
基于时空切分和词向量相似性的轨迹伴随模式挖掘
2019-10-14 05:07李欣
中山大学学报(自然科学版)(中英文) 2019年5期
李欣
(中原经济区“三化”协调发展河南省协同创新中心∥河南财经政法大学资源与环境学院,河南 郑州450046)
多源传感器获取的位置信息产生了海量具备时空属性的轨迹数据,此类数据真实而全面地反映了人群和车辆的流动行为。传统的轨迹数据,主要应用在宏观分析整个研究区域的交通运行状态,及微观刻画和表达目标个体或群组的移动规律上。而,多源采集的轨迹数据具有大数据的4V特征,对其进行清洗、索引、存储和挖掘的难度大大增加。因此,必须利用更加有效的大数据平台和挖掘算法,从中准确提取移动群组的流动规律,从而实现发现同类群体或检测频繁路径等功能。
目前,已有一些关于伴随模式的研究。如:Flock方法[1-2]利用连续时间节点和圆形空间范围作为判定伴随模式的时空约束条件;Convoy方法[3-4]将空间约束条件扩展为密度可达;Swarm方法[5]将时间约束条件扩展为可以不连续;Platoon方法[6]通过时间分段、阈值细化实现了局部或全局时段的伴随模式挖掘。以上方法主要针对静态交通流轨迹数据。对于实时采集的无边界流式轨迹数据而言,其时空约束条件设置难度较大,且该种算法处理效率低、挖掘能力不足。词向量[7](Word2 Vec)原本用于语法语义规律的挖掘[8-11],其特征之一是能够准确描述相似关系。许多学者认为:在一定拓扑空间内的交通流或轨迹数据同样存在上下游相关关系[12-15]。因此,词向量曾被用于解决智能交通系统中的聚类分析和网络预测等问题,如:解决网络分类的网络节点词向量训练[16]、网络聚类和路径预测的链路词向量表示[17-18]及城市功能区划分的区域词向量表示[19]等。但以上研究对于交通流轨迹的时空异质性考虑不够全面[20-22],还需对词向量模型进行有针对性的优化,以适应伴随模式挖掘的需要。
本文拟提出一种基于时空Hausdorff距离切分和词向量相似性的伴随模式挖掘方法。首先,建立交通流轨迹数据的清洗、索引、存储和查询框架[23];然后利用时空Hausdorff距离和时间滑动窗口对轨迹进行切分,建立轨迹段和词句的类比关系;并使用词向量模型完成轨迹整体相似度的计算,实现伴随模式挖掘,达到为智能交通中的群组移动模式提供理论基础的目的。
1 伴随模式的数据挖掘
交通流轨迹大数据的挖掘算法分为以下几个步骤:1)通过多源传感器采集移动对象定位信息,并按照时序组合为轨迹数据;利用孤立点检测算法[24]完成数据清洗、构建时空索引,配置负载均衡规则并入库。2)输入伴随模式的挖掘条件,通过语义解析提取挖掘请求中的时空约束条件;利用索引快速从海量轨迹数据中提取符合条件的数据,并记录为中间数据集。3)利用词向量模型训练历史轨迹数据集,得到轨迹向量语料库。4)计算中间数据集中所包含的轨迹记录的时空Hausdorff距离,并利用滑动窗口将其切分为重叠和非重叠子轨迹段,生成子轨迹段集合。5)根据切分结果构建轨迹段和词句之间的类比关系,利用语料库将轨迹段表达为词向量,计算单词相似度;根据轨迹段在整条轨迹中的长度比例确定权重,然后利用词向量模型中的“语句”结构相似度计算方法,得到定量化的轨迹相似度,并判定轨迹间是否呈伴随模式,最后返回伴随对象集合和可视化结果。具体流程如下:

