
基于大数据的列存储数据库技术研究
2020-07-27 16:31邱宏
中阿科技论坛(中英阿文) 2020年5期


摘要:随着物联网及云计算技术的兴起,以及移动互联网技术的不断发展,以社交网络、电商等为代表的新型应用在日常生活中使用越来越广,与此同时它们的数据规模也急剧增加。列存储数据库在管理海量数据、从规模庞大的数据中获取有用信息方面有突出的优势。在处理海量数据时列存储数据库的性能要明显优于传统的行存储数据库,因此研究基于大数据的列存储数据库技术有重要意义。
关键词:列存储,大数据,数据库,并行查询
中图分类号:TP311.13 文献标识码:A
收稿日期:2020-04-29
作者简介:邱宏(1979-)男,讲师,硕士,研究方向:网络安全与执法。
1 前言
随着移动互联网技术及计算机技术的发展,对海量数据进行处理的场景变得越来越常见。传统的数据库是行存储的,在处理海量数据时存在先天性不足。为了解决大数据时代面临的海量数据处理挑战,列存储数据库技术应运而生。
和传统的行存储数据库相比,列存储数据库处理海量数据时的优势主要包括[1]:(1)存储数据前采用压缩算法先压缩数据,对于存在大量重复的数据可以有效提升存储利用率。(2)可以直接访问压缩数据,提高了数据查询性能。(3)查询时可以只读取查詢相关列,节省数据缓存的同时能够提升查询性能。
2 大数据理论基础
Hadoop生态的MapReduce并行编程技术是大数据的基础,主要目的是解决在分布式集群环境下的海量数据处理问题。和传统的并行编程技术相比,MapReduce并行编程模型能够隔离上层应用程序和底层通信,在面向数据挖掘、云计算等大数据应用时应用更加广泛。
MapReduce在处理海量数据任务时,将大数据集分成多个独立的子任务,并且并行执行这些子任务,每个并行执行的独立任务称为Map任务。实际执行时,Map任务是分配到不同的机器上并行执行的,执行完成后会调用Reduce任务对各机器执行的Map任务的中间结果进行汇总。
需要注意的是,MapReduce是一种并行计算模型,Map任务及Reduce任务并不是固定不变的,而是用户根据自己的需要自行实现的,只要按照固定的输入、输出格式实现即可。Map任务及Reduce任务的输入及输出格式如表1所示:
在采用MapReduce并行计算模型时,分布式集群的Master节点将数据划分成多个子集,并把整个计算任务分为Map任务和Reduce任务,然后把各个任务分配到集群中空闲的worker节点。典型的MapReduce任务过程过程包括[2]:(1)划分数据集。用户提交作业请求,Master节点将输入数据分成多个子数据块,并转化为
集群所以节点计算任务得到的键值对可能有不同的键值,为了提高计算消息,可以将相同键的数据交给同一个Reduc处理,这样就需要对Map 阶段产生的所有键值对进行交换和排序,以便将相同key的键值对存放在同一数据块中。(4)Reduce阶段。调用Reduce函数对Map阶段得到的所有中间数据进行处理。(5)输出阶段。将输出结果输出到指定位置。
MapReduce模型的处理流程如图1所示:
3 列存储数据库的自适应索引技术
索引的合理使用可以有效降低查询读取的数据量,从而能够显著提升数据库的查询性能。影响索引性能的重要指标包括初始化成本、查询执行时间以及收敛速度。初始化成本指的是第一个查询语句需要的时间;收敛速度说明经过多少查询语句后索引的性能趋于稳定;查询语句的执行时间包括单个查询语句的执行时间和累积执行时间。
数据分割索引算法对数据库的列进行索引时使用的是快速排序算法,并用查询语句的边界值充当列的划分点。在数据库的列第一次被查询的时候,数据分割索引算法会构造此列对应的索引列,然后据此查询数据的边界值,以对索引列中的数据进行重组。在第一个查询语句执行完毕后,索引列会被划分成多个子集,子集间整体上是有序排列的,但各个子集内部局部是无序的。后续有查询需求时,只需要根据数据的边界范围即可访问索引的不同部分,而不需要访问整个索引列,这样可以大大降低查询数据的数据量,提高查询性能。
自适应合并索引算法对数据库的列进行索引时使用的是合并排序算法。第一个查询语句执行后会将数据列划分成若干数据块,在对数据块排序后再从数据块中查找数据,每个数据块自身是排好序的,因此查找数据时采用二分法。后续的查询语句会将满足需求的数据合并后转移到结果集,然后对结果集进行排序;等数据块中的所有数据都被转移到结果集后,索引就建立成功。
数据分割索引算法和自适应合并索引算法在执行第一个查询语句时构建索引列的过程是不同的[3]:数据分割索引算法构建索引列是通过复制完成的,而在后续的查询语句中重组数据块借助的是两个边界值;自适应合并索引算法在执行第一个查询语句时是把数据列分成了多个数据块,并对每个数据块进行排序,后续的查询语句是借助二分法。
