.
4.2.1 文本聚类
如第3小节所描述的数据特征,医学文本往往句式复杂并且常常采用大量短句结构,从而造成语义晦涩,不便于机器理解,类别分散,聚类数据量大等困难,所以常用的聚类算法[18]并不能很好地处理这类数据.因此,本文采用了基于向量空间模型(VSM)的文本聚类方法,以向量的形式来量化分析医学文本的类别特征.
在向量空间模型中,每一个文本被看成一个词汇集合,然后被表示成词条权重的向量:
di={wi1,wi2,…,win}
(1)
其中,di表示一个文本,n表示词条空间的维数,每一个词条的权重win代表了该词条在文本中的重要性.
本文使用TF-IDF方法来计算词条的权重,并使用向量的余弦系数来衡量文本之间的相似度[4],最终将文本数据划分到不同的类簇中.
4.2.2 关键词提取
为了获得医学领域的常用术语,需要提取每一个文本类簇中重要的描述词,即医学文本中的关键词.为此,本文使用一种改进的TextRank[19,20]算法,在有向图结构中使用依存关系作为节点词之间关联的主要规则,并且采用短句拆分的方式来降低图结构的复杂程度.如算法1所示,这种方法可以在不需经过预先训练的情况下进行关键词提取.
考虑到依存关系只出现在相邻两个词之间且文本以短句为主,所以算法1中的窗口大小k设置为2,权重收敛条件为连续两次计算的结果相差不超过0.0001,权重更新的最大迭代次数count为10,候选关键词数t为3.
然而,由于构建有向图之前还需要利用现有工具对描述短句进行分词和词性标注,鉴于目前的各种NLP系统在医学领域的文本数据上处理效果一般,所以在利用算法1提取出关键词后还需要进一步的人工校正,以提高医学术语库的可用性.
4.3 结构化信息抽取
该模块包含中文分词、语义依存分析和关键指标抽取三个操作,目的是从医学文本中抽取出结构化的键值对数据.在中文分词阶段,本文采用基于HMM训练模型的Jieba分词系统,并利用在4.2节中生成的医学术语库来识别医学文本描述中的命名实体,包括人体组织名、器官名和一些常用的医学表述词,以此来提高医学领域文本数据的分词质量,而语义依存分析和关键指标抽取两个阶段将分别在4.3.1节和4.3.2节中详细介绍.
算法1.基于TextRank的关键词提取算法
输入:文本类簇集合CLUSTERS,每个类簇包含若干个文本dj,迭代次数count,窗口大小k,候选词数t;
输出:关键词集合KeyWords.
1. 初始化WordSet=φ,迭代次数count=0;
2. FORCiINCLUSTERS
3. FORdjINCi
4.WordList=posSegment(dj);
5. FORwkINWordList
6. Filter(wk);/*对wk进行语法过滤*/
7. Graph←wk;/*将词wk添加到有向图中*/
8. IF dependency(wk,wl,k)
9. Graph←edge;/*添加有向边*/
10.WS←Init();/*初始化权重*/
11. WHILEcount 12. IFWS达到收敛 break; 13. Update(WS);/*更新权重WS*/ 14. count++; 15. WHILE 节点Vi≠NULL 16. Sort(WS) /*节点权重降序排列*/ 17. WHILEi 18.WordSet←Vi;/*将节点词添加到KeyWords*/ 19.count←0;/*更新迭代次数为0*/ 20. RETURNKeyWords. 4.3.1 语义依存分析 由于医学文本都是采用自然语言描述的,需要通过语义分析来进行解析,因此本文利用依存语法来分析词条之间的这种语义依存[21-23]关系.依存语法是一种描述句子中各个词条之间的依存结构的语法,这种语法不仅表示形式简单,而且保留了短语结构信息.语言学家Robinson[24]总结了依存语法的理论基础,归纳出以下4个公理: 公理1.一个句子中只有一个成分可以作为核心成分; 公理2.一个句子中的某一成分直接依存于句子中的其他成分; 公理3.句子中的任何成分不能依存于两个或者两个以上的成分; 公理4.