
基于Mahout与协同过滤算法的中医调理文章推荐引擎
2020-06-11 09:26刘艳方田刘嘉慧戴彩艳王珍
电子技术与软件工程 2020年1期
文/刘艳 方田 刘嘉慧 戴彩艳 王珍
(南京中医药大学人工智能与信息技术学院 江苏省南京市 210023)
1 引言
随着信息的快速增长,每天都有多种多样的中医养生调理方案产生,过多的数据导致被动获取的信息过载,怎样快速地获取用户感兴趣且有用的信息呢?通过中医调理文章的推荐信息管理系统,可以有效的解决这个问题。其主要的任务之一就是通过联系更多的用户与推荐平台,解决推荐信息资源过载的问题,提升用户推荐的质量,提高用户的满意度。
本文利用基于用户的协同过滤推荐算法,分析智慧血压监测与健康管理APP中用户上传的资料和用户历史数据,挖掘用户相似度,引入属性相似度概念,实现了一个基于Mahout 的中医养生调理文章推荐系统,可以智能选取用户感兴趣的调理文章,每日推送相关的中医调理方法。
2 Mahout研究
Mahout 是Apache 软件基金会(全称Apache Software Foundation,也简称ASF)旗下的一个经典算法开源项目,集成了各式各样的聚类、推荐等算法,是一个很好用的经典算法工具集,可以更好地帮助我们去理解和学习这些算法,并在此基础上对它们加以系统性的研究和创造性的改进。在目前被广泛采用的机器智能学习数据分析技术中,Mahout 主要用于推荐引擎、聚类和分类。
Taste 是Mahout 基于Java 的一个推荐实现,Taste 不仅可以实现基本的基于用户的和基于内容的协同过滤算法,还可以实现比较高效的SlopOne 算法和基于SVD 和线性插值的推荐算法,同时也为个性化推荐算法的实现提供了一个可扩展接口,使得用户可以很方便的使用和设计完成自己的推荐算法,也较好的满足了企业对个性化推荐引擎在性能、灵活性等诸多方面的更高要求[2]。Mahout协同过滤算法的具体包含如图1 所示。
3 协同过滤算法研究

图1:Mahout 协同过滤算法图

图2:用户分析图(左)和“物品—用户”倒排表图(右)
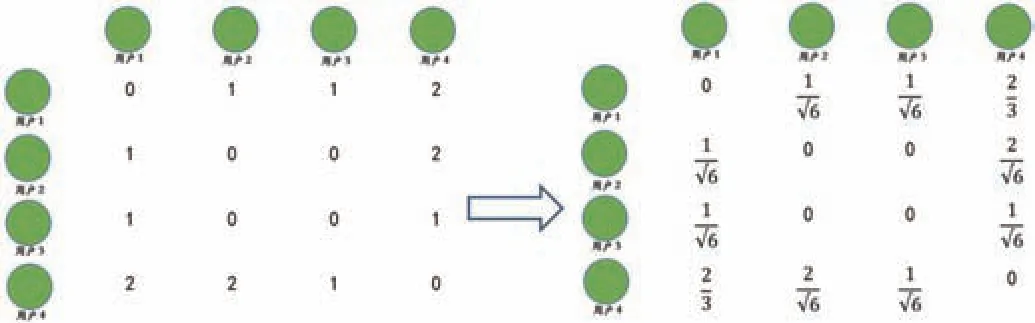
图3:用户矩阵图(左)和用户相似度矩阵计算图(右)
3.1 协同过滤算法
协同过滤推荐算法是较为著名且诞生最早的推荐算法,其主要的功能是推荐和预测。算法主要是通过利用对用户历史浏览记录和行为数据的统计与分析,进行挖掘发现每个用户的喜好,基于各式各样的喜好数据可以对每个用户进行协同划分,预测用户的喜好,然后对用户进行相应的喜好内容推荐。并且协同过滤最大的优点是对推荐的对象本身没有特殊的结构化要求,能够有效处理非结构化的复杂对象,如网络小说,音乐等。
协同过滤推荐算法主要分为两大类,一是基于用户的协同过滤算法,二是基于物品的协同过滤算法。这两种算法各有优势,根据智慧血压监测与健康管理APP 的实际情况,我们采用了基于用户的协同过滤算法。
3.2 基于用户的协同过滤算法
本算法是通过研究用户的历史行为数据,发现用户对文章的喜欢,比如文章收藏,内容评论或分享等,然后对这些喜欢的文章进行打星或打分。算法主要的流程是:首先,找到和目标用户喜好相似的用户推荐集合;然后,找到这个推荐集合中目标用户非常喜欢,且目标用户没有看过的文章推荐给目标用户。
假设有4 个用户购买了5 种不同图书,如图2 用户分析图所示。如何找到与目标用户喜好相似的用户呢?首先我们可以建立一张“物品—用户”的倒排表,如图2 的“物品—用户”倒排表图所示,可以清晰的看出每本书被哪些用户购买。
然后利用“物品—用户”的倒排表,构建用户相似矩阵,其中的值,表示用户和用户之间共同喜欢的图书的数量,如图3 中的用户矩阵图所示。而后,可以通过余弦相似度公式(1)计算用户与用户之间的相似度,对用户矩阵进行进一步的分析计算,如图3 中的用户相似度矩阵计算图所示。
余弦相似度:

由上述步骤,可以很清楚的帮助目标用户找到与其兴趣相似的用户集合。但是由于传统的协同过滤算法仅仅是依靠用户对项目的评分,用户浏览记录等信息,这样容易导致用户之间的相似度计算不准确。本文考虑将从用户评分、用户浏览等信息以外的用户基本资料中挖掘到的用户基本属性相似度(称属性相似度)结合到协同过滤算法中,形成一种融合相似度,更好的帮助智慧血压监测与健康管理APP 上的用户进行个性化推荐。
4 中医调理文章推荐算法设计
4.1 收集用户数据
在智慧血压监测与健康管理APP 上的用户个人信息数据包括注册用户ID、性别、年龄、文章编号ID、文章分数、舒张压、收缩压、呼吸频次、脉搏跳动次数、体温等相关数据。本文将浏览文章分数作为文章的偏好程度的衡量依据,根据用户ID,文章ID、文章分数这三种数据用于计算传统的相似度,由皮尔逊相关系数计算,其他数据用于计算属性相似度,增加相似度的准准确率。
4.2 计算相似度
4.2.1 皮尔逊(Pearson)相关系数
通过Pearson 相关系数计算传统相似度,与余弦相似度相比,皮尔逊相关系数的特点是将数值“中心化”,首先将每个向量的所有分量都减去分量均值,再求余弦相似度。皮尔逊相关系数的绝对值越大,即相关系数越是接近于1 或-1,相关性越强,相关系数越是接近于0,相关性越弱[4]。
皮尔逊相似度:

4.2.2 属性相似度
根据采集的用户个人资料中的年龄、性别、舒张压、收缩压、呼吸频次、脉搏跳动次数和体温等的统计数据,当用户与用户之间属性相同或属性值相近时,则增加一个单位,得到的总数除以属性总数,得到属性相似度。
4.2.3 融合相似度
设置一个alpha 值(小于1),作为行为相似度(即由皮尔逊相关系数计算的相似度)占的比例,则属性相似度占的比例则为1-alpha,计算公式为:
融合相似度=alpha×行为相似度+(1-alpha)×属性相似度
4.3 建立评估推荐器,实现推荐系统
首先如何让推荐器有一个好的结果,评估推荐器是一个很有必要的工具。评估推荐器的方法有多种,其中一种是评估它所可能产生的偏好指数与真实喜好程度的匹配程度,即预测准确度。

表1:部分推荐结果数据

图4:基于用户的协同过滤流程图
评估推荐器可以利用平均绝对误差(MAE)作为度量指标,来计算预测分数与真实分数之间的绝对变差的平均值。与平均误差相比,平均绝对误差不会出现正负相抵的情况,能更好的反应推荐性能的好坏[10]。平均绝对误差越小,则说明推荐系统的性能越好,推荐越准确。u:测试集中的用户,i:物品,rui:用户对物品的实际评分,推荐算法给出的预测评分,MAE 平均绝对误差具体公式如下:

而后,利用Mahout 里的Taste 组件来实现推荐系统,首先将数据加载到内存中,加载各个用户浏览文章的信息,连接数据库查询用户的属性和体质信息,计算相似度(皮尔逊相似度和属性相似度),而后计算固定大小的领域,构建基于用户的协同过滤推荐器,生成推荐引擎,最后输出推荐结果。基于用户的协同过滤流程如图4 所示。
4.4 推荐结果
本文所取的文章数据集是39 健康网中医文章导读搜集到的数据,系统运行后得到的推荐结果如表1 所示。
5 总结
在传统的基于用户的协同过滤算法上引入了属性相似度,增加了相似度的可靠性和准确度,提高了推荐性能。利用评估推荐器计算平均绝对误差评测,来衡量推荐器的好坏,使推荐器性能有一定的保障。在智慧血压监测与健康管理APP 上构建基于Mahout 的推荐器,不仅对开发来说更方便,也给用户推荐物品时带来便捷,给智慧血压监测与健康管理APP 带来流量。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
今日农业(2021年19期)2021-11-27
基层中医药(2021年5期)2021-07-31
疯狂英语·初中天地(2021年11期)2021-02-16
初中生世界(2020年43期)2020-12-18
初中生世界·九年级(2020年11期)2020-12-02
今日农业(2020年13期)2020-08-24
少年漫画(艺术创想)(2019年2期)2019-06-06
今日农业(2019年16期)2019-01-03
科学与财富(2018年16期)2018-08-10
