
基于最长频繁序列挖掘的恶意代码检测
2020-07-10 01:12黄琨茗
四川大学学报(自然科学版) 2020年4期
黄琨茗, 张 磊, 赵 奎, 刘 亮
(四川大学网络空间安全学院, 成都 610065)
1 引 言
恶意代码包括病毒、蠕虫、木马、后门、Rootkit、流氓软件以及广告软件等. 目前恶意代码的检测主要分为基于可移植执行文件及其反汇编文件的静态检测和基于恶意代码运行过程的行为特征的动态检测.
静态检测方法[1]的特征主要包括可移植执行文件及其反汇编文件的字节码、汇编指令、导入函数和分节信息等. 该方法对使用了代码混淆技术[2]的已知恶意代码和未知的恶意代码作用有限.
为克服基于静态检测方法的不足,研究者们提出基于行为的方法,相对于特征码,程序的行为更加固定. 恶意代码往往通过执行关键API调用函数实现恶意行为,系统API调用序列可作为恶意代码检测方法的最有效特征之一,API调用序列特征被研究者广泛使用. 2013年Ahmadi 等人[3]使用迭代模式的挖掘方法来挖掘频繁序列,他们认为恶意软件编写者调用重复性的API,特别是循环加密或解密和感染. 2014年Cho等人[4]应用序列队的方法检测变种恶意代码,该方法能够发现恶意软件API调用序列中的相同部分并检测出相似行为. 2015年Ki等人[5]使用DNA序列抽象出恶意软件的API调用序列模式,得出相同的恶意代码功能可以包含在不同的类别中,Pirscoveanu等人[6]用取前两百个不重复API函数,API函数的频繁度等作为特征,用于恶意代码分类. 2016年,Kolosnjaji等人[7]提取动态API序列的kernel系统调用序列,使用N-Gram和CNN提取序列特征输入到LSTM网络中进行恶意代码检测. 2018年,荣俸萍等人[8]使用模式挖掘算法得到API调用序列并结合随机森林模型来识别恶意代码,该方法使用改进的沙箱模型能有效检测逃避性样本. 以上基于API序列的恶意代码检测都没有考虑不同类别恶意代码的行为差异,而把所有恶意代码集中到一起进行特征挖掘,不能充分挖掘能代表恶意行为的序列模式,以至于不能有效的检测恶意代码.
基于恶意代码的行为依赖图[9-10]需通过动态污点分析的方法获取,该方法需要人工操作,速度慢效率低,还可能造成污点爆炸等问题. N-Gram方法[11-13]被广泛用于API序列的特征提取,N-Gram提取的子序列维度很大. 其中,文献[14]采用冗余子序列去除法处理子序列维度很大的问题,使用信息增益筛选N-Gram序列,输入到LSTM网络模型中进行分类,其API序列特征可解释性差,恶意样本在API序列中插入不相关API来逃避检测,会导致N-Gram失效.
为了改进以上基于恶意代码行为的动态检测技术的不足,本文选择挖掘不同种类恶意代码的最长频繁序列以表征恶意代码的恶意行为,提出了一种基于多种类恶意代码的最长频繁序列集合的恶意代码检测方法. 对于样本文件在沙箱中动态运行产生的系统API调用序列,使用改进的序列挖掘算法挖掘出同一类型的恶意代码的最长频繁序列,并将挖掘的多种类的最长频繁API序列集合合并,构造词袋模型,基于该词袋模型使用向量表征样本文件的动态API序列,构造随机森林分类器用于恶意代码的检测. 本文的主要贡献如下.
1) 采用了挖掘不同种类恶意代码的最长频繁序列的策略:不同种类的公共恶意行为往往有所区别,勒索软件会进行大量的注册表读写和文件读写操作,蠕虫病毒有大量自我复制和网络行为,特洛伊木马监听键盘记录和窃取账号密码等,挖掘不同种类的最长频繁序列集合能代表不同恶意行为模式.
2) 提出了新的最长频繁序列挖掘算法:本文提出的最长频繁序列挖掘算法在引入面向目标的关联挖掘技术的基础上进行了去重、剪枝的过程,保留关键API序列用于挖掘,大大减小了挖掘的时间复杂度,在运行过程中基于深度优先策略,通过判断候选项是否属于可扩展项,边挖掘边剪枝,进一步减小了挖掘过程中的时间和空间消耗.