图1 伴随模式的数据挖掘流程图Fig.1 Data mining process of accompanying patterns
1.1 时空Hausdorff距离与相似轨迹切分
在以往的研究中,对轨迹定位时间和定位位置分别进行判断,导致了轨迹的真实特征被人为拆分。本文采用时空Hausdorff距离(spatial-time Hausdorff distance),将时间和空间因素同时引入轨迹段的距离计算,能较好体现轨迹段之间的时空相似程度。
1.1.1 轨迹对象时空Hausdorff距离计算 在实际应用中,移动目标的轨迹在空间上可能是部分相似的,如图2所示。图2中,虚线框中的轨迹在空间上差异很小,可以认为此部分是重叠或相似的,但其他部分并不相似。在进行伴随模式的挖掘时,需要将重叠和非重叠轨迹段进行切分;并根据重叠部分的多少以及轨迹分段后的结构特征,结合轨迹的时空异质性,计算整条轨迹的相似程度。
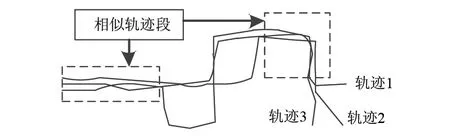
图2 相似轨迹示意图Fig.2 Schematic diagram of similar trajectories
轨迹由定位点组合而成,而Hausdorff距离主要用于计算两个无序点集之间的距离。因此,Hausdorff距离可度量两条轨迹之间的距离。设存在两个无序点集P={p1,p2,,pi,,pn}和Q={q1,q2,,qi,,qn},则Hausdorff距离为:
H(P,Q)=max(h(P,Q),h(Q,P))
(1)
(2)
(3)
其中,dist(pi,qj)为点pi到点qj的欧氏距离。公式(1)为双向Hausdorff距离,它是Hausdorff距离的基本形式,度量了两个点集间的最大不匹配程度。公式(2)为从P到Q的单向Hausdorff距离,即计算集合P中的每个点pi到距离此pi点最近的qj点的欧氏距离,并取其中的最大值作为h(P,Q)的值。公式(3)与公式(2)的性质类似。
Hausdorff距离虽然度量了两个点集的最大不匹配程度,但因轨迹定位点还存在时序属性,须对其公式进行扩展改进,以适应伴随模式的挖掘需要。为了体现轨迹对象的时空属性,本文提出了一种基于时间序列的一对三轨迹的Hausdorff距离。已知在某一时间段内,两个移动目标的定位频率一致,坐标对随时序一一对应。设某条轨迹中的一个定位点p的时空结构为p(x,y,t),则轨迹P表达式为:TRp={p1,p2,pi,,pn} 。其中,n>3,x和y为经纬度坐标,t为定位时刻。同理,轨迹Q的表达式为:TRq={q1,q2,,qi,qn}。则,改进后的Hausdorff距离公式为:
H(TRp,TRq)
=max(h(TRp,TRq),h(TRq,TRp))
(4)
h(TRp,TRq)
(5)
h(TRq,TRp)
(6)
式中,pi∈TRp,i≠1且i≠n。dist(pi,(qi-1,qi,qi+1))为pi到三点qi-1、qi、qi+1所确定平面的距离。
