
知识追踪模型在教育领域的应用:2008—2017年相关研究的综述
2019-11-09 13:40李菲茗叶艳伟李晓菲史丹丹
中国远程教育 2019年7期
李菲茗 叶艳伟 李晓菲 史丹丹

【摘要】 近年来,随着在线学习系统在教育环境中越来越普及,在线学习人数越来越多,教育者不可能追踪每一个学习者的知识状态并提供个性化的学习指导;在线学习系统中的知识需要学习者通过各种冗余信息自我查找,导致学习资源和学习路径多样化但却不一定有效。为了解决上述问题,一个可以自动追踪学习者知识掌握情况的知识追踪模型对教育者和学习者都是必要的,因为它既可以向教育者反馈学习者知识掌握情况,让教育者更加了解每一个学习者,也可以推断学习者的知识弱点,向学习者推荐高效的学习路径和恰当的学习资源,从而做到因材施教。通过2008—2017年相关文献的内容分析,从知识点、学习者和数据三方面总结知识追踪模型在教育领域的应用。知识追踪模型为教育研究者预测学习者知识掌握提供了一个便捷的途径,一直是教育数据挖掘领域的研究热点。
【关键词】 在线学习系统;知识追踪模型;学习路径;学习资源;知识点层面;学习者层面;数据层面;
教育应用
【中图分类号】 G434 【文献标识码】 B 【文章编号】 1009-458x(2019)7-0086-06
在线学习系统是快速发展的网络学习平台,在教育环境中越来越普及,吸引了数百万学习者注册学习多元化的在线课程。从教育研究的角度来看,在线学习系统提供了几个重要的优点,最显著的是留下学习者详细的学习轨迹,提供了调查不同轨迹下学习者行为效能的条件。然而,在线学习系统中的知识需要通过各种冗余信息自我寻求,对于学习者选择什么样的学习资源和学习路径,教育者还不能及时提供帮助,因此,学习者往往缺乏个性化的教学指导帮助他们更有效地学习。为了提供个性化的指导,教育者需要评估一个学习者知道什么,不知道什么,具体来说是根据过去一系列具有正确或不正确答案的练习自动分析学习者的知识掌握情况,预测其未来表现(闾汉原, 等, 2011)。其中一种方法是利用潜在变量(学习者知识掌握)和观察变量(学习者的表现)构建分析学习者知识掌握情况的知识追踪模型(如图1所示),为提供个性化学习资源和学习路径做好诊断。随着研究的深入,如何利用知识追踪模型研究学习者学习问题,以提高学习效率,成了研究者关注的问题。因此,本文的目的是通过对2008—2017年相关文献内容分析,总结出知识追踪模型预测学习者知识掌握的研究情况,为知识追踪模型在在线教育的应用和研究提供参考。
一、知识追踪模型
(一)知识追踪模型的起源
知识追踪模型是模拟学习者知识掌握情况的一个典型模型,由Atkinson于1972年首次提出。它假设每个知识点由猜测率、学习率、失误率和学习知识之前的先验概率4个参数组成(Pardos & Heffernan, 2010),并由Corbett和Anderson(1994)引入智能教育领域,目前已经发展成为智能辅导系统中对学习者知识掌握情况建模的主流方法。
(二)知识追踪模型的原理
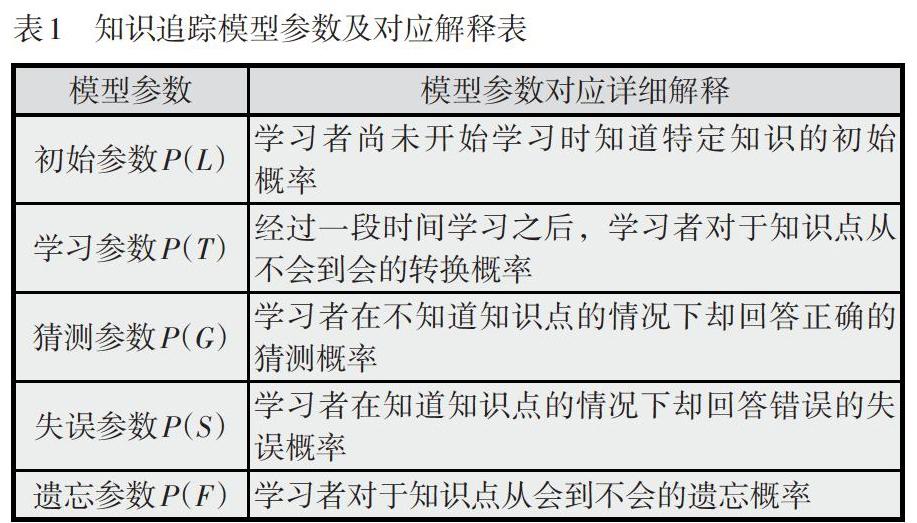
知识追踪模型需要对不同的知识点分别建模,因此,在分析学习者对知识点的掌握情况时一般是把将要学习的知识体系分为以层级关系连接的若干个知识点,并把学习者对每个知识点的掌握水平用一组二元变量来表示,每组二元变量代表学习者对此知识点处于“会”和“不会”两种状态之一。
