
基于改进BP神经网络的交通标志识别
2020-04-21 17:33李平安
攀枝花学院学报 2020年2期
罗 山,李平安
(攀枝花学院 交通与汽车工程学院,四川攀枝花617000)
0 引言
先进的交通标志识别技术是实现辅助驾驶和无人驾驶的关键技术之一;可以辅助司机判断周围道路状况,减轻负担,显著提高驾驶的安全性和舒适性。国内外学者对交通标志识别做了很多研究,李翔等[1]提出了基于Hu不变矩的识别方法,但Hu不变矩含有大量的冗余信息;魏艳艳提出一种基于幅值谱和神经网络的交通标志识别算法[2],较好解决了所获取的标志图像与实际交通标志图像之间的几何失真问题,提高了识别率;田秋红[3]等提出了基于Zernike矩特征的识别方法,Zernike矩只能提取图像的全局特征,无法描述图像;杨斐提出了分块图象特征与BP神经网络相结合的识别方法,但只对33幅图像进行处理[4],该方法鲁棒性较差。
针对目前交通标志识别方法存在的不足,本文提出一种改进的交通标志识别算法。采用颜色概率与局部模板进行交通标志检测,去除部分冗余信息,并且能够识别各种形状的交通标志;利用融合改进的MDA和MPCA进行特征值提取,能够解决投影矩阵的求解问题;加入L2正则化和dropout结构改进BP神经网络。同时,选用德国交通标志库作为训练和识别对象,样本容量大,更具有代表性;并对实际场景中的交通标志进行测试,验证算法的有效性。
1 交通标志识别流程
具体识别流程见图1所示。
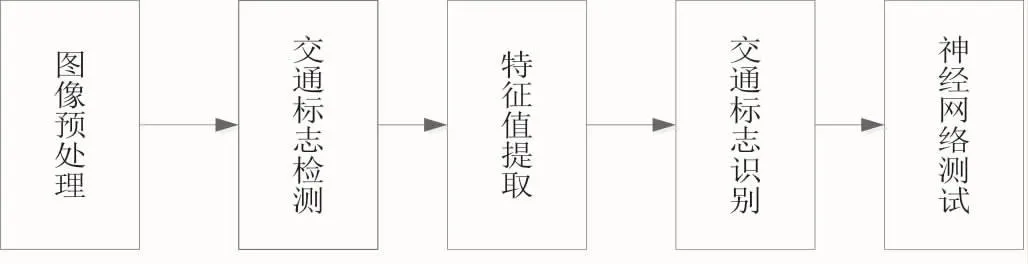
图1 交通标志识别流程
2 交通标志检测
2.1 交通标志颜色概率模型
为减少亮度的影响,在RGB颜色模型中,采用式(1)对颜色坐标进行归一化处理[5]。

在交通标志己知的条件下,该像素点出现的概率 p(r,g|sign)服从二维高斯分布,即 p(r,g|sign)~N(μ1,μ2),根据 Bayes规则,对于对于图像上的任意一点(r(i,j),g(i,j)),可能的交通标志的后验概率为:

式中,p(sign)—某点是交通标志的概率,p(r,g)—某点是(r,g)颜色的概率。
通过对颜色概率的建模,得到二值化图像,但是需要将二值化图像的所有区域进行分割,以此来判断是否为交通标志区域。
2.2 局部模板形成机制
在对检测到的图像进行边缘检测和形态学处理之后,还需要对边缘选取的影像进行确认,在确认时,以目标图像作为模板与原图像的各个子区域图像做比较,当目标和模板的相似性达到某一程度时,认为该子区域上的图像与模板匹配,即该一子区域含有目标。
2.3 基于颜色概率和局部模板的交通标志检测
基于融合颜色概率模型和局部模板的交通标志检测算法主要有三个步骤:
(1)通过颜色概率模型对可能是交通标志的像素进行提取,除掉不属于交通标志类别的颜色特征;(2)采用局部模板对交通标志进一步确认;
(3)在原始尺度下进行三次连续的重采用以减少匹配过程耗时。其原理大致如下:先在分辨率最低的图像中进行一次粗匹配,根据相似程度去除明显不是交通标志的目标,同时,也就获得了可能的交通标志目标,在这个基础上,对该可能的交通标志目标再进行三次连续的匹配,便可以得到所需要的交通标志目标[5]。
3 融合改进MPCA、MDA的交通标志特征值提取
融合改进的MPCA、MDA的特征提取原理是在原张量数据空间的n-mode中找到一组正交矢量,要求这组矢量能最大化的表示原张量在n-mode下的平均平方方差,然后将张量从原张量空间投影到新的张量空间得到新的张量,再在新形成的张量数据空间的n-mode中找到一组Qn个正交矢量,要求这组矢量能最大化的表示新的张量在n-mode下的类间平均平方方差,最小化的表示原张量在n-mode下的类内平均平方方差,则投影新张量就是构成原张量的目标特征张量,且完成了数据的冗余度去除[6]。特征提取算法主要有两步:
(1)训练图像数据,构建交通标志的特征张量子空间;
(2)将训练图像投影到特征张量子空间上形成特征张量。
4 交通标志识别
4.1 BP神经网络的改进
针对BP神经网络在训练过程中出现的“过拟合”现象,对神经网络进行L2正则化和添加dropout结构的方式进行优化,L2正则化指的是权值向量w中各个元素的平方和然后再求平方根,神经网络在拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。而dropout结构让一半的隐含层节点值为0,整个dropout过程就相当于对很多个不同的神经网络取平均。这种方式减少了特征检测器(隐含层节点)间的相互作用,在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强。
4.2 改进的BP神经网络设计
交通标志图像归一化为大小48×48,因此输入层节点数为2304;单隐含层的节点数为100,双隐含层的节点数分别为500和100,隐含层激活函数选择Sigmoid函数;输出层节点数为43;初始权值为[-1,1]内的随机数,迭代次数为200,学习率1,L2正则化系数1e-4,dropout系数0.5;单次放入迭代图片数100,训练集标签数43,测试集标签数43。
4.3 基于改进BP神经网络的交通标志识别及分析
本文选用德国GTSRB数据集[7],数据集包含的43类交通标志是在不同天气条件、不同的光强度、不同的遮挡水平和不同的分辨率下采集所得,其中有39209个训练样本和12630个测试样本,样本图像包含标记区域和10%的周围区域。
各状态下的期望输出与实际输出如图2、3、4、5所示(其中,红色表示期望输出,蓝色表示实际输出):
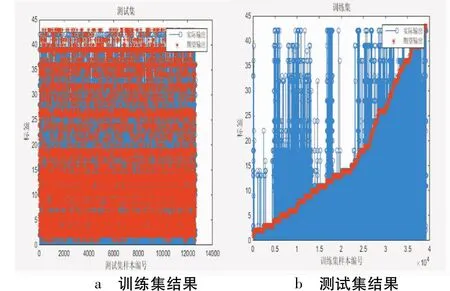
图2 直接训练
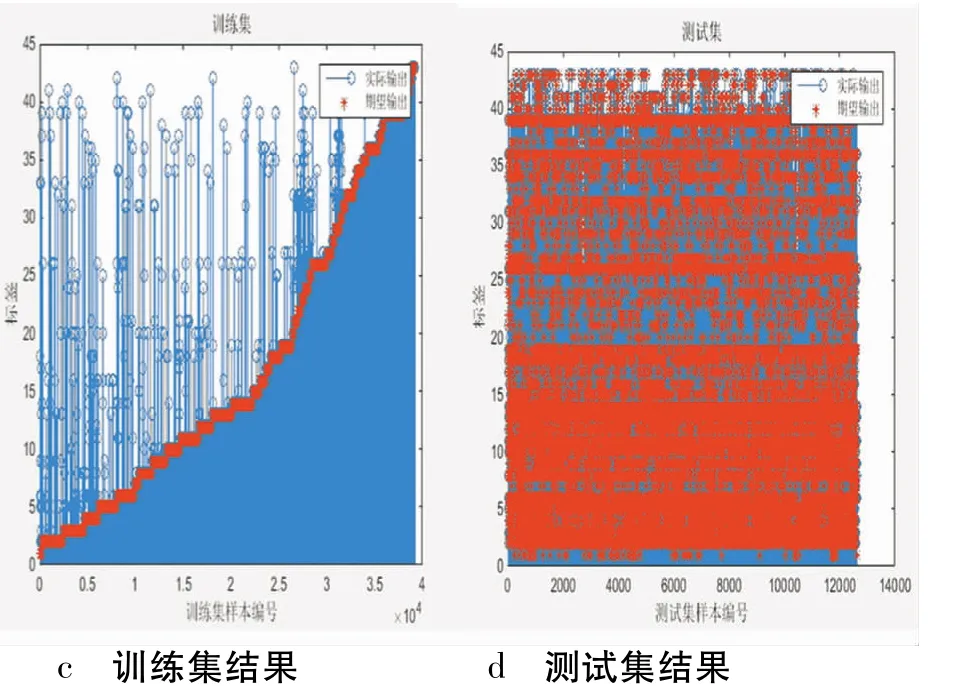
图3 增加dropout结构训练

