
基于机器学习的苹果始花期预测
2020-03-13 11:48张兴伟陈超田姗付琳
中国农业科技导报 2020年10期
张兴伟, 陈超, 田姗, 付琳
(成都信息工程大学, 成都 610225)
物候现象是生物节律与环境条件的综合反映。从气象条件来说,它不仅反映了当天的天气,而且反映了过去一段时间气象条件的累积情况[1]。始花期预测正是基于这一理论而开展的研究。休眠是植物在生长过程中形成的一种对环境和季节性气候变化的生物学适应[2],是植物发育中的周期性过程。休眠不仅可以使果树度过寒冬,而且也是落叶果树下一年正常开花结果必需经历的一个过程[3]。果树生长过程中,当温度降低时落叶果树进入休眠期,冷量温度逐渐累积,果树自身通过一系列的生理变化应对温度降低,当冷量积累到一定程度,满足需冷量后开始升温,随即进入萌芽期开始累积热量,此时果树体内通过一系列生理变化来促进芽的萌发和生长[4]。在苹果丰产栽培中,为了达到苹果高产、优质、稳产、高效之目的,必需将苹果营养生长规律与栽培管理密切结合起来。始花期的早晚是过去一段时间的气象条件累积对果树产生的影响。目前,关于苹果始花期的预测从特征向量上来分,有单气象因子与多气象因子两种。从算法模型上分,有统计学建模和线性回归建模。蒲金涌等[5]和毛明策等[6]研究了气温对苹果始花期的影响。李美荣等[7]在果树物候模型理论的基础上,应用统计学方法对不同月份气温进行分析建模。柏秦风等[8]从苹果花期以前日平均温度的不同摄氏度积温及天数进行分析建模。张艳艳等[9]使用最小二乘回归法进行多因子分析预测建模。藏曦[10]使用不同月份的不同气象数据进行多因子逐步回归预测建模。同时,通过对其他果树的分析可以发现[11-13],多因子线性回归建模为花期预测的主流预测方法。
多元线性回归预测建模能够很好的表征果树生长过程受不同气象因子的影响。但是目前的研究更多只是在算法层面,并没有很好的表明影响苹果始花期的主要影响时间段。根据山西省临汾市气象局发布的农用气象预报,研究分析休眠期内三个时间段的生长特性对苹果树的影响:是否发生冻害(12月1日至次年3月1日)、能否正常越冬(11月1日至次年3月15日)和热量和水分需求(3月1日至3月21日)。通过机器学习中的多元回归方法和组合方法预测始花期,从而可以得到影响始花期的主要时间段及主要影响气象因子,同时完成对始花期的提前、精准预测,以期帮助果农提前做好农事安排和病虫害防治,为苹果果园清园、病虫害防治、田间管理和施肥提供建议,从而有助于增加果树树势和抵抗力,使苹果的经济效益最大化。
1 数据与方法
1.1 数据来源
气象资料包含吉县1987—2017年温度、降水量、湿度、地温、日照时长等气象因子,数据来源于山西省临汾市吉县气象局。
2010—2017年苹果物候期资料由山西省临汾市吉县气象局提供,观测品种为“红富士”。
1.2 处理方法
1.2.1时间间隔 以每年1月1日起至苹果果树开花始期为时间间隔,用于花期的预测。根据“中国物候观测网”的观测标准,植物始花期定义为观测植株上开始出现第一个完全开放花朵的日期[14]。
1.2.2数据标准化和相关性分析 使用Z-score标准化方法,将不同量级的数据统一转化为同一个量级,统一利用Z值进行衡量,以保证数据之间的可比性,消除由于不同量级数据所带来的影响。
(1)