句子中具有依存关系的成分之间不能有交叉关系. 根据依存语法的4个约束公理,本文在现有语法规则的基础上归纳总结了中文自然语言中常用的14种语义依存关系,如表3所示.同时为了方便检索和理解,本文对每一种依存关系都做了相应的标注和英文描述,通过这些常见的语义依存关系来构建一个依存关系库,并将其应用于后续的语义依存分析处理. 在语义依存分析阶段,本文使用CRFs模型获取短句中任意两词之间最可能的依存关系,并采用最小生成树算法来构建依存句法树.以表1中的数据样例为例,人工描述中写到“左上叶管口可见新生物”,进行中文分词后可得到词条序列{“左上叶/nz”、“管口/n”、“可见/v”、“新生物/n”},再分析语义依存关系可得到图2所示的依存句法树.由图2可知,依存关系树的根节点就是每个短句具有核心关系的词,即整个句子的核心,每个节点包含了原始词、词性以及该节点与其父节点之间的依存关系(根节点除外).由于医学报告文本往往以短句的形式来描述,因此生成的依存句法树通常结构相对简单,并且树的高度较低,这样便于从这种树形结构中抽取 表3 语义依存关系归纳 序号依存关系标注描述1主谓关系SBVSubject-verb2动宾关系VOBVerb-object3定中关系ATTAttribute4状中关系ADVAdverbial5动补关系CMPComplete6并列关系COOCoordinate7介宾关系POBPreposition-object8间宾关系IOBIndirect-object9前置宾语FOBFronting-object10左附加关系LADLeft-adjunct11右附加关系RADRight-adjunct12独立结构ISIndependent-structure13核心关系HEDHead14兼语DBLDouble 4.3.2 关键指标抽取 从4.3.1节中可知,对于每个描述短句,都可以构建与之对应的依存句法树,并且具有核心关系的词作为根节点,从而可得到每个词的词性及其与父节点的依存关系.本节将结合句法树中的语义依存关系和词性特征来提取医学文本描述中的关键指标及其指标值,以实现结构化信息抽取. 图2 依存句法树示例Fig.2 Example of dependency tree 在中文自然语言中,一个短句的成分通常包括:主语、谓语、宾语、定语、状语和补语,其中具有核心关系的词一般作为谓语成分,而医学文本描述中又常常以动词、名词、形容词作谓语;同时,在对医学报告文本的描述语言进行归纳总结后,发现短句中常出现的语义依存关系(除核心关系外)主要有5种:主谓关系(SBV)、动宾关系(VOB)、定中关系(ATT)、动补关系(CMP)和并列关系(COO),表4列举了医学描述语言中的动词、名词和形态词分别作为核心词时主要出现的依存关系. 本文依据句法树中根节点上的核心词词性及其与各孩子节点间的依存关系,分别采用不同的抽取策略.如算法2所示,当根节点上的词性为动词时,直接遍历子节点并判断其与父节点之间的依存关系即可确定关键指标名及其相对应的指标值;当根节点上的词性为名词或形容词时,在遍历各子节点之后,还需要对具有并列关系的子节点上的词进行合并,作为最终的指标名,而将具有定中关系的词作为相应的指标值. 表4 不同词性的核心词主要出现的依存关系 SBVVOBCMPATTCOO动词√√√名词√√形容词√√ 算法2.关键指标抽取算法 输入:由各关键词节点生成的依存句法树,树的每个节点包含原始词word、词性postag和依存关系relation; 输出:结构化键值对 1. 初始化RESULT=φ; 2. IF 根节点root≠NULL 3. FORword,postag,relationINroot 4. IFpostag==′v′|′vn′|′vd′ /*根节点为动词*/ 5. WHILE 子节点child≠NULL 6. IFchild[relation]==′主谓关系/SBV′ 7. 指标名key←child[word]; 8. ELSE IFchild[relation]==′动宾关系/VOB′|′动补关系/CMP′ 9. 