3) 提出了一种基于最长频繁序列集合表示样本文件的方法:样本的动态API序列可以看作具有时间序列的一维文本,单个最长频繁序列可以看成能表征文本类别的一个特征.本文使用挖掘的最长频繁序列集合构造词袋模型,基于此模型把样本文件动态API序列转化为特征向量,特征向量能有效的包含样本文件的恶意行为.
2 最长频繁序列挖掘与恶意代码检测
2.1 方法概述
本文提出的恶意代码检测方法主要检测Windows系统的恶意可执行文件PE(Portable Executable)文件,采用本文提出的序列挖掘算法挖掘出各个类别的最长频繁序列,使用最长频繁序列集合构造词袋模型,把样本文件由向量表示,使用随机森林构造分类器进行恶意代码检测. 如图1方法实现流程图分为两个阶段,即特征挖掘和恶意代码检测阶段.
1) 特征挖掘阶段:首先提取样本文件的动态API调用序列,对动态API进行预剪枝;其次,基于同一类别的恶意代码挖掘出对恶意代码和正常样本有区分作用的最长频繁API序列;然后,合并挖掘出的不同类别恶意代码最长API序列集合,构造词袋模型;最后,根据词袋模型将样本文件的动态API转化为向量.
2) 恶意代码检测阶段:首先使用训练样本构造分类器;然后提取测试样本的动态API调用序列,进行简单的去重处理;最后把去重的样本文件的API序列转化为向量,用训练的分类器模型进行恶意代码检测.

图1 方法实现流程图Fig.1 Flow chart of the method
2.2 动态API提取及预剪枝
本文使用系统API调用序列表征恶意代码的行为,基于Cuckoo Sandbox搭建恶意代码动态分析系统,为了更好地模拟正常用户的环境,在客户机上安装一些常用的应用软件,并留下使用记录. 该分析系统通过Hook技术提取恶意代码运行过程的API调用,形成样本报告,实现了API序列的批量自动提取.
2.2.1 动态API预剪枝 由于恶意软件的动态API序列往往比较长,而恶意代码要完成恶意行为必须执行关键的API函数,过多的非关键API函数在模式挖掘过程中会产生大量冗余且无益的序列,这些会大大增加特征挖掘过程的时间消耗.所以,需要删除动态API序列中的非关键的API函数,对不同类别的动态API集合序列进行预剪枝,预剪枝分为动态API去重和关键API函数筛选.
2.2.2 动态API去重 序列模式中存在同一种API序列模式被频繁调用,存在信息冗余. 为了减少挖掘过程中的复杂度,并且要保证保留的信息不减少,本文采用了连续API序列模式去除方法[13],即只保留连续重复出现的API子序列中的单个子序列,如表1展示了API序列去重前后的API序列.

表1 API序列去重
2.2.3 关键API函数筛选
定义1 设f={s1,s2,…,sn}是同一个类别去重后的恶意代码样本动态API序列集,h={h1,h2,…,hm}是正常样本去重后的动态API序列集. 令ak表示该类别动态API序列中的API调用序列第k个API调用;freq(ak,f)表示ak在恶意代码类别f中的加权频率;freq(ak,h)表示ak在h中的加权频率. 它们的相关度的计算公式如下.
(1)
(2)
式(1)中,SN(ak,f)表示包含ak且属于类别f的样本数量;SN(f)表示类别f中的样本总数量;AN(ak,f)表示ak在恶意类别f的样本集中的动态API序列中出现的次数;AN(f)表示恶意类别f的样本文件API调用序列中API调用的总次数. 式(2)中,SN(ak,h)表示样本集h中包含ak的样本数量;SN(h)表示h中的样本总数量;AN(ak,h)表示ak在h的样本集中的动态API序列中出现的次数;AN(h)表示h的样本文件API调用序列中API调用的总次数. 本文当freq(ak,h)>freq(ak,f)时,可对恶意代码类别集合中所有样本进行合理剪枝.
2.3 最长频繁序列集合挖掘
恶意序列模式挖掘的主要目的是挖掘出对恶意样本和正常样本文件有区分能力的最长恶意API调用序列模式. 本文基于Freespan算法思想[14],采取树深度优先策略,提出了基于有限API序列集挖掘出最长频繁API子序列的算法.
2.3.1 最长频繁API序列模式挖掘相关概念的定义 我们先给出最长频繁子序列挖掘算法的相关概念定义如下.