图4 增加L2正则化训练
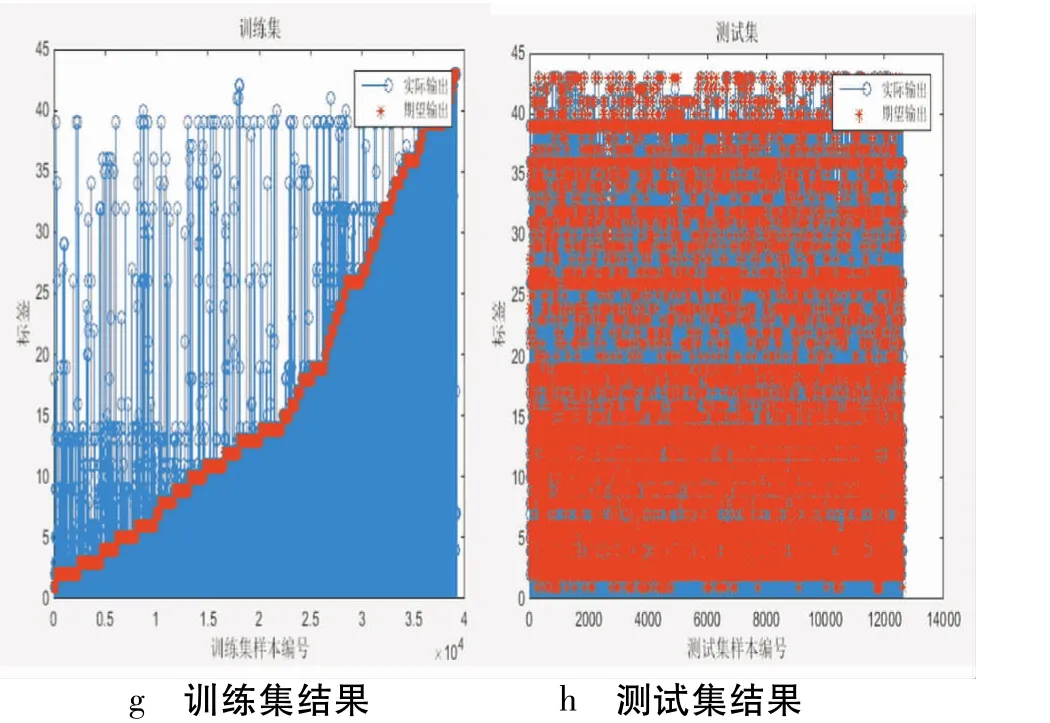
图5 增加L2和dropout训练
神经网络改进前后交通标志识别结果如表1所示。

表1 交通标志识别结果对比
从表1可知,加入L2正则化或dropout的BP神经网络对交通标志训练、分类和识别均有良好效果,识别率有较大提高;而同时加入L2正则化和dropout结构后的神经网络性能更好,识别率进一步提高,其实际输出和预期输出更为贴近,无过多“过拟合”标签数,实现了交通标志的分类识别。而且,改进的神经网络不受交通标志形状影响,只要该类型的交通标志在GTSRB数据集中均能实现识别。
4.4 改进网络的测试
为了检验改进的BP神经网络能否在一定程度上满足实际的需要,需要对网络进行测试,在测试时,用两种方式测试:
①选取交通标志库中的4张图片如图6,将其大小设置为48×48进行网络测试,测试结果见图7。

图6 用于网络测试的图片

图7 测试结果
将测试结果与前述用于神经网络训练的训练集内相应类数对比,说明交通标志识别准确。
②将自然场景下获取的4幅交通标志图如图8,进行预处理、分割定位并将其大小设置为48×48进行网络测试,测试结果见图9。

图8 自然场景下的4幅交通标志图

图9 测试结果
前述用于神经网络训练的训练集内第7类为限速80 km/h标志、第33类为禁止驶入标志,从测试结果可知交通标志识别错误,其原因是该交通标志不属于交通标志数据集。而另外两类属于交通标志数据集,识别正确。
5 结束语
为减少BP神经网络“过拟合”现象,在网络中增加了L2正则化和dropout结构,通过在误差函数上加约束和忽略一半的特征检测器的方式使模型泛化性更强,训练效果得到进一步提高,识别效果好。另外,改进后的神经网络不需要人工分析交通标志形状、颜色,方法简单,鲁棒性好。
猜你喜欢
汽车实用技术(2022年9期)2022-05-20
科技信息·学术版(2022年8期)2022-02-25
华南师范大学学报(自然科学版)(2021年5期)2021-11-09
井冈山大学学报(自然科学版)(2021年4期)2021-10-13
华南师范大学学报(自然科学版)(2021年3期)2021-07-03
北华大学学报(自然科学版)(2020年6期)2021-01-05
南京大学学报(数学半年刊)(2020年1期)2020-03-19
上海师范大学学报·自然科学版(2018年3期)2018-05-14
北京航空航天大学学报(2017年6期)2017-11-23
小天使·一年级语数英综合(2016年8期)2016-05-14