相比于一对多或一对一的Hausdorff距离,时间序列的一对三的Hausdorff距离具有能体现定位点的时序性和相关性的特点。三种轨迹的Hausdorff距离计算方法如图3所示。
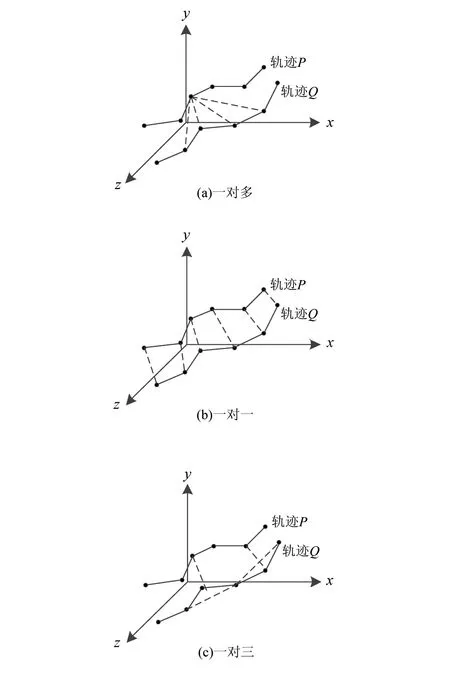
图3 三种轨迹的Hausdorff距离示意图Fig.3 Schematic diagram of three track Hausdorff distance calculation methods
图3(b)中,计算的是轨迹上的每个定位点与另一条轨迹上对应时刻的定位点之间的距离,满足了时间排序的要求,但没有体现轨迹Q上其他点对该点的影响。图3(c)中,计算的是轨迹P的定位点pi与轨迹Q的定位点qi、以及前后两点qi-1和qi+1所确定的平面之间的距离。该算法不仅体现了时刻顺序和对应时刻前后两点的相关性,而且单个定位点的计算量大大减少,提高了算法的运行效率。
1.1.2 基于时间滑动窗口的轨迹切分 在进行整条轨迹的相似性度量之前,需要进行切分,得到重叠和非重叠子轨迹集合;然后,使用词向量度量轨迹的整体相似性。本文使用时间滑动窗口对轨迹进行切分,其原理如图4所示。
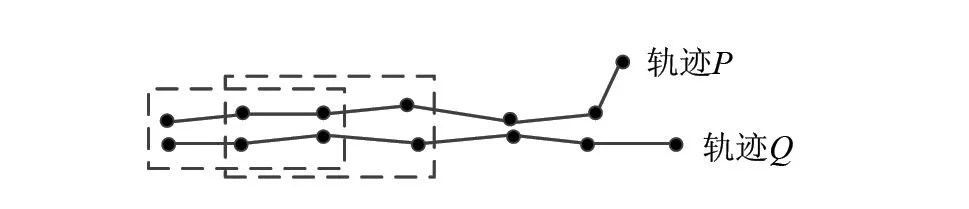
图4 基于时间滑动窗口的轨迹切分Fig.4 Trajectory segmentation based on time sliding window
在切分过程中,输入项为目标轨迹TRp={p1,p2,,pi,,pm}、待判定轨迹TRq={q1,q2,,qi,,qn}、最小时间滑动窗口k(3≤k≤min(m,n))和子轨迹Hausdorff距离阈值h;输出项为重叠和非重叠子轨迹集合。具体步骤为:
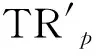
(2)计算待判定轨迹起始位置最小时间滑动窗口k内子轨迹段的Hausdorff距离,并判断其距离是否小于阈值h。
(3)若小于阈值,则将时间滑动窗口增加一个单位长度,直至距离超过阈值;并将小于阈值的子轨迹段切分,记录为重叠子轨迹段。
(4)若时间滑动窗口k的长度增加后,子轨迹的Hausdorff距离超出阈值,则从时间滑动窗口末端开始重新以最小窗口k扫描剩余轨迹。
(5)扫描剩余轨迹时,最小窗口k内子轨迹的Hausdorff距离超出阈值,则将最小窗口向后平移一个单位长度,继续扫描剩余轨迹,同时记录超出阈值的子轨迹段作为非重叠子轨迹段。
(6)整条轨迹扫描结束后,即可得重叠和非重叠子轨迹集合。
1.2 基于词向量的轨迹相似性度量
1.2.1 词向量模型与轨迹段类比 词向量技术设计的初衷是为了实现机器对人类自然语言的语义理解,计算“词”和“句”的相似性,度量目标词与上下文之间的相关关系。词向量模型又分为CBOW(continuous bag of word)和Skip-gram两种模型架构[2],二者均可通过训练语料库表达词的相关关系,而差异在于CBOW通过上下文计算目标词出现概率,Skip-gram根据目标词计算可能出现的上下文。其原理如图5所示。
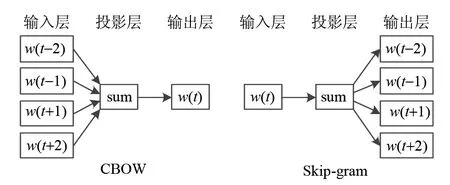