指标值value←child[word]; 10.RESULT←(key,value);/*将键值对添加到结果集*/ 11. IFpostag==′n′|′ns′|′nz′|′a′|′ad′|′an′ /*根节点为名词或形容词*/ 12. 指标名key←root[word]; 13. WHILE 子节点child≠NULL 14. IFchild[relation]==′并列关系/COO′ 15.k←combine(root[word],child[word]);/*合并具有并列关系的词*/ 16. 更新指标名key←k; 17. ELSE IFchild[relation]==′定中关系/ATT′ 18. 指标值value←child[word]; 19.RESULT←(key,value); 20. RETURNRESULT. 本文使用真实的医学影像报告作为实验数据,其中共包含3000多条文本记录,每条记录由检查项目、主要病症和人工描述三个文本类型的属性组成.针对这些实验数据,本文首先进行了初步的统计分析,如表5所示,实验的文本数据集在各类别上分布不均.因此,本文重点筛选了样本数量占比较大的支气管镜、彩超、胃镜的影像报告数据进行实验.此外,本文还将数据分为训练文本集和测试文本集,两部分数据集的规模按照6:4的比例进行随机划分. 针对选取的这3类样本数据集,本文从句型的角度分析了医学报告文本的句子特征.表6统计了支气管镜、彩超和胃镜的报告文本中的句子长度情况,从中可以看出医学上的文本数据主要以短句为主,句子的长度绝大部分都不超过10个词,且主要集中在5个词以内,平均占比达到了84.73%,而在胃镜的检查报告中,使用短句最多,5个词以内的短句达到了91.67%,这说明医学领域的文本描述受书写习惯的影响较大,往往为了表述上的简洁明确而弱化了中文自然语言的语法规则,从而增加了语义分析的难度. 表5 样本数据统计信息 序号检查项目样本数量占比1支气管镜41.28%2彩超32.36%3胃镜19.71%4CT1.51%5DR1.41%6MR1.41%7肠镜1.01%8超声胃镜0.70%9鼻咽镜0.61% 表6 三类样本数据集的句子长度统计 0<词数≤55<词数≤10词数>10彩超80.33%19.64%0.03%胃镜91.67%8.32%0.01%支气管镜82.20%17.76%0.04%平均值84.73%15.24%0.03% 本文的实验数据首先要经过中文分词处理.目前开源的分词工具较多,但采用的算法模型不同,效果不一,因此本文对于使用比较广泛的3种分词工具,即NLPIR、IKAnalyzer和Jieba分别在现有数据集上进行了分词实验.由图3的对比结果可知,对于医学领域的中文文本数据,三种分词工具进行直接分词的效果并不理想.相比之下,Jieba分词能够达到90%左右的准确率,较之NLPIR和IKAnalyzer有一定的优势,因此本文选择Jieba作为本文实验的主要分词工具. 通过关键词提取,本文得到了医学描述中常用的术语,图4给出了训练文本和医学术语库中的一些高频词的分布情况.由图4可知,动词、名词和形容词作为医学描述语言中的常用词汇,在训练文本和术语库中的占都比较大,其中名词使用频率最高,在训练文本中使用频率达31.13%,而在术语库中出现的频率达43.62%,这主要因为医学报告通常是对人体组织名和器官名的描述,所以名词出现最多.相比于训练文本数据,医学术语库中动词、名词和形容词相较于其它词性的词分布更加集中,这说明关键词提取操作有效识别并提取了医学描述语言中的一些常用词汇. 图4 训练文本和术语库中高频词对比Fig.4 High frequency words in training texts and termbase 为了提高中文分词质量,本文使用生成的医学术语库作为用户词典,用于辅助分词,表7给出了直接分词和使用术语库进行辅助分词的结果对比.在实验中,本文将测试数据集分为三个子集,分别从彩超、胃镜、支气管镜三个主要的样本数据来比较分词的准确率.