式中,x为观测值,μ为总体平均值,σ为总体标准差。
使用皮尔逊相关系数(pearson correlation coefficient),用于度量两个变量x和y之间的线性相关性。
(2)
式中,cov(x,y)为x和y的协方差,σx和σy分别为x和y的方差。
1.3 评价指标
均方误差(MSE)是指参数估计值与参数真值之差平方的期望值,它可以评价数据的变化程度,MSE值越小,预测模型描述数据具有更好的精确度。
(3)
均方根误差(RMSE)是均方误差的算术平方根,RMSE值越小,模型越好。
(4)
平均绝对误差(MAE)是绝对误差的平均值,能够很好地反映预测值误差的实际情况。MAE值越小,模型越精准。
(5)
式中,yi表示实际值,fi表示预测值。
决定系数(R2),又称为判定系数或拟合优度,它反映因变量的全部变异能通过回归关系被自变量解释的比例。表征了回归方程在多大程度上解释了因变量的变化,或者说方程对观测值的拟合程度如何[15]。R2值越大越好,当预测模型不犯任何错误时值为1。
(6)
式中,SSR为回归平方和,SST为总平方和。
MSE、MAE同样也是线性回归的损失函数,损失函数的选取受到多方因素的制约和影响,常见的影响因子有异常值、时间复杂度、求导困难度、预测值置信度等[16]。在线性回归的时候目的就是让损失函数越小越好。
1.4 模型建立
1.4.1相关性分析 在进行特征向量选择时,尽可能剔除不相关或冗余的特征向量,从而减少特征向量个数,提高模型精确度,减少模型运行时间。相关性分析可以帮助完成数据的筛选,达到降维的目的。使用pandas库中的.corr函数,分别对12月1日至次年3月1日(是否发生冻害)、11月1日至次年3月15日(能否正常越冬)和3月1日至3月21日(热量和水分需求)三个时间段的数据进行相关性分析。同时,通过.nlargest函数设置参数k=4选择出与时间间隔相关性最大的4个气象数据因子(包含时间间隔),完成多元线性回归模型中自变量的选择。
1.4.2多元线性回归 回归模型应用训练集数据进行参数估计,得到回归模型。如果回归分析中包含两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归。给定由d个属性描述的示例x=(x1;x2;…;xd),其中,y=w1x1+w2x2+...+wdxd+b,一般用向量形式表示(式7)。
f(x)=wTx+b
(7)
式中,w=(w1;w2;...;wd)。
当权重w和截距b学习得到之后确定模型。选择30%气象因子作为特征向量进行预测,而剩余的70%为冗余向量。即选择与时间间隔相关性最大的3个特征(不包含时间间隔)作为特征向量,分别对三个时间段进行多元线性预测建模。使用2017年数据为测试集,验证模型准确性。剩余年份为训练集,用于模型训练。三个时间段所对应的预测模型选用的特征向量分别为:15 cm地温、光照时长和10 cm地温;15 cm地温、10 cm地温和5 cm地温;最小湿度、平均相对湿度和降水量。
1.4.3组合方法 由于在是否发生冻害和能否正常越冬时间段内的气象因子与时间间隔的正相关性因子远多于负相关因子,故对这两时间段的预测结果使用“合奏”的方式,对预测结果进行算术平均,将算术平均后的结果进行取整。常用的方法有截取整数部分、向上取整、向下取整和四舍五入取整。通过实验验证发现,通过向上取整后其结果更能拟合真实值结果。