图5 CBOW模型和Skip-gram模型原理图[2]Fig.5 CBOW model and Skip-gram model[2]
由于伴随模式挖掘的目标是度量整条轨迹的相似性,因此为了体现对象在移动过程中的分段伴随状态,可以将子轨迹段类比为单词,整条轨迹类比为语句,利用词向量模型计算语句的相似性,实现轨迹的伴随模式挖掘。通过目标词计算可能出现的上下文信息的Skip-gram模型更加适用。
1.2.2 轨迹相似性度量方法 利用词向量的语句结构和单词上下文,可以体现轨迹的分段结构和上下游特征。基于词向量的轨迹相似性度量方法,主要考虑整条轨迹的长度,以及重叠和非重叠子轨迹段的结构特征,对词向量语句相似度计算方法进行改进,从而实现伴随模式的挖掘。其流程如图6所示。
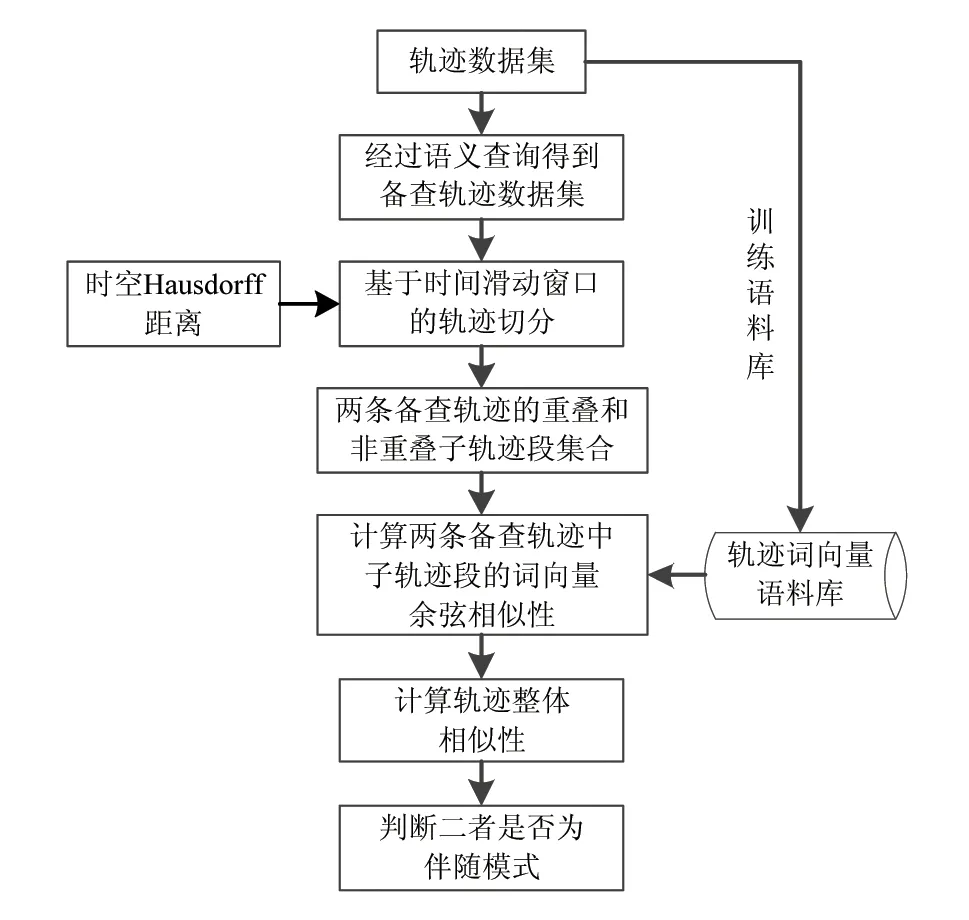
图6 基于词向量的轨迹相似性度量方法Fig.6 Trajectory similarity measurement based on word vector
由于城市交通轨迹几乎全部运行在路网中,因此可以按照路网中的路段训练词向量语料库,并进行轨迹相似性度量。具体步骤如下:
(1)训练词向量语料库。将路段类比为词,每一条轨迹类比为语句,利用地图匹配算法可以将轨迹映射为由路段序列组成的路径,然后使用Python第三方库中的“gensim”工具即可从大量轨迹路径中实现Word2 Vec语料库训练,语料库中包含路网中的各个路段(词)及其对应的实数向量。
(2)利用语料库度量任意一条轨迹段的词向量与其他轨迹段之间的相似性。向量相似性高说明:词的共现频率高或语句的上下文结构相似,轨迹的时空特征也相似。
(3)基于Hausdorff距离和时间滑动窗口对轨迹进行切分。从备查轨迹数据集中提取两条轨迹P和Q,利用前述1.1.2节的方法,得到重叠和非重叠子轨迹集合。
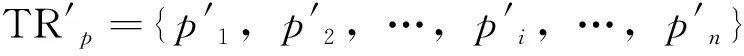
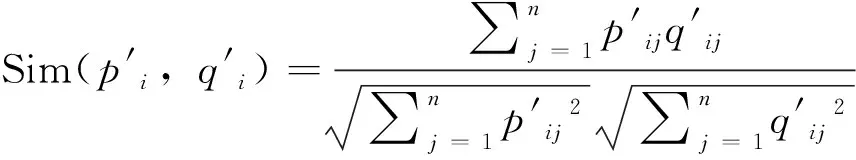
(7)
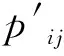
(5)计算轨迹的整体相似度。计算得到每一个子轨迹段的向量相似度后,结合该子轨迹段在整条轨迹中所占权重比例,即可得到轨迹整体相似度。
(8)
其中,ki为该子轨迹段在整条轨迹中所占权重,可以使用其长度百分比进行赋值。
最后,得到两条轨迹的整体相似性指标SimTra(P,Q)。整体相似性指标不仅通过Hausdorff距离体现了轨迹定位的时序性和相关性特征,而且通过子轨迹段的词向量相似性、对应的长度权重体现了轨迹的分段结构特征。因此,通过伴随模式挖掘得到的结果更加符合移动对象的实际伴随规律。
2 实验结果与分析
2.1 实验数据与运行环境
本文的实验数据是郑州市主城区内8万辆浮动车的定位数据,采集时间为2018年5月1日至31日,浮动车的定位频率为60 s。每条数据的记录包含车辆ID、经纬度坐标、速度、方向和时间等信息。