具体来说,每个知识点赋予5个参数(如表1所示),分别为两个学习参数、两个表现参数和一个遗忘参数。初始概率P(L)和学习概率P(T)是学习参数,猜测概率P(G)和失误概率P(S)是学习者的表现参数。请注意,在Corbett和Anderson首次提出的知识追踪模型中遗忘概率P(F)设置为0,即假设学习者在知识学习过程中不存在遗忘现象(王卓, 等, 2015)。根据图1所示的知识追踪模型,每次学习者答题后模型都会根据答题正误的序列利用贝叶斯公式迭代更新其对知识的掌握情况。当P(G)和P(S)都为0时,说明学习者答题不存在猜测和失误情况,答题结果将会客观真实地反映学习者的知识水平;如果P(G)和P(S)值大于0.5,说明知识追踪模型出现模型退化现象,学习者回答问题的结果不能用来反映其真实知识水平。
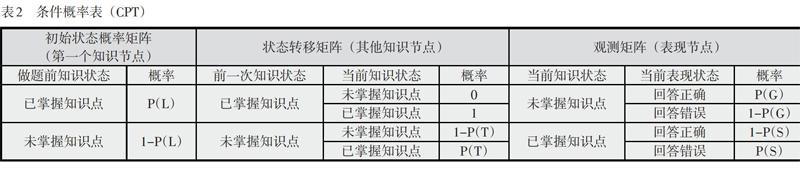
实际上知识追踪模型是一种特殊的隐马尔科夫模型(hidden markov model, HMM),每一个节点都通过条件概率表(conditional probability table, CPT)来量化父节点对自身的影响(如表2所示)。表现节点在知识追踪模型中是已知态,或为正确,或为错误;将已知的做题表现作为输入,分析学习者潜在知识节点的掌握情况,预测学习者再次遇到该知识点时的表现。
(三)知识追踪模型的概率公式和更新算法
根据对以上知识追踪模型的分析,很容易得到答对答错时的概率公式和知识水平更新算法。这些公式被用来预测学习者做题表现的概率,算法用來更新学习者知识掌握水平。
1. 根据做题数据训练好参数之后,预测学习者做题表现的概率
当答对题目时:学习者答对题目的概率被解释为在知道知识点的情况下没有犯错和在不知道知识点的情况下猜对的概率之和,即
当答错题目时:学习者答错题目的概率被解释为在知道知识点的情况下犯错和在不知道知识点的情况下猜错的概率之和,即
2. 学习者知识水平的更新算法
知识追踪模型分为两个阶段:一是上面提到的利用学习者的大量答题序列训练模型参数;二是学习者在学习过程中的知识掌握情况随着时间变化,[P(L)]表示所有学习者对知识点掌握的初始情况。在推断学习者对知识点的掌握情况时,每次学习者给出答案后,利用已训练好的模型基于该学习者答题正误的序列,使用贝叶斯公式迭代更新其对知识掌握的程度值(Pardos, Bergner, Seaton, & Pritchard, 2013)。知识点掌握情况迭代更新的算法思想如表3所示。其中,[P(Lk)]表示学习者在回答第k道题之前对相应知识已掌握的先验概率,而[PLk|evidencek]根据学习者第k道题回答情况,表示更新后的已掌握知识的后验概率。另外,最后一个等式表示的是学习者答题后收到系统反馈时的学习转化过程,这个公式在加入学习概率后计算新的先验概率。
总的来说,知识追踪模型是预测学习者下一阶段学习表现的一项重要建模技术。上述介绍为理解知识追踪模型提供了基本指导原则。知识追踪模型能够用一种更加直观且容易理解的方式判断学习者什么时候掌握了某个知识点,而不是简单地以学习者连续N个同一知识点题目回答正确来判断。因此,对于知识追踪模型的研究者而言,需要了解如何运用和解释知识追踪模型的变化,以便在变化的学习环境中更恰当地理解学习者的知识掌握情况。
二、研究对象的选择