最终结果=
(8)
1.5 模型实现
使用Python 3.5编程语言,在Jupyter notebook中运行相应代码。
数据处理库numpy、pandas,数据可视化库seaborn、matplotlib,日期时间处理库datetime,机器学习库sklearn和数学函数库math。
2 结果与分析
2.1 苹果果树的气温需求分析
根据临汾市气象局发布的农用天气预报可知,冬季当地果树处于休眠期的平均气温要求在-10~7 ℃之间,当平均气温低于-15 ℃时易发生冻害。以每年12月1日至次年3月1日为是否发生冻害的时间段,分析1987—2017年的日平均气温(图1)发现,吉县苹果树在该时段内的气温在-4.52~-0.54 ℃之间,满足吉县苹果树休眠期的气温需求(-10~7 ℃),且日平均温度的平均值为-2.65 ℃。这就说明对于吉县当地苹果树休眠期的气温需求可以放缩至-4.52~-0.54 ℃的范围内。
2.2 苹果果树需冷量
落叶果树自然休眠所需的有效低温时数称为果树的需冷量,又称为低温需求量或需冷积温[17]。
以每年11月1日至次年3月15日为能否正常越冬时间段。分析1987至2017年日平均温度≤7.2 ℃的天数和日最高温度≤7.2 ℃的天数,如图1所示。可以发现,在该时期内日平均气温符合≤7.2 ℃的天数占比在88%以上,而日最高温度≤7.2 ℃的天数占比平均保持在55.62%。这就说明在该时间段内,日平均温度<7.2 ℃占比高于88%时,吉县苹果树能够顺利完成安全越冬。

图1 前期气温分析Fig.1 Preliminary temperature analysis
2.3 苹果树需热量和水分分析
需热量是指从内休眠结束至盛花所需的有效热量累积,又称热量单位累积量或需热积温[18]。当需冷量满足后,需热量则在一定程度上影响着果树花芽的正常萌发以及花期的早晚。引入降水量与湿度,用于分析水分对苹果树花期的影响。以每年3月上中旬(3月1日至3月21日)为热量与水分需求时间段。对2010—2017年该时间段的降水量、日最高温度、日最小湿度、光照时长和5 cm地温与时间间隔进行分析,结果如图2所示。可以看出,3月1日至21日部分气象数据与时间间隔的比较所示,2012年与2011年相比,当降水量和日最小湿度升高,日最高温度、光照时长和5 cm地温降低时,时间间隔降低;2013年与2012年相比,当降水量和日最小湿度降低,日最高温度、光照时长和5 cm地温升高时,时间间隔降低。说明在该时间段内,苹果树对于水分的需求与对热量的需求是相对反向的。同时也很好的说明了影响时间间隔的气象因子是多个的、复杂的。与单因子预测建模相比,使用多因子的预测建模能够更好的表征气象因子对植物生长的影响。

图2 3月1日至21日部分气象数据与时间间隔比较Fig.2 Comparison of selected meteorological data with time intervals from 1st to 21st March
2.4 苹果始花期花期预报结果分析
2.4.1相关性分析 所有特征对结果的贡献不一样的[19],使用相关性分析用于对数据进行降维和特征选择。分别对是否发生冻害(12月1日至次年3月1日)、能否正常越冬(11月1日至次年3月15日)和热量与水分需求(3月1日至3月21日)三个时间段内标准化后的气象数据(2010至2017年)与时间间隔进行相关性分析,结果如表1所示。
