
基于遗传算法的改进K-means算法
2020-06-11 09:26林龙成
电子技术与软件工程 2020年1期
文/林龙成
(江苏省南通卫生高等职业技术学校 江苏省南通市 226010)
K-means算法[1][2][3]是一种广泛使用的聚类算法,思想简单易行,时间复杂度接近线性,对大数据集,具有高效性和可伸缩性。但是算法也有一些局限性,需事先给定聚类数k 值;对于初始值的选择比较敏感,选择不同的初始值,可能会导致不同的分类结果。
遗传算法[4][5]被广泛应用于提高人工智能技术的性能。结合遗传算法能够寻找全局最优解的优势,以及K-means 算法容易因为初始聚类中心的选择不同而陷入局部最优解的问题,本文利用遗传算法初始化K-means的初始聚类中心点,提出基于遗传算法的K-means聚类算法GA-K-means。
1 K-means聚类算法
K-means 算法,也被称为k-均值算法,是基于距离的聚类算法,采用距离作为相似性的评价指标,两个数据点的距离越近,则相似度越大。计算样本间的距离公式有欧氏距离、曼哈顿距离、余弦相似度等,其中最常用的是欧氏距离。
K-means 算法基本思想是通过迭代将数据集划分为不同的类簇,使得用不同类簇的均值来代表相应各类样本中心时所得的总体方差最小。误差平方和准则函数公式为:

E 表示样本空间中所有数据点到聚类中的平方误差的总和。p表示数据对象,Ci表示第i 个类簇,mi表示第i 个类簇的平均值。
2 基于遗传算法的K-means算法
2.1 GA-K-means算法的具体流程
GA-K-means 是在K-means 聚类中利用遗传算法选择最优的初始种子。图1 为GA-K-means 聚类的总体框架。
首先,系统生成初始种群,用于寻找全局最优初始种子,遗传算法对当前种群进行选择、交叉和变异等遗传操作,不断更新种群,直到满足停止条件;然后根据输出的初始聚类中心,使用K-means算法进行聚类,输出聚类结果。
2.2 染色体编码
以学习风格为例,本文采用实数编码方式,能够直接反映问题的固有结构,便于设计专门的遗传算子,缓解“组合爆炸”的问题。染色体的结构如表1 所示,前4 位表示第一聚类中心的学习风格向量,依次类推。
2.3 适应度函数设计

表1:染色体编码

表2:10 次实验结果
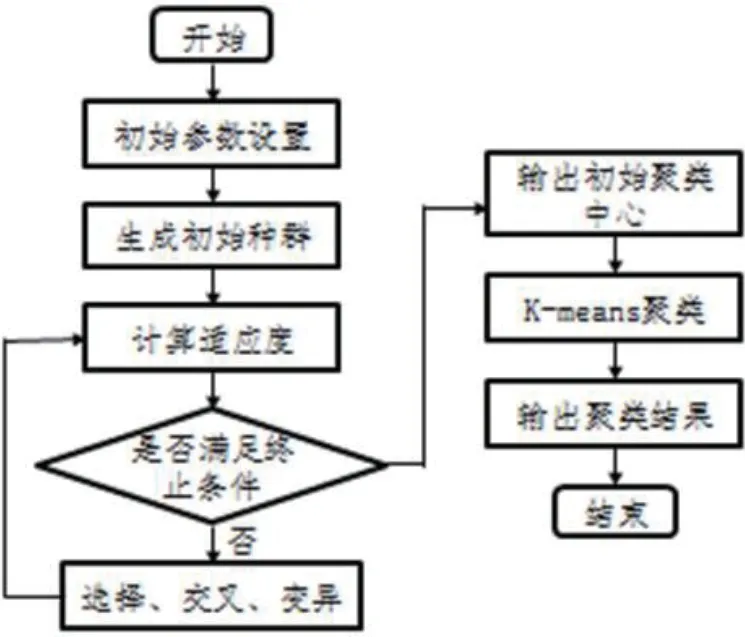
图1:GA-K-means 算法

图2:单点交叉

图3:变异操作
适应度函数是促使遗传算法收敛到最优解的一个因素。我们选择总最小距离函数作为染色体强度的适应度函数,以找到K-means算法的最优初始种子。适应度函数定义如下:

其中,Gi表示第i 个聚类,Lj 表示属于Gi的学习者,LSj表示第j 个学习者Lj的学习风格向量,gj表示Gj 的聚类中心。适应度函数Fit 越小,说明初始聚类中心的选择越好.
2.4 遗传算子

图4:两种算法的聚类结果
在遗传算法中,通过一些列算子来决定子代的生成,本文使用选择、交叉、变异算子,交叉算子通过双亲染色体交换有意义的遗传物质来产生两个新的后代,变异算子通过向种群中引入一个全新的成员来维持种群的遗传多样性。
2.4.1 选择算子
选择操作通过适应度选择优质个体,抛弃劣质个体,体现了“适者生存”的生物法则。常见的选择操作主要有:轮盘赌选择、排序选择、最优个体保存及随机联赛选择。本文采用轮盘赌选择方式,某染色体被选的概率Pc 为:

其中:f(xi)表示第i 个染色体的适应度值;∑f(xi)表示种群中所有染色体适应度值之和。
2.4.2 交叉算子
交叉是指两个染色体按照某种方式交换部分基因信息,从而产生两个新的染色体。常用的交叉方法有:单点交叉、双点交叉、均匀交叉及算术交叉。本文使用单点交叉,从其中可能的三个交叉点P1、P2、P3、P4中随机选择一个交叉点。交叉操作如图2 所示,其中P2 是所选交叉点。
2.4.3 变异算子
变异是指以一定概率随机改变染色体编码串中部分基因值,形成新的个体。常用的变异方法有:基本位变异、均匀变异、二元变异及高斯变异。本文采用基本位变异方法,从五种可能性(I 到V)中选择一个随机基因组(四位),并根据学习风格情境,使用相反选择答案得到的4 位编码串替换它。变异操作如图3 所示,IV 基因被反向基因组(7 8 10 6)替换。
2.5 K-means聚类
(1)以遗传算法得到的最优解作为初始聚类中心
(2)计算所有数据对象到这k 个初始聚类中心的距离,并将数据划归到离其最近的那个中心所在的类
(3)重新计算已经得到的各个簇的质心,作为新的聚类中心
(4)计算公式(1)中的准则函数E,若E 不满足,重复第2、3 步,直到聚类的中心不再移动,输出聚类结果
3 实证分析
为了检验本文提出的算法的有效性及对学生学习风格进行分析,本文使用MATLAB 进行仿真实验,实验环境的硬件配置为 Inter(R)Core(TM)i5-3470 CPU@3.20GHz 4.00GB,开发环境为 MATLAB R2016a。
下面采用传统K-means 和GA-K-means 分别对学习风格数据进行分类,验证本文提出的GA-K-means 算法的有效性。实验结果如图4 所示。
可以看出,传统K-means 算法虽然收敛速度快,但是容易陷入局部最优解,而本文提出的GA-K-means 算法则能够避免早熟现象,且收敛平稳,收敛效果明显优于传统K-means 算法。
为了进一步验证算法的有效性,对传统K-means 算法和本文提出的GA-K-means 算法分别进行10 次实验,实验结果如表2 所示。其中匹配度计算公式为:

从表2 可以看出,由于传统K-means 算法对初始聚类中心的选择比较敏感,导致每次聚类结果都有很大差异,10 次实验结果的匹配度较低,而本文提出的GA-K-means 算法匹配度较高,具有较好的稳定性。
4 结论
本文在传统K-means 算法的基础上,提出了基于遗传算法的GA-K-means 聚类算法。该方法弥补了K-means 在寻找全局最优解方面的不足,在稳定性和有效性方面都明显好于传统K-means 聚类算法。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
数学物理学报(2021年2期)2021-06-09
应用数学(2020年2期)2020-06-24
数学年刊A辑(中文版)(2018年2期)2019-01-08
数学物理学报(2016年3期)2016-12-01
小学生导刊(低年级)(2016年6期)2016-07-02
中国塑料(2016年11期)2016-04-16
计算机工程(2015年8期)2015-07-03
振动、测试与诊断(2014年6期)2014-03-01
教育与职业(2014年16期)2014-01-19