实验环境基于Spark框架构建[23],设备为5台服务器,配置均为Intel xeonE5-2640 2.6 GHz、8核、16 GB内存。其中,4台为分布式数据处理节点,负责对浮动车数据进行清洗、预处理、按照车辆ID和定位时序构成轨迹数据,并对其进行索引存储。另外1台服务器为中心管理节点,完成轨迹数据的分布式语义查询、进行轨迹切分、度量轨迹整体相似性,从而完成伴随模式挖掘。
2.2 轨迹切分实验
实验中分别使用了一对多、一对三和一对一的Hausdorff距离进行轨迹差异计算和切分。随机选取一个移动对象连续31 d中每天17:30-19:00的轨迹数据,距离阈值分别取10、20、30、40和50 m,统计运用三种轨迹切分方法计算Hausdorff距离所耗费的时间。图7为三种方法的计算效率。
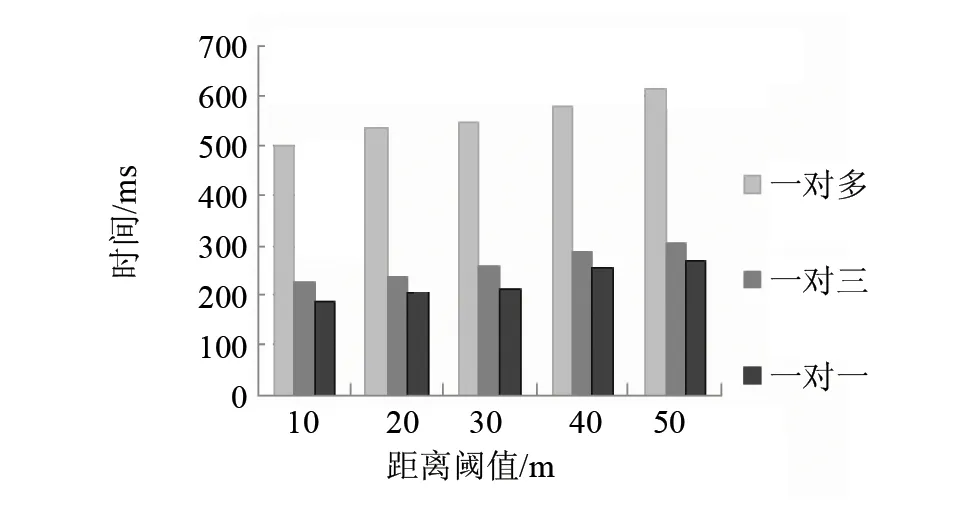
图7 三种计算方法的效率Fig.7 Efficiency of three calculating methods
从图7可以看出,不同的距离阈值对计算效率影响不大;而,三种方法的计算耗时顺序为一对多>一对三>一对一。设两条轨迹都包含n个定位点,则一对多的计算次数为2n2次,一对三和一对一的计算次数都是2n次。因此,一对三和一对一的计算量远小于一对多,所耗费时间也更少。一对三方法为了体现轨迹上定位点之间相关性,计算的距离为某定位点到另一条轨迹上三个点所形成的面的距离,和一对一方法的两点间欧氏距离算法相比较为复杂,因此耗时稍多。
选取郑州市某时段内10 000条轨迹作为待挖掘数据集,对其进行轨迹切分,并统计伴随轨迹数量,进行三种方法的准确性对比实验。统计结果如表1所示。

表1 三种时空Hausdorff距离挖掘准确性对比Table 1 Accuracy comparison of three spatial-time Hausdorff distance mining
根据表1的统计结果并结合人工检查,可以发现:一对三的伴随轨迹数量少于一对多的。这是因为一对多并不体现定位点的时序;一对三法挖掘的伴随轨迹数量多于一对一的。这是因为一对一的方法虽然体现了定位时序,但并未考虑上下游定位点之间的相关关系。因此,相比于一对多而言,一对三的方法排除了反向轨迹;相比于一对一而言,一对三的方法挖掘出了隐藏的伴随关系。
2.3 伴随模式挖掘实验
对轨迹进行切分后,使用词向量方法建立“子轨迹段—词”、“轨迹—语句”的类比关系,并利用语句中的结构模拟轨迹中的子轨迹段结构,实现整条轨迹在结构上的相似性度量。基于相似性度量指标可实现移动对象的伴随模式挖掘,图8为所挖掘的部分伴随轨迹的效果图。
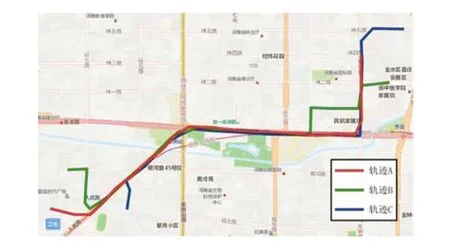
图8 伴随轨迹的可视化效果图Fig.8 Visualization of accompanying trajectories
从图8中可以看出,轨迹A、B和C在相同时段内,部分子轨迹段运行规律一致;但由于驾驶员对于道路的熟悉程度不同、偏好不同、中途点不同等因素的影响,有部分子轨迹段并非重叠;利用本文的词向量方法,可分析出的大部分子轨迹段具有共同的上下游。因此,它们在分段结构上具有较高的相似性,可以判断它们的运动规律符合伴随模式。