本研究的中文文献来源于中国知网(CNKI),英文文献来自Springer数据库、Wiley-Blackwell数据库和ACM数据库。文献的时间跨度为2008— 2017年。中文使用“贝叶斯知识追踪”和“知识追踪”,英文使用“Bayesian Knowledge Tracing”和“Knowledge Tracing”作为关键词在相应的中英文数据库进行精确搜索获得相关文献。对获得的相关文献进行分析整理,选取关于知识追踪模型教育应用的文献纳入研究样本,最终选定58篇文献,其中英文文献56篇,中文文献2篇,可见国外知识追踪模型研究文献相对较多。
通过深入分析这些相关文献,希望能揭示知识追踪模型在教育领域应用的三个问题:①知识追踪模型分析了知识点的哪些方面;②学习者的哪些特性影响知识追踪模型的效果;③数据集包含的样本和数据量对知识追踪模型的影响。
三、文献内容分析
各种各样功能丰富的在线学习系统正在产生大量的数据。为了分析这些数据,研究人员经常使用一种发展了20年的方法——知识追踪,目前知识追踪模型已经成为对学习者知识掌握情况建模的主流方法。通过对2008—2017年知识追踪模型相关文献内容的分析,文章从以下三个方面分析知识追踪模型的教育应用。
(一)从知识层面分析知识追踪模型的教育应用
知识追踪模型根据学习者答题情况反映当前知识点的掌握状况,追踪学习者在学习过程中知识掌握情况的变化,在知识追踪模型的知识点层面从单个知识点和多个知识点两个角度分析教育领域已有的研究。
首先,从单个知识点角度,Hawkins等(2014)研究了同一知识点中各问题的相似性对于适度提高知识追踪模型预测准确性的作用,发现问题之间相似度越大模型预测表现越好;Pardos等(2011)研究通过增加知识难度节点使知识追踪模型给学习者合理分配知识练习的时间,并提高学习者知识掌握情况反馈报告的准确性;Lin等(2016)對每个知识点采取不同类型的教学干预措施(如一种诱发式教学干预),使答题数据与知识追踪模型的拟合性更强,并提升模型的预测精度。
从多个知识点角度,即知识组合不仅仅是单个知识的“总和”,而是将知识与知识相结合(或连接起来)以产生额外知识,且较低层次的知识作为了解更高层次知识的先决条件。Lee等(2015)使用知识追踪模型来追踪随着时间的推移知识的出现模式,发现知识之间层级和关系的拓扑结构;Klingler等(2014)研究了知识组合的不同层级和关系,结果表明获取知识之间的层次结构可以显著提高知识追踪模型预测精度;Huang等(2016)研究了具有知识组合分层功能的知识追踪模型,结果表明这种模型显著提高了知识掌握预测精度,并且倾向于更合理地分配学习者各知识点的学习时间;值得一提的是,Zhang等(2016)的研究表明,知识拓扑结构的目标是产生满足所有先决条件的一系列知识,以前的研究很少从知识追踪模型的角度看待这一问题。实验结果也显示,知识拓扑结构可用于提高学习者的学习效率,并为学习者提供个性化的学习路径;David等(2016)在知识追踪模型中采用一种序列算法排列学习者各知识点掌握情况来推荐个性化教育内容,以满足他们个性化的学习资源需求;Zhang等(2016)的研究利用各个知识点之间的关系,直接输出学习者对每个知识的掌握程度,并描绘学习者知识掌握的变化,更好地模拟学习过程,提高学习者的学习效率。
(二)从学习者层面分析知识追踪模型的教育应用
对知识追踪模型的学习者层面研究表明,学习者特性对模型预测精度有影响。在该研究层面也确定了可以提高预测精度的两类方法:模型本身包含的学习者参数特性和学习者学习参与特性。