由表7可知,使用提取出的医学术语库可以明显提高中文分词的质量,平均准确率达到了97.78%,相比直接进行分词,提高了7.23%,并且在胃镜检查的文本类簇中的分词效果最好,准确率达到98.24%,而在支气管镜的文本类簇中的分词效果提升最明显,准确率提高了9.30%,由此可见,使用关键词提取得到的术语库进行辅助分词确实有效地提高了医学文本数据的分词质量. 表7 直接分词和使用术语库的分词准确率对比 彩超胃镜支气管镜平均值直接分词92.06%91.23%88.37%90.55%术语库分词97.42%98.24%97.67%97.78%差值+5.36%+7.01%+9.30%+7.23% 在结构化信息抽取阶段,本文采用了哈尔滨工业大学NLP实验室开发的LTP工具包来进行语义依存分析,并且与基于结构化模板匹配[25]的方法进行了实验对比.根据样本数据的三个主要类别,本文设计了三组对比实验,分别针对彩超检查报告、胃镜检查报告和支气管镜检查报告进行文本数据的结构化处理,并分析计算结果的准确率、召回率和F1值,实验结果如表8、表9和表10所示. 由表8、表9和表10可知,在三组不同样本集的实验中,采用语义依存分析的方法准确率都能达到80%以上,相比之下,基于结构化模板匹配的方法由于通过人工构建模板库在三个样本集中实验效果更佳,在彩超和支气管镜的样本数据上准确率和召回率都要高于语义依存分析的结果.然而在胃镜检查报告的样本数据中采用语义依存分析的结果准确率达到了83.76%的准确率,与通过模板匹配的结果相差不大,并且在召回率上甚至达到了88.09%,高出了0.94%,这说明语义依存分析的方法能够有效识别并抽取医学文本描述中的结构化信息,并且与通过人工模板库进行匹配的结果相近,甚至在一些特定数据集下采用语义依存分析的方法能获得更高的指标覆盖率,即能够识别出更多的关键指标,从而抽取出更多的 表8 彩超报告结构化信息抽取结果对比 准确率召回率F1基于模板匹配81.62%85.21%83.37%语义依存分析80.53%83.11%81.80%差值 -1.09%-2.10%-1.57% 表9 胃镜报告结构化信息抽取结果对比 准确率召回率F1基于模板匹配84.02%87.15%85.56%语义依存分析83.76%88.09%85.87%差值 -0.26%+0.94%+0.31% 表10 支气管镜报告结构化信息抽取结果对比 准确率召回率F1基于模板匹配82.51%86.21%84.32%语义依存分析80.93%84.50%82.68%差值 -1.58%-1.71%-1.64% 最后,本文对抽取的结构化键值对做了进一步分析,图5给出了语义依存分析和基于模板匹配两种方法处理后的结果数据中五种高频依存关系的对比情况.由图5可知,采用结构化模板进行匹配的方法主要处理的是具有主谓关系、定中关系和并列关系的词,而对于具有动宾关系和动补关系的词处理效果较差.相比之下,采用语义依存分析的方法对于这五种依存关系都能取得较好的效果,占比都在10%以上,并且对于具有并列关系的词能达到21.57%的处理效率,由此说明采用语义依存分析的方法能识别并处理更多的依存关系,相比模板匹配具有更高的语法覆盖率,因而该方法适用性更强,并有利于向其它文本数据扩展. 图5 语义依存分析和模板匹配的依存语法覆盖率对比Fig.5 Grammar coverage of semantic dependency analysis and template matching 本文所提出的一种针对医学领域文本数据的结构化信息抽取方法,重点分析了样本集的数据特征,并采用文本聚类和关键词抽取的方法获得了医学术语库,显著提高了医学文本的分词质量;在结构化信息抽取阶段,本文通过分析词与词之间的语义依存关系和构建依存句法树,准确识别并抽取出了医学描述中的关键指标及其对应的指标值,同时取得了很好的语法覆盖率,有利于本方法的扩展应用.然而在抽取的准确率上,本文的方法还有待改进和提升,未来将考虑结合深度学习相关的算法模型,更加充分地提取和利用数据本身的特征,以更好地实现结构化信息抽取.