4 列存储数据库的并行查询技术
从海量数据中查询数据时,由于数据量非常大的原因,如果查询过程采用传统的串行化操作,那么势必会影响查询的效率,并行化查询是提高数据库查询性能的重要手段。
并行数据库查询的实现方式主要包括[4]:(1)并行查询操作。将原来的一个查询语句并行化为多个并行查询。(2)多查询间的并行。对于相互间不影响的查询操作,尽量一起操作,进行并行查询。(3)用户间的并行。不同用户间的查询操作,允许同时进行。
作为查询语句的基本组成部分,查询操作自身的并行对提高查询效率的影响很明显,选择、连接以及聚集等查询操作都可以并行。对于基于扫描的查询操作,在扫描数据文件时就并行操作;对于基于排序的查询操作,先对数据进行排序,然后选择和查询操作相关的并行处理方式;对于基于索引的查询操作,想建立索引,然后通过索引并行执行相关操作。
查詢语句的并行执行具体实现方式是根据操作间的并行程度实现的,根据查询操作间的依赖关系,可以把查询语句的并行执行方式分为查询操作间的独立并行执行及查询操作间的流水线并行执行。查询操作间的独立并行执行指的是查询操作时完全相互独立的,各个查询操作间没有任何关系,也不存在先后顺序;这样的查询操作可以分别分配一定数目的处理单元,实现完全并行。查询操作间的流水线并行执行指的是各个查询操作间存在某种先后顺序关系,这样的话可以为存在先后关系的查询操作分配同样的处理单元,在前序查询操作执行一部分后,即可将前序操作的结果传递给后序查询操作处理,而不用等前序查询操作完全执行完毕。
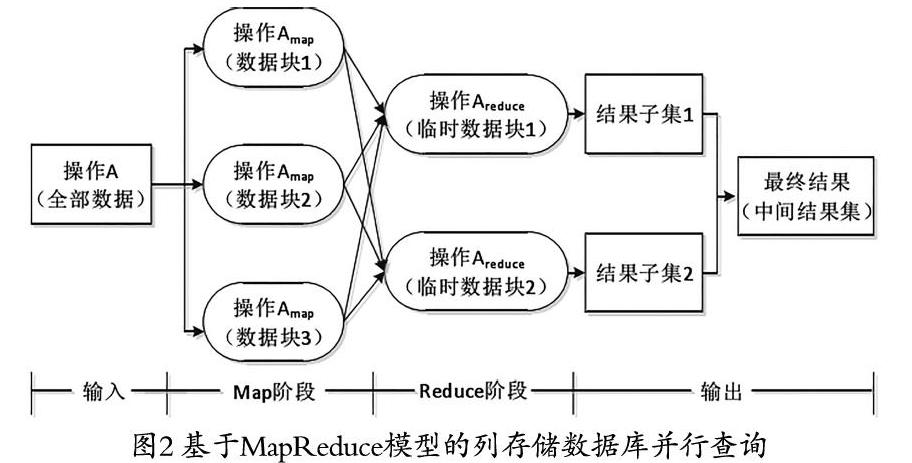
采取MapReduce模型实现列存储数据库中并行查询操作的流程如图2所示:
其中Map阶段Amap函数会对各个数据块进行处理,处理结果会在Reduce阶段被Areduce函数使用,对应的结果子集在汇总后被输出为最终的结果集。
5总结
本文对基于大数据的列存储数据库技术进行研究。首先,介绍了列存储数据库技术的理论基础——MapReduce并行计算模型;然后在此基础上分析了列存储数据库的自适应索引技术和并行查询技术。最终采取MapReduce模型实现了列存储数据库的并行查询操作。
参考文献:
[1]王振玺,乐嘉锦,王梅,等.列存储数据区级压缩模式与压缩策略选择方法[J].计算机学报,2019(8):1524-1530.
[2]王梅,杨思箫,乐嘉锦.列存储数据库中压缩位图索引技术[J].计算机工程,2018(10):26-29.
[3]邓亚丹.面向共享Cache多核处理器的数据库查询执行优化技术研究[D].长沙:国防科学技术大学,2019.
[4]郑黎辉.数据库并行查询优化的设计与实现[J].长春:吉林大学,2018.
Abstract: With the rise of Internet of things and cloud computing technology, as well as the continuous development of mobile Internet technology, new applications such as social networks, e-commerce, etc. are used more and more widely in daily life, at the same time, their data scale has increased dramatically. Column storage database has outstanding advantages in managing massive data and obtaining useful information from large-scale data. When dealing with massive data, the performance of column storage database is obviously better than that of traditional row storage database, so it is of great significance to study the technology of column storage database based on big data.
Key words: Column storage, Big data, Database, Parallel query
猜你喜欢
财经(2017年15期)2017-07-03
财经(2017年2期)2017-03-10
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
财经(2010年20期)2010-10-19