定义2 支持度. 一个序列S在序列集T中的支持度等于该序列集中包含序列S的个数,即该序列的频繁度,记SupT(Sa)是数据集T中所包含的Sa序列的个数,其中S∈T,Sa=sub(S).
定义3 最大不支持度Supnon:一个序列S在序列集T中的支持度等于该序列集中不包含序列S的最小个数.
定义4 频繁序列. 对于子序列Sa,如果其在序列集T中支持度大于或等于设定的最小支持度阈值Supmin,即SupT(Sa)Supmin,那么称Sa为序列集T的频繁序列.
定义5 最长频繁序列. 设Sa是频繁序列,如果不存在频繁序列Sb是Sa的超集,则Sa被称为最长频繁序列.
定义6 候选扩展项. 如果一个频繁序列的最后一项为X2,如果频繁一项集序列S1=[X1,X2,X7,…,X59],则候选可扩展项序列为S1,其中序列的每一项均是候选可扩展项.
定义7 可扩展项. 设序列s为频繁序列,如果s最后面扩展一项后支持度依然大于或等于Supmin,即扩展后得到的序列还是频繁序列,该项被称为s的可扩展项.
定义7给出了扩展项的概念,可知频繁API序列顺序添加单个候选扩展API后得到的新API序列还是频繁API序列,则该API项是原API序列的可扩展API项. 根据最长频繁子序列的定义可知:如果频繁API序列没有扩展项且其不是其他最长频繁API序列的子集,则序列s为最长频繁API子序列. 表2频繁1项API序列的可扩展项所示,展示API序列集中频繁1-项API序列集的候选可扩展项及其可扩展项,例如API4可扩展项集合有{API2,API5},表中没有可扩展项的记为“∅”.

表2 频繁1项API序列的可扩展项
2.3.2 最长频繁API序列挖掘算法 本文设计了一种最长API频繁子序列挖掘算法,利用Redis队列结构边挖掘边过滤,算法分两部分.
第一部分为最长频繁序列挖掘部分,即把产生的最长频繁序列加入到Redis队列头部,本文采用字典来记录i-项频繁API序列的可扩展项信息,字典名为extend_address,以"API2":{s_1:address},{s_2:address},…,
{s_i:address},…,"APIn":{s_1:address},{s_2:address},…,{s_i:address}}的形式存储其信息,s_i与address分别指包含该可扩展项的动态AP序列和其在对应动态API序列中的位置信息. 例如{1:{s_1:1,s_2:1,s_3:2,s_5:7},2:{ s_2:2,s_3:4,s_5:9}},其中的可扩展项在动态API序列编号为1,2,可扩展项1分别在s_1、s_2、s_3和s_5动态序列的1、1、2和7位置,可扩展项2分别在s_2、s_3和s_5动态序列的2、4、9位置. 挖掘算法采用深度优先搜索的策略来遍历序列模式的搜索空间.
搜索过程如下:首先搜索所有1-项频繁API子序列集并将其作为候选可扩展项,然后以1-项频繁API子序列作为第一层树节点,最左边第一个树节点添加候选可扩展项作为后缀搜索2-项频繁API子序列,把没有扩展项的最长频繁API序列存到数据库队列头部,把搜索得到的频繁二项序列作为第二层树节点,同理从第二层最左边节点继续搜索频繁三项序列,最后递归搜索直到搜索的所有i-项频繁API子序列的扩展项都为“∅”时停止搜索.
最长频繁API序列挖掘算法的伪代码如算法1.