Table 3 Summary of semantic dependency relations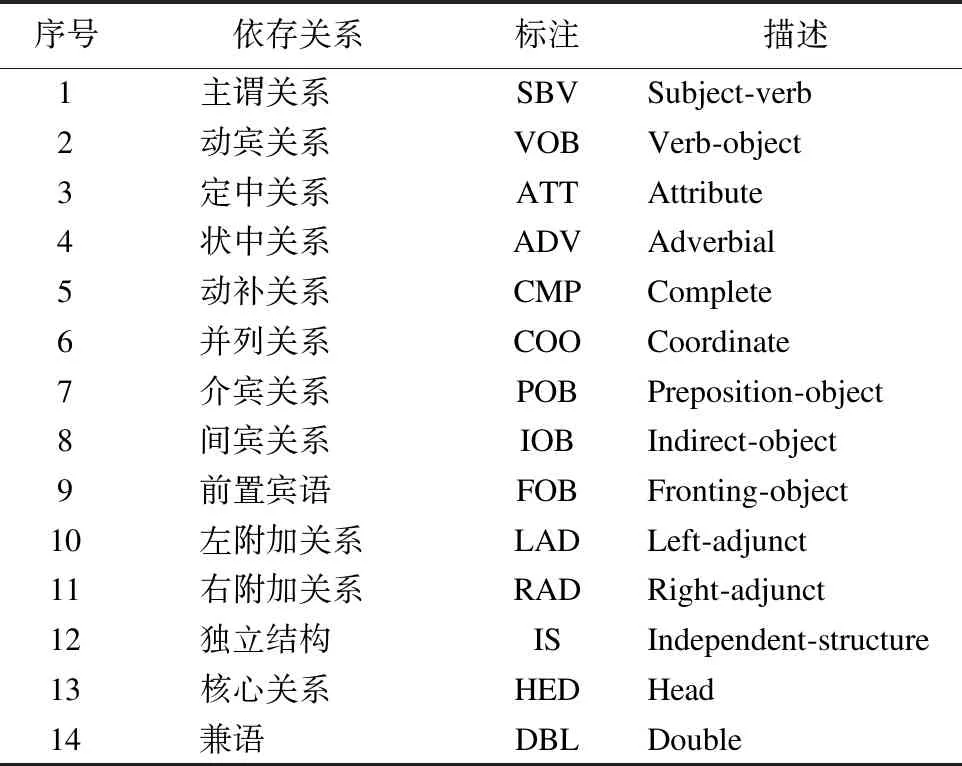
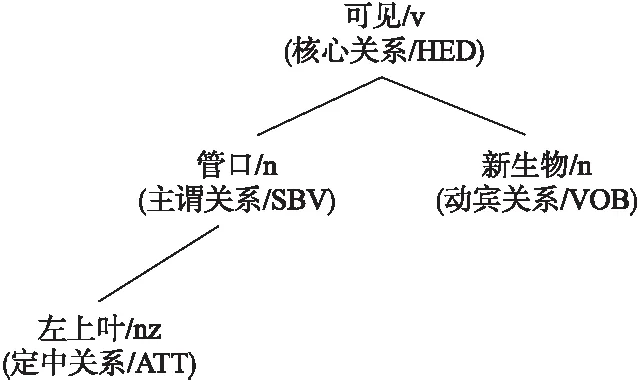
Table 4 Dependency relations on different key words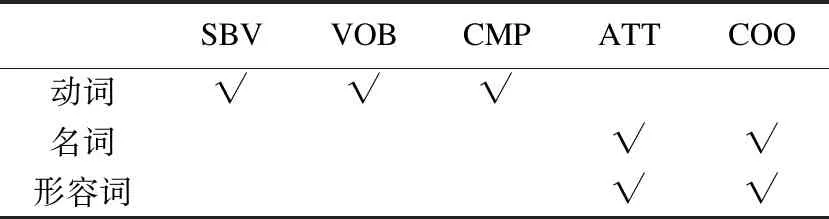
5 实验与结果分析
5.1 实验数据集
Table 5 Statistics of sample data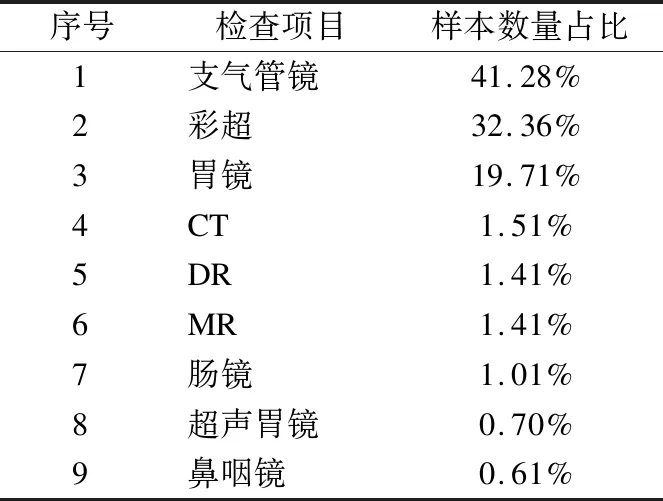
Table 6 Statistics of sentences in three samples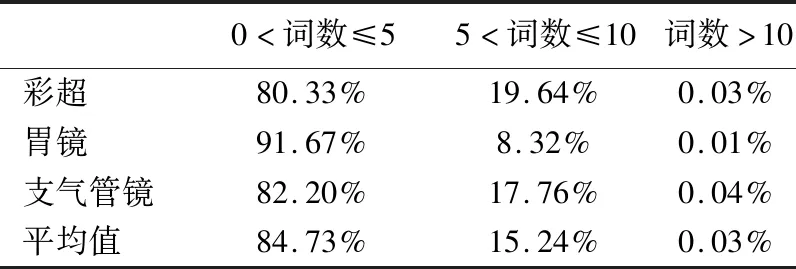
5.2 对比实验与分析