Nelimarkka等(2014)研究表明,先验概率值的设定不是越大越好,因为具有较高先验概率的学习者产生较少的信息供知识追踪模型来估计猜测率和学习率,估计误差会略有增加;Pardos等(2010)利用相关知识先前的数据集建模,赋予学习者不同的先验概率,结果表明模型预测精度明显改善;Corbett等(2008)通过学习者前后答题情况估计猜测率和失误率,而不是在所有情况下使用固定猜测和失误率,结果显示知识追踪模型预测学习者表现比以前的方法明显更精确;QIU等(2011)确定了贝叶斯知识追踪模型在预测学习者表现方面存在系统错误的特殊情况——随着时间知识遗忘这种现象,虽然这不令人惊讶,但是加入学习者随着时间会遗忘的特性,知识追踪模型更容易解释,并可以更好地拟合一些数据集。
尽管模型本身包含的学习者参数特性通常也能很好地预测学习者的表现,但它没有考虑到学习者的学习参与特性。Spaulding和Breazeal(2015)对学习者情绪状态的研究表明,学习者情绪(高兴/悲伤等)影响知识追踪模型的交互时间和预测准确性;闾汉原等(2011)的研究结果表明,学习者的学习态度影响知识追踪模型的预测准确性;Xu等(2014)通过脑电波(EEG)捕捉的精神状态来估计学习者在冷静或专注等状态下的学习效率和失误率,并从EEG数据中推断学习者的参与度,可以及时调整知识追踪模型以便重新吸引学习者最终提升学习效率;而Schultz等(2014)则利用知识追踪模型研究了学习者学习过程中的不参与行为。
(三)从数据层面分析知识追踪模型的教育应用
从数据层面分析知识追踪模型教育应用有三个方面:①提高数据所包含的信息量。如Wang(2011)和Heffernan等(2013)的两个研究中不仅是从学习者回答问题的正确(1)和错误(0)两个维度获取数据,而是赋予每个学习者连续的0~1之间的值代表答对题的概率,结果表明这种方法可以更精确地估算学习者知识掌握水平,实现知识追踪模型更精准的未来表现预测。②使用部分数据代替所有数据训练知识追踪模型参数。如Nooraei等(2010)使用这一方法发现:每个学习者最后15个问题的数据训练知识追踪模型在节省运行时间的同时取得和使用学习者总体数据训练的知识追踪模型可比的预测效果。③确定选择多大的样本量。如果训练样本量不够充分,即使是完美的拟合算法也会产生预测能力较差的参数,样本量多了虽然预测效果好,但却加大了模型运行时间。如Coetzee等(2014)在研究了知识追踪模型的样本量后提出用于训练模型的学习者数量以及生成参数的值等因素,提高对推断参数的准确性的估计,分析表明误差的标准偏差大致与1/[n]成正比(n是样本大小),从而给出了在理想的或可接受的标准偏差下应该取多大样本量的参考。
以上研究表明,选择不同的数据类型(二进制数据或连续数据)、题目数量和学习者样本量来训练知识追踪模型会导致模型预测精度的差异,所以应该根据不同的需求选择包含需要的知识点维度和学习者维度的数据。不同维度的选取要有相关性,否则会导致数据处理时难以形成逻辑,更多的只能流于表面和片段式分析。
上述研究从知识点层面、学习者层面和数据层面对知识追踪模型的教育应用做了探索。在知识点层面研究了单知识点的难度和同一知识点不同题目之间的相似性,以及多知识点的知识层级关系和知识拓扑顺序等知识组合问题。在学习者层面研究了根据学习者特性制定的知识追踪模型五个参数(先验知识/学习速率/猜测概率/失误率/遗忘)对模型的影响,并探究了学习者情绪、态度和参与度等对于提高模型预测精度的作用。在数据层面研究了数据集包含的维度和样本量对知识追踪模型预测精度的影响。通过对这三个方面的探讨揭示出,调整这三个层面中的一个方面有助于改善知识追踪模型的预测准确性(Zhang, et al., 2017)。