算法1 最长API频繁序列挖掘算法
输入类别f={S1,S2,…,Sn},关键API序列important_api=[api1,api2, …,apin],初始第一层节点init_seq,最小支持度Supmin和最小不支持度Supnon
输出Redis数据库存储最长频繁API序列集f′=[s1,s2,…,sk]
1) one_item_frequent=[] # 全局变量
2) function main() # 此为程序入口函数
3) extend_address = find_one_seq()
4) recusive_seq(init_seq, extend_address)
5) functionfind_one_seq () # 获取频繁一项集在动态API序列位置
6) for api in important_api:
7) forSiinf:
8) extend_address={Si:位置} # 记录api在Si首次出现的位置
9) if the number of Si contains api>supmin:
10) one_item_frequent. append(api) # 包含api的序列个数大于支持度
11) return exend_address
12) function recusive _seq(init_seq, extend_address): # 递归得到所有的最长频繁序列
13) can_extension=find_extension_seq(seq, extend_address)
14) if can_extension is not null:
15) for eachseq in can_extension: #递归获得最长频繁序列
16) can_extension=find_extension_seq(seq, extend_address)
17) else :
18) Redis. lpush(f′, seq)
19) functionfind_extension_seq (extend_address) #得到序列的可扩展一项集
20) for item in one_item_frequent:
21) for Si in extend_address:
22) Item_extend_address={Si:位置} # 记录在动态API的位置
23) If (++non_sup) > Supnon
24) Break # 候选可扩展项的不支持度大于Supnon,结束循环
25) extend_address={item : 可扩展项的位置 }
26) return extend_address
本文提出了最大不支持度概念(在挖掘算法第23~24行),当不支持度大于最大不支持度时,提前结束本轮循环,在最小支持度较大,最大不支持度较小时,比如本文最小支持度为94,最大不支持度为6,能显著减少计算量.
第二部分对搜索过程中产生的最长频繁API序列进行过滤,由于本挖掘算法采用深度优先策略,挖掘过程中会产生大量较短的子序列. 本文从Redis数据库的队尾依次取出最长频繁序列进行过滤,过滤队列为f’,过滤策略如下.
(1) 超集检测:对一个最长频繁序列s,通过查找其在f′中是否存在一个最长频繁API序列Sa,使得s⊆Sa,如果存在,则s不是最长频繁API序列. 如果不存在,s就是目前为止已经挖掘到的最长频繁API序列,并把它添加到f′中.
(2) 子集检测:如果序列s通过了超集检测,即它为目前已经挖掘到的最长频繁API序列,那么需要删除f′中s所有的子集,设s′是f′中任意一个API序列,如果s′⊆s,则其是s的子集,从f′中移除s′.
2.4 恶意代码表示与检测
本文基于挖掘的最长频繁序列集合构造词袋模型,把样本文件的动态API序列转化为特征向量,使用随机森林进行分类器训练和恶意代码检测.
2.4.1 最长频繁序列集合表征样本文件 词袋(Bag of Words,BoW)模型最早出现在自然语言处理领域,广泛用于信息检索和文本分类,用于把文本内容向量化. 词袋模型也广泛应用于恶意代码的分类与聚类问题[15-17].
样本的动态API序列可以看作具有时间序列的一维文本,单个最长恶意频繁序列作为能表征文本类别的一个特征,因此本文用最长频繁API序列集合构造恶意行为的词袋模型,基于此模型将恶意代码样本和正常样本的动态API序列转化为向量.
对于恶意代码来说,恶意行为往往多次出现,因此最长频繁序列可能在样本文件的动态API序列中多次出现. 统计表明,大多数最长频繁序列在动态API序列中出现次数不超过5次.因此,为了避免奇异性向量出现导致训练时间长,当该API序列在动态API序列出现的次数超过5次时,计为5次.
2.4.2 分类器构建与恶意代码检测 本文使用随机森林算法[18]建立分类器模型并进行恶意代码检测. 随机森林属于集成学习中的Bagging算法,通过组合多个弱分类器(决策树),最终结果通过投票或取均值,使得模型有较高的精确度和抗过拟合性能.
检测阶段首先把训练样本的向量集进行归一化处理;然后进行标注,导入数据开始训练分类器;最后把处理好的测试集输入到已训练好的模型中进行检测.
3 实验结果和分析
本节通过一系列实验对本文提出的恶意代码检测方法进行评估,并将其与已有的基于API调用序列的恶意代码检测方法进行比较. 本文实验采用多进程,利用Redis数据库的队列功能实现分布式挖掘,挖掘部分在2台6核Intel(R)i5-8600k机器上进行,去重部分在6核Intel(R) Xren(R) CPU E3-1230 v3上运行.
3.1 实验数据集及挖掘结果
论文实验中的实验样本来源于阿里云安全算法大赛使用的数据集,包括7个典型类别的恶意样本和正常样本. 实验的7类恶意代码分别是勒索病毒、挖矿程序、DDoS木马、蠕虫病毒、感染性病毒、后门程序和特洛伊木马. 此数据集包含301个API函数,为便于处理,本文对每个API函数用编号替代.