图9为郑州市三环范围内主要道路的伴随对象统计图。路段颜色越深,单位时间内符合伴随模式的移动对象数量越多。在图9中,城市主干道和快速路上挖掘到的伴随对象多于其他一般道路。这是因为:一方面受到道路等级和承载能力的限制,高等级的主干道交通流量较大,承载的移动对象较多;另一方面,次级道路的交通流一般呈现向主干道汇集的趋势,上下游路段在空间位置和方向上也具有一定的相关性。因此,移动对象的运动轨迹呈现的趋势为:起点和终点附近的子轨迹段匹配在次级道路上,而大部分移动轨迹匹配在主干道上。
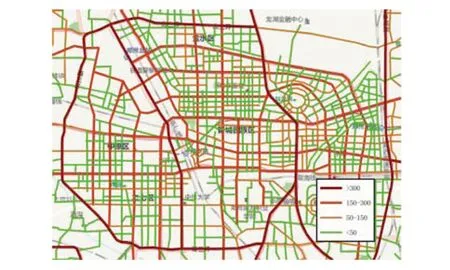
图9 伴随对象的统计图Fig.9 The statistical thematic maps of accompanying pattern mining
表2为工作日7:30-9:00、10:00-11:30、14:30-16:00和17:30-19:00四个时段的伴随对象统计表。如表2所示,早高峰时段7:30-9:00和晚高峰时段17:30-19:00的伴随对象数量明显高于另外两个平峰时段,这是因为高峰时段交通流量较大,符合伴随模式的移动对象数量较多。因此,通过本文设计的方法得到的符合伴随模式的移动对象在时间维度上的分布符合实际规律。

表2 不同时段伴随对象数量统计表Table 2 Statistics on the number of accompanying objects at different times
3 结 语
本文针对移动对象伴随模式的挖掘问题,设计了一种基于时空Hausdorff距离切分和词向量相似性度量的方法。发现:
1)在进行轨迹结构切分时,时空Hausdorff距离的计算采用了一对三的方法。此方法不但体现了轨迹定位点的时序特征,而且反映了上下游定位点之间的空间相关关系,可以排除反向轨迹,挖掘隐藏的伴随轨迹。其分析结果比一对多和一对一的方法更为准确,而且经过时间滑动窗口切分,将轨迹的分段特征提取出来,为词向量结构的相似性度量建立了基础。
2)在进行轨迹相似性度量时,将切分后的子轨迹段类比为词,整条轨迹类比为语句,利用词向量方法对轨迹段上下游结构相似性进行了计算。
此方法可以较为准确的度量伴随轨迹的相似程度,同时体现轨迹的空间、方向和时间异质性。通过实验验证,发现该方法挖掘到的伴随轨迹数量及其分布符合交通流的实际运行规律,可为发现同类群体或检测频繁路径等应用提供理论支撑。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
信号处理(2022年6期)2022-07-22
上海文化(文化研究)(2022年3期)2022-06-28
保健医苑(2021年9期)2021-09-08
河北画报(2020年8期)2020-10-27
五邑大学学报(自然科学版)(2019年3期)2019-09-06
煤炭工程(2019年6期)2019-06-22
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
舰船电子工程(2018年10期)2018-10-23
