
高校大数据平台构建研究
2020-02-06 13:46
岳阳职业技术学院学报 2020年6期
(岳阳职业技术学院 信息工程学院,湖南 岳阳 414006)
大数据时代,高校管理中数据激增,仅数据收集(不涉及分析与利用)就已经成为管理者的负担,大数据已成为高校一个无法回避的挑战。海量数据中包含着各种信息,大数据技术在各行各业中作用日益凸显,成为推动社会转型的新动力和提升社会治理能力的新途径[1]。高校大数据技术实施过程中,大数据平台的构建是至关重要的一个环节,关系到大数据项目的落地实现。
1 高校大数据平台的建设现状
随着信息化建设的发展,高校已完成了校园网站的建设、校园一卡通业务系统的建设,建成了教学管理系统、学生工作信息管理系统、教务管理系统、科研系统等,基于校园网的信息资源和应用系统建设不断丰富和完善[2]。现有管理系统内蕴含的巨量数据(数据量以TB 计),为师生的学习、生活、教学、科研、管理等方面提供了丰富的数据信息。但由于系统间技术架构各异,数据标准不一,形成信息孤岛,信息共享难以实现,阻碍了部门间的协作[3]。另一方面,日常产生的海量日志类数据,以及记录校内群体行为的数据,蕴含了巨大的价值,需要存储、处理和分析[4]。
2 高校大数据平台的构建目标
数据资源建设是高校信息化建设的重要组成部分,经过多年的建设,高校校园信息化系统已积累了大量的数据。高校大数据平台建设的目标为:利用大数据技术,对校园数据进行采集、清洗、整理和分析,充分挖掘其中蕴含的价值,为师生提供智能化的服务,为高校的发展提供决策支持,为高校的管理提供指导方向,实现信息综合服务能力的提升,为校园建设奠定基础[5]。
3 高校大数据平台的架构设计
高校大数据平台要运用大数据技术,对学校已有数据进行充分的挖掘、分析,并通过数据可视化工具,快速地构建数据图表,有效地展示结果,高效地发挥数据的价值[6]。因此,需实现数据采集、数据存储、数据分析、数据展示的功能。
课题组依据高校数据特点,在传统高校数据平台的基础上,以数据采集、数据存储、数据分析、数据展示为主线,结合大数据领域最流行的Hadoop 框架与Spark 框架,展开了高校校园大数据平台架构,如图1 所示。
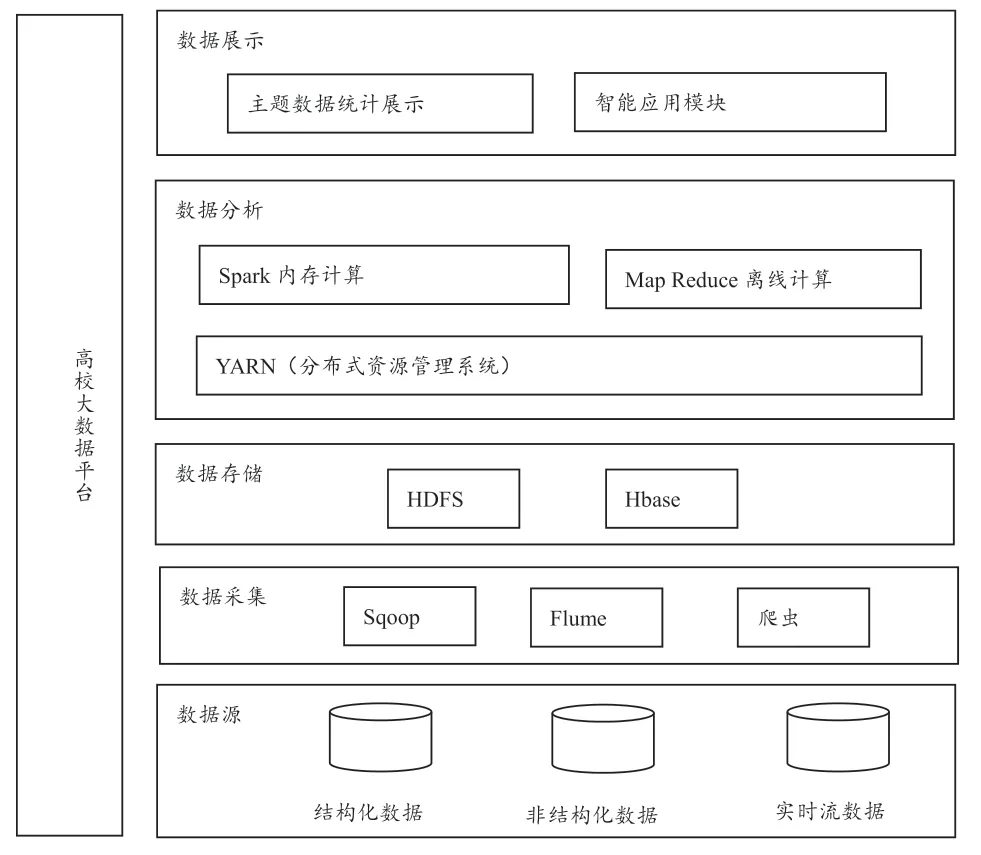
图1 高校校园大数据平台架构
平台以Hadoop 为核心。Hadoop 为大规模并行数据处理算法提供运行环境,支持PB 级别的存储容量,适合大数据分析应用,适合大服务器集群的运行。根据实际需要,平台上选用了一些Hadoop 家族的开源组件(如Sqoop、Hbase、Yarn、Spark 等)。这些开源组件的优势在于:社区活跃,组件能得到不断维护和更新;用户较多,存在的bug 能被及时发现并修补,质量更可靠;代码开源,可结合项目的需求修改代码,使用风险低。
3.1 数据采集