由于此数据集包含逃避性样本,还有一些样本因其他原因未在沙箱环境成功运行[6,9],对最长频繁序列挖掘及后面的恶意代码检测造成干扰,因此剔除这部分样本,该数据集的蠕虫病毒样本数量较少,故额外选取180个蠕虫样本,他们来源于开源病毒库Virushare,使用Virustotal检测和本地搭建Avclass[19]环境进行标注. 本文除去挖掘样本后,80%的样本用于模型训练,20%的样本用于测试. 筛选后的数据集样本空间如表3样本集所示.
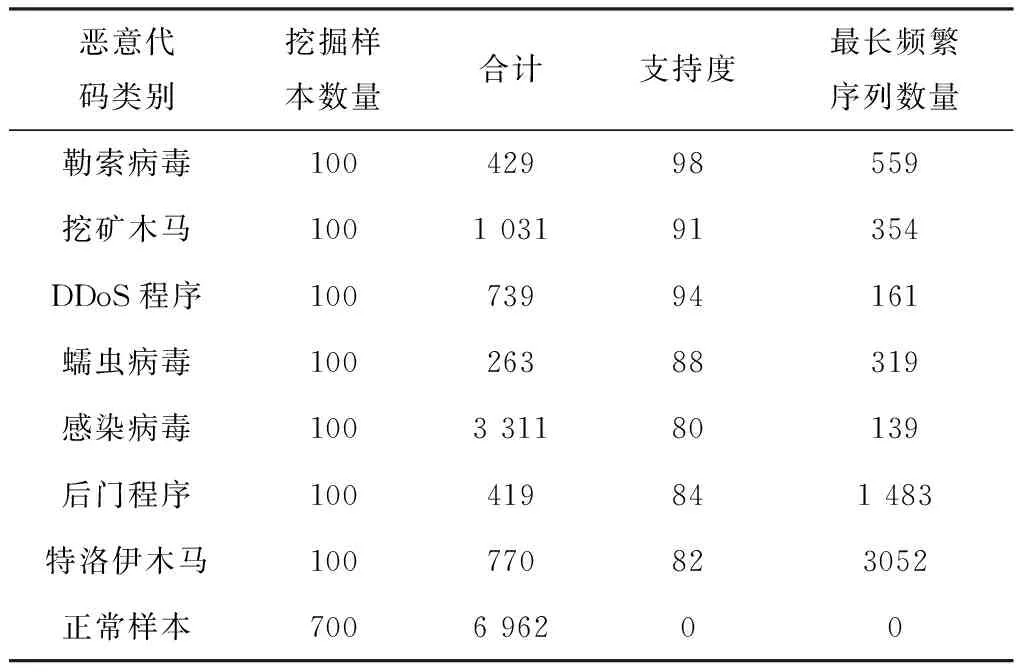
表3 样本集
为保证挖掘的最长频繁序列具有普适性,样本应该随机选取,且达到一定量. 所有类别采用100个样本进行挖掘. 由定义可知,支持度越小,时间和空间复杂度越大,挖掘到的最长频繁序列越多. 为保证挖掘算法的时间可实现性,而挖掘到尽可能多的最长频繁序列,支持度应合理选择. 本文各类别挖掘的支持度以及挖掘结果如表3所示.
3.2 实验结果分析
在分类问题中,评价指标有准确率(Accuracy,ACC)、精确度和召回率曲线(Precision Recall Curve,PRC)、特征曲线(Receiver Operating Curve,ROC)和曲线区域面积(Area Under Curve,AUC). 曲线面积AUC在测试集样本分布变化时仍然能够保持稳定. AUC越大,表明分类器效果越好,因此测试结果的采用的主要指标有:ACC和AUC. 这些指标涉及机器学习中的四个检验指标:真阳性(TP)、真阴性(TN)、假阳性(FP)、假阴性(FN),如表4检验指标的含义.
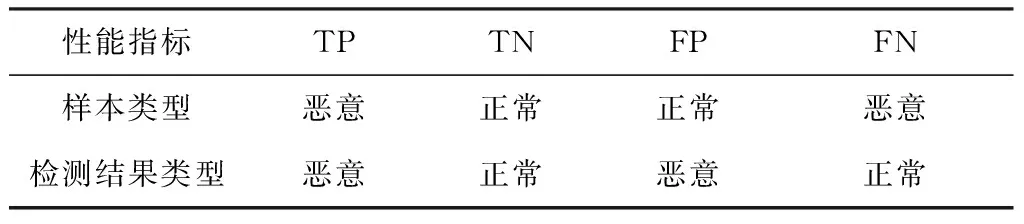
表4 检验指标的含义
ROC是一个二维坐标轴中的曲线,横坐标是假阳性率(False Positive Rate,FPR),纵坐标是真阳性率(True Positive Rate,FPR),由表4得到TPR和FPR定义. 由一个确定的分类器和测试集可得到一组FPR和TPR,设置不同的TPR可得到一系列的FPR和TPR构成ROC曲线,AUC是ROC曲线好坏的有效度量方式,TPR、FPR和ACC的定义如下.