另一类优化知识追踪模型预测精度的方法是将知识追踪与其他模型组合应用。如Gonzalez-Brenes等(2014)研究证明,知识追踪与其他建模方法组合应用对模型预测精度可以有更好的影响。Khajah等(2014)组合知识追踪和项目反应理论(Item Response Theory, IRT)两种互补模型——以知识追踪模拟学习者学习、IRT反映学习者的个体差异来预测学习者的知识掌握,结果显示组合模型显著優于知识追踪模型。这个结论与Khajah等(2014)利用潜在因素结合知识追踪模型得出的结论一致;该结论在Xu等(2013)利用项目反应理论结合知识追踪的研究中也曾被提及。Cai等(2015)组合知识追踪和回归分析模型研究学习者整体学习趋势来预测学习者的未来表现,获得了更好的预测效果。这类建模方法组合研究为优化知识追踪模型预测精度提供了一些可用建议:在预测学习者未来学习表现时,应该根据不同的预测要求选择不同的模型组合。另外,在模型组合中不同模型呈现的内容要有相关性,否则会导致处理学习内容时需要更长的时间,从而降低学习效率。
四、结论与展望
正如文献分析结果所显示的,知识追踪模型能通过对前一阶段的表现来预测学习者对知识的掌握情况,并可以利用知识之间的关系,自动描绘学习者不断变化的知识状态,分析学习者整体学习趋势,更好地模拟学习者的学习过程,提高学习者的学习效率;通过分析学习者的学习轨迹所包含的有意义信息,潜在地做出提供暗示、反馈或建议新的练习等干预措施,让教育者更加了解学习者的进步和问题领域,满足学习者对个性化学习路径和学习资源的需求,提高智能辅导系统的有效性,为研究者实现自动分析学习者知识掌握程度、自动评价学习者和自动反馈给学习者自适应的学习资源和学习路径提供动态的数据支撑。
知识追踪模型作为一种对学习者知识掌握情况建模的主流方法,在教育和军事等方面都已经有了不少成功案例,研究的深度和广度都得到了很大的拓展。然而,本文认为在知识点、学习者和数据三个层面都还存在一些不足。例如对于知识掌握的预测会设定度和阈值,但是很少涉及学习者知识掌握判定的度或阈值的设定,不知道什么类型的知识设定什么样的阈值范围,以及设置阈值的依据是什么;而且现有的知识追踪模型相关文献多是对单个学习者对于知识点掌握预测,缺少小组学习、合作学习/协作学习的学习者知识掌握的研究。另外,虽然已经知道数据量和样本量的选择都会影响模型预测精度和模型运行时间,但还没有相对可靠的标准给出何种类型的探究实验对应大致的样本和数据量范围。但毋庸置疑的是,知识追踪模型比判断学习者知识掌握的传统方法提供了更丰富的动态信息和预测,使教育者可以面对更多学习者,更加了解学习者知识的掌握,让学习者更加清楚自己学习的问题。随着人工智能技术的发展,知识追踪模型在教育领域的研究会得到越来越广泛的运用。
下一步我们计划利用加入遗忘的标准知识追踪模型与动态键值存储网络组合模型等分析具体的学习数据,探究在教育中的应用,希望知识追踪模型不仅仅应用在自动监督、自动评价和自动反馈等方面,还能向第二导师方向发展,真正实现教育领域的一对一、个性化和自适应,为教学程序的改善和学习效果的增强寻求可行的途径。
[参考文献]
闾汉原,申麟,漆美. 2011. 基于“态度”的知识追踪模型及集成技术[J]. 江苏师范大学学报(自然科学版),29(4):54-57.