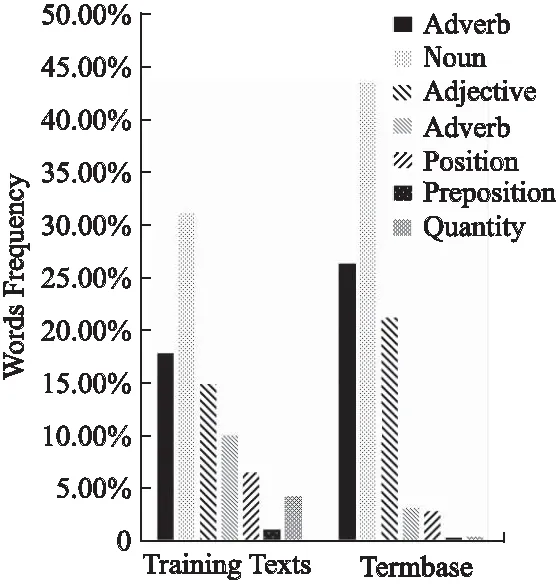
Table 7 Comparison of segmentation accuracy with directly segmenting and using termbase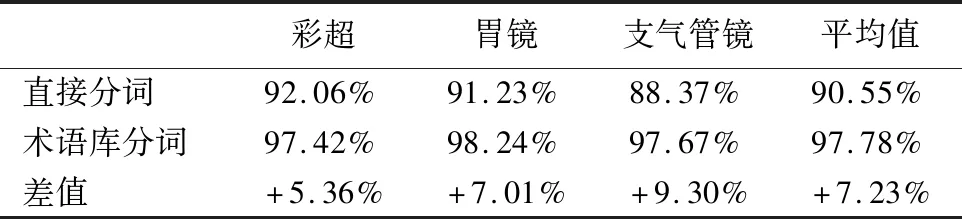
Table 8 Comparison of the results on color doppler reports for structured extraction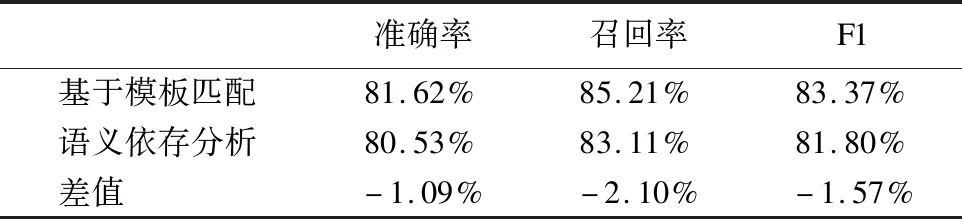
Table 9 Comparison of the results on gastroscope reports for structured extraction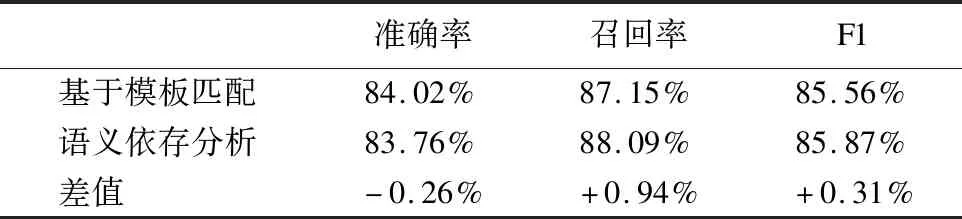