(3)
(4)
(5)
选取不同的信息增益的序列,可得到一系列的AUC和ACC值,如图2不同最长频繁数量的准确率和AUC值所示.
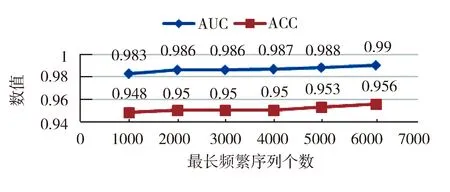
图2 不同最长频繁数量的准确率和AUC值Fig.2 The accuracy and AUC value of different sequence number
从图2可以看出,选取前6131个信息增益较大的最长API序列,AUC曲线面积最大为0.99,分类器的准确率为95.6%. 而芦效峰等人[13]提出的方法使用信息熵筛选API序列特征,组合随机森林和LSTM网络进行恶意代码检测. 如表5为本文方法芦效峰等人的组合模型的对比.
表5 本文方法和组合框架方法的检测结果
Tab.5 The method comparison between this paper and combination frame

本文Method组合模型准确率/%AUC准确率%AUC95.60.9993.50.971
表5的实验结果表明,本文提出的恶意代码检测方法相对于芦效峰等人的组合模型对恶意代码检测的效果更佳. 这是因为芦效峰等人把所有样本作为一个恶意样本集进行API序列的筛选,没有考虑不同种类的恶意代码的功能差异性导致的API序列的差异性.
文献[8,13]指出序列长度越长,对恶意样本和正常样本有更强的区分能力,而文献[8]提出的MACSPMD方法挖掘的序列长度大于等于5的才174个,大于等于7的序列才8个,文献[14]采用4-Gram方法进行API序列的分割,因此检测准确率存在局限性. 本文提出的方法挖掘的6 131个序列长度分布如图3所示.
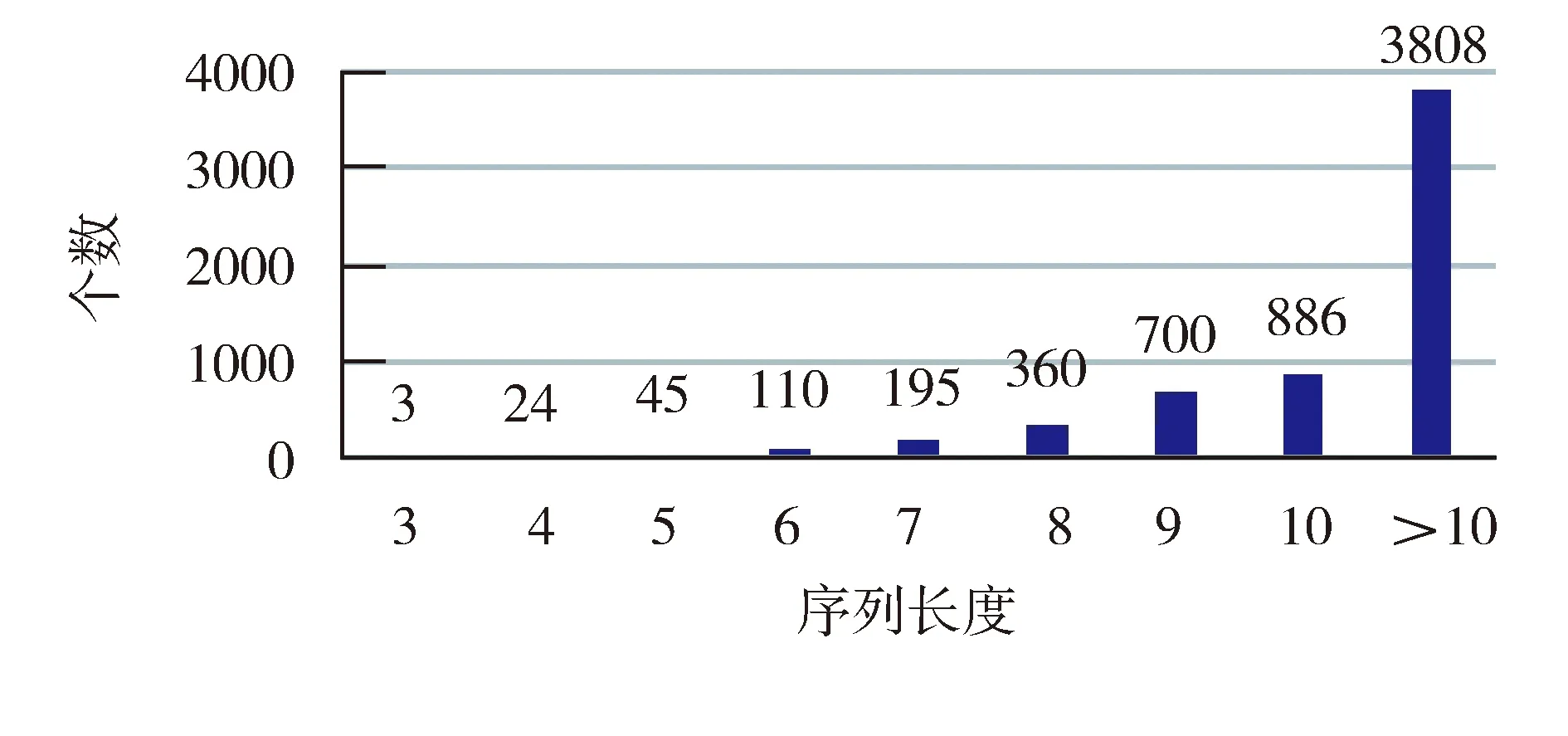
图3 最长频繁序列不同长度的个数分布图Fig.3 The number of longest frequent API sequence distribution of the length