数据采集是数据分析的基础,这个模块负责多模态数据的广泛采集,所采集的数据包括结构化的业务数据(教务、学工、科研、财务等业务数据)、半结构化或非结构化的机器数据(HTML日志、网络日志等机器数据)和学校外部互联网数据。数据采集的设计,取决于数据源的特性。数据源是整个大数据平台蓄水的上游,而数据采集只是获取水源的管道。大数据平台数据采集必须支持数据源的多样性,不同的数据源使用不同的工具,在数据采集的过程中应确保数据的质量和可靠性。
本研究的高校大数据平台数据采集主要由Sqoop、Flume 和爬虫组成。Sqoop 主要用于HDFS与关系型数据库(Mysql、Oracle、SQLserver 等)之间的数据传输,能够将关系型数据库中的数据导入到HDFS 中,或将HDFS 中的数据导入到关系型数据库中。Flume 负责基于Hadoop 平台的系统日志数据采集。高校大数据平台产生大量高价值系统日志信息,Flume 采用分布式管道架构和流处理方式,可满足平台对信息速度的需求。网络爬虫负责网络数据采集,按照一定的规则,通过网页链接地址寻找网页,自动地抓取万维网信息。校园大数据平台需要对现实网页中的数据(包括网页、数据、图片和文件等)进行采集、预处理和保存,网络爬虫正好适合。
数据采集的任务可根据需要设置定时运行,浏览接口运行的情况,对数据接口设置全量更新或增量更新。采集来的数据采用数据集的方式管理,设置钻取路径、数据归档备份、数据回滚操作,保证数据的安全可靠以及系统的稳定。
3.2 数据存储
大数据面对的数据量异常大,数据结构复杂,因此,大数据平台的数据存储模块需要集成多种类数据存储技术。对于传统业务系统数据,采用关系型数据库进行存储,对于半结构化、非结构化数据,采用HDFS 进行存储。依据实际情况,制定合适的存储策略,将数据存放到相应的逻辑存储区中,方便管理和调用。
本研究设计的校园大数据平台存储方面主要涉及Hadoop 分布式存储技术,包括HDFS(Hadoop Distributed File System)分布式文件系统。分布式存储技术将很大的记录查询任务拆分到不同的节点上进行查询,每个节点数据量不会很大,从而提升了查询效率。HDFS 为海量数据提供了高容错性和高吞吐量的数据存储,除HDFS 外,数据存储模块还采用开源数据库HBase,HBase 是一种分布式、面向列的数据库,它部署在HDFS 上,通过添加廉价的商用服务器,增加计算和存储能力。HBase 是非关系型数据库,它摆脱了表的存储模式,再加上起步较晚,因而对大数据的响应要比关系型数据库快的多。
校园大数据平台还要建设符合要求的数据仓库,数据仓库根据主题的不同,将原本分散的数据集成新的数据源,产生新的数据接口,供系统调用。
3.3 数据分析
大数据领域研究的热点问题为:如何将来源各异的海量数据,经过有效的分析处理,得到有价值的信息。
高校大数据平台业务需求为:基于数据仓库中的数据,运用编程语言,结合当前主流的大数据处理分析框架和工具,对数据进行全方位、深度的挖掘和分析,提供有价值的信息,供学校领导层作方向判断和决策制定。
这里,数据分析模块主要采用的组件为YARN、Spark 和MapReduce。YARN 用来为上层应用提供统一资源管理和调度,主要有三大模块:RM 负责资源的监控、分配和管理;AM 负责应用程序的调度和协调;NM 负责节点的维护。3 个模块协同工作,完成集群的资源统一管理,出色地实现资源利用率、数据共享等。