从表1 可以看出,在是否发生冻害时间段,温度、降水量、地温、湿度和光照时长与时间间隔都是正相关的,影响苹果树开花的主要因素是10、15 cm地温和光照时长,其与时间间隔的相关性都大于等于0.5;在能否正常越冬时期,15 cm地温是与时间间隔正相关性最大的因子,在该时期内比起对温度的关注更应该考虑地温;在热量与水分需求时期,只有湿度与苹果树开花量正相关,且日最小湿度为主要影响因子,这说明在3月中上旬,水分对苹果始花期的影响作用显著。
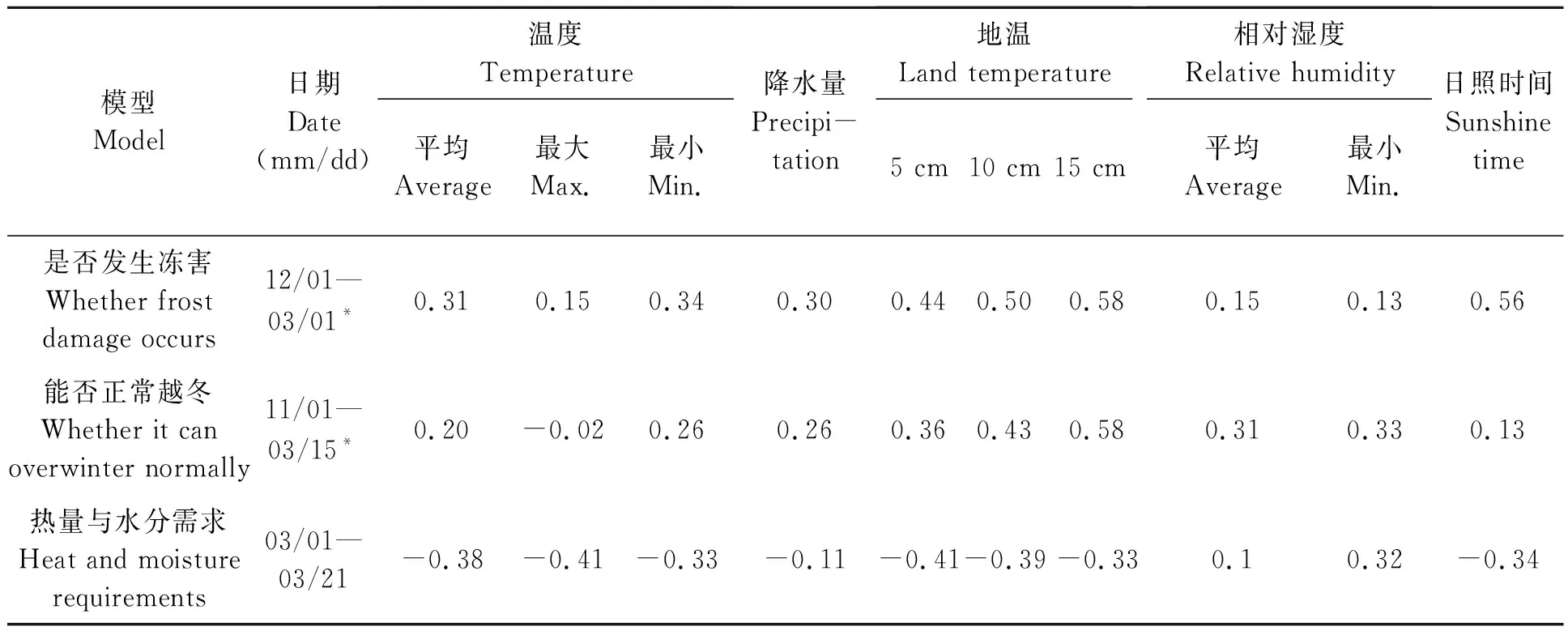
表1 日气象因子与时间间隔的相关性Table 1 Correlation between daily meteorological factors and time interval
2.4.2模型性能分析 通过对模型进行训练得到权重W与截距b如表2所示。

表2 模型结果Table 2 Model results
从表3预测模型检验可以看出,是否发生冻害、能否正常越冬和热量与水分需求三个时间段的决定系数分别为0.59、0.71和0.48,而通过组合方法的决定系数为0.78,这说明组合方法有近80%的对因变量的可解释性,而能否正常越冬模型只有71%。当决定系数在0.7以上时,使用组合方法的均方误差和平均绝对误差值明显低于能否正常越冬模型。均方根误差(RMSE)实质与均方误差一样,只是将误差的结果和数据同级化。四个算法模型的误差分别为2.11、1.78、2.37和1.54 d。

表3 模型性能指标Table 3 Test of predictive models
通过热量与水分需求模型预测结果和是否发生冻害模型、能否正常越冬模型预测结果相比。是否发生冻害与能否正常越冬时间段的预测误差相对较低,数据之间正相关的因子远大于负相关因子,且决定系数都高于50%。这是因为在研究过程中三个时间段的时间跨度不同。其分析天数分别为21 d(热量与水分需求时间段)、90~91 d(是否发生冻害时间段)和135~136 d(能否正常越冬时间段),这就造成不同时间段内的气象因子与时间间隔的相关性不同,以致于影响评价指标。通过研究分析可以得出,在进行花期预测过程中气象因子的时间跨度选取不宜过小,且只有正相关因子才能提高预测的准确性。
从图3可以看出,使用组合方法获得的模型预测值与真实值在2011、2012、2013和2017年重合,在2010、2015、2016年保持1 d的误差。是否发生冻害模型预测结果只有在2015年及以后误差较小,而在2015年之前平均误差2 d。能否正常越冬模型模型预测值与真实值的误差1~3 d,没有重合点,且大部分年份误差为1 d。热量与水分需求模型其预测值与真实值的平均误差为2 d。综上,结合衡量指标可以看出,能否正常越冬模型与组合方法模型是相对较好的两个模型,而热量与水分需求模型波动较大,不适合用于预测。
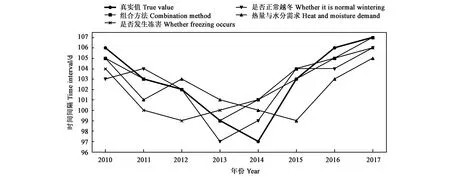
图3 不同模型预测结果Fig.3 Different model prediction results