Table 10 Comparison of the results on bronchoscopy reports for structured extraction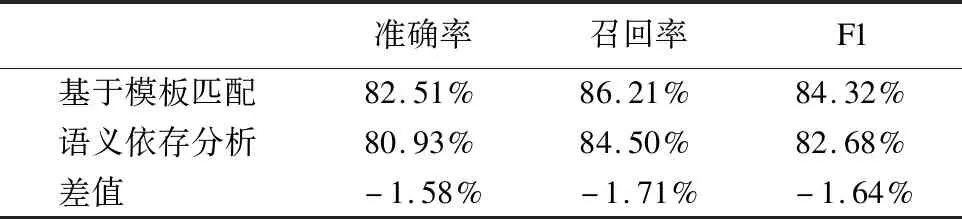
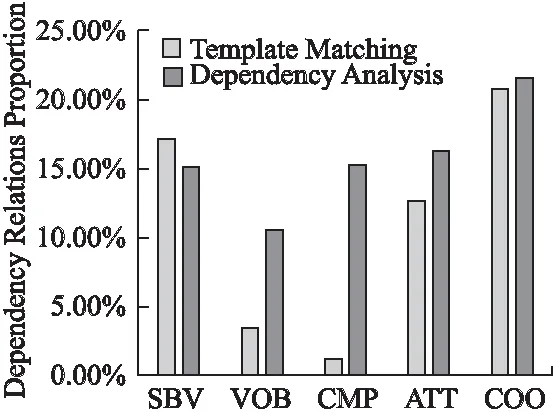
6 总 结
猜你喜欢
十几岁(2022年34期)2022-12-06校园英语·月末(2021年13期)2021-03-15娃娃画报(2019年8期)2019-08-05娃娃画报(2019年8期)2019-08-05智富时代(2019年6期)2019-07-24智富时代(2019年6期)2019-07-24中国科技术语(2012年3期)2012-03-20中国科技术语(2012年3期)2012-03-20中学教学参考·语英版(2008年8期)2008-11-26中学生英语·外语教学与研究(2008年4期)2008-03-18