Spark 是专为大规模数据处理设计的内存计算框架。Spark 中数据被高度抽象、存储,加载到节点内存中,在内存中完成计算,能够快速访问数据,有效提高了执行的时间效率,特别适合数据分析中的批处理、迭代计算、交互式处理(如数据挖掘)和流式处理(如点击日志分析)等。
MapReduce 框架用来为大规模数据集提供并行计算,通过将待处理的大数据分为多个数据块,分配、调度计算节点处理相应的数据块,监控节点的执行,并负责执行的同步控制,为编程人员将程序运行在分布式系统上提供方便。
数据分析模块提供数据挖掘开发工具,用户可在平台图形界面自行指定数据源、配置算法参数和数据输出位置。模块在数据仓库的基础上,运用常用的统计方法,如关联规则分析、线性回归等,通过专业软件进行分析、挖掘处理后,给出有数据支撑的报告,从中发现问题,预测趋势。例如:在学生在校相关行为日志数据的基础上进行大学生行为分析,对学生学习、消费等趋势作出预测。
数据分析模块还提供数据分析建模工具,数据分析建模工具运用常用的机器学习算法,根据用户需求,在已有数据基础上,自动进行智能分析,提供参考结果。如学生异常行为发现、绩效考核预警等。
3.4 数据展示
数据展示模块主要采用数据可视化技术,将数据分析结果在图表视窗中清晰、直观地展示出来。数据展示模块提供图形化拖拽界面,支持各类统计图、报表的自动生成、灵活部署。图表、仪表板和数据报表是数据最直接的展现方式。数据可视化技术支持人机交互方式下,各种统计分析图表类型的绘制。
数据展示分为主题数据统计展示和智能应用模块。主题数据统计展示根据不同的主题,形成数据统计展示,包括领导驾驶舱数据展示、教师个人数据展示、学生个人数据展示等;智能应用模块展示包括学生综合预警功能、网络安全预警功能等。
4 结束语
大数据平台是高校校园数据的中心,大数据平台的构建,为高校大数据的应用提供数据、管理、服务、技术等多层面的有效支撑。高校大数据平台的建设,解决了高校数据共享问题,以及非结构化数据存储与处理问题,
本研究提出的校园大数据平台,基于当前最流 行的Hadoop 开放式架构,采用Sqoop、Flume 和爬虫完成各类数据的采集,采用HDFS 完成分布式存储,采用YARN、Spark 和MapReduce 组成分析模块,采用数据可视化技术进行数据展示,能够对校园信息进行综合的分析整理,更好帮助教师管理学生,加快推进智慧校园的建设。下一步将重点研究大数据相关算法以及架构中数据利用过程中的安全问题和隐私保护问题。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
琴童(2017年3期)2017-04-05
小天使·二年级语数英综合(2017年3期)2017-04-01
浙江大学学报(工学版)(2015年2期)2015-05-30
土木建筑工程信息技术(2013年4期)2013-10-17
汽车与新动力(2012年1期)2012-03-25