如图所示最长频繁序列的长度大部分大于6,因此,本文挖掘的最长频繁序列能更好的表示恶意代码的某种潜在恶意行为,并且相对于其他特征形式(API调用集和N-Gram模式),本文挖掘的最长频繁序列作为特征有更强的解释性. 另外本文不同类别的恶意样本分布不均衡,仍能取得较好的检测效果,说明本文提取的特征更有效,因此对恶意样本和正常样本有更好的区分能力.
4 结 论
本文基于恶意代码的动态API调用序列,采用最长频繁序列挖掘算法,提出了一种新的恶意代码检测方法. 本文提出的恶意代码检测方法首先获取PE文件在沙箱中运行产生的API调用序列;然后,选取区别恶意样本和正常样本的关键API保留其调用顺序,并使用本文提出的分类别的最长频繁序列挖掘算法挖掘出能代表这一类恶意代码的最长API调用序列;使用挖掘出的最长频繁API序列集合构造词袋模型;用特征向量表征样本文件;最后采用随机森林构造分类器用于恶意代码检测. 实验结果表明,本文提出的恶意代码检测模型能有效检测恶意代码.
本文提出的挖掘算法在挖掘过程中要根据候选项多次迭代,产生了大量冗余的子序列,这也是当前序列挖掘算法的一大难点,希望在以后的工作中能够优化数据结构和算法,避免大量冗余的序列产生,加快挖掘速度,节约存储空间. 本文考虑到子序列的数量级较大,未将最长频繁API序列还原成API子序列,在恶意行为的表征方面缺乏细粒度的表示,下一步提出优化策略完全还原所有的API子序列,并筛选增益较大的API子序列来表征恶意代码的恶意行为. 另外本文选取的特征较为单一,在加入API总数、API个数、单个API所占比例统计特征,API语义,API参数及返回值等特征,结合自然语言处理和深度学习算法应该能进一步提高准确率.
猜你喜欢
电子产品世界(2022年4期)2022-04-21
陶瓷学报(2021年4期)2021-10-14
计算机系统应用(2021年2期)2021-02-23
少儿画王(3-6岁)(2020年4期)2020-09-13
商品与质量(2019年34期)2019-11-29
计算机测量与控制(2019年4期)2019-05-08
计算机系统应用(2019年3期)2019-03-11
科技视界(2015年24期)2015-08-22
中国信息化·学术版(2013年1期)2013-05-28
微型计算机(2009年4期)2009-12-23