2.4.3花期预测结果 以2017年作为独立样本,将气象因子带入各预测模型中。对2017年苹果始花期花期进行试报,结果如表4花期预测值所示。不同模型的误差天数在1~2 d之间,花期预测模型拟合效果较好。

表4 花期预测值Table 4 Flowering forecast values
组合方法模型的决定系数高于能否正常越冬模型和是否发生冻害模型,但其在试报过程中误差相同,这是因为得到的所有预测结果全部都是小数。而对于预测的结果,时间间隔要求是以天为单位的,这就需要对小数进行取整。在取整过程中对预测结果是采用向上取整、向下取整、四舍五入还是直接提取整数,具体哪种取整方式提出了要求,在此过程中便会降低预测的准确性。
3 讨论
本研究划分三个时间段,针对休眠期内苹果果树的关键时间节点气象因子对始花期的影响进行分析,分析天数分别为21 d(热量与水分需求时间段)、90~91 d(是否发生冻害时间段)和135~136 d(能否正常越冬时间段)。由于分析天数的不同造成了不同时间段内的气象因子与时间间隔的相关性不同,影响了评价指标和模型准确性。对于三个不同时间段的分析可以看出,在预测过程中的分析天数不宜过短,这与丁锡强等[20]的研究结果相一致。对于分析天数的选取是否需要扩大,多久的分析天数才能更好的预测始花期这需要进一步的研究。
多元线性回归中,权重w直观表达了各属性在预测中的重要性,因此线性模型有很好的可解释性[21]。每个数据的价值不一样,选择十个气象因子中的三个气象因子作为特征向量参与建模,这是因为通过对是否发生冻害、能否正常越冬和热量与水分需求的三个时间段的训练集数据进行主成分分析后,发现三个特征向量分别可以表征88.65%、97.26%和91.60%的气象因子信息,即30%的特征向量表征了88%以上的信息。
组合方法思想认为好的模型并不一定是从多种模型中选择一个模型,而是可以把多个模型进行组合以得到更好的模型,包括“堆叠”和“合奏”两种思想。“堆叠”就是用前一个预测方法得到的预测值,为后一个预测方法得到的预测误差进行修正。“合奏”就是同时应用多个不同的预测方法得出多个预测值,并对这些预测值以某种方法进行平均,得到最终的预测值。采用的思想进行建模,是因为“合奏”的思想可以给出较高预测精确度的预测值,且模型简单、泛化能力好。
预测模型以70%以上的拟合程度,实现在3月15日的精准预报。所用数据集中始花期最早出现日期为4月8日,以3月15日进行预测可以提前24 d完成预测。这与尹贞钤等[22]的7~15 d提前预测相比,在保证预测准确性的前提下预测的提前量有了很大的提升。同时,由于预测的时间间隔是以天为单位的,在模型预测过程中不可避免使用到小数取整的过程这对预测的准确性提出了新的挑战。
猜你喜欢
农技服务(2022年5期)2022-06-01
今日农业(2021年15期)2021-10-14
今日农业(2020年13期)2020-08-24
小学生学习指导(低年级)(2019年3期)2019-04-22
意林(2017年8期)2017-05-02
新东方英语(2016年11期)2016-11-11
传奇故事(破茧成蝶)(2015年8期)2015-02-28
火花(2015年7期)2015-02-27
读写算·小学低年级(2014年4期)2014-07-24
滇池(2014年5期)2014-05-29