王卓,张铭. 2015. 基于贝叶斯知识跟踪模型的慕课学生评价[J]. 中国科技论文,10(2):241-246.
Baker, R. S. J. D., Corbett, A. T., & Aleven, V. (2008). More accurate student modeling through contextual estimation of slip and guess probabilities in bayesian knowledge tracing. Lecture Notes in Computer Science, 5091, 406-415.
Cai, Y., Niu, Z., Wang, Y., & Niu, K. (2015). Learning Trend Analysis and Prediction Based on Knowledge Tracing and Regression Analysis. Database Systems for Advanced Applications. Springer International Publishing.
Chen, L., & Min, C. (2016). Intervention-BKT: Incorporating Instructional Interventions into Bayesian Knowledge Tracing. International Conference on Intelligent Tutoring Systems (pp. 208-218). Springer, Cham.
Coetzee, D. (2014). Choosing Sample Size for Knowledge Tracing Models. EDM (Workshops).
Corbett, A. T., & Anderson, J. R. (1994). Knowledge tracing: modeling the acquisition of procedural knowledge. User Modeling and User-Adapted Interaction, 4(4), 253-278.
David, Y. B., Segal, A., & Gal, Y. (2016). Sequencing educational content in classrooms using bayesian knowledge tracing (pp. 354-363).
Gonzalez-Brenes, J., Huang, Y., & Brusilovsky, P. (2014). General features in knowledge tracing to model multiple subskills, temporal item response theory, and expert knowledge.
Hawkins, W. J., & Heffernan, N. T. (2014). Using Similarity to the Previous Problem to Improve Bayesian Knowledge Tracing. EDM (Workshops).
Huang, Y., Guerra-Hollstein, J. D., & Brusilovsky, P. (2016). Modeling Skill Combination Patterns for Deeper Knowledge Tracing. The Intl. Workshop on Personalization Approaches in Learning Environments.
K?ser, T., Klingler, S., Schwing, A. G., & Gross, M. (2014). Beyond Knowledge Tracing: Modeling Skill Topologies with Bayesian Networks. Intelligent Tutoring Systems. Springer International Publishing.
Khajah, M. M., Huang, Y., Gonzalez-Brenes, J. P., Mozer, M. C., & Brusilovsky, P. (2014). Integrating knowledge tracing and item response theory: a tale of two frameworks. Bmj Quality & Safety.
Khajah, M. M., Wing, R. M., Lindsey, R. V., & Mozer, M. C. (2014). Integrating latent-factor and knowledge-tracing models to predict individual differences in learning. Journal of Nursing Education, 39(9), 409-11.
Lee, H. S., Gweon, G. H., Dorsey, C., Tinker, R., Finzer, W., & Damelin, D., et al. (2015). How does Bayesian knowledge tracing model emergence of knowledge about a mechanical system? International Conference (pp. 171-175).
Nelimarkka, M., & Ghori, M. (2014). The effect of variations of prior on knowledge tracing. In International Conference on Educational Data Mining.
Nooraei, B. B., Pardos, Z. A., Heffernan, N. T., & Baker, R. S. J. D. (2010). Less is More: Improving the Speed and Prediction Power of Knowledge Tracing by Using Less Data. International Conference on Educational Data Mining, Eindhoven, the Netherlands, July (pp. 101-110). DBLP.
Pardos, Z. A., & Heffernan, N. T. (2010). Modeling Individualization in a Bayesian Networks Implementation of Knowledge Tracing. International Conference on User Modeling, Adaptation, and Personalization (Vol. 6075, pp. 255-266). Springer-Verlag.
Pardos, Z. A., & Heffernan, N. T. (2011). KT-IDEM: Introducing Item Difficulty to the Knowledge Tracing Model. User Modeling, Adaption and Personalization. Springer Berlin Heidelberg.
Pardos, Z., Bergner, Y., Seaton, D. T., & Pritchard, D. E. (2013). Adapting Bayesian Knowledge Tracing to a Massive Open Online Course in edX. International Conference on Educational Data Mining (Vol. 66, pp. 939–951).
Qiu, Y., Qi, Y., Lu, H., Pardos, Z. A., & Heffernan, N. T. (2011). Does Time Matter? Modeling the Effect of Time with Bayesian Knowledge Tracing. International Conference on Educational Data Mining, Eindhoven, the Netherlands, July (Vol. 39, pp. 139-148).
Schultz, S. E., & Arroyo, I. (2014). Expanding Knowledge Tracing to Prediction of Gaming Behaviors. EDM (Workshops).
Spaulding, S., & Breazeal, C. (2015). Affect and Inference in Bayesian Knowledge Tracing with a Robot Tutor. The Tenth ACM/IEEE International Conference (pp. 219-220). ACM.
Wang, Y. (2011). Extend the knowledge tracing framework using partial credit as performance.
Wang, Y., & Heffernan, N. (2013). Extending Knowledge Tracing to Allow Partial Credit: Using Continuous versus Binary Nodes. International Conference on Artificial Intelligence in Education (Vol. 7926, pp. 181-188). Springer Berlin Heidelberg.
Xu, Y., Ave, F., & Mostow, J. (2013). Using item response theory to refine knowledge tracing. Psychiatry-interpersonal & Biological Processes, 26(6), 1015-20.
Xu, Y., & Chang, K. (2014). Using eeg in knowledge tracing.
Zhang, J., & King, I. (2016). Topological Order Discovery via Deep Knowledge Tracing. Neural Information Processing. Springer International Publishing.
Zhang, J., Shi, X., King, I., & Yeung, D. Y. (2016). Dynamic key-value memory networks for knowledge tracing.
Zhang, L., Xiong, X., Zhao, S., Botelho, A., & Heffernan, N. T. (2017). Incorporating Rich Features into Deep Knowledge Tracing. ACM Conference on Learning (pp. 169-172). ACM.
收稿日期:2018-03-30
定稿日期:2018-05-22
作者簡介:李菲茗,博士,副教授,硕士生导师;叶艳伟,硕士研究生;李晓菲,硕士研究生;史丹丹,硕士研究生。浙江工业大学教育科学与技术学院(310023)。
责任编辑 韩世梅
猜你喜欢
中国典型病例大全(2022年12期)2022-05-13
学生天地(2020年15期)2020-08-25
意林·少年版(2020年2期)2020-02-18
体育时空(2017年5期)2017-06-17
海外华文教育(2016年4期)2017-01-20
中国卫生(2016年2期)2016-11-12
课程教育研究·学法教法研究(2016年14期)2016-06-29
教学考试(高考化学)(2016年5期)2016-03-17
新课程学习·下(2015年2期)2015-10-21
中国音乐教育(2015年3期)2015-05-